
《Hyperspectral Image Transformer Classification Networks》论文笔记
论文题目:《Hyperspectral Image Transformer Classification Networks》
论文作者:Xiaofei Yang , Weijia Cao , Yao Lu, and Yicong Zhou , Senior Member , IEEE
论文发表年份:2022
模型简称:HiT
发表期刊:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING
Abstract
由于现有的基于cnn的方法不能充分挖掘光谱特征的序列属性,阻碍了HSI分类的进一步性能提升。本文提出了一种Hyperspectral image Transformer(HiT)分类网络,该分类网络通过在Transformer结构中嵌入卷积运算来捕捉细微的光谱差异并传递局部空间上下文信息。HiT包括两个关键模块,即光谱自适应三维卷积投影模块和卷积置换器(ConV-Permutator),用于提取细微的空间-光谱差异。光谱自适应三维卷积投影模块使用两个光谱自适应三维卷积层代替线性投影层从HSIs生成局部空间光谱信息。此外,Conv-Permutator模块利用深度卷积操作分别沿高度、宽度和光谱维度对空间光谱表示进行编码。
源码:https://github.com/xiachangxue/DeepHyperX
现有CNN、RNN和基于Transformer网络处理高光谱图像分类的缺点:
CNN:所有基于CNN的方法虽然在捕获HSIs的局部环境信息方面具有强大的能力,但都缺乏捕获邻近光谱波段细微光谱差异的能力。其次,基于cnn的方法过于关注空间序列信息,导致提取的特征中光谱序列信息的错误表示,增加了内在和潜在光谱信息的挖掘和表示难度。
RNN:基于rnn的方法由于对谱带顺序的极度依赖,导致梯度消失严重,难以学习到长期依赖性,在实际HSI分类中存在性能瓶颈。
