《CBAM: Convolutional Block Attention Module》论文笔记
论文题目:《CBAM: Convolutional Block Attention Module》
论文作者:Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon
论文发表年份:2018
模型简称:CBAM
发表会议:ECCV
Abstract
我们提出了一种简单而有效的前馈卷积神经网络注意模块(Convolutional Block Attention Module, CBAM)。给定一个中间特征映射,我们的模块沿着通道和空间两个独立维度依次推导注意映射,然后将注意映射与输入特征映射相乘,进行自适应特征细化。因为CBAM是一个轻量级的通用模块,它可以无缝地集成到任何CNN体系结构中,开销可以忽略不计,并且可以与基本CNN一起进行端到端训练。我们通过在ImageNet-1K、MS COCO检测和VOC 2007检测数据集上的大量实验验证了我们的CBAM。
Contribution
1. 我们提出了一种简单而有效的注意模块(CBAM),可以广泛应用于提高CNN的表示能力。
2. 我们通过广泛的消融研究验证了我们的注意模块的有效性。
3.通过插入我们的轻量级模块,我们验证了在多个基准(ImageNet-1K、MS COCO和VOC 2007)上,各种网络的性能都得到了极大的提高。
Related Work
与我们的工作更接近的是,在的Squeeze-and-Excitation模块中,使用全局平均池特征来计算通道方面的注意力。然而,我们表明,为了推断精细通道注意力,这些是次优特征,我们建议使用最大池特征。SE模块还会错过空间注意力,而空间注意力在决定“集中在哪里”方面起着重要作用。在我们的CBAM中,我们基于一个高效的体系结构开发了空间型和通道型注意力,并验证了同时利用这两种注意要优于仅使用通道型注意力。同时,BAM采用了类似的方法,将3D attention map推理分解为通道和空间。他们在网络的每个瓶颈处放置BAM模块,而我们在每个卷积块中插入。
