爬虫综合大作业
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
作业要求:
- 爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
参考:
爬了一下天猫上的Bra购买记录,有了一些羞羞哒的发现...
Python做了六百万字的歌词分析,告诉你中国Rapper都在唱些啥
分析了42万字歌词后,终于搞清楚民谣歌手唱什么了
十二星座的真实面目
唐朝诗人之间的关系到底是什么样的?
中国姓氏排行榜
三.爬虫注意事项
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
- import time
- import random
- time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
- 首先打开你的浏览器输入:about:version。
- 用户代理:
- 收集一些比较常用的浏览器的user-agent放到列表里面。
- 然后import random,使用随机获取一个user-agent
- 定义请求头字典headers={’User-Agen‘:}
- 发送request.get时,带上自定义了User-Agen的headers
3.需要登录
发送request.get时,带上自定义了Cookie的headers
headers={’User-Agen‘:
'Cookie': }
4.使用代理IP
通过更换IP来达到不断高 效爬取数据的目的。
headers = {
"User-Agent": "",
}
proxies = {
"http": " ",
"https": " ",
}
response = requests.get(url, headers=headers, proxies=proxies)
1 # 获取数据,根据url获取 2 def get_data(url): 3 headers = { 4 5 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' 6 } 7 req = request.Request(url, headers=headers) 8 response = request.urlopen(req) 9 if response.getcode() == 200: 10 return response.read() 11 return None
爬虫主题:分析电影《新喜剧之王》是否有看点

剧情简介:
大型影视基地,胸怀明星梦的女子如梦(鄂靖文 饰)已经在影视圈摸爬滚打了十多年,却依旧还是籍籍无名的龙套演员。平日里,在片场饱受剧组和其他演员的欺凌嘲笑,回到家则被恨铁不成钢的老爹指责,甚至扬言断绝父女关系。然而如梦一律微笑面对,天大的委屈也藏在心中,死皮赖脸地抓住每一个希望渺茫的机会。在此期间,她结识了热衷于跑龙套的李洋,早已过气却自视甚高的童星马可(王宝强 饰),更彻彻底底看清了自己以及爱情的真相。
她是过于平凡的小人物,是一个不该有梦的女孩,是一个直到宇宙灭亡也永远不会得到演戏机会的可悲龙套……
爬取对象:
https://maoyan.com/films/580298
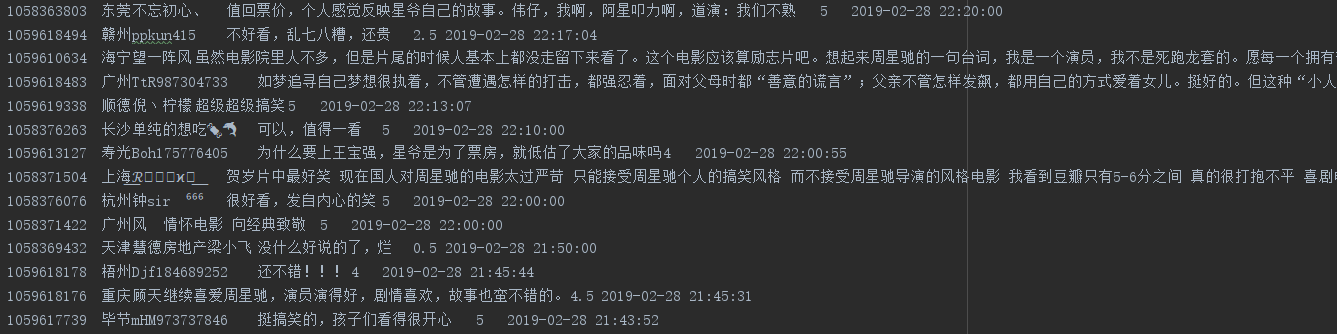
爬取代码(本次爬取了评论中用户ID、用户名、用户所在城市、用户评论、评分分数、评论时间。):
1 def get_data(url): 2 headers = { 3 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' 4 } 5 req = request.Request(url, headers=headers) 6 response = request.urlopen(req) 7 if response.getcode() == 200: 8 return response.read() 9 return None 10 11 #处理接口返回数据 12 13 def parse_data(html): 14 data = json.loads(html)['cmts'] # 将str转换为json 15 for item in data: 16 comment = { 17 'id': item['id'], 18 'nickName': item['nickName'] if 'nickName' in item else '', # 处理nickName不存在的情况 19 'cityName': item['cityName'] if 'cityName' in item else '', # 处理cityName不存在的情况 20 'content': item['content'].replace('\n', ' ', 10), # 处理评论内容换行的情况 21 'score': item['score'], 22 'startTime': item['startTime']if 'startTime' in item else '' 23 } 24 comments.append(comment) 25 return comments 26 27 if __name__ == '__main__': 28 for d in range(10): 29 for i in range(40): 30 comments = [] 31 html = get_data('http://m.maoyan.com/mmdb/comments/movie/580298.json?