金融风控贷款预测之EDAtask2
查看train与test列特征
train 800000条数据,47列; testa 200000条数据,48列。
>>>print(train.shape)
>>>print(testa.shape)
(800000, 47)
(200000, 48)
testa数据集存在n2.2, n2.3, 但在train数据集中没有
目标列为isDefault
>>>print('testa have no column : ', set(train.columns).difference(set(testa.columns)))
>>>print('train have no column : ', set(testa.columns).difference(set(train.columns)))
testa have no column : {'isDefault'}
train have no column : {'n2.2', 'n2.3'}
查看空缺、重复值
1、train数据集共22列存在空缺值。 testa数据集共11列存在空缺值。
2、train数据集:除匿名特征n3外其余匿名特征均存在空缺值并且在3w以上,n11空缺值最多达6.9w;空缺值第二多的特征是employmentLength(就业年限)存在4.6w个空缺值;其它特征空缺数量在百位和个数。
3、testa数据集:除匿名特征n3外其余匿名特征均存在空缺值,n11空缺值最多达1.7w;空缺值第二多的特征是employmentLength(就业年限)存在1.1w个空缺值;其它特征空缺数量在百位和十数。
| train列列名 | 数量 |
|---|---|
| n11 | 69752 |
| employmentLength | 46799 |
| n8 | 40271 |
| n14 | 40270 |
| n5 | 40270 |
| n0 | 40270 |
| n1 | 40270 |
| n2 | 40270 |
| n13 | 40270 |
| n2.1 | 40270 |
| n6 | 40270 |
| n7 | 40270 |
| n9 | 40270 |
| n12 | 40270 |
| n4 | 33239 |
| n10 | 33239 |
| revolUtil | 531 |
| pubRecBankruptcies | 405 |
| dti | 239 |
| title | 1 |
| postCode | 1 |
| employmentTitle | 1 |
| testa列名 | 数量 |
|---|---|
| n11 | 17575 |
| employmentLength | 11742 |
| n13 | 10111 |
| n0 | 10111 |
| n1 | 10111 |
| n2 | 10111 |
| n2.1 | 10111 |
| n2.2 | 10111 |
| n2.3 | 10111 |
