文本检测: CTPN
参考:
https://zhuanlan.zhihu.com/p/37363942
https://zhuanlan.zhihu.com/p/34757009
https://zhuanlan.zhihu.com/p/31426458 【 Faster RCNN 非常详尽】
对于理解RNN/LSTM首先推荐阅读以下2篇文章,里面有详细的公式推导:
简介
文章基本信息
论文题目:Detecting Text in Natural Image with Connectionist Text Proposal Network,简称CTPN.该文章是ECCV2016乔宇老师的文章
论文地址:https://arxiv.org/pdf/1609.03605.pdf
代码实现:https://github.com/tianzhi0549/CTPN(作者的caffe实现),
https://github.com/eragonruan/text-detection-ctpn(其他人tensorflow实现)
作者提供的caffe实现没有训练代码,不过训练代码可以参考faster-rcnn的训练代码
文本检测概述
文本检测可以看成特殊的目标检测,但它有别于通用目标检测.在通用目标检测中,每个目标都有定义好的边界框,检测出的bbox与当前目标的groundtruth重叠率大于0.5就表示该检测结果正确.
文本检测中正确检出需要覆盖整个文本长度,且评判的标准不同于通用目标检测,具体的评判方法参见(ICDAR 2017 RobustReading Competition).所以通用的目标检测方法并不适用文本检测。
原始CTPN只检测横向排列的文字。CTPN结构与Faster R-CNN基本类似,但是加入了LSTM层。假设输入 Images:
- 首先VGG提取特征,获得大小为
的conv5 feature map。
- 之后在conv5上做
的滑动窗口,即每个点都结合周围
区域特征获得一个长度为
的特征向量。输出
的feature map,该特征显然只有CNN学习到的空间特征。
- 再将这个的feature map每一行都作为一个
的数据流,输入Bi-directional LSTM(双向LSTM),学习每一行的sequence feature。经过reshape后最终输出
特征,既包含空间特征,也包含了LSTM学习到的序列特征。
- 再经过“FC”卷积层,变为
的特征
- 最后经过类似Faster R-CNN的RPN网络,获得text proposals,如图2-b。
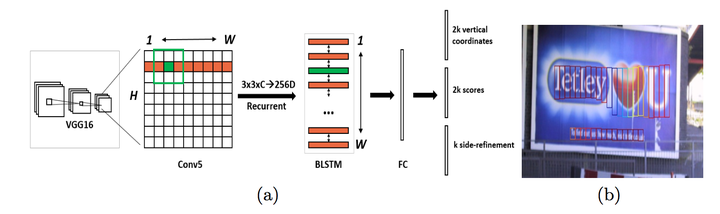
图2 CTPN网络结构
-
更具体的网络结构,请使用netscope查看CTPN的deploy.prototxt网络配置文件。
接下来,文章围绕下面三个问题展开:
- 为何使用BLSTM
- 如何通过FC层输出产生图2-b中的Text proposals
- 如何通过Text proposals确定最终的文本位置,即文本线构造算法
回答这三个问题,基本原理就了解了。感谢作者,写的很详细。
详见知乎:https://zhuanlan.zhihu.com/p/34757009

 浙公网安备 33010602011771号
浙公网安备 33010602011771号