整理--数据类型,文件操作
绝对路径和相对路径:
1. 绝对路径:从磁盘根目录开始一直到文件名.
2. 相对路径:同一个文件夹下的文件. 相对于当前这个程序所在的文件夹路径. 如果在同一个文件夹中. 则相对路径就是这个文件名. 如果在上一层文件夹. 则要../
我们更推荐大家使用相对路径. 因为在我们把程拷贝给别人使用的时候. 直接把项目拷贝走就能运行. 但是如果用绝对路径. 那还需要拷贝外部的文件
文件操作
追加读(a+)
a+模式下, 不论先读还是后读. 都是读取不到数据的.
with open("S10_Globe_v1.00.txt","a+") as f: f.write("aaaaaaaaaa") a = f.read() print(a) # 打印内容为空
使用seek都是移动到开头或者结尾
通常我们使用seek都是移动到开头或者结尾.
移动到开头: seek(0)
移动到结尾: seek(0,2) seek的第一个参数表示的是从哪个位置进行偏移, 默认是0, 表示开头, 1表示当前位置, 2表示结尾
with open("S10_Globe_v1.00_test.conf.src.txt","r+") as f: f.write("aaaaaaaaaa") a = f.read(10) b = f.tell() #打印光标的位置 print(a,b) # export tz_ 20 读取是个字符,光标的位置在20,
深坑请注意: 在r+模式下. 如果读取了内容. 不论读取内容多少. 光标显示的是多少. 再写入或者操作文件的时候都是在结尾进行的操作.所以如果想做截断操作. 记住了. 要先挪动光标. 挪动到你想要截断的位置. 然后再进行截断
![]()
![]()
关于truncate(n), 如果给出了n. 则从开头进行截断, 如果不给n, 则从当前位置截断. 后面的内容将会被删除

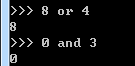
逻辑运算
1, 在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往
右计算。
判断下列逻辑语句的True,False
x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。

编码
python2解释器在加载 .py 问件中的代码时,会对内容进行编码(默认ascill),在python3对内容进行编码的默认为utf-8
while 条件:
循环体
else: 循环在正常情况跳出之后会执行这句
注意: 如果循环是通过break退出的. 那么while后面的else将不会被执行, 只有在while条件判断是假的时候才会执行这个
else
整数(int)
整数可以进⾏的操作:
bit_length(). 计算整数在内存中占用的二进制码的长度
布尔值(bool)
int => bool bool(int). 0是False 非0是True
bool=>int int(bool) True是1, False是0
str => bool bool(str) 空字符串是False, 不空是True
bool => str str(bool) 把bool值转换成相应的"值"
字符串
首字母大写: ret = s1.capitalize()
大小写转换: ret = s1.swapcase()
每个被特殊字符隔开的字母首字母大写 ret = s3.title()
可以改变\t的长度, 默认长度更改为8
s1 = "alex wusir\teggon"
s1.expandtabs()
s11 = "银王哈哈银王呵呵银王吼吼银王"
lst = s11.split("银王") # ['', '哈哈', '呵呵', '吼吼', ''] 如果切割符在左右两端. 那么一
定会出现空字符串.深坑请留意
s1.startswith("sylar") # 判断是否以sylar开头
s1.endswith("语言.") # 是否以'语言.'结尾
ret = s1.find("tory") # 查找'tory'的位置, 如果没有返回-1
ret = s1.index("sylar") # 求索引位置. 注意. 如果找不到索引. 程序会报错
# 条件判断
s14 = "123.16"
s15 = "abc"
s16 = "_abc!@"
# 是否由字母和数字组成
print(s14.isalnum())
print(s15.isalnum())
print(s16.isalnum())
# 是否由字母组成
print(s14.isalpha())
print(s15.isalpha())
print(s16.isalpha())
# 是否由数字组成, 不包括小数点
print(s14.isdigit())
print(s14.isdecimal())
print(s14.isnumeric()) # 这个比较牛B. 中文都识别.
print(s15.isdigit())
print(s16.isdigit()
负数转成正数
s17 = "-123.12" s17 = s17.replace("-", "") # 替换掉负号
s17.count(".") == 1 有小数点=1,表示是小数
元组
元组和元组嵌套
元组: 俗称不可变的列表.又被成为只读列表, 元组也是python的基本数据类型之一, 用小括号括起来, 里面可以放任何数据类型的数据, 查询可以. 循环也可以. 切片也可以. 但就是不能改.