Transformer:1)虽然它们很好地解决了光谱特征的长期依赖性问题,但未能捕捉到局部的空间-光谱融合信息。
2)由于重要的二维卷积运算,Transformer网络可以捕获局部空间上下文信息。然而,二维卷积运算不能很好地检索局部光谱信息。
3)现有Transformer网络采用flattening运算和线性投影顺序编码空间信息,导致局部空间光谱信息和位置信息丢失。如SST:无法捕获HSI分类任务中的局部光谱差异。
Contributions
1)提出了一种新的基于Transformer的HSI分类方法HiT。据我们所知,本文首次将ViTs与卷积运算应用于HSI分类。
2)提出了一种自适应提取光谱信息的SACP模块,并进一步捕获光谱空间融合信息。据我们所知,本文是第一个使用三维卷积运算来投影输入HSI的文章。
3)我们提出了一个新的模块,名为Conv-Permutator,通过分别沿高度、宽度和光谱维度对输入表示进行编码来获取更多的光谱空间信息。
4)基于4个基准数据集的实验结果表明,本文提出的HiT方法优于现有的Transformer和基于cnn的方法。
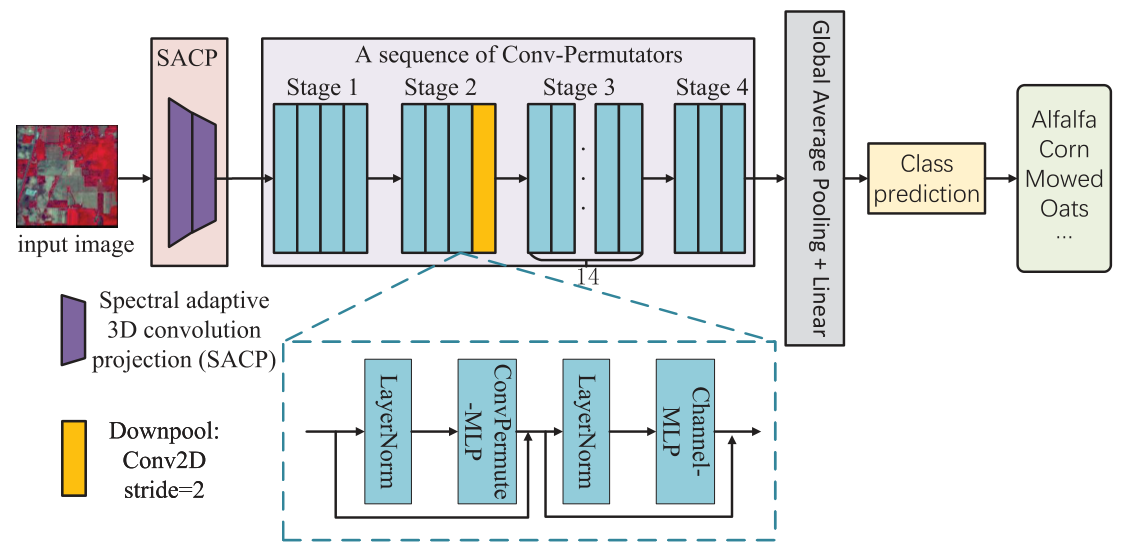
1.SACP Module:SACP使用两个光谱自适应三维卷积层构建,如下图所示,其中包括两个分支:局部空间分支L和全局光谱分支G。局部空间分支旨在学习空间位置敏感的重要图,全局光谱分支通过卷积方式自适应聚合光谱信息。X∈RC×S×H×W,C为通道数。SACP层可表述为:${Y = G(X)\bigotimes (L(X)\bigodot X)}$.$\bigotimes$表示卷积,$\bigodot$表示按元素乘法。上述两个分支关注的是光谱空间信息的不同方面。
1) 局部分支(Local Branch):
它试图通过三维卷积获取短程的光谱空间信息,并关注重要的特征。局部分支对空间位置敏感,利用短期光谱动态进行局部空间光谱特征提取操作。
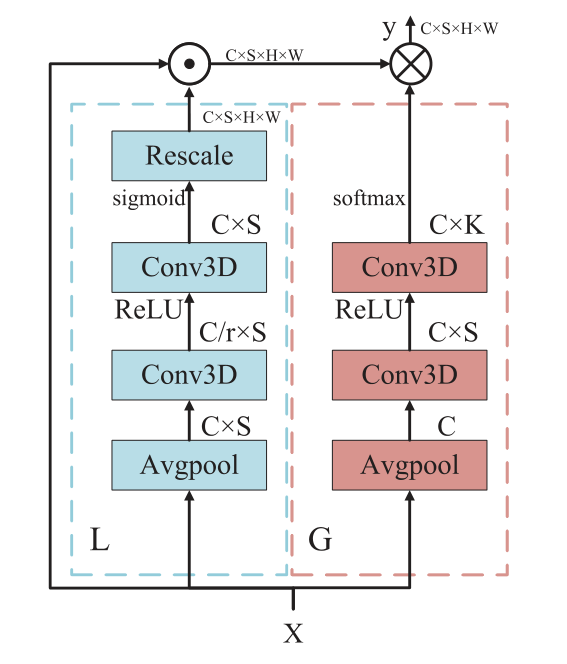