Method
由于卷积运算通过混合通道和空间信息来提取信息特征,我们采用的模块来强调这两个主要维度上的有意义的特征:通道和空间维度。为了实现这一目标,我们依次应用通道和空间注意模块,这样每个分支都可以分别知道在通道和空间维度上要学习“什么”和关注“哪里”。因此,我们的模块通过学习强调或抑制哪些信息,有效地帮助信息在网络中流动。下图为整体架构。
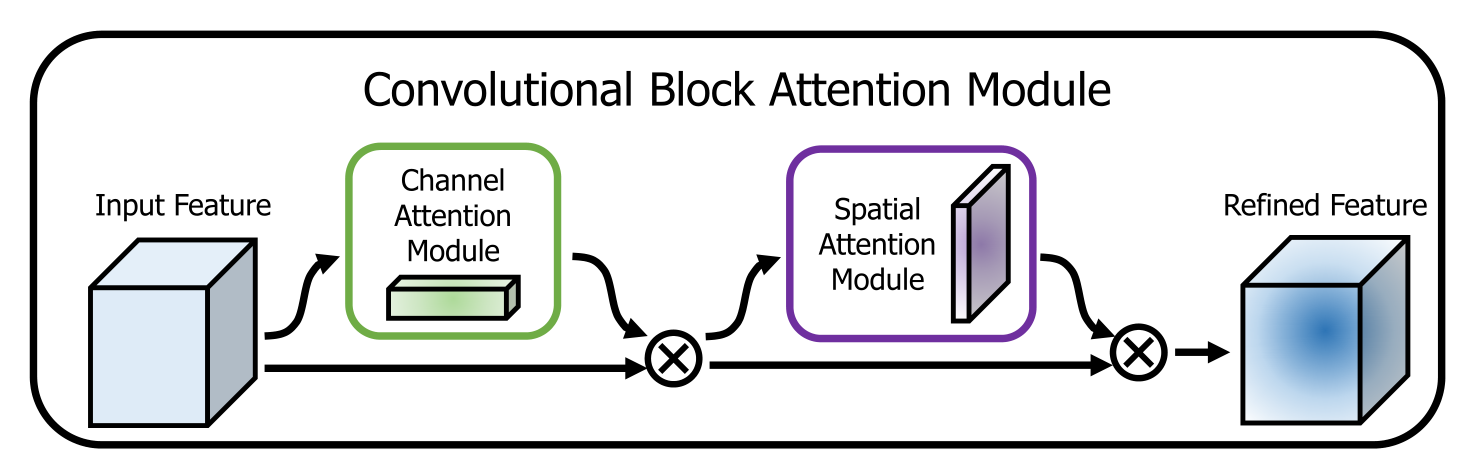
给出一个中间特征图F∈RC×H×W作为输入,CBAM依次推导出一维通道注意映射Mc∈RC×1×1,二维空间注意映射Ms∈R1×H×W,整个注意过程可以总结为:
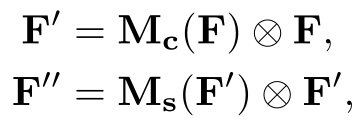
⊗表示按元素计算的乘法,在乘法过程中,注意值相应地被广播(复制):通道注意值沿着空间维度被广播,反之亦然。F”是最终的精炼输出。下图描述了各个注意map的计算过程。
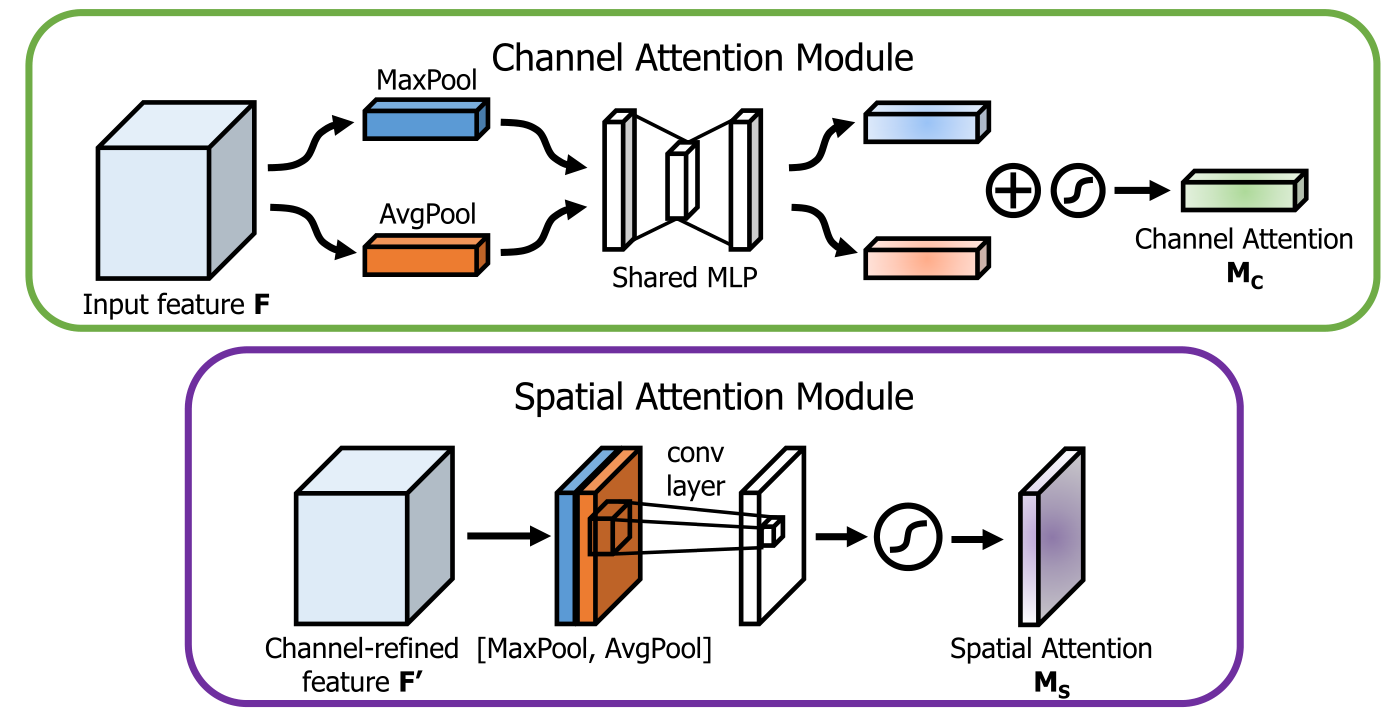
Channel Attention Module(focus on what):我们首先通过使用平均池化和最大池化操作聚合feature map的空间信息,生成两个不同的空间上下文描述符:Fcavg和Fcmax ,然后,两个描述符都被转发到一个共享网络,生成我们的通道注意映射Mc∈RC×1×1,共享网络是包含一个隐藏层的多层感知器(MLP),为了减少参数开销,隐藏层的激活大小设置为RC/r×1×1,r是减少比率。在将共享网络应用到每个描述符之后,我们使用基于元素的求和来合并输出特征向量,通道注意计算为:
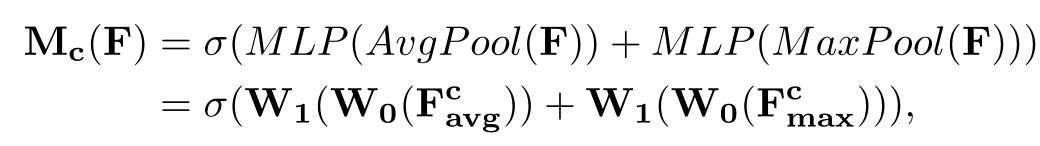
其中σ表示sigmoid函数,W0∈RC/r×C, W1∈RC×C/r。注意,MLP权值W0和W1对于两个输入是共享的,W0后面是ReLU激活函数。
