Redis
Redis数据存储结构
内部底层是一个大的hashmap,内部实现是hash,冲突通过挂链的办法实现。
一、数据类型
RedisObject 给redis key value不是直接存储,而是包装了一层。
数据结构
typedef struct redisObject
{
unsigned type:4;(OBJ_ENCODING_RAW...OBJ_ENCODING_HT)
unsigned encoding:4; (OBJ_ENCODING_RAW:。。。)
unsigned lru:REDIS_LRU_BITS; //最后一次更新的时间
/* lru time (relative to server.lruclock) */
int refcount; 引用计数
void *ptr; 数据指针//指向真正的数据
} robj;
1、String类型,底层数据结构(字符串长度<21转为整数,整数储存int。)
存储长度<=39,转为embstr简单动态字符串SDS和Redis Object一起分配),
( int格式,当数据值为数字且长度小于20时,就会采用int格式进行存储,此时不需要用到sds结构体,直接将redisObject中ptr字段的值改为该数字(注:当数值为0-10000时,key会指向预先创建好的redisObject,而不需要新建redisObject))
embstr创建只分配一次内存,
而raw为两次,分别给RedisObject和SDS分配空间。
SDS(简单动态字符串)。
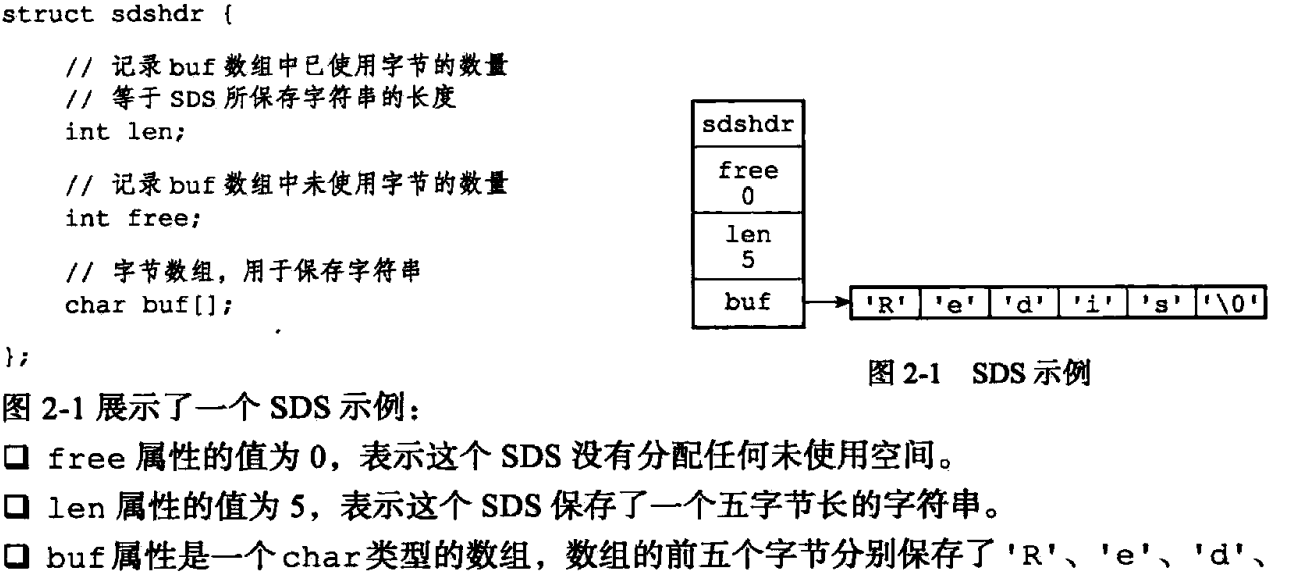
优点:
1、不用遍历就能获取长度, (封装到了结构体的,可以直接访问len属性)
2、拥有自动扩容机制(SDS中剩余空间大于新增内容的长度是否需要扩容),预分配机制,如果分配后的大小小于1MB,就会分配A+A+1=2A+1的空间,A是本次要用的空间
如果大于1MB程序分配1MB,程序会用A+1MB+1byte的长度。
3、不同于C语言字符串,二进制安全。(不会收到'\0'字符影响,C语言字符串是\0阶段)
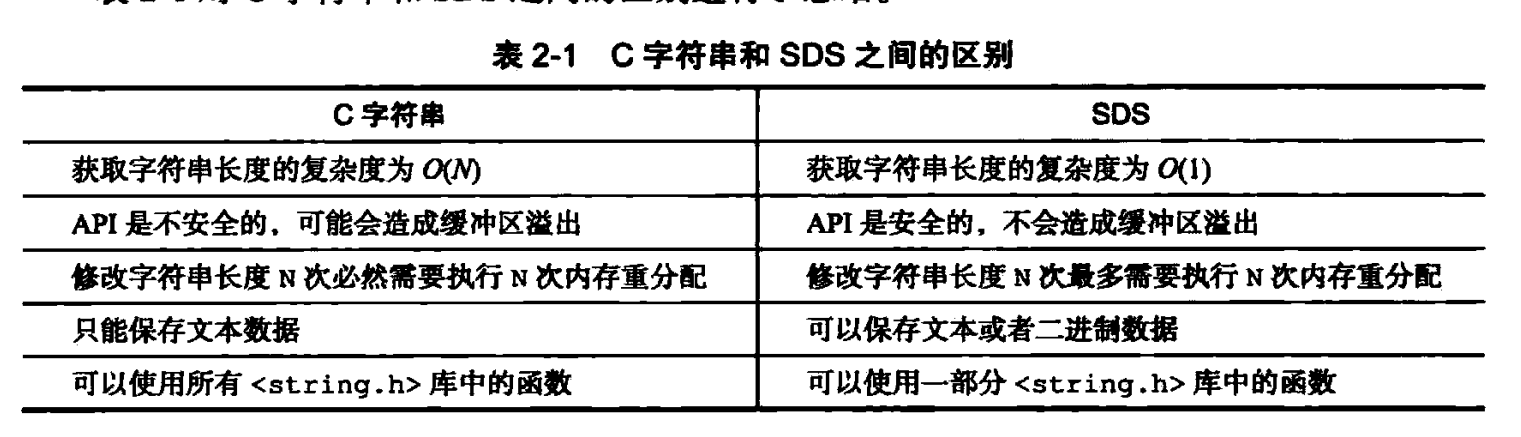
二进制安全:C语言字符必须使用某一种字符编码,并且除了字符串的末尾之外,字符串不能包含空字符,否则最先被程序读入的空字符会被认为是空字符串,使得C字符串只能保存文本数据,不能保存图片、音频、视频等数据。
SDS API都会以处理二进制的方式,来处理SDSS存放在buif数组里的数据,程序不会对其中数据做任何限制,假设,过滤,数据写入是怎样,就是怎样。也就是说SDS buf属性保存以二进制方式来保存,不会按照C语言字符字符串的方式来保存。就不会对'\0'这种字符影响。所以redis不是用buf数组保存字符,而是保存一系列二进制数据。——所以buf属性被称为字节数组。
字符串必须有'\0'结束但字符数组可以没有。所以用的char数组保存二进制数据。
字符串是特殊的字符数组,字符串是必须以'\0'结尾,编译器也会自动加上。而char数组,不会以null作为结尾,看到null也不会停止遍历。
4、SDS拥有惰性空间释放机制,减少了内存重新分配的次数。(预分配减少空间分配)。
惰性机制:程序不立即使用内存重分配回收缩短后的字节。使用free属性将这些字节数量记录起来,并等待将来的使用。
ReadObject