_v_=yes&offset={}&startTime=2019-03-{}%2022%3A25%3A03'.format(i*15, d)) 32 comments = parse_data(html) 33 for item in comments: 34 with open('film_criticisms.txt', 'a', encoding='utf-8') as f: 35 f.write(str(item['id']) + '\t' + item['cityName'] + '\t' + item['nickName'] + '\t' + item['content'] + '\t' + str(item['score']) + '\t' + 36 item['startTime'] + '\n') 37 print('爬取第{}页'.format(i)) 38 print(comments)
爬取结果:
数据分析:
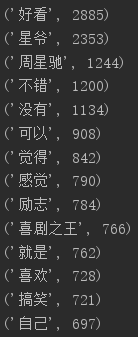
获取用户评论中热词
1 comments = [] 2 with open('film_criticisms.txt', mode='r', encoding='utf-8') as f: 3 rows = f.readlines() 4 for row in rows: 5 try: 6 comment = row.split('\t')[3] 7 if comment != '': 8 comments.append(comment) 9 except:# 预防出现list[index]的index超出范围的情况 10 print('这一条有误:'+ comment) 11 continue 12 13 14 15 16 17 18 pl = ' '.join(comments) 19 print(' '.join(comments)) 20 21 ci = ['。', ' ', '我们', '知道', '看到', '自己', '起来', '什么', '他们', '一个', '看着', '没有', '看看', '就是', '怎么', '还是', '这么', '觉得', '电影'] 22 23 for c in ci: 24 myText = pl.replace(c, "") 25 26 '''分割出词汇''' 27 words = list(jieba.cut(myText)) 28 wordDict = {} 29 30 '''统计频率次数''' 31 wordSet = set(words) 32 for w in wordSet: 33 if len(w) > 1: 34 wordDict[w] = words.count(w) 35 36 '''排序''' 37 wordList = list(wordDict.items()) 38 wordList.sort(key=lambda x: x[1], reverse=True) 39 40 '''输出top20''' 41 for i in range(20): 42 print(wordList[i])
结果如下:
生成词云(由于无法导入imread包,因此我将数据放至wordart描绘词云):
1 import matplotlib.pyplot as plt 2 from wordcloud import WordCloud 3 from scipy.misc import imread 4 5 6 wc =WordCloud(background_color="white", mask=imread('xiju.jpg'), max_words=2000,font_path="C:\Windows\Fonts\simkai.ttf", 7 max_font_size=60, random_state=30) 8 myWord = wc.generate(pl) 9 wc.to_file('result.jpg') 10 plt.imshow(myWord) 11 plt.axis("off") 12 plt.show()
词云生成地址:https://wordart.com/create
词云如下:
原图: 词云显示图:


完整代码:
总结:
- 《新喜剧之王》极具周星驰以往所释演的角色的风格,主角从一个不起眼、被欺负、被凌辱的小人物到实现理想的褪变。但与以往又有所不同,片中每次引发我们开怀大笑的背后,隐藏着一个又一个的辛酸的真实故事。
- 这部片把社会的丑恶拼凑成一盘菜,拍的太真实,没有了以前那种天马行空的感觉,搞笑也没那么多,更多的是在表达小人物的艰辛,跟全世界的人都看不起你,打击你的时候,只有你的父母是真正关心你的人。
- 希望观影的观众能够真正去理解这一部电影要解释的内容,而非一味的寻找笑点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号