| n14 | 10111 |
| n5 | 10111 |
| n6 | 10111 |
| n7 | 10111 |
| n8 | 10111 |
| n9 | 10111 |
| n12 | 10111 |
| n10 | 8394 |
| n4 | 8394 |
| revolUtil | 127 |
| pubRecBankruptcies | 116 |
| dti | 61 |
4、 重复值
train, testa 均没有重复值
>>>print(train.duplicated().sum())
>>>print(testa.duplicated().sum())
0
0
查看数据集数据类型
这里查看数据类型是为了后续分开连续型变量和类别型变量
数据集分为数值型和object类型。
object类型:grade,subGrade,employmentLength,issueDate,earliesCreditLine
--------------input---------------------
num_types = []
object_types = []
for i, types in enumerate(train.dtypes):
object_types.append(train.dtypes.index[i]) if types=='object' else num_types.append(train.dtypes.index[i])
print('num_types:',num_types)
print('-'*24)
print('object_types:',object_types)
---------------output-----------------------------
num_types: ['id', 'loanAmnt', 'term', 'interestRate', 'installment', 'employmentTitle', 'homeOwnership', 'annualIncome', 'verificationStatus', 'isDefault', 'purpose', 'postCode', 'regionCode', 'dti', 'delinquency_2years', 'ficoRangeLow', 'ficoRangeHigh', 'openAcc', 'pubRec', 'pubRecBankruptcies', 'revolBal', 'revolUtil', 'totalAcc', 'initialListStatus', 'applicationType', 'title', 'policyCode', 'n0', 'n1', 'n2', 'n2.1', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14']
------------------------
