使用pytorch时所遇到的问题总结
使用pytorch时所遇到的问题总结
1、ubuntu vscode切换虚拟环境
在ubuntu系统上,配置工作区文件夹所使用的虚拟环境。之前笔者误以为只需要在vscode内置的终端上将虚拟环境切换过来即可,后来发现得通过配置vscode的解释器(interpreter)具体方法如下:
选中需要配置的文件夹,然后点击vscode左下角的写有“Python ***”的位置(或者使用快捷键“ctrl+shift+p”)--》选择文件夹--》从解释器列表中选择要用的解释器。完成设置后,会在文件夹下面多出一个名为“.vscode”的文件夹,其中会多出一个名为“settings.json”的文件,经过设置后该文件内会多出一个条目来指向虚拟环境中的python的路径,例如:python.pythonPath:"/home/lh/anaconda3/envs/pytorch/bin/python"。
2、使用DataLoader时报错:raise RuntimeError('already started')
出错位置在使用DataLoader时,将参数“num_workers”设置为大于0的值了,推测原因是没有打开多线程功能,解决方法为将num_workers设置为0。如果需要要使用多个子线程来加载数据,那么就需要让主程序在“if __name__ = 'main'"中运行。
3、pytorch中使用TensorBoard
问题(1): Import Error:TensorBoard logging requires TensorBoard with Python summary writer installed
这是由于当前的环境中没有安装TensorBoard。如果电脑上安装有anaconda,那么直接使用命令“conda install tensorboard”即可。
问题(2):调出tensorboard界面
当在程序中调用SummaryWriter之后,在控制台中会给出如下信息:

其中需要注意的是“--port 41889”。然后我们在控制台中输入命令“tensorboard --logdir='log' --port=41889”,--logdir用来指向之前所指定的日志目录,--port就是之前控制台中给出的端口号。输入指令后,控制台中会给出一个网址,打开该网址就可以在浏览器中打开tensorboard界面了。
4、pytorch使用dataloader时,报出“TypeError:default_collect:batch must contain tensors, numpy arrays, numbers,dicts or lists; found <class 'PIL.Image.Image'>”
这是因为在创建torchvision.Dataset对象的时候没有将数据库内的图像转为torch张量,在创建数据库对象的时候将参数transform进行如下设置就可以了:transform=transform.ToTensor()。
5、RuntimeError:Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
这是由于传入模型的数据是放在CPU内存中的,而模型本身被放置在GPU内存中了。因此只需要将输入的数据放置到GPU内存中就可以解决问该问题了。
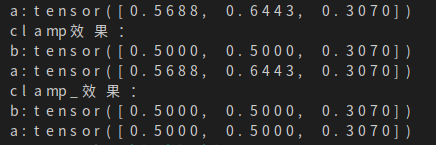
6、pytorch,同名函数后面加一个'_',例如:'clamp()'与'clamp_()'
一般来说,如果函数后带了一个下划线,就意味着在改变当前张量的值的同时返回一个修改后的副本;如果不带下划线,那么就只返回修改后的副本,而不改变原来张量的值。例如:
import torch a=torch.rand(3) print('a:{}'.format(a)) print("clamp效果:") b=a.clamp(0, 0.5) print('b:{}'.format(b)) print('a:{}'.format(a)) print("clamp_效果:") b=a.clamp_(0, 0.5) print('b:{}'.format(b)) print('a:{}'.format(a))
结果为如下图,可见张量a在调用clamp_函数后其本身的值也会发生改变,但是调用clamp的时候则只会返回一个修改后的副本。
7、python中(1)与(1,)的区别
‘(1)’这种写法得到的是一个int类型的数据,而‘(1, )’得到的是一个turple类型的数据。验证如下:

8、tqdm进度条
tqdm.update()所传入的参数指的是进度条前进的步长,而不是当前进度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号