

镇楼图

pixiv: torino
一、介绍
数据库系统的组成
数据库系统是特殊的计算机系统,目的即存储、处理数据。数据库系统主要由硬件、数据、软件、用户组成。其中数据尤为重要
数据具有以下特点
■集成:数据可合并且具有较少的冗余
■共享:数据可给不同用户访问
■持久:可长期存储
用户一般分为三类用户
■应用程序员:负责编写数据库的应用程序
■最终用户:通过应用访问数据库使用相关功能
■数据库管理员(DBA)数据管理员(DA)
一般会采用用户——客户端——服务器——数据库的模式来完成应用
数据独立性
数据独立性分为物理独立性和逻辑独立性
物理独立性是指避免应用程序依赖于数据的物理结构
逻辑独立性是指避免应用程序依赖于数据的逻辑结构
独立性低的数据库会导致应用程序经常因为数据结构的变动而变动,导致效率低下且难以改变
ANSI/SPARC体系结构
为了达到数据独立性的目的,一般采用三层结构达到较高的数据独立性
■内部层(存储层,Internal Level):数据的物理存储方式,分离出物理结构
■概念层(公共逻辑层,Conceptual Level):中间层次,用于表示数据的结构
■外部层(用户逻辑层,External Level):视图,分离出逻辑结构
关系上内部层←→概念层←→外部层。其中外部层可具有多个以存在多种逻辑结构供不同应用使用
而这种关系称为映像,为数据独立性提供了保证,映像分为两种
■概念模式/内模式:保证物理独立性
■外模式/概念模式:保证逻辑独立性
二、关系数据模型
关系模型
关系数据库是目前主流数据库的一种,它最大的特点在于有数学理论撑腰显得比较科学。尽管有些方面目前并不是那么常用,但作为比较重要的数据库模型,依然需要了解,以下内容需要读者具备离散数学基础,最好有集论基础。
首先常常会说到关系和表,在某种程度上它们是完全一样的,但从数学上来说是完全不同的定义。表和关系之间存在着一种规则使得可以相互转换,使得看上去它们类似。
关系是什么?
熟悉集论的知道关系是笛卡尔积的子集,但在数据库中关系常常会更复杂些。
定义:
(标题也称为表头,定义了主体元素(元组)的类型)
数据库中的关系其数学模型非常复杂,但另一方面因为能用数学描述显得逻辑清晰
定义中一个很重要的概念——类型。类型不只是数据库中有,编程语言甚至针对类型分成了强类型和弱类型语言,后续会详细说明。
标题是在数据库中的列头,有列名也有类型名指向一个类型。比如出生日期+时间类型,就是一个列名表示了语义,类型名指向了类型
而主体则是数据库中的主要内容,主体的一个元素在数据库中就是一行
关系变量是最基本的数据,它也有相关的运算法则,后续会详细说明
基本关系变量是指在概念层上的关系变量,导出关系是通过运算得到的关系。关系的运算会从关系得到关系
SQL是关系数据库的标准,它的内容非常复杂,有很多关系数据库软件并不会完全照搬SQL,会有很多SQL所没涉及的内容,因此SQL的方言非常多,但国内主要用的关系数据库基本是MySQL。SQL的基本功能主要是定义关系变量(DDL)、运算关系变量(DML)、目录(Catalog)、模式(Schema)、视图、事务。而拓展功能主要是结合了程序语言,有嵌入式SQL、动态SQL、SQL/CLI等。SQL的基本特点是大部分都是非过程化的,而拓展则是增强了过程化的功能
类型
类型简单来说就是数据类型,它有系统内置类型,也有用户定义类型。大部分情况下都会存在,比如C语言有bool、int之类的内置类型,也有struct用户自定义的,在数据库中也是如此
比较复杂的是类型转换,强类型语言中有隐式转换,从数据范围小的变成数据范围大的(从定义上是指类型的域从子集拓展至其超集),也有弱类型语言特别复杂的转换规则(如果稍有不慎没有做类型校验可能还会被坑,比如b站21年引发的系统故障),Java中的装箱拆箱本质上就是类型自动转换(箱是指对象类型)
不同类型具有不同的运算,比如数字都是加减乘除,而字符串的运算是比较拼接之类的,如果是用户自定类型有的时候可能需要用户自行编写函数来定义运算。运算一般会尽量保证类型是不变的,但不绝对,隐式转换就是一个例子。
类型从约束的角度来看,它实际上是限制在了域中,所有值必须是域的元素,因此这样的最基本的约束也称为类型约束
类型有两类,一类是标量(scalar)就是指原子的类型(如int,double),另外一类是非标量(noscalar)就是指由类型组成的类型,可以简单理解为结构体,里面有很多分量
在定义关系变量的类型时实际上是定义非标量,里面可以有很多类型不同的分量。比如学生里面有学号、姓名就是一个非标量的类型
SQL官方支持的标量类型有布尔、数值、字符串、二进制、位串、时间等
元组(记录)
关系变量中类型是要表达的数据类型,而主体则是类型相应的数据
主体中的元素称为元组或记录
定义: (熟悉集论的知道有序元组是由无序元组构成的其实就是也就是)
其中一个元组由多少组成变称为这个元组是几元(度,目)的。子集称为是属性(或列)
元组具有以下非常显而易见的性质
■由定义得属性只有唯一值
■集合的元素是无序的,因此列之间是无序的
关系类型是指关系中的标题(表头),关系类型是非标量类型