由于局部分支的目标是捕获短期的空间-光谱信息,我们首先使用“AdaptiveAvgPool3d”操作对输入图像进行平均池化,但不是在光谱维度上,然后设置第一个三维卷积核大小K为(3,1,1),只基于局部光谱窗口学习一个重要map。第一个Conv3D后面跟着BN和ReLU。然后,第二个具有Sigmoid激活的Conv3D得到对光谱位置敏感的重要权重W∈RC×S。公式如下:
AdaptiveAvgPool3d理解:
1 import torch 2 import torch.nn as nn 3 4 # target output size of 5x7x9 5 m = nn.AdaptiveAvgPool3d((5,7,9)) 6 input = torch.randn(5, 64, 8, 9, 10) 7 output = m(input) 8 9 print("input.shape:",input.shape) 10 print("output.shape:",output.shape) 11 12 #output 13 #input.shape: torch.Size([5, 64, 8, 9, 10]) 14 #output.shape: torch.Size([5, 64, 5, 7, 9]) 15 16 # target output size of 7x7x7 (cube) 17 m = nn.AdaptiveAvgPool3d(7) 18 input = torch.randn(5, 64, 10, 9, 8) 19 output = m(input) 20 21 print("input.shape:",input.shape) 22 print("output.shape:",output.shape) 23 24 #output 25 #input.shape: torch.Size([5, 64, 10, 9, 8]) 26 #output.shape: torch.Size([5, 64, 7, 7, 7]) 27 28 # target output size of 7x9x8 29 m = nn.AdaptiveAvgPool3d((7, None, None)) 30 input = torch.randn(1, 64, 10, 9, 8) 31 output = m(input) 32 33 print("input.shape:",input.shape) 34 print("output.shape:",output.shape) 35 36 #output 37 #input.shape: torch.Size([1, 64, 10, 9, 8]) 38 #output.shape: torch.Size([1, 64, 7, 9, 8])
2) 全局分支(Global Branch):
其目的是利用三维卷积层,将远程光谱信息整合到一起,进行自适应光谱聚合。综合全局光谱信息,学习生成光谱自适应卷积核进行动态聚合。
全局分支由两个Conv3D层构建,其大小为1 × 1 × 1。它类似于SE Block,只是卷积层是三维卷积层。值得注意的是,生成的核是channel-wise的,这意味着全局分支只对光谱关系建模,而不考虑通道相关性。更正式地说,对于第c个通道,自适应核学习如下:
![]()
其中Θc∈Rk为第c个通道生成的自适应核(聚集权值),K为自适应核大小,δ为激活函数ReLU。F(W1)和F(W2)表示Conv3D层,φ(.)为自适应平均池化操作。由于学习的自适应核具有全局接受域,因此可以聚合全局光谱上下文。学习到的聚合权重Θ= Θ1,Θ2,...,Θc用于进行光谱-空间自适应卷积。
3)Spectral-Adaptive Aggregation:
在这一步中,我们通过结合局部分支和全局分支来输出最终的特征:Y = G(X) ⊗ Z。Y ∈ RC×S×H×W。实际上是把G(X)得到的softmax分数与最后的Conv3D层的初始化的参数进行矩阵乘法、reshape后作维Conv3D层的权重,对L(X)作卷积得到输出Y,再将输出 Y reshape为 Y' ∈R(C×S)×H ×W,其中第三维是光谱维。得到SACP的最终输出。
总之,我们的SACP提供了一个自适应模块,并专注于捕捉不同的结构(即短期空间-光谱结构和长期光谱结构)。
2.Conv-Permutator:
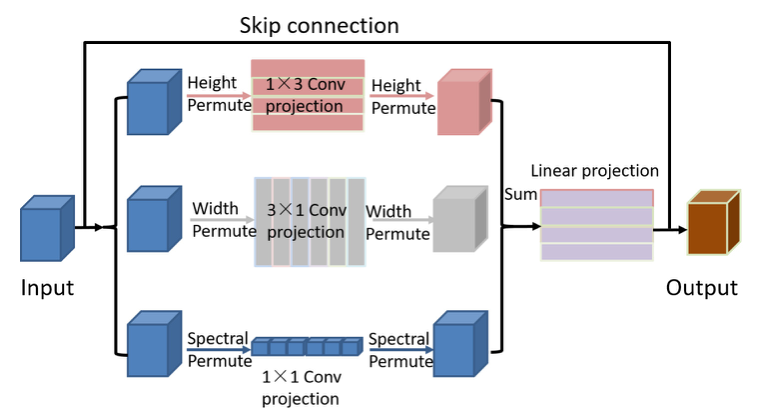
Conv-Permutator 模块由ConvPermute和Channel-Master Limited Partnership (MLP)两个关键组件构成,分别对局部空间信息和光谱信息进行编码。该模块与ViP结构相似。空间-光谱信息分别沿着高度、宽度和光谱维度进行处理。与ViP不同的是,我们通过利用深度和点卷积层而不是线性投影来提取空间-光谱表示。给定输入编码 D tokens T ∈ RH ×W×D,Conv-Permutator的输出公式为:

Conv-Permute Module:首先分别沿高度、宽度和光谱维度对空间光谱特征进行编码。提取的特征然后利用元素加法和一个完全连接层聚合。光谱通道操作是使用一个带权重WS ∈ R1×1的简单点卷积层从输入X捕获局部光谱信息。生成局部光谱特征XS。给定输入X∈RH×W×D,空间信息编码器将X分为两个分支:高通道编码器和宽通道编码器。高度通道操作是使用权重为WH的深度卷积层提取高度局部空间信息,生成XH 。宽度通道操作利用权重为Ww的深度卷积层捕获宽度局部空间信息,生成Xw。然后使用elementwise加法简单地融合从三个分支获得的输出特征。为了进一步改进融合的特性,我们使用一个新的全连接层来重新校准三个不同分支的重要性。最后,我们采用跳过连接来避免梯度消失问题。
Channel-MLP Module:与ViP结构相似(ViP中提到:Channel-MLP模块的结构与Transformer中的前馈层相似,包括两个完全连接的层,中间有一个GELU激活)。
下图为普通卷积、深度卷积、点卷积的区别:
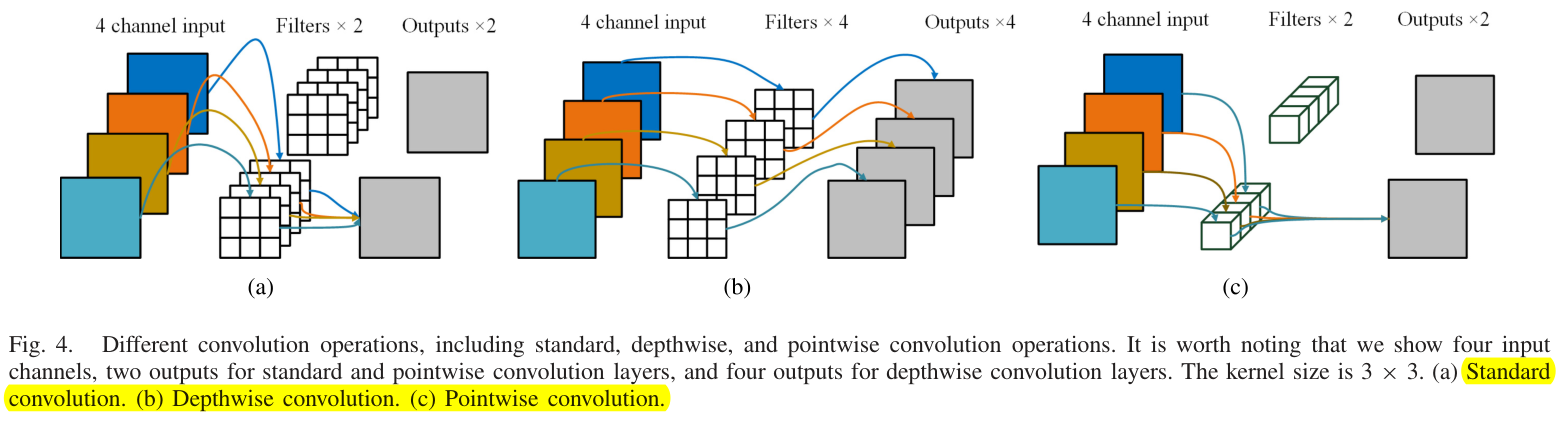
标准卷积运算同时给出了通道和空间计算,深度卷积是一种对每个输入通道使用单一卷积滤波器的空间特征学习运算,而点卷积是一种组合通道的通道特征学习运算。由于光谱信息被嵌入到信道维度中,因此使用点卷积层来捕获光谱信息。总之,深度卷积和点卷积分别用于捕获空间相关性和光谱相关性。Note:本文将深度卷积层FH和FW的大小设置为3 × 1 和1 × 3 。
Experiment
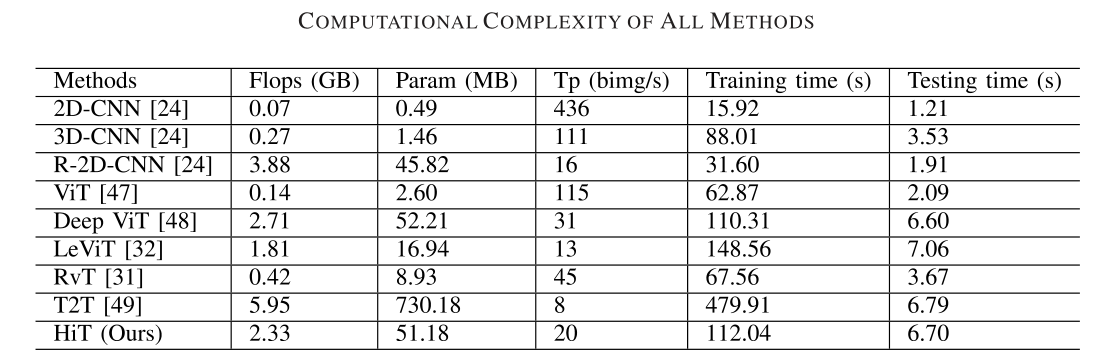
我们选择了几个具有代表性的基线和最先进的骨干方法,包括AEs、RNN、基于CNN的方法(即2-D-CNN、R-2D-CNN、3-D-CNN)和基于Transformer的方法(即ViT、Deep ViT、LeViT和RvT)。比较结果如下:
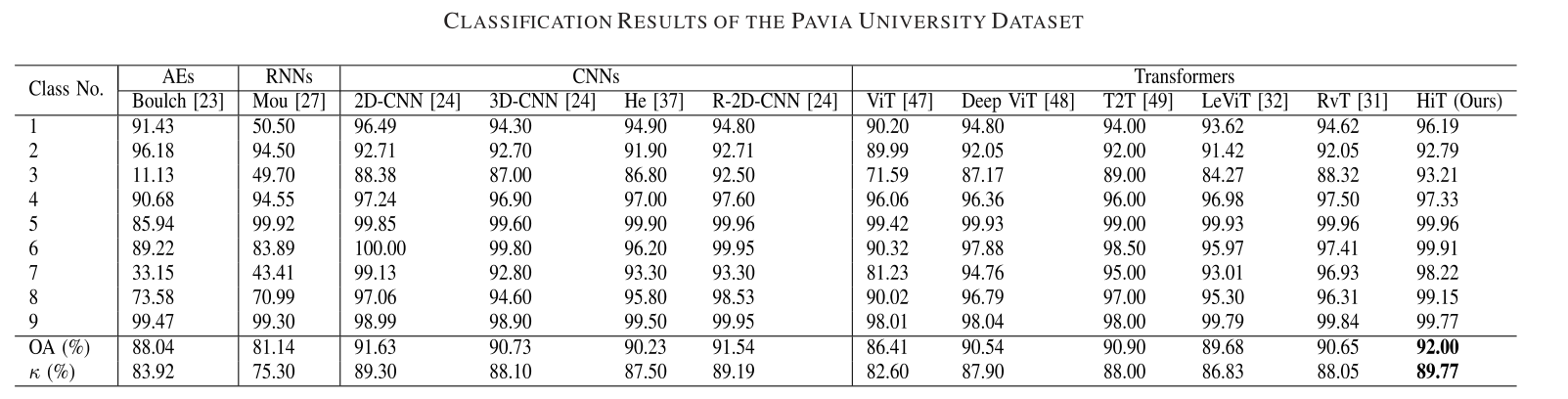
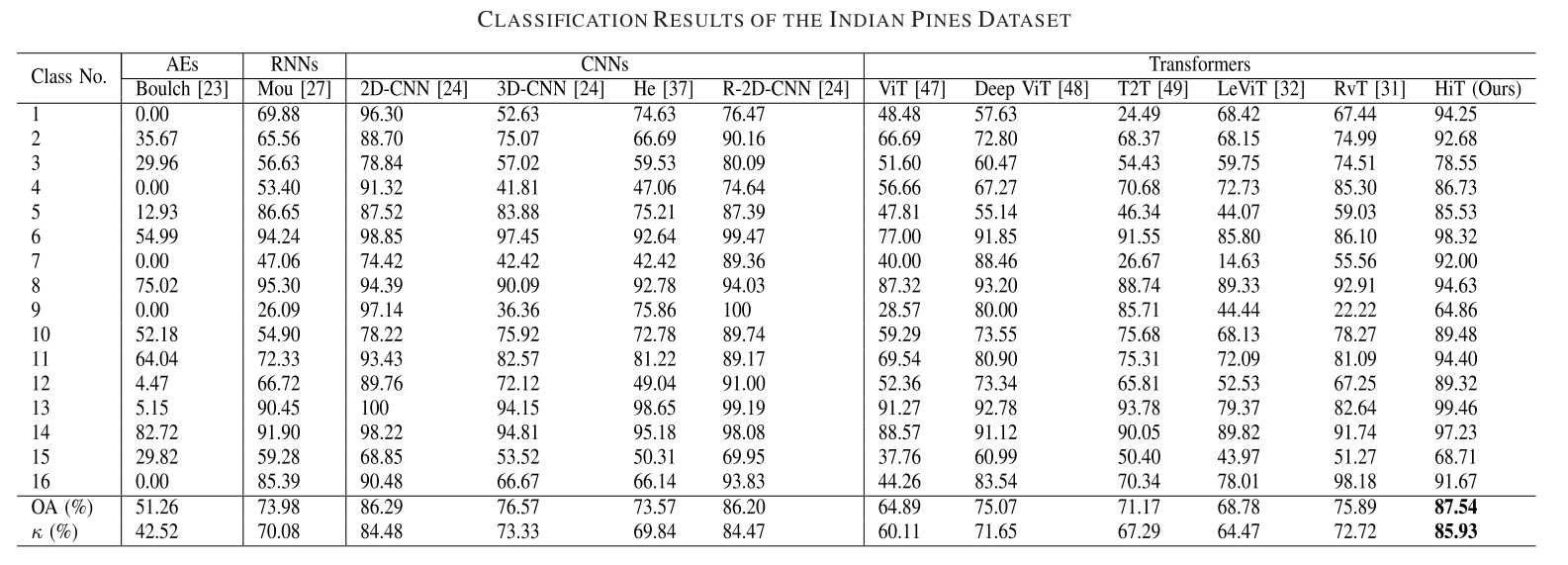

但是对于计算时间而言,提出的HiT方法表现相对于CNN的方法要慢很多。这主要是因为大多数基于Transformer的方法需要许多重复的自注意模块来学习丰富的特征表示。
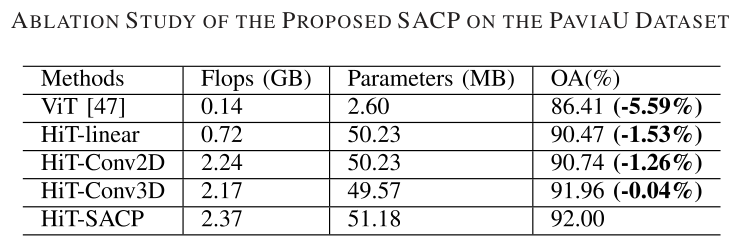
对于SACP模块的消融实验:
Conclusion
提出的HiT由两个解决HSI分类问题的关键模块组成,即SACP模块和Conv-Permutator模块。SACP模块利用两个光谱自适应三维卷积层捕获局部空间光谱信息(特别是细微光谱差异)。光谱自适应三维卷积层由两个分支组成:局部空间分支用于学习空间位置敏感的重要特征图,全局分支用于自适应捕获长期光谱信息。Conv-Permutators分别沿着高度、宽度和光谱维度对空间-光谱表示进行编码,并将编码后的空间-光谱信息传递到下一步。在四个基准HSI数据集上的大量实验表明,提出的HiT优于其它基于Transformer的方法和最先进的基于cnn的方法。未来的工作方向是整合CNN和Transformer的优点,并通过引入先进的技术(如迁移学习和自监督学习)来改进Transformer的架构。具体来说,我们将设计一种通用的、轻量化的、基于Transformer的、更适合HSI分类的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号