object_types: ['grade', 'subGrade', 'employmentLength', 'issueDate', 'earliesCreditLine']
查看匿名特征与标签isDefault相关强度
观察匿名特征与标签的相关系数可视化结果,发现匿名特征普遍与标签的相关强度弱,但某些匿名特征之间存在强相关性。后续数据处理过程应该注意这个细节
# 提取匿名变量
nList = ['isDefault']
for column in train.columns:
if column.startswith('n'):
nList.append(column)
# 加入标签isDefault
nList.append('isDefault')
plt.subplots(figsize=(20,20))
sns.heatmap(train[nList].corr(), annot=True, square=True, cmap='Blues', vmax=True)
plt.show()
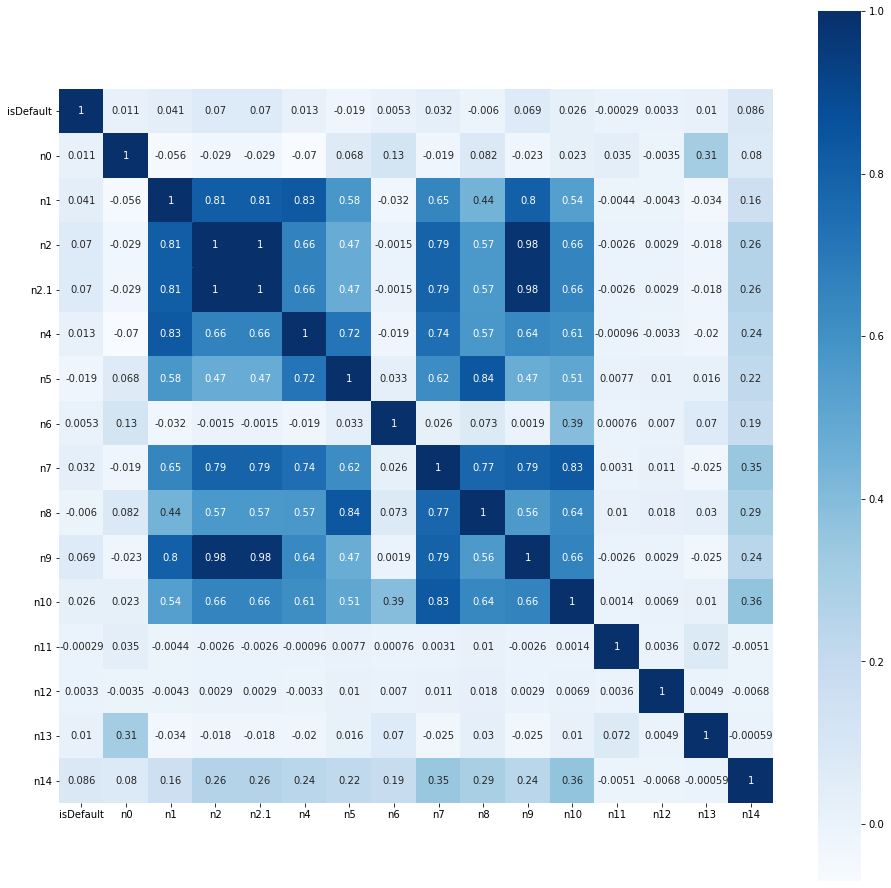
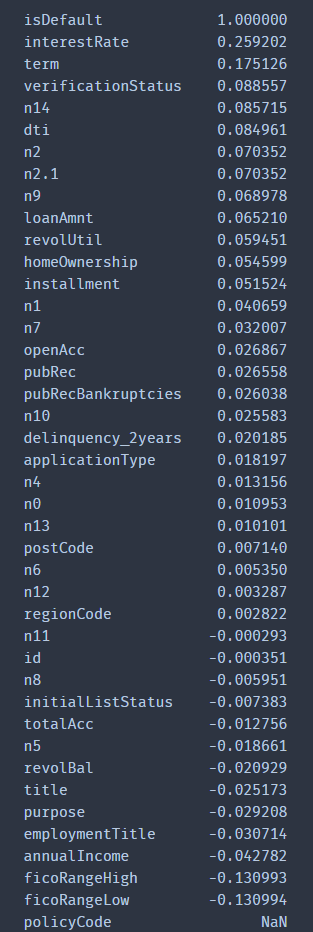
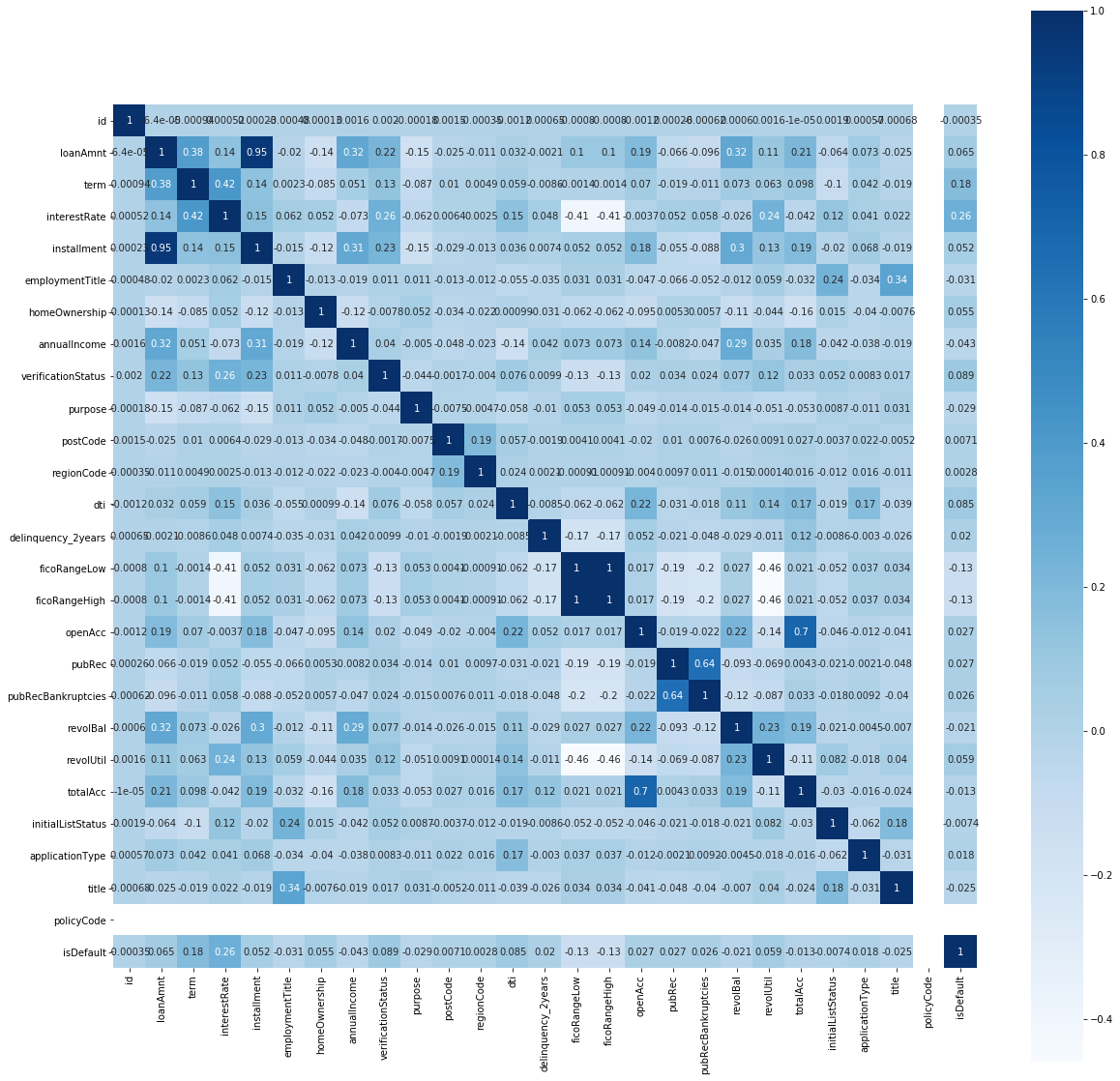
查看非匿名特征的数值特征与标签isDefault相关强度
计算后发现,与标签相关强度最大的是interestRate(贷款利率)。和我预想的不太一样(原以为贷款金额与标签相关强度最大,可能这就是人的错觉吧)
此外,某些特征之间相关性比较强。 如loanAmnt(贷款金额)、installment(分期付款金额);totalAcc(当前信用额度)、openAcc(未结信用额度数量)等。 这些特征也是在后续特征处理中需要注意的地方。
num_data = train.drop(columns=object_types)
drop_nList_data = num_data.drop(columns = nList)
drop_nList_data['isDefault'] = train.isDefault
# 查看相关性系数并降序
num_data.corr().isDefault.sort_values(ascending=False)
查看标签0、1比例
01样本数量不平衡。 0/1 接近 8/2
>>>train.groupby(['isDefault']).count().id/train.shape[0]
isDefault
0 0.800488
1 0.199513
Name: id, dtype: float64
(train.groupby(['isDefault']).count().id/train.shape[0]).plot(kind='bar')
plt.title('label rate')
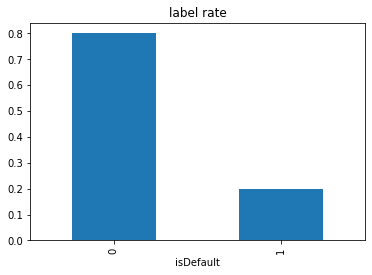

 浙公网安备 33010602011771号
浙公网安备 33010602011771号