关系的性质
■属性间是无序的(由集合元素的无序性可得)
■元组间是无序的(由集合元素的无序性可得)
■无重复元组(由集合元素的互异性可得)
■每个属性只有唯一值(这一点常常会描述成属性是原子的,但这不对,后面会说明)
关系的运算
元组相等:元组当且仅当
元组不相等,即不满足元组相等的条件
关系上有属于、不属于、包含或不包含的运算(其实就是集合的基本运算,这里不再说明)
关于关系为空,它可能会产生歧义。关系为空不代表是空集。如果关系是空集就不是关系的定义了。关系无元组常常是代表关系为空的准确定义,这也符合实际情况。也有另外的说法是指关系类型为空集,但一般不会这么描述
SQL的数学理论前提是关系代数、关系演算。
关系代数
关系代数由一组运算的集合组成,关系由于是由类型和元组组成的,它对针对两个集合进行运算
分为两类运算,一类是传统的集合运算,另外一类是专门的运算
关系封闭性:之前已经说过,其实是指关系经过运算后依然能得到关系
关系类型推演规则:根据输入的关系类型,操作后可推得输出的关系类型
传统的集合运算:
■并:(A、B关系类型必须相同)
■交:(A、B关系类型必须相同)
■差:(A、B关系类型必须相同)
■笛卡尔积:
传统的集合运算相当简单,SQL也支持并、交、减的运算,笛卡尔积是另外使用特殊的select复合的运算符进行的
专门的关系运算:
■选择:(即过滤不满足条件F的元组)
■投影:(即筛选出子集A的投影)
■连接:(其中θ表示比较选择符,即满足条件的笛卡尔积)若A和B无共同属性,相当于笛卡尔积,若仅有共同属性,相当于交集
■除法:
所谓除法是笛卡尔积的逆运算,除法会生成R中S之外的投影
相关运算性质以及一些复合性的运算(如半差、半连接等)这里不再赘述
其他特殊运算(不会具体介绍,有些内容SQL并不能实现):
■分组:,会根据R关系中X以外的元组子集为单位根据值是否相等来分组,X属性内常会有多个属性值
■解组:,对R关系中X属性进行解组
■扩展:,在R关系后添加X属性
关系演算
SQL除了关系代数作理论基础外,关系演算也是其中一部分。关系演算主要用到了数理逻辑。主要分为元组演算和域演算,元组演算即对行,域演算即对列。
范围变量:是指限制在取值范围的变量
元组演算:(选择关系的属性相当于投影,然后执行命题)
在谓词逻辑的命题中,除了基本的命题还有量词的约束,这一点在SQL中也支持,即all和exists
SQL中的select语句结合了关系代数、关系演算两个理论基础
select 选择的范围变量(相当于投影)
from 关系变量(可用连接操作)
where 命题(可包含量词)
/*已忽略其他内容*/
完整性约束
完整性是为了防止合法用户因误操作导致的异常。它的本质其实就是一组命题,一般会进行检查,若不满足则会禁止执行以防止异常。检查通常会是预先定义后,再检查来判断;所谓预先定义其实是一种预先输入,输入了后要提交才能真正输入数据进去,比如SQL Server输入记录时必须要全部输入完才能提交,这实际上是为了检查。
此外完整性和正确性并不相同,完整性不一定正确,某种意义上数据库系统无法保证正确性,一切都要人为判断。比如设置了不合理的命题,系统会保证命题一定为真,但为真的命题不一定正确。
所谓约束就是保证完整性的命题,约束的本质是缩小取值范围到合理且人为判断是正确的命题。约束大体上有两类,一类是静态性的约束,一类是动态性的约束。SQL并不能很好地支持动态性的约束,因此关于动态性方面的约束可能有些操蛋。
在属性间的约束简单来说就是各种码
码
候选码:若属性集K具有唯一性、不可约性则称为关系的候选码。若K只有一个属性,则称为简单候选码,否则称为复合候选码
唯一性:
不可约性:也称为最小性,是指K的真子集不存在具有唯一性的可能,保证候选码是最小的属性集
超码:候选码的超集,超码具有唯一性但不具有不可约性
主码:多个候选码之间选取其一则称为是主码,因为具有唯一性可以当作标识元组的ID。“以简便性为选取原则,但这是在关系模型研究之外的。”
外码:是指不同关系的元组间构成的联系。有候选码,有属性集,若类型相同(不需要考虑属性名),且的值为中分量的值中的一个或为空,则称FK是CK的外码。外码是对候选码的参照,外码的规则实际上是参照完整性,即某一关系属性集的值为空或另一关系候选码的值。
这种参照关系抽象出来即为联系,它指关系间的某种联系,而联系的具体语义是由用户自定的。如R→S→P即P的外码是由S的候选码决定,但同时S的外码是由R的候选码决定。这种参照关系可用图论解释。参照路径是指外码所形成的“参照链”。但是参照路径也可能形成回路,参照性的约束是关系间的约束。如果关系的候选码发生变化,那么相应的外码也应当发生变化,否则会导致外码不满足规则的情况。但是如何变化,存在相关规则,这种规则在任何操作都需要考虑到,称为参照行为。
参照行为有以下三种情况
■restrict:只有不存在相应元组时才操作,否则拒绝
■cascade:级联操作,即操作前先操作参照的关系
■no action:默认情况,可能违反外码规则
触发器
触发器是为了实现动态的约束,简单来说就是if-else,但语法看上去会非常复杂
触发器执行过程:触发→执行→检查完整性
