

C# 爬虫 HttpClient 之 https 踩坑记录(response自适应解码gzip)
背景
有一个网页(https),请求返回是一串json,可通过模拟浏览器获取,也可以通过api请求获取,其中通过C#的httpclient的Get发起请求,会出现不定时的返回结果乱码
请求代码
[HttpPost(Name = "GetTestNoParams")]
public async Task<string> GetTestNoParams(string url)
{
var ret = string.Empty;
try
{
var httpClientHandler = new HttpClientHandler
{
ServerCertificateCustomValidationCallback = (sender, cert, chain, sslPolicyErrors) => true,
};
var client = new HttpClient(httpClientHandler);
client.Timeout = new TimeSpan(0, 0, 5);
client.DefaultRequestHeaders.Add("Host", "www.southernfund.com");
client.DefaultRequestHeaders.Add("Accept-Encoding", "gzip, deflate, br");
var response = await client.GetAsync(new Uri("url"));
if (response.IsSuccessStatusCode)
{
return await response.Content.ReadAsStringAsync();
}
else
return $"请求失败:{response.RequestMessage}";
}
catch (Exception ex)
{
return ex.Message;
}
}
首先乱码排查
通过浏览器直接访问,发现该网页一段时间返回结果会进行压缩,一段时间结果直接返回,直接是json串 【Content-Encoding: gzip 可以判断内容进行了gzip压缩】
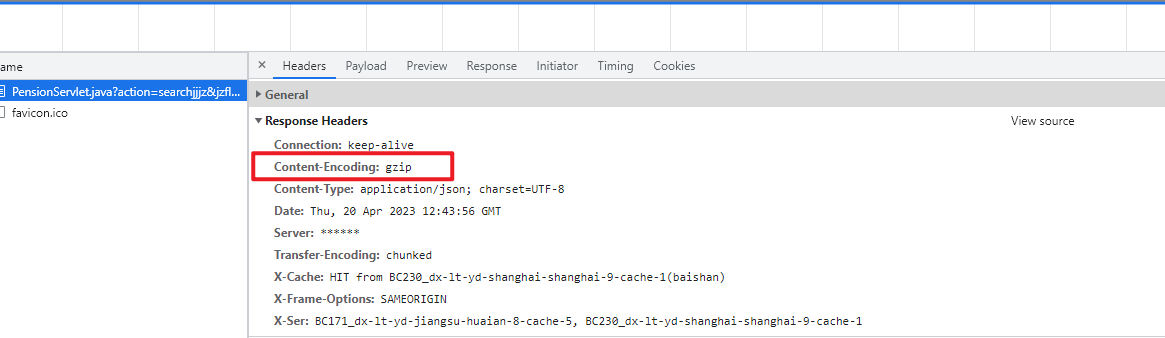
此时代码运行返回乱码

乱码解决
知道内容进行了gzip压缩,那我们就对内容进行GZIP解压缩,代码如下
[HttpPost(Name = "GetTestNoParams")]
public async Task<string> GetTestNoParams(string url)
{
var ret = string.Empty;
try
{
var httpClientHandler = new HttpClientHandler
{
ServerCertificateCustomValidationCallback = (sender, cert, chain, sslPolicyErrors) => true,
};
var client = new HttpClient(httpClientHandler);
client.Timeout = new TimeSpan(0, 0, 5);
client.DefaultRequestHeaders.Add("Host", "www.southernfund.com");
client.DefaultRequestHeaders.Add("Accept-Encoding", "gzip, deflate, br");
var response = await client.GetAsync(new Uri("url"));
if (response.IsSuccessStatusCode)
{
var stream = await response.Content.ReadAsStreamAsync();
var bts = Decompress(stream);
return Encoding.UTF8.GetString(bts);
//return await response.Content.ReadAsStringAsync();
}
else
return $"请求失败:{response.RequestMessage}";
}
catch (Exception ex)
{
return ex.Message;
}
}
public static byte[] Decompress(Stream stream)
{
var gzipStream = new GZipStream(stream, CompressionMode.Decompress);
var mmStream = new MemoryStream();
byte[] block = new byte[1024];
while (true)
{
int byteRead = gzipStream.Read(block, 0, block.Length);
if (byteRead <= 0)
break;
else
mmStream.Write(block, 0, byteRead);
}
mmStream.Close();
return mmStream.ToArray();
}
返回结果正常

bug
上述看似问题处理 但是这里面有个bug ,就是C#通过httpclient发起get请求的response的headers中不包含 Content-Encoding: gzip这个头信息,程序无法自动判断解压缩,上述代码也是强解压,当对方服务器切换返回非压缩的内容时,上述代码仍旧无法获取正常内容
C#通过httpclient发起get请求的response的headers
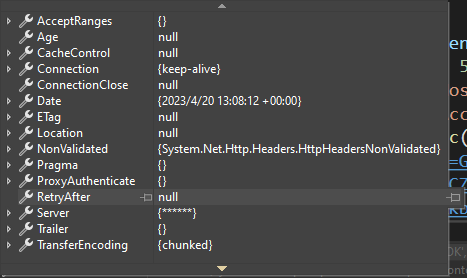
不过楼主发现通过python是可以获取到的

紧急的就用python做 后续期望C#能找到解决办法
解决了哈哈哈哈 C#的httpclient发起get请求的Content-Encoding: gzip头信息 不在response的headers中 而是在response.Content.Headers.ContentEncoding中 可以通过如下代码优化做 自适应
if (response.IsSuccessStatusCode)
{
if (response.Content.Headers != null && response.Content.Headers.ContentEncoding.Contains("gzip"))//同理可扩展其他解码格式
{
using (var gzipStream=new GZipStream(await response.Content.ReadAsStreamAsync(),CompressionMode.Decompress))//更优雅的解码
{
using (var streamReader=new StreamReader(gzipStream,Encoding.UTF8))
{
return await streamReader.ReadToEndAsync();
}
}
}
else
return await response.Content.ReadAsStringAsync();
}
else
return $"请求失败:{response.RequestMessage}";
