pandas contact 之后,若要用到index列,要记得用reset_index去处理index
# -*- coding: utf-8 -*-
import pandas as pd
import sys
df1 = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']})
frames = [df1, df2, df3]
result = pd.concat(frames)
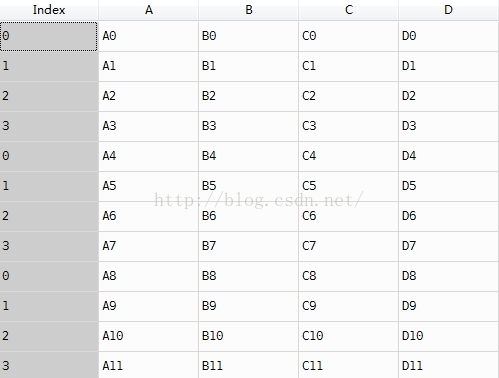
说明:直接contact之后,index只是重复,而不是变成我们希望的那样,这样在后续的操作中,容易出现逻辑错误。
-
df4 = pd.DataFrame({'val':[0,1,2,3,4,5,6,7,8,9,10,11],'A': ['A0', 'A1', 'A2', 'A3','A4', 'A5', 'A6', 'A7','A8', 'A9', 'A10', 'A11'],})
-
result['val'] = df4['val']
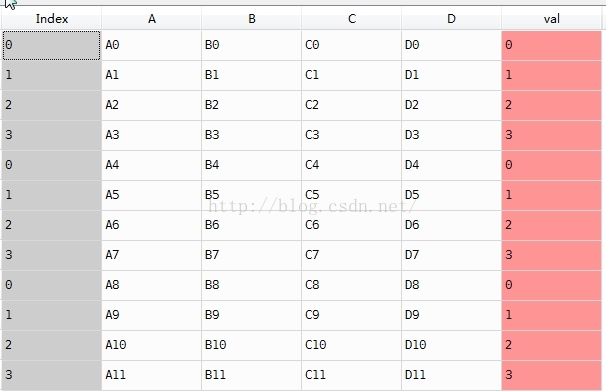
说明:result['val'] = df4['val'] 是按照index赋值的,所以,结果就出乎我们的意料。
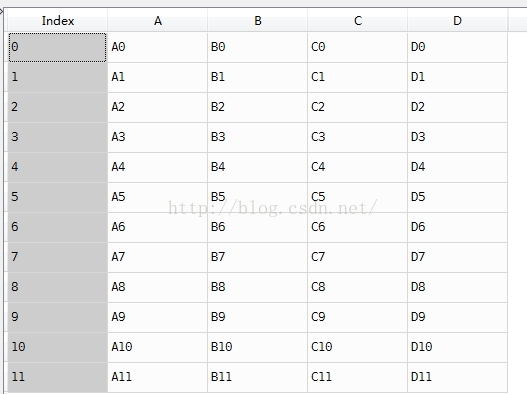
使用result = result.reset_index(drop=True)来改变index就可以了,
转自:https://blog.csdn.net/lujiandong1/article/details/52929090

 浙公网安备 33010602011771号
浙公网安备 33010602011771号