组成(ECA):事件、条件、动作
触发时间:before→开始事务→after/instead of
create trigger 触发器名
before | after
事件 on 关系名
insert | delete | update
for each row(行级多次) | for each statement(一次性)
触发时间
布尔表达式
触发器的缺点:
■触发器并发执行时无法确定先后顺序
■可能引发触发链,即可能导致触发后再触发其他触发器甚至可能死循环触发
视图
视图是虚关系变量,即保留关系表达式,只有使用时才会代入
相当于定义一个函数
视图提供了集成性、逻辑独立性、安全性等优点
逻辑独立性更准确地说是分为可成长性(可增加新的属性、关系)和可重构性(重构后可保证视图不变)
视图检索:在查询上,视图可以像正常关系变量一样直接用select。并且因为视图的简化,也更容易编写
视图更新:视图更新在一般情况下是无法执行的,具体情况如下
更新即insert、delete或update,相当于一个函数,假设视图的函数为
若要更新相当于执行,但实际上更新的不是视图而是要更新
也就是,要作用于上,在上则要执行即需要找到逆函数
但这可能无法找到,因此视图更新依赖于数理基础可能无法实现
另外如果关系足够多,比如,若要视图更新实质上是更新元组的一部分,这直接违反了更新要更新一整个元组的规定
若要完成视图更新,限制过多,一般不太可能支持视图更新或者只有少部分情况支持
三、传统意义的关系数据库范式
范式
范式是指遵循一些规定的特殊关系的集合,但目前意义上讨论的范式是比较古老的,可能只有理论价值。这里只会说明1NF、2NF、3NF、BCNF、4NF和5NF的体系。
Codd提出了1NF、2NF、3NF
Codd和Boyee共同提出了BCNF
Fagin提出了4NF、5NF
在这种体系下规范化的本质就是投影,且规范化是可逆的,它极其依赖语义,但并不会讨论语义如何产生
无损分解
无损分解是这种范式体系下最基础的概念
无损性:投影是规范化的操作,而其逆操作连接则是反范式化,也同样重要。无损即关系规范化后再反范式化依然是等价的
函数依赖(FD)
函数依赖是比较基础性的依赖,实质上有非常多的依赖,这里主要讨论函数依赖、多值依赖和连接依赖
依赖是指属性集之间关系
函数依赖定义:若属性集X到属性集Y具有多9对一或一对一的关系则记作,称为Y依赖于X,或X决定Y其中。X称为自变量,Y称为应变量。属性集是关系属性集的子集
(1)若为候选码,则决定的任意属性集的子集
(2)若,则(蕴含)
(3)若,则(传递)
函数依赖集:某关系函数依赖的集合
平凡函数依赖:应变量⊆自变量
闭包:所蕴含的所有的函数依赖
Armstrong公理:
■自反律:若,则
■增广律:若,则(AC表示)
■传递律:若,则这种依赖称为传递依赖
由公理推得的规则:
■自含规则:
■分解规则:若,则
■合并规则:若,则
■复合规则:若,则
■通用一致性定理(Darwen):若,则
求解某一属性集的闭包的算法:
(1)令
(2),若,则
(3)若变化则重复第二步,否则输出
求解关系的闭包的算法:简单来说就是循环求解任意属性集的闭包然后并运算。但运算量可能非常大,有n个属性则会有个属性集,一般不会计算关系的闭包
最小函数依赖集:若任意函数依赖的(1)应变量均为单元素集合,(2)自变量不可约,即删除自变量的任意子集会导致函数依赖集的闭包的变化,(3)删除任意函数依赖会导致函数依赖集的闭包的变化,则称这样的函数依赖集是最小函数依赖集。任何函数依赖集都存在最小函数依赖集,它能最直观最简洁地展示出函数依赖
Heath定理:设关系,若有函数依赖,则与等价
任何关系都要满足1NF吗?
1NF是最基础的范式,在很多时候都会描述成属性值必须是原子值即标量值,甚至作为关系的基本特征。
但实际上这是错误的,关系的值不一定是原子值,类型也可以是非标量的。甚至很多数据库是间接支持这一点,比如MySQL支持JSON类型,JSON恰好是非标量的,如果用JSON类型基本可以当作是违反了1NF,这种情况称为是PNF,不过在此不多说明。
2NF、3NF、BCNF
2NF定义:满足1NF且每一非码属性不可约依赖于主码。
非码属性:不是主码的属性
不可约依赖(完全依赖):是指所有非码属性的真子集不能决定主码
2NF大体上分成了主码属性和非码属性
3NF定义:满足2NF且非码属性之间不存在传递依赖
3NF在非码属性上保证独立性不存在多余的传递依赖
BCNF定义:满足3NF且关系只有唯一的候选码
3NF并没有约束候选码,候选码可能有多个可能是复合也可能存在重叠的情况。BCNF让候选码必须唯一解决这种情况
多值依赖(MVD)和4NF
函数依赖在定义上是建立于一对一,一对多,但却没有多对多的情况。MVD是FD的推广,它包含了FD的所有情况。记作大体与FD相同
MVD与FD的关系:若,则
Fagin定理:已知,若,则等价于(为了方便描述,会将简记为,对于MVD以及后面的JD都是一样的)
4NF定义:满足BCNF且唯一的非平凡的MVD只能为超码的形式(数学描述:)
连接依赖(JD)和5NF
