Flink简介
Flink简介
Flink的核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以方便用户编写分布式任务:
1. DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便的采用Flink提供的各种操作符对分布式数据集进行各种操作,支持Java,Scala和Python。
2. DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便的采用Flink提供的各种操作符对分布式数据流进行各种操作,支持Java和Scala。
3. Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过Flink提供的类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如:
1. Flink ML,Flink的机器学习库,提供了机器学习Pipelines API以及很多的机器学习算法实现。
2. Gelly,Flink的图计算库,提供了图计算的相关API以及很多的图计算算法实现。
Flink的技术栈如下图所示:
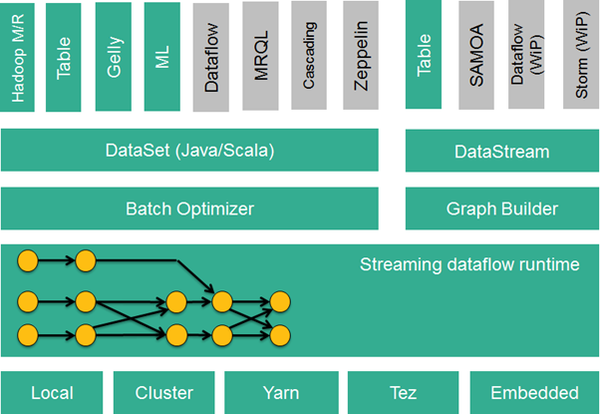
Flink技术栈
此外,Flink也可以方便地和其他的Hadoop生态圈的项目集成,例如,Flink可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式的数据源,直接重用MapReduce/Storm代码,或是通过YARN申请集群资源等等。
Flink是一个拥有诸多特色的项目,包括其统一的批处理和流处理执行引擎,通用大数据计算框架与传统数据库系统的技术结合,以及流处理系统的诸多技术创新等。
Flink还有一些其他很有意思的特性没有详细介绍,比如DataSet API级别的执行计划优化器,原生的迭代操作符等,感兴趣的读者可以通过Flink的官网了解更多Flink的详细内容。
链接:https://zhuanlan.zhihu.com/p/20585530
FLink 简介:
Spark 和 Flink 比较
Spark 和 Flink 两个项目的核心 API 基本一致,Spark 在机器学习整合方面投入更多,Flink 在流处理方面更赞,当然二者最大的区别,也还在于对流式计算的支持。
这句的潜在含义就是 Spark 存在的道理:尽管 Spark Steaming 现在和 Flink 相比优势不显,但它的生态更为丰富,除了 Streaming 还有 SQL、MLib、Graphx 等,
同时目前 Spark 对 Kubernetes 云原生技术的原生支持更加到位。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号