
NLP python库 nltk 安装
使用python进行自然语言处理,有一些第三方库供大家使用:
·NLTK(Python自然语言工具包)用于诸如标记化、词形还原、词干化、解析、POS标注等任务。该库具有几乎所有NLP任务的工具。
·Spacy是NLTK的主要竞争对手。这两个库可用于相同的任务。
·Scikit-learn为机器学习提供了一个大型库。此外还提供了用于文本预处理的工具。
·Gensim是一个主题和向量空间建模、文档集合相似性的工具包。
·Pattern库的一般任务是充当Web挖掘模块。因此,它仅支持自然语言处理(NLP)作为辅助任务。
·Polyglot是自然语言处理(NLP)的另一个Python工具包。它不是很受欢迎,但也可以用于各种NLP任务。
先由nltk入手学习。
1. NLTK安装
简单来说还是跟python其他第三方库的安装方式一样,直接在命令行运行:pip install nltk
2. 运行不起来?
当你安装完成后,想要试试下面的代码对一段英文文本进行简单的切分:
import nltk
text=nltk.word_tokenize("PierreVinken , 59 years old , will join as a nonexecutive director on Nov. 29 .")
print(text)
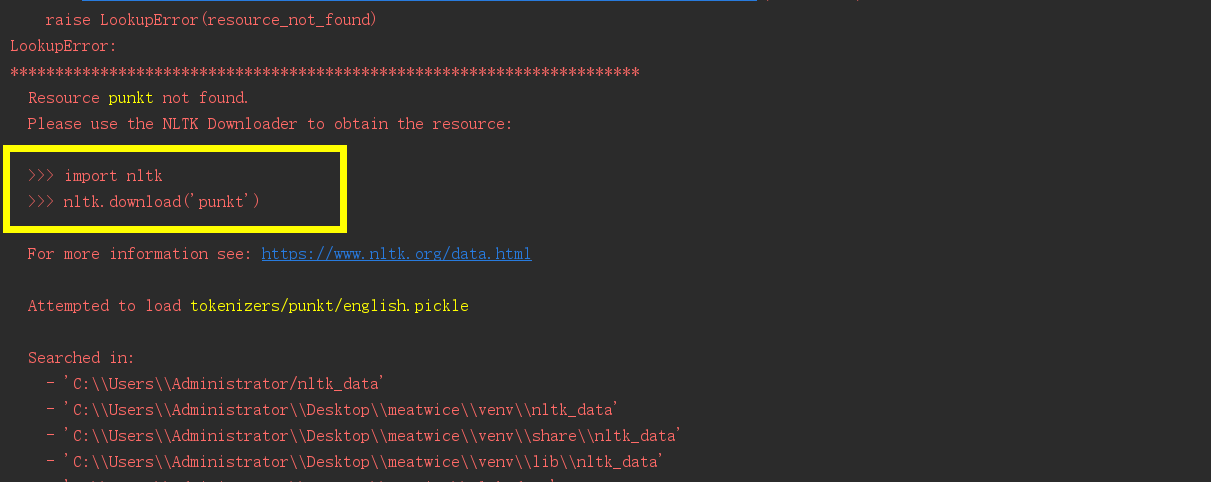
运行结果, 报错如下:

...
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt/english.pickle
Searched in:
- 'C:\\Users\\Administrator/nltk_data'
- 'C:\\Users\\Administrator\\Desktop\\meatwice\\venv\\nltk_data'
- 'C:\\Users\\Administrator\\Desktop\\meatwice\\venv\\share\\nltk_data'
- 'C:\\Users\\Administrator\\Desktop\\meatwice\\venv\\lib\\nltk_data'
- 'C:\\Users\\Administrator\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- ''
**********************************************************************
3. 解决方法:
不用着急,解决方法在异常中已经给出来了
命令行进入python交互模式,运行如下:
import nltk nltk.download()
然后会弹出一个窗口,点击models,找到punkt,双击进行下载即可。

然后运行开始的那段python代码,对文本进行切分:
import nltk
text=nltk.word_tokenize("PierreVinken , 59 years old , will join as a nonexecutive director on Nov. 29 .")
print(text)
结果如下,不会报错:

4. nltk的简单使用方法。
上面看了一个简单的nltk的使用示例,下面来具体看看其使用方法。
4.1 将文本切分为语句, sent_tokenize()
from nltk.tokenize import sent_tokenize text=" Welcome readers. I hope you find it interesting. Please do reply." print(sent_tokenize(text))
从标点处开始切分,结果:

4.2 将句子切分为单词, word_tokenize()
from nltk.tokenize import word_tokenize text=" Welcome readers. I hope you find it interesting. Please do reply." print(word_tokenize(text))
切分成单个的单词,运行结果:

4.3.1 使用 TreebankWordTokenizer 进行切分
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
print(tokenizer.tokenize("What is Love? I know this question exists in each human being's mind including myse\
lf. If not it is still waiting to be discovered deeply in your heart. What do I think of love? For me, I belie\
ve love is a priceless diamond, because a diamond has thousands of reflections, and each reflection represent\
s a meaning of love."))
也是将语句切分成单词,运行结果:

