Hadoop综合大作业
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
- 在上次爬虫大作业中,我对2019年2月5日上映的电影《新喜剧之王》的评论等信息进行爬取分析,电影主要信息如下:
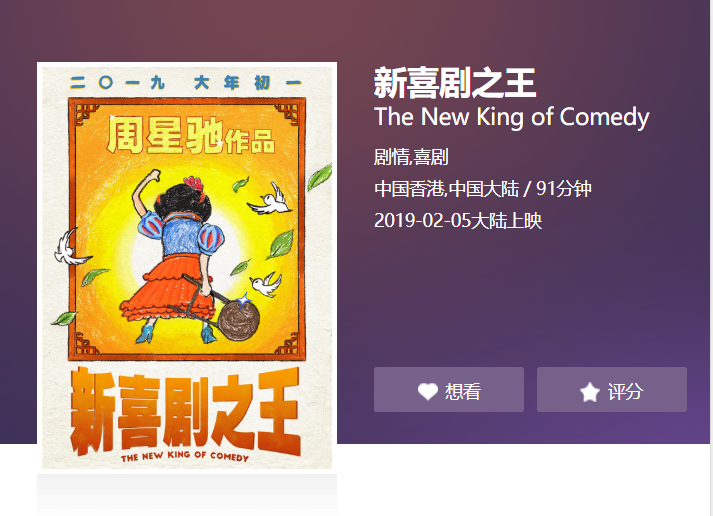
剧情简介:
大型影视基地,胸怀明星梦的女子如梦(鄂靖文 饰)已经在影视圈摸爬滚打了十多年,却依旧还是籍籍无名的龙套演员。平日里,在片场饱受剧组和其他演员的欺凌嘲笑,回到家则被恨铁不成钢的老爹指责,甚至扬言断绝父女关系。然而如梦一律微笑面对,天大的委屈也藏在心中,死皮赖脸地抓住每一个希望渺茫的机会。在此期间,她结识了热衷于跑龙套的李洋,早已过气却自视甚高的童星马可(王宝强 饰),更彻彻底底看清了自己以及爱情的真相。
她是过于平凡的小人物,是一个不该有梦的女孩,是一个直到宇宙灭亡也永远不会得到演戏机会的可悲龙套……
- 对电影评论爬取后,保存了相关的评论的.txt文件以及热词csv文件并生成词云图,如下:
·txt :

·csv:
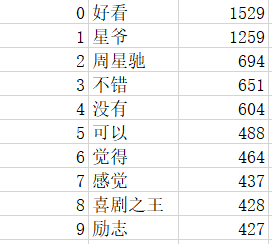
·wordcloud:

- 本次作业为Hadoop综合大作业,主要是用Hive对爬虫大作业产生的进行数据分析,要求如下:
1.将爬虫大作业产生的csv文件上传到HDFS
由于爬虫大作业已将用户的评论等相关信息直接生成为t文本文件,因此此步忽略,所产生的csv文件为热词排行,不做导入;
2.对CSV文件进行预处理生成无标题文本文件
3.把hdfs中的文本文件最终导入到数据仓库Hive中
基本操作如下:
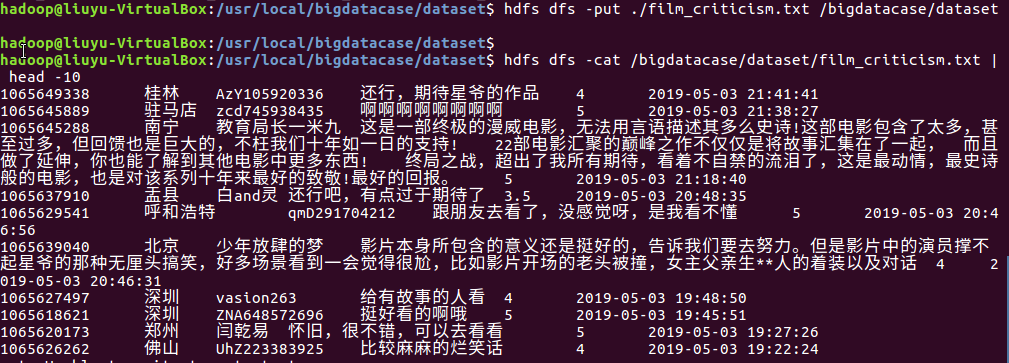
(1)、在HDFS上建立bigdatacase/dataset文件夹,并给予相应的权限:

(2)、将HDFS中的.txt文件上传到HDFS中并查看前10条记录:
(3)、启动数据库和hive:

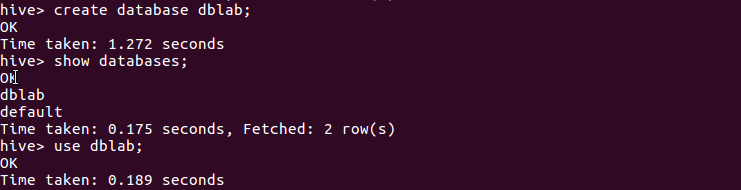
(4)、创建数据库dblab:
(5)、创建外部表bigdata_film,并把HDFS中/bigdatacase/dataset目录中的数据加载到数据仓库HIVE中

表格基本信息如下:
- dblab
- bigdata_film
-id STRING
-province STRING
-uid STRING
-film_crtticisms STRING
-film_score INT
-film_date TIMESTAMP
-TERMINATED BY '\t'
-LOCATION '/bigdatacase/dataset';
4.在Hive中查看并分析数据(列举一条)
显示10条数据:

至此,基本的数据导入已经完成,能够进行查询操作,下一步我将利用相关的查询操作,对数据进行分析并得出分析结果。
5.用Hive对爬虫大作业产生的进行数据分析,描述分析过程和分析结果。
①查看表内有多少条数据
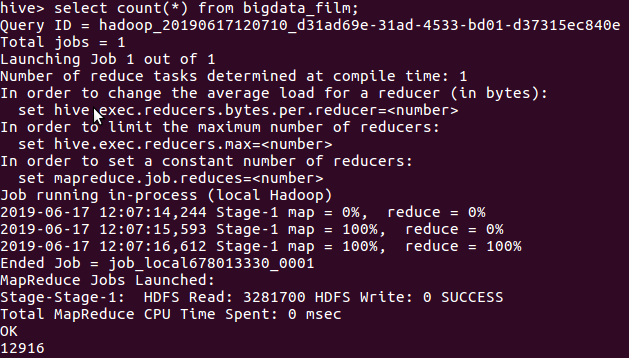
可以看到,一共有12916条数据。
②查看前20位用户对电影的评论和评分情况

从数据上看,前20位用户对于电影的评价以及评分都挺高的,而只有两个人给了2星和0星,表示电影不好看,乱七八糟。
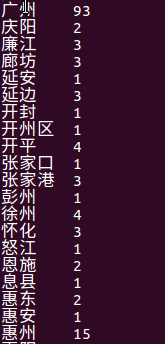
③查看各个城市的评论数


从数据看(部分未截出),大城市的评论人数相对较多,例如广州、惠州、深圳、杭州、武汉、沈阳等地区。
④ 查看有多少人给予4-5星
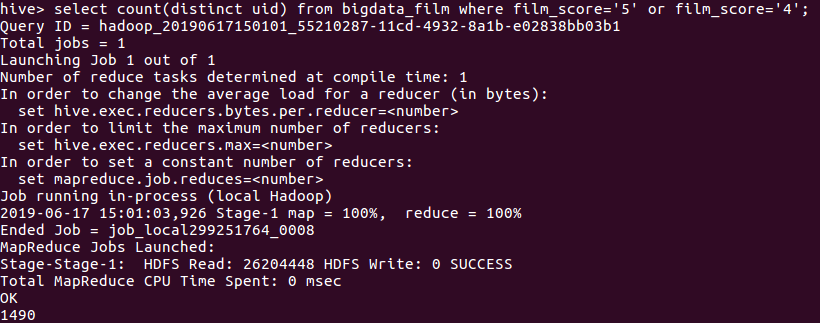
共有1490人对这部电影评分4-5星,占总条数的11%,可见好评率相对较低。
⑤查看有多少人给予0-1星
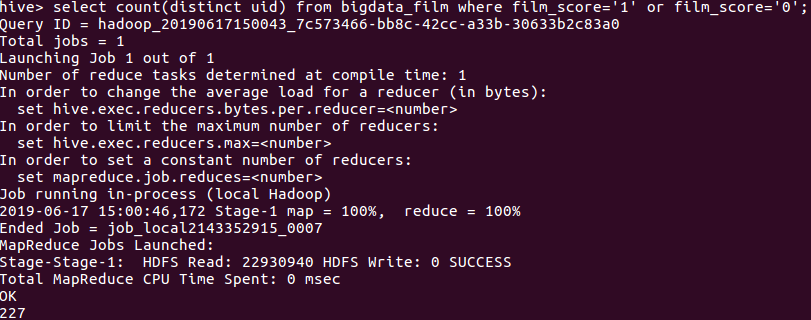
共有227位用户给对这部电影评分0-1星,占总条数1.7%,可见差评率相对较低。
⑥查看前15位评分0-1星的用户的评论

⑦查看前15位评分4-5星的用户的评论

⑧查看不同地区分别有多少用户对电影进行评论
- 总结:
从总体上看,观看《新喜剧之王》的用户大部分集中于大城市较多,这也跟每个城市的发展情况相关,对于电影的评价,好评率要多于差评率,但相对于大部分用户,80%还是选择给与2-3星,对这部电影的评价处于一个中立状态,给与好评的用户主要认为这部电影仍旧延续了星爷一贯的风格,认为这部电影充满笑点,而且在电影最后也存在着转折和泪点,觉得特别好看。而给予差评的用户则认为这部电影完全没意思,全程许多无脑笑点和广告植入,觉得特别烂。从我的观点看,我认为每个人对一部电影的感觉是完全不一样的,每个人在评价一部电影的时候应该站在观众和演员以及电影情节的这几个角度上评价,而不单单从个人的观点出发,总而言之,每一部电影都是每个导演和演员的辛苦付出,我认为《新喜剧之王》这部电影还是不错的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号