Spatial Attention Module(focus on where):为了计算空间注意力,我们首先沿通道轴应用平均池化和最大池化操作,并将它们连接起来,以生成一个有效的特征描述符。沿着通道轴应用池操作可以有效地突出显示信息区域。在连接特征描述符上,我们应用卷积层生成空间注意映射Ms(F)∈RH×W,它编码了强调和抑制的位置。我们通过两个pooling运算对通道信息的feature map进行聚合,生成两个2D map: Fsavg∈R1×H×W, Fsmax∈R1×H×W ,然后进行连接并被一个标准的卷积层卷积,产生二维空间的attention map。空间注意力的计算方法为:
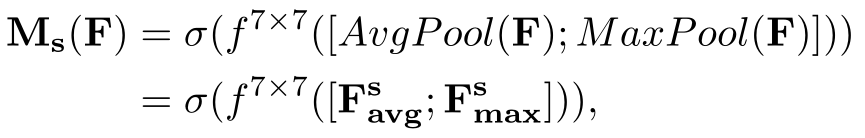
其中σ表示sigmoid函数,f7×7表示filter size为7×7的卷积运算。
Ablation Studies
下图为不同渠道注意方法的比较。我们观察到,使用我们提出的方法优于提出的SE方法。

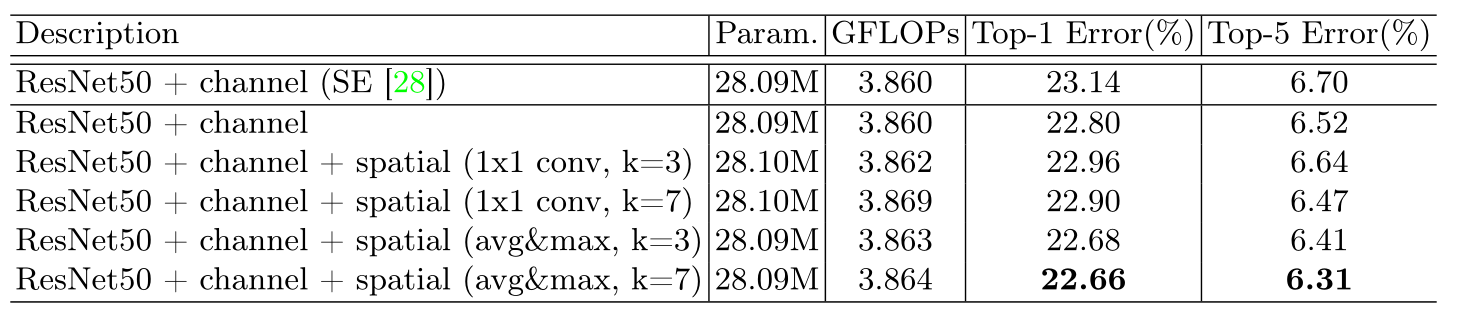
下图为不同空间注意方法的比较。使用提出的通道池(即沿通道维度的平均池化和最大池化)以及7*7的卷积核大小进行卷积运算效果最好。
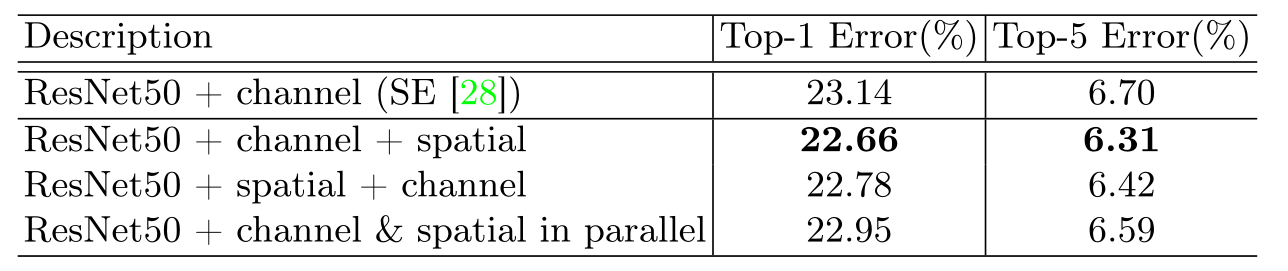
下图为通道和空间注意结合顺序的比较。同时使用两种注意力是至关重要的,而最佳组合策略(即顺序,Channel First)进一步提高了准确性。
Conclusion
我们提出了一种提高CNN网络表示能力的新方法——卷积块注意模块(CBAM)。我们将基于注意力的特征细化应用于两个不同的模块,通道和空间,并在保持较小开销的同时实现了可观的性能提升。对于通道注意,我们建议使用最大池特征和平均池特征,从而产生比SE更好的注意力。我们进一步利用空间注意力来推动表现。我们的最后一个模块(CBAM)学习在强调哪里或抑制什么,并有效地改进中间特性。为了验证其有效性,我们用各种最先进的模型进行了大量的实验,并证实CBAM在三个不同的基准数据集(ImageNet1K、MS COCO和VOC 2007)上的表现优于所有基线。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号