JD定义:已知,则记作连接依赖是多值依赖的超集,再次进行了抽象,抽象到了投影的本质层面
规范化的本质是投影,因此可以看成一个关系R分解成n个投影,JD的每一元素为投影。
JD与MVD的关系:若,则即抽象成投影-连接的依赖
5NF定义:又称PJ/NF。满足4NF且候选码蕴含每一非平凡连接依赖
平凡连接依赖:当且仅当连接依赖的元素是中所有属性的集合
注:候选码蕴含是指连接依赖的每一元素都是候选码的子集
5NF比较抽象很难理解,它的问题一般只出现在循环关系的情况。
比如一个关系有名字、技能、工作
其中名字和技能有联系,名字和工作有联系,技能和工作有联系,因此其连接依赖为
其中它满足4NF但违反了5NF即不管选取什么候选码,都有不在连接依赖的元素的情况。假设选取名字为候选码,剩余的并没有被候选码蕴含
若要范式化为5NF,只要化成三个关系表就行即分成三个表即可
关于反范式这里不作说明,属于拓展性内容。一定程度上范式可以说是以连接的时间代价换取空间的缩小
语义建模——E/R模型
之所以说范式无用,主要是语义建模的E/R图模型基本可以解决这些问题。范式是在数据层上,而语义建模则是建立于数据层之上的语义层,就当且所述的范式体系下语义建模是降维打击,这种范式的实用价值可以说没有。E/R模型建立后如果转换得当大部分情况是直接到5NF
实体:可区分的对象
实体类型:实体的抽象类,其个体为实例
联系:实体间的联系
属性:实体或联系均有属性,实体或联系可以看成非标量型的结构
其常用图标如下
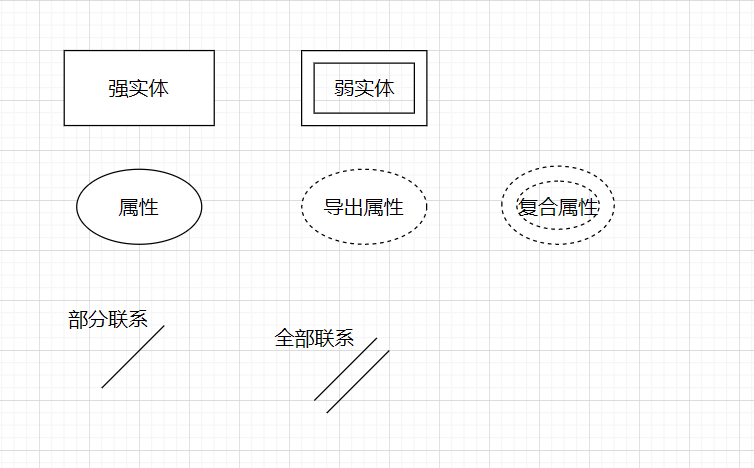
其中实体分为强实体和弱实体
强实体是指不依赖于其他实体的实体
弱实体是指依赖于其他实体的实体,比如自行车依赖于轮子,如果id1234的自行车删除后相应的轮子也会删除
属性具有很多性质,一般会对主码的属性下加上下划线来表述。其中复合、多值、null等性质一般不会直接实现。比如对于复合即非标量的属性可能会拆解或是单独成为一个关系。但破坏1NF的PNF则可以完成这一点
联系表明了实体之间的关系,其中根据参与者的数量会称具有多少度。
实体在层次上会分为超类型和子类型,即面向对象的思想,这一点后续会详细说明。在设计数据库时会先在语义层设计E/R图然后转成实际代码,具体内容这里不再说明
四、事务
事务
事务为逻辑工作单元,具有以下特性,被简称为ACID
■原子性:事务是原子的,要么全做要么全不做
■一致性:事务会从一致性状态转向新的一致性状态,即保证了完整性
■隔离性:事务相互隔离互不影响,即事务若并发处理需要进行相关处理
■持久性:事务若成功提交则永久生效
事务管理器:
通过commit、rollback的设计提供了ACID特性
rollback分为显式和隐式,显式即代码中的rollback,隐式即异常时也会进行的步骤
commit会提交事务并且永久性更新,这是持久性和一致性。如果发生异常则会rollback即回滚至上一状态,这是原子性和一致性。
commit:建立提交点,标志着事务的结束
rollback:回到初始提交点
在事务执行过程中会记录在恢复日志中,这是物理级冗余,以提供处理异常的机制。数据库并非不存在冗余,其中一部分是为了解决异常。回滚的实质是通过恢复日志进行记录来更新
为了实现ACID特性一般会有以下内容
■不存在嵌套事务
■支持事务并发
■日志先写原则:提交前会先写入日志
系统恢复——全局故障
在全局故障下一般分为两类故障,且有针对的解决方法
■系统故障(软故障):影响所有事务,但不会破坏数据库的故障
■介质故障(硬故障):破坏数据库的故障
解决介质故障的方法一般就是备份,当发生故障时用备份的副本来恢复
解决系统故障则是定期自动设置检查点后才写入数据并且记录于日志中

图中可知T1事务是正常的;因为要恢复至检查点会导致T2、T4的事务丢失而需要重做;T3、T5事务则因为没做完需要撤销
一般的算法:
(1)设置UNDO、REDO列表。UNDO列表包含最近检查点中所有事务列表(此例中为T2、T3),REDO设为空
(2)正向扫描日志,事务在开始时会在日志里设置BEGIN TRANSCTION,若遇到开始事务的标记则T加入至UNDO列表。若遇到COMMIT,则事务会从UNDO列表转移至REDO列表
(3)反向恢复:反向扫描日志,撤销UNDO列表中的事务
(4)正向恢复:正向扫描日志,重做REDO列表中的事务
日志扫描只会扫描上一检查点到异常时间点这段时间内,因此第一步会添加上一检查点正在进行的事务于UNDO列表中以避免扫描不到BEGIN TRANSCTION。(此例中无法扫描T2、T3的BEGIN TRANSCTION)第二步开始扫描,若扫描到BEGIN TRANSCTION则会先认为是要UNDO的,如果扫描不到事务结束的标识(即COMMIT)则是事务进行中未完成的需要撤销,如果扫描到了,则是在上一检查点到异常时间点之间的事务已经做完的需要重做。第三步第四步则是依次进行恢复
ARIES算法:
(1)分析:设置UNDO、REDO列表(和上一算法的过程一致)
(2)重做:检查点开始重做REDO列表的事务,即返回至崩溃时的状态
(3)撤销:撤销提交失败的更新
之所以先重做再撤销,是为了防止恢复过程中又失败的情况,已完成的撤销不会再次重复
多数据库的事务——两阶段提交
事务可能并非针对某一数据库而是多个数据库,这个时候如果要保证都能处理成功,必须要处理之间的一致性问题。每个数据库均有资源管理器用于管理自身数据库的资源和恢复日志,协调器用于管理涉及到多数据库的事务的多个资源管理器
协调者(coordinator):关于多个数据库的事务时,协调者用以统一涉及数据库范围的指令
(1)准备:协调者指示所有资源管理器写入日志并完成指令,之后资源管理器发送响应表明以完成写入日志
(2)提交:若所有资源管理器均发送响应准备好,则commit完成事务,否则rollback通知相应数据库发生异常
若事务处理过程中故障,则会重启依据日志并继续执行
保存点(SQL99):于事务中建立保存点间接实现了事务嵌套
事务并发的基本问题
一般而言,事务就分为两个内容,即读取内容和更新内容。事务并发是指多个事务同时进行且针对同一对象,这时候可能会因为读取和更新的顺序不同导致了问题
(1)脏写——丢失更新问题
| 事务1 | 事务2 |
|---|---|
| 读取元组t | |
| 读取元组t | |
| 更新元组t | |
| 更新元组t |
由于事务1优先更新了t,事务2再更新则会导致事务1更新的失效。即写入时再写入称为脏写
(2)脏读——未提交依赖问题
| 事务1 | 事务2 |
|---|---|
| 更新元组t | |
| 读取元组t | |
| rollback |
脏读问题是指已更新未提交的数据再次读取后,若事务2rollback会导致事务1的读取失效。rollback不等于commit哪怕是显式的rollback即事务按照代码正常执行也会认为是发生了异常,此时则会陷入系统故障,事务1自然也失效
(3)不可重复读——不一致分析问题
| 事务1 | 事务2 |
|---|---|
| 读取元组t | |
| 读取元组t | |
| 更新元组t | |
| 读取元组t |
不可重复读是因为事务1读取后,事务2导致元组发生变化且并未提交,此时再读取元组t会读取更新后的会导致运算错误,因此也称为不一致分析。比如原本事务1要计算某个内容,事务2在计算过程中更新了,而计算需要再次读取则是读取更新后的,最终会导致计算错误
并发问题的本质:本质上说读取可简记为R(Read),更新简记为W(Write),即组合时会发生的问题。比如RR是指事务A先进行了R操作,事务B进行了R操作,这显然是没有任何问题发生的,而其他的——WW即脏写问题,WR即脏读问题,RW即不可重复读问题
锁机制
在了解了并发问题后,像操作系统一样,采用锁机制来解决
即为事务的对象(目前对象视为元组)赋予锁,保证其他事务访问该对象
X锁:又称排他锁、写锁、Exclusive Lock。会拒绝其他事务对锁的请求
S锁:又称共享锁、读锁、Shared Lock。可以允许其他事务对S锁的请求,但会拒绝X锁的请求。
这里不采用锁类型相容矩阵的说法,采用锁类型前驱图的说法。即高等级的锁不可能被低等级或同等级的锁访问(称为锁冲突),低等级则可以被高等级的锁访问,比如先发动S锁不会与X锁冲突,而先发动X锁则会与S锁或X锁冲突。目前的锁类型前驱图比较简单就是X→S,后续会进行扩展。
一级封锁协议:在事务开始更新前会添加X锁,直到事务结束后才释放。X锁针对于W操作,只能解决WW问题,无法解决涉及R操作的问题。
二级封锁协议:在一级封锁协议的基础上,在事务读取前加S锁,但读取后即释放S锁,可以解决WR问题。即W的时候为X锁,S锁不能申请即不能执行R操作,此时可解决。但不能解决RW问题,因为R操作后S锁直接释放了,此时进行W操作即申请X锁是可以执行的
三级封锁协议:在二级封锁协议的基础上,释放S锁不是在读取后释放而是事务结束后释放。可以进一步解决RW问题。当R操作后S锁依然存在,此时进行W操作申请X锁是禁止的。这是与二级封锁协议的区别
如果锁申请操作被禁止了则会进入等待状态,当可以申请的时候可以进行操作,至此三个并发基本问题都能解决
锁的问题
锁解决了基本的并发问题,但锁本身也有问题
(1)活锁问题
当有足够多的事务时,会因为锁机制很多事务会进行等待,此时谁先执行事务是无法确定的,有的事务可能会一直处于等待状态,则等待时间过长,但对用户来说可能是卡了,这称为活锁问题。这实际上是没有对事务先后进行排序,采用队列即可解决,因为锁冲突进行等待时则会加入队列,保证先入先出
(2)死锁问题
这个问题比较复杂,假设A事务因为B事务的锁冲突进行等待,但如果B事务也因为A事务的锁冲突进行等待。此时会陷入死循环导致A、B事务相互等待的情况。
■比如一个事务有多次更新时,即两次X锁时,会导致自身的X锁还未释放就等待,从而永远等待。在本质上是因为事务在等待关系上形成了闭环,从而导致一直等待
■至于如何避免死锁,在数据库上会采用Wait-Die或Wound-Wait方法即时间戳
(1)每个事务开始时标注唯一的开始时间
(2)新事务试图申请锁时,如果是Wait-Die如果原本事务的开始时间更晚,则原本事务等待,否则原本事务回滚并重新开始;如果原本事务开始时间更早,则原本事务等待,否则新事务回滚并重新开始。不管怎样都是更早的。(但不管怎样都是新的事务优先,旧的事物延后)
(3)事务若重新开始,保留其原本的时间戳
■一次封锁法:对要用到的数据事先全部加锁,而不是等用到时才加锁。但一般情况不会采用这种方法
■顺序封锁法:预先规定封锁的顺序以破坏等待循环。一般也不会采用这种方法
但并发不只是数据库才有,有些方法在数据库方面可能用得不多,在其他地方用得比较多
幻读问题与意向锁
除了基本的并发问题和锁机制的衍生问题,还有一类问题称为幻读。它非常像不可重复读的问题,但根本的不同是之前所有问题关于更新元组方面只针对原本的元组更新,而幻读是添加了新的元组。
比如A事务要统计内容,而在统计过程中B事务添加了新的元素,而A事务此时统计的是添加之前的而非统计后的导致了统计的错误
为了解决这种问题采用了意向锁的机制
锁粒度:是指锁对象细化的程度,之前都默认了锁对象为元组,其实锁对象可以改为关系的所有元组。锁粒度的引入有了另外的结论,比如锁对象改成关系后即锁粒度变粗使得不再需要更多锁,一个锁即可代表关系的所有元组。并发问题的前提是锁对象都一致,锁粒度小时即可增大并发度使得更细的级别间减少并发问题
在锁粒度的基础上有以下新的锁
意向共享锁(IS锁):对关系所有元组设置S锁
意向排他锁(IX锁):对关系所有元组设置X锁
共享意向排他锁(SIX锁):允许并发读,但不能更新即S锁+IX锁
在拓展了锁粒度的情况下锁类型前驱图如下

锁类型前驱图的另外概念是锁强度,即不同类型锁有不同强度,一个锁会与其强度更高的或同等强度的锁产生锁冲突
可串行性与隔离级别
调度:调度是指如何安排多个事务的执行。笼统来分只有串行调度和交错调度。串行就是一个执行完后再执行效率比较低,交错则是并发效率比串行高
事务有很多调度,如果多个事务之间串行调度和交错调度等价,则串行调度转变为交错调度可提高效率。在调度的意义上并发问题其实是指交错调度与串行调度不等价,每解决一个并发问题实质上是降低并发度更接近串行调度,因此为了效率,会在保证不会出现某个并发问题的情况下不解决这个并发问题。
因此引出了隔离级别的概念,不同数据库可能定义不同,这里以MySQL为例
| 隔离级别 | 解决的并发问题 |
|---|---|
| READ UNCOMMITTED | 脏写 |
| READ COMMITTED | 脏写,脏读 |
| REPEATABLE READ | 脏写,脏读,不可重复读 |
| SERIALIZABLE | 脏写,脏读,不可重复读,幻读 |
不管什么级别,都能解决脏写问题,如果隔离级别过高可能会影响效率,但如果太低且无法保证不会出现问题则会出现异常,具体如何定级需要用户自己决定。至于死锁则是锁机制本身的衍生问题并非并发问题本身
关于并发在恢复上也有些问题
| 事务1 | 事务2 |
|---|---|
| 更新元组t | |
| 提交(针对于元组t) | |
| rollback |
如图所示,当事务2更新后,事务1提交,如果事务2再rollback其实是失效的,它可能并没有违反锁冲突。对于并发即交错调度而言可恢复条件是级联独立(在事务运行期间其他事务不能commit)
ACID存在一定缺陷,这里就不多说明了
五、其他主题
数据库的安全性
安全性是防止一些非法用户的破坏,系统的安全分层的,除了数据库,在网络、系统、程序等方面都需要考虑。这里只考虑在数据库这一层上的安全性。主要采用自主存取控制(DC)和强制存取控制(MC)两种方法
(1)自主存取控制
DC采用与约束完全相反的思路即授权
授权主要有授权名、授权的关系对象、授权的属性范围、授权操作、被授权的用户组成
(2)强制存取控制
MC主要采用赋予等级的方式,用户赋予许可证等级,数据对象赋予密集,有两类规则
■简单规则:用户许可证等级大于等于数据对象密集才可访问
■星规则:用户许可证等级等于数据对象密集才可访问
(3)身份鉴别
即检查用户是否为正确的合法用户,手段有很多这里不再说明
(4)信息隐蔽通道问题
这类问题主要是通过一个特殊的布尔表达式来推断出某个个体数据。比如用户可以获取某个职位的平均工资,但某个职位只有一个人,就可以推断出这个人的工资。这样的问题需要限制输入来尽可能避免。这种问题一般会出现在统计数据库中
查询过程
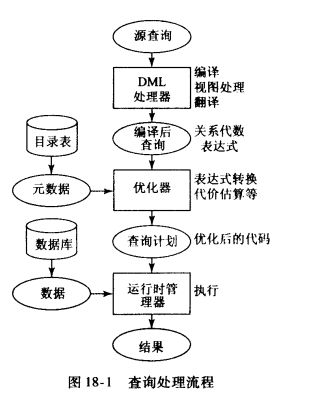
阶段1:将查询代码转换为便于机器处理的内部格式
阶段2:将内部格式统一为规范格式
阶段3:考虑低层操作
阶段4:生成多个计划并选择执行最低代价的计划
信息空缺
对于信息空缺而言采取了两种方法即3VL与空值的方法
(1)3VL方法
3VL是指三值逻辑,即对布尔值以及相关操作进行拓展,在原本true和false新增加unk表示不确定性
具体操作如下
| AND | t | u | f |
|---|---|---|---|
| t | t | u | f |
| u | u | u | f |
| f | f | f | f |
| OR | t | u | f |
|---|---|---|---|
| t | t | t | t |
| u | t | u | u |
| f | t | u | f |
| NOT | |
|---|---|
| t | f |
| u | u |
| f | t |
| MAYBE | |
|---|---|
| t | f |
| u | t |
| f | f |
MAYBE操作符用于判断值是否是不确定的
但在实际编程环境中,经常会遇到不同类型结合布尔型的情况,比如非0当作false等都是共识了
对于新引入值unk而言,规定,其中是其他类型的操作
但是3VL的缺陷也非常明显
■违反直觉,比如,其中表示城市为伦敦,那么命题的含义就是城市是伦敦或不是或可能是,这种可能是在自然语言环境下可能很奇怪
■3VL的引入导致了之前的优化策略失效,比如多了unk后就不一定为r,而原本的优化策略是直接优化成r
(2)空值
另外一种方法则是引入了空值UNK(当然实际编程环境中为null)
UNK可以单独看成一个类型而不是拓展原本的布尔类型,UNK代表了不是值
同样任何类型操作都会导致,但这种特性导致了非常奇怪的结果
在RDBMS中已经存在了外连接操作,但其他的外交、外差、外并等操作仅存在于理论上(外并曾出现于SQL标准中后删除)
所谓外操作就是考虑了空值的情况
内连接:,不允许关系存在空值
左外连接:,允许左侧关系存在空值
右外连接:,允许右侧关系存在空值
全外连接:,允许所有关系存在空值
空值的引入也扩展两类完整性的定义
扩展-实体完整性:主码不存在UNK且唯一,如果主码允许UNK就会因为导致主码可无限多出现UNK从而无法起到标识作用
扩展-参照完整性:外码值为匹配值或UNK,UNK的引入并不会破坏参照完整性因此允许UNK
(3)SQL的做法
SQL采用了3VL与UNK杂糅的3VL系统,存在理论上的缺陷
如果有值是unk的情况,它可能返回true也可能返回false,导致了实际编程中可能会有此相关的异常
类型继承
继承机制在面向对象中非常重要,它分成了单一继承与多重继承。所谓单一继承是指子类最多仅有一个超类即树结构,多重继承是指子类可以具有多个超类即图结构。继承常常用图论的方法表述,如下例
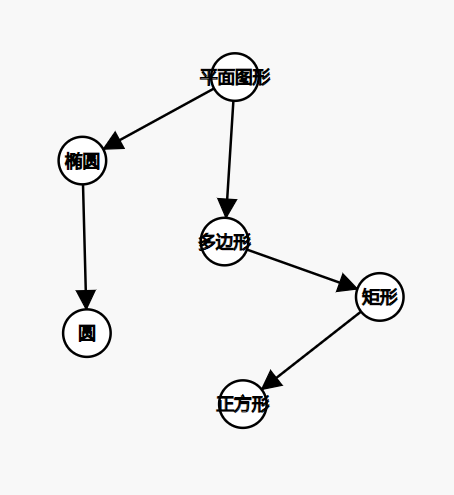
除了超类与子类的定义外给出如下定义
真类型:A为B的超类型且则称A是B的真超类型,反之称B为A的真子类型
直接类型:若A为B的超类型且不存在即是A的真子类型又是B的真超类型的类型,则称A为B的直接超类型,反之称B为A的直接子类型
根类型:不存在超类型的类型
叶类型:不存在子类型的类型
(1)对于直接超类型而言一定不存在圈
(2)不相交假设:同一根类型、同一超类型的不同直接子类型是不相交的,即有直接子类型T1、T2,
(3)多态性是指超类的操作也同样适用于子类,即操作名相同,参数列表可以不同,参数列表相同的情况下称为重写,参数列表不同的情况下称为重载。从模型角度,是一种多个版本的同一操作即操作的语义应当一致。从用户角度,仅有一种唯一语义的操作
(4)可置换性:又称里氏替换原则。是指任何超类可接受的值,也可用子类型的值进行替换,即超类的性质也保留于子类中
(5)类型上转是指子类转换成超类,保证超类的一些被覆盖的属性、方法可用。类型下转是指超类转子类,但一般不推荐下转
(6)约束泛化是指超类为子类的超集,子类不满足约束条件时上升为范围更广的超类以解决子类扩展的问题。约束特化是指子类为超类的子集,当满足特定条件时超类可被特化为性能更优的子类。但这在目前显然是无法实现的,约束条件几乎无法找到通用结论,只能靠程序手动实现
(7)类型校验:是指在接受输入时先检查类型是否符合预设类型范围内,以防止错误类型的值传入,在弱类型语言中尤其重要
时态数据库
时态数据库是指记录历史数据、当前数据等随时间变化的数据信息,比如点赞数、搜索量等都是一种随时间变化的数据信息
时态数据库有针对于新的维度——时间,有一些基本问题
■时间是否具有起点、终点
■时间是连续的还是离散的
■如何描述“当前”的概念
基本假设如下
■时间量子:用于描述时间的最小单位,即受限于技术时间只能是离散的
■时间点:具有目的的时间间隔
■时间点除去起点、终点外上一个时间点称为前驱点,下一个称为后继点。一般情况时间具有起点,而终点似乎不需要存在
■时间区间:时间点间的时间段区间
区间类型
从上面时间区间抽象出了一个新的类型——区间类型。它代表了一个范围性的数据
定义:已知区间类型,其中值,为区间的起点,为区间的终点
针对这种类型Allen定义了非常多的操作符
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)当且仅当时才可运算
(11)当且仅当时才可运算
除了基于值本身运算外,基于区间类型的关系也存在运算,假设
(12)拓展:
(13)压缩:,,
(14)归并与反归并,在拓展、压缩操作基础上引入了序特征的操作,例子如下
关于区间操作它是否有应用的价值,这在一些特殊算法中博主已经找到了,或许某一天会用到。博主在一个游戏中记录的数据采用了区间类型,通过collapse操作以及相关理论成功将记录数据压缩了,减少了实际游戏中的空间占用,该算法时间复杂度大约是
6NF是什么?