关于不可变, 注意: 这里元组的不可变的意思是子元素不可变. 而子元素内部的子元素是可以变, 这取决于子元素是否是可变对
字典
dic = {"id": 123, "name": 'sylar', "age": 18, "ok": "科比"}
print(dic.items())
for key, value in dic.items():
print(key, value)
# dict_items([('id', 123), ('name', 'sylar'), ('age', 18), ('ok', '科比')])
# id 123
# name sylar
# age 18
# ok 科比
is 和 == 区别
小数据池
# 数字小数据池的范围 -5 ~ 256
# 字符串中如果有特殊字符他们的内存地址就不一样
# 字符串中单个*20以内他们的内存地址一样,单个*21以上内存地址不一致
is 比较内存地址
id() ---- 获取内存地址
小数据池:
数字的小数据池范围是 -5 ~ 256
字符串:
字符串中不能包含特殊符号 + - * / @ 等等
字符串单个字符*20以内内存地址都是一样的,单个字符*21以上内存地址不一致
注意: pycharm是个坑, 一个py文件中所有相同的字符串 一般都是使用一样的内存地址
== 比较俩边的值
![]()

将一个列表里面的元素拼接成一个字符串



循环删除列表中的每一个元素
l = [11,22,33,44] for i in l: l.remove(i) print(l) #[22, 44]
使用
del l[i] l.pop()
这两个方法同样不行.
分析原因:
for的运行过程. 会有一个指针来记录当前循环的元素是哪一个, 一开始这个指针指向第0个. 然后获取到第0个元素. 紧接着删除第0个. 这个时候. 原来是第一个的元素会自动的变成第0个. 然后指针向后移动一次, 指向1元素. 这时原来的1已经变成了0, 也就不会被删除了
只有这样才是可以的:
#正确实例 for i in range(len(l)): l.pop() print(l) # []
dict中的fromkey(),可以帮我们通过list来创建一个dict
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"]) print(dic) 结果: {'jay': ['周杰伦', '麻花藤'], 'JJ': ['周杰伦', '麻花藤']}
注意:
dic = dict.fromkeys(["1","2"],["kk","ll"]) print(dic) #{'1': ['kk', 'll'], '2': ['kk', 'll']} dic.get("1").append("mm") print(dic) #{'1': ['kk', 'll', 'mm'], '2': ['kk', 'll', 'mm']}
代码中只是更改了jay那个列表. 但是由于jay和JJ用的是同一个列表. 所以. 前面那个改了. 后
面那个也会跟着改
dict中的元素在迭代过程中是不允许进行删除的
dic = {'k1': 'aaaa', 'k2': 'bbb', 's1': '⾦⽼板'}
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
del dic[k] # dictionary changed size during iteration, 在循环迭
代的时候不允许进⾏删除操作
print(dic)
那怎么办呢? 把要删除的元素暂时先保存在一个list中, 然后循环list, 再删除
dic = {'k1': 'aaaa', 'k2': 'bbb', 's1': '金老板'}
dic_del_list = []
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
dic_del_list.append(k)
for el in dic_del_list:
del dic[el]
print(dic)
类型转换
a = (1,2,3,) b = list(a) #元组 转 列表 print(b) #[1, 2, 3] c = tuple(b) #列表 转 元组 print(c) #(1, 2, 3) e = set(b) #列表 转 集合 print(e) f = list(e) #集合 转 列表 print(f)
b = ["aa","bb","c"]
d = ",".join(b) #列表 转 成字符串 注意列表的元素一定要是字符串,不能是整数
print(d)
set集合
set中的元素是不重复的.无序的.里面的元素必须是可hash的(int, str, tuple,bool),
set集合中的元素必须是可hash的, 但是set本身是不可hash得. set是可变的.
增加
1 -----s.add("aaa")
2 -----可迭代更新
set1 = {1,2,3}
dict1 = {'name':"BGWAN",'age':22}
set1.update(dict1)
print(set1) #{1, 2, 3, 'age', 'name'} 去掉了value
set2 = {4,5,6}
set3 = {5,6,7,'890'}
set2.update(set3)
print(set2) #{4, 5, 6, '890', 7}
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s) #{'麻', '关之琳', '王祖贤', '藤', '花', '刘嘉玲'}
s.update(["张曼", "李若彤","李若彤"])
print(s) #{'李若彤', '麻', '关之琳', '王祖贤', '张曼', '藤', '花', '刘嘉玲'}
这里我们想到一个函数set(),将元素强制集合化,即先将字符串、元组、列表转化成了集合,然后再进行添加更新。要注意的是:非集合元素内容必须是可迭代类型,‘int’类型就不可以,将1放进括号内就会报错。
我们再往深里想,若像列表内又嵌套了列表或集合或元组等类型时会怎么样呢?
set1 = {1,2,3}
list2 = [1,2,(7,9)] #元组
set1.update(list2)
print(set1) #{1, 2, 3, (7, 9)}
set = {1,2,3}
list = [[6,5],[9,7]] #列表
set.update(list)
print(set) #报错
这里结果会报错,TypeError: unhashable type:list,类型错误,不可拆卸类型,也叫不可哈希。出现这种异常是因为在使用set()过程中,set()传递进来的是不可哈希的元素,而列表嵌套内部由于不分解,要被当做集合内的元素,必须是可哈希的
可哈希的元素有:
int、float、str、tuple
不可哈希的元素有:
list、set、dict,
那么里面嵌套的类型不能是这三种
为什么列表是不可哈希的,而 元组是可哈希的:
(1)因为 list 是可变的,可以在任意改变其内的元素值。
(2)元素可不可哈希,决定是否使用 hash值 进行索引
(3)列表不使用 hash 进行元素的索引,自然它对存储的元素没有可哈希的要求;而 se集合使用 hash 值进行索引。
删除
s.pop() # 随机弹出一个
s.remove("aaa") # 直接删除元素
s = {"11","22","33","44","55","66"}
a = s.pop() #随机删
print(a)
a = s.pop()
print(a)
s.remove("44")
print(s) #直接删除元素,如果元素不存在,删除会报错
s.clear() #清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和dict区分的.
