
Mysql 锁
一、读锁、写锁
1、 表锁
读锁也称为共享锁、写锁称为排他锁
读锁会阻塞其他进程写操作,写锁会阻塞其他进程读和写操作
(加上写锁,当前线程可以继续查询)
tips:如果是常用写操作的场景,不建议使用myisam引擎,以写优先,会给数据库表加写锁,导致其他线程无法访问,降低并发量。
2、 行锁(偏向Innodb、开销大、会出现死锁;并发度高)
问题:无索引行锁升级为表锁,行锁锁的是索引
索引失效:如果类型是varchar,没加单引号,会自动类型转换,就会导致索引失效,会造成行锁,变成了表锁。
tips:
select xxx for update 锁定某一行后,其他操作被阻塞,相当于加了个行锁。
3、间隙锁:
当使用范围条件而不是相等条件检索数据,并请求共享或排他锁时,innodb会给符合条件的已有数据记录的索引加锁,对于键值在条件范围内并不存在的记录,叫做间隙(gap)
Innodb会对这个间隙加锁,这种锁机制就是所谓的间隙锁(next-key锁)
可以防止一定程度上的幻读。
4、INNODB意向锁(支持行级锁与表级锁共存,而意向锁就是其中一种表锁)
需要解决的问题:
在数据表中,如果给某一行数据加上了排它锁,数据库自动的给更大一级的空间,比如数据页和数据表上自动加上意向锁,告诉其他人这个数据页或数据表已经有人上过排他锁了
这样当其他人再要获取排它锁的时候,只需要了解是否有人获取了这个表的意向排他锁即可
1、意向锁存在是为了协调行锁和表锁的关系,支持多粒度的锁并存
2、意向锁是一种不与行级锁冲突的表级锁!!!!
3、表明某个事务正在某些行持有了锁或该事物准备去持有锁
1、意向共享锁
2、意向排他锁


查看最近的锁数量等
show profiles查看整个查询的每一步过程,进行排查。
mysql主从复制
复制基本原则:
1、每个slave只能有一个唯一的id
2、每个slave只有一个master
3、每个master可以有多个slave
slave会从master读取binlog来进行数据同步
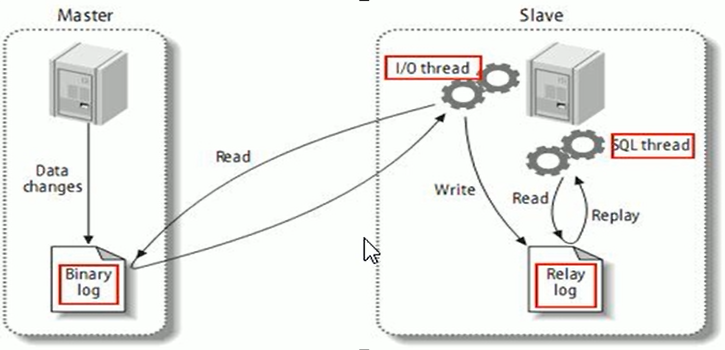
mysql主从复制分为三步:
1、mysql将改变记录写到二进制日志(binlog),这些记录过程的日志叫做binary log events;
2、slave将master的binary log events拷贝到它的中继日志(relaylog)
3、salve重做中继日志事件,将改变应用到自己的数据库中。mysql复制是异步且是串行化。
同步方法:
1、异步复制(一致性最差,效率最高)
如果主机宕机了,会存在binlog丢失的情况。

2、半同步复制
在commit之后不直接返回结果,等待至少一个库接收成功了,并写入了relay中继日志后,再返回。
这样提高了数据的一致性,但是多增加了一个网络IO请求延迟,降低了读写效率
CAP理论
Consistency一致性:所有节点访问同一份最新数据的副本(数据一致性,强一致)
Availability可用性:非故障节点在合理时间内返回合理的响应(淘宝、京东保证高可用)
Partition Tolerance 分区容错性 ,分区后仍然能对外提供服务。
(网络分区:分布式系统之前是网络连通的,但是因为故障,导致了部分节点出现了问题,某些节点之间不连通了,分成几个区域,叫网络分区)
重点:
当发生网络分区的时候,如果要继续服务,那么强一致性和可用性只能2选1.也就是说当网络分区后P是前提,决定了P之后才有C和A的选择。也就是分区容错性。
简而言之P是一定要满足的,在此基础上只能满足可用性A或者一致性C
因此分布式理论不可能选择CA,只能选AP或者CP。
Zookeeper、HBase就是CP架构
Cassandra、Eureka就是AP架构
Nacos不仅支持CP也支持AP架构。
为啥不可能选择CA?若系统出现分区,系统中某个节点进行写操作,为了保证C一致性,必须要禁止其他节点的读写操作,这就和A发生冲突了。如果保证了A,其他节点的读写操作正常的话,那就和C发生冲突了。
选择CP还是AP关键在于当前的业务场景,没有定论,比如对于保证强一致性的场景如银行一般选择保证CP。
另外,需要补充说明一点是:如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证P的时候,C和A能够同时保证。
NoSQL保证AP,分布式关系型数据库保证CP
分库分表
分库:
1、分库就是将数据库分散到不同的数据库中
例1:
将数据库中用户表和订单表分离到两个数据库中
例2:
由于用户表数据量太大、对用户表进行了水平拆分,然后将切分后的用户表分别放在两个数据库中。
总结:将单个表、将多个表分离到多个库的类似分库操作
分表:
对单表数据进行拆分,可以是垂直拆分,也可以是水平拆分
1、垂直拆分:就是对数据表列的拆分,把一张列比较多的表拆分成多个表。
2、水平拆分:对数据表行的拆分,把一张行比较多的表拆分为多个表。
什么情况下需要分库分表:
1、单表的数据达到千万级以上,数据库读写速度比缓慢(分表)。
2、单个数据库占用空间越来越大,
3、应用的并发量太大。
分库分表会带来什么问题:
1、join操作:同一个数据库中的表分布在了不同数据库,导致无法join操作。这样就需要多次查数据库
2、事务问题:同一个数据库中的表分布在了不同数据库,无法满足数据库自带的事务了。
3、分布式id:分库后数据库的自增主键已经满足主键唯一了。这个时候就需要引入分布式id了。
分布式id
特点:
1、全局唯一
2、趋势递增
3、单调递增
4、高可用高并发
方案:
1、uuid,会造成id随机,没有规律性,频繁造成数据库也调整。概率也可能会重复
2、db自增:无法具备全剧唯一。不能使用分库分表
3、雪花算法:在容器出现之前,雪花并发性好,但是由于雪花算法依赖时间戳,如果容器进行始终回调,导致灾难性的问题。还有雪花算法分布式环境下,如果机器的时钟不同步,可能会导致非递增的问题。可以优化。
4、美团Leaf算法,分布式id生成算法
Leaf算法特性:
1、全局唯一:不会出现重复id,且id整体趋势递增。
2、高可用,服务完全基于分布式架构,即使mysql宕机,也可以容忍一段时间的数据库不可用。
3、高并发低延时:QPS 5W+
4、接入简单,直接通过RPC服务和HTTP服务接入。