5NF已经到了本质性的连接依赖,能否进一步拓展?依据上面新的区间类型,有了一些拓展,但目前的环境讨论6NF确实没什么应用价值,这里简单介绍,不过多说明。
推广操作符(U_op):即将原本的类型拓展至区间类型,而且普通类型与区间类型可以通过expand、collapse、pack、unpack进行转换。6NF的本质就是将连接依赖中重要的操作——投影,拓展成为U_投影即针对区间类型的情况,其余内容与5NF完全一致
关于U_op它形式化为,其中是输入的关系,为一般操作,为关系中为区间类型的属性集。通过这种形式可以将很多操作进行拓展,如U_ 并、U_ 交、U_ 差、U_ 乘、U_ 投影、U_ 选择、U_ 连接......
根据定义它是将有区间类型的关系先反归并后按传统操作再归并得到有区间类型的操作,一种特殊情况是当时,即退化为正常操作
例子:
供应商于城市发送某种货物,其中有现在的信息也有曾经的信息,关系模式如下
它满足了5NF但问题依然很大,比如当前时间信息与其他属性并不是统一的,这个时间对于供应商来说可能是与城市建立合同开始的时间,货物则是生产时间...解决这样的问题,采用“水平分解”即分解属性的方式
另外一个则是历史时间信息,水平分解并不能满足实际需求,需要采用“垂直分解”即分解成关系的方式
垂直分解即保证关系不存在U_ 投影
在最后,需要讨论下区间类型的一些问题
■冗余问题:区间类型存在重叠的问题,如显然中间2以及3是冗余的可以压缩成,因此需要pack或collapse操作压缩,事先防止出现一般采用merges或overlaps来判断
■迂回问题:区间类型不重叠但边缘连续的问题,如没有任何冗余的元素,但结构性上可被优化成,事先防止出现一般采用merges或meets来判断
■矛盾问题:在不同状态下区间值虽然也不允许重叠,如这两个状态完全无法重叠需要事先防止,这并非冗余问题,冗余以及迂回是针对多值的情况
数据库证明理论模型
在一般的模型理论中认为
1.数据库是关系的集合
2.关系是一组元组以及一组约束的集合
3.元组是一组属性值的集合
这似乎已经足够简洁且有说服力了,但从数学上它缺乏基础性的公理(好比1,2,3,...缺乏Peano公理,能用但不完善),证明理论模型就是引入了一组基本公理集来为这种构造提供理论支持
■封闭世界假说:数据库内不具有假命题
■唯一命名公理:真命题不可重复
■域闭包公理:命题必须于数据库域中
■其他一组与上述公理等价的公理
基本公理所构成的数据库称为外延数据库,演绎公理、完整性构成的数据库称为内涵数据库
候选码约束可形式化为
外码约束可形式化为(外码的参照链可能形成闭环)
对象数据库、对象/关系数据库以及其缺陷
对象类是一种具有特殊结构的类型,面向对象编程具有特殊的形式以更方便地编写代码,其中大部分术语和之前所述的类型是一致的
| 类型上的术语 | 面向对象上的术语 |
|---|---|
| 类型 | 对象类 |
| 值 | 对象 |
| 变量 | 可变对象 |
| 常量 | 不可变对象 |
| 操作符 | 方法 |
| 操作符转换 | 消息 |
封装性:是指对象类屏蔽了内部实现,像标量一样,即具有物理独立性。对象一般具有私有空间和公共接口,公共接口是展示给用户的,这种性质的要求衍生出了权限这个机制,在Java语言中可以体会到。
对象标识(OID):可以简单理解为C语言的指针,用于区分或引用对象
观点——对象模型是否等同于关系模型?否定,博主认为对象模型是关系模型的一种特殊约束,关系模型可以转换为对象模型,这种设计在很多数据库系统都存在,但是对象模型只有在特定情况下才能转换为关系模型
对象数据库的缺陷:查询会遇到各种问题(性能、访问失败、可选链等);性能问题且不具备通用方法;缺乏DBMS的特性,更接近于文件系统;对象模型缺乏数据独立性;对象模型与关系模型不等同造成一些问题
对象/关系数据库的缺陷:关系不等于对象,如果关系等同于对象会造成很多严重后果(如不满足1NF,类型可继承、需要同时支持两种模型的方法等),其中比较能说明这种问题是对象模型的引入损害了关系模型的概念完整性;指针即OID引入关系模型可能产生一些错误,指针与类继承会发生冲突
参考书籍
《数据库系统导论(第8版)》


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具