print(s) # set()
print(dic.clear()) # None 直接清空字典打印的是None
修改
# set集合中的数据没有索引. 也没有办法去定位一个元素. 所以没有办法进行直接修改.
# 我们可以采用先删除后添加的方式来完成修改操作
常⽤操作
s1 = {"aa","bb","cc","dd"}
s2 = {"11","22","33","dd"}
# 交集 ------两个集合中相同的元素
print(s1 & s2) # {'dd'}
print(s1.intersection(s2)) # {'dd'}
# 并集 ----------两个集合的所有元素,去掉重复的
print(s1 | s2) # {'11', 'dd', 'aa', 'cc', '22', '33', 'bb'}
print(s1.union(s2)) # {'11', 'dd', 'aa', 'cc', '22', '33', 'bb'}
#差集------前一个相对于后一个的差集
print(s1 - s2) # {'aa', 'cc', 'bb'} s1 相对于 s2的不同
print(s1.difference(s2)) # {'aa', 'cc', 'bb'}
print(s2 - s1) # {'22', '11', '33'} s2 相对于 s1的不同
print(s2.difference(s1)) # {'22', '11', '33'}
# 反交集 ------ 两个集合中单独存在的数据
print(s1 ^ s2) # {'11', 'cc', 'bb', 'aa', '22', '33'}
print(s1.symmetric_difference(s2)) # {'11', 'cc', 'bb', 'aa', '22', '33'}
s3 = {"aa","bb","cc"}
#一个集合是另一个集合的子集
print(s3 < s1) # True
print(s3.issubset(s1)) # True
#超集
print(s1 > s3) # True
print(s1.issuperset(s3)) # True
print(s1 < s3) # False
print(s3.issuperset(s1)) # False
深浅拷贝
深浅拷贝(难点)
1. 赋值. 没有创建新对象. 公用同一个对象
2. 浅拷贝. 拷贝第一层内容. [:]或copy()
3. 深拷贝. 拷贝所有内容. 包括内部的所有.
1. 赋值. 没有创建新对象. 公用同一个对象
2. 浅拷贝. 拷贝第一层内容. [:]或copy()
3. 深拷贝. 拷贝所有内容. 包括内部的所有.
赋值
l1 = ["aa","bb","cc","dd"] l2 = l1 print(l1) #['aa', 'bb', 'cc', 'dd'] print(l2) #['aa', 'bb', 'cc', 'dd'] l1.append("11") print(l1) #['aa', 'bb', 'cc', 'dd', '11'] print(l2) #['aa', 'bb', 'cc', 'dd', '11'] dic1 = {"id": 123, "name": "aaa"} dic2 = dic1 print(dic1) #{'id': 123, 'name': 'aaa'} print(dic2) #{'id': 123, 'name': 'aaa'} dic1["name"] = "ccc" print(dic1) #{'id': 123, 'name': 'ccc'} print(dic2) #{'id': 123, 'name': 'ccc'}
对于list, set, dict来说, 直接赋值. 其实是把内存地址交给变量. 并不是复制⼀份内容. 所以.
lst1的内存指向和lst2是一样的. lst1改变了, lst2也发生了改变
浅拷贝
l1 = ["aa","bb","cc","dd"] l2 = l1.copy() print(l1) # ['aa', 'bb', 'cc', 'dd'] print(l2) # ['aa', 'bb', 'cc', 'dd'] print(id(l1),id(l1)) #5896752 5886752 内存地址不一样 # 结果: # 两个lst完全不⼀样. 内存地址和内容也不⼀样. 发现实现了内存的拷贝
l1 = ["aa","bb","cc","dd",["11","22"]] l2 = l1.copy() l1[4].append("33") print(l1) # ['aa', 'bb', 'cc', 'dd', ['11', '22', '33']] print(l2) # ['aa', 'bb', 'cc', 'dd', ['11', '22', '33']] print(id(l1[4]),id(l2[4])) #6567456 6567456 内存地址一样
浅拷贝. 只会拷贝第一层. 第二层的内容不会拷贝. 所以被称为浅拷贝
深拷贝
#深拷贝 import copy l1 = ["aa","bb","cc","dd",["11","22"]] l2 = copy.deepcopy(l1) l1[4].append("333333") print(l1) # ['aa', 'bb', 'cc', 'dd', ['11', '22', '333333']] print(l2) # ['aa', 'bb', 'cc', 'dd', ['11', '22']] print(id(l1[4]),id(l2[4])) # 7311568 7312488 不一致
都不一样了. 深度拷贝. 把元素内部的元素完全进行拷贝复制. 不会产生一个改变另一个跟着
改变的问题
最后我们来看一下题目:
a = [1,2] a[1] = a print(a[1]) #[1, [...]]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号