1.1 基本的key-value类型,Redis利用C语言写的,但是Redis并没有用C的字符串表示,而是自己构建了一种简单的动态字符串。
相比C的原生字符串,Redis的SDS不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度的复杂度为O(1)
1.2 常用命令:set、get、strlen、incr、decr、setex等
1.3 应用场景:一般常用在需要计数的场景,比如用户访问次数、热点文章的转发等
2、LIST类型 底层数据结构是 双向链表/quicklist(双链表+压缩列表(优点、插入删除更方便,两端访问是O(1),微观上是一片一片的entry节点,可以二分查找))、压缩列表
当列表对象同时满足一下条件,列表对象使用ziplist进行存储,否则用linkedlist。
1、列表对象保存的所有字符串元素小于64字节。
2、列表对象保存的元素数量小于512个
2.1 list即是一种链表。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除可以灵活调整链表的长度。许多高级语言java也有linkedlist,redis的list实现是一个双向链表。
牺牲时间换空间。
ZipList类似于双向链表,是由一系列的特殊编码连续内存快组成,不存储上一个节点或者下一个节点的指针,而是存储上一个节点长度和当前节点的长度,牺牲时间换空间。

zlbytes:记录了压缩列表占用的内存字节数,在对压缩列表进行内存重分配,或者计算zlend的位置时使用。它本身占了4个字节。
zltail:记录了尾节点(entry)至起始节点(entry)的偏移量。通过这个偏移量,可以快速确定最后一个entry节点的地址。
zllen:记录了entry节点的数量。当zllen的值小于65535时,这个值就表示节点的数量。当zllen的值大于65535时,节点的真实数量需要遍历整个压缩列表才能得出。
entry:压缩列表中所包含的每个节点。每个节点的长度根据该节点的内容来决定。
zlend:特殊值0XFF,标记了压缩列表的末端。表示该压缩列表到此为止。
特点:
1、压缩列表本身是一个连续的内存块,由表头、若干个entry节点和压缩列表尾部标识符组成,提高内存的利用率,适用于存储整数和短字符串。
2、压缩列表ZipList结构的缺点是:每次插入或删除需要频繁移动,搬数组节点。
2.2 常用命令rpush,lpop,lpush,rpop,lrange,llen等
应用场景:发布与定于或者消息队列、慢查询。
3、Hash Ziplist+hash
3.1 类似于jdk8中的hashmap,内部实现也差不多(数组+链表),不过redis的hash做了更多的优化。hash是一个string类型的field和value的映射表,特别适用于存储对象,后续操作的时候,可以仅仅修改对象的某个字段。比如hash数据结构来存储用户信息,商品信息等。
3.2 常用命令:hset、hmset、hexists、hget、hgetall、hvals等
3.3 应用场景:系统中对象数据的存储。
(hmset userInfoKey name "guide" description "dev" age "24")
4、Set hash+整数数组
4.1 类似于java中的hashset,redis中的set类型是一种无需集合,集合中元素没有先后。set可以轻易实现交集、并集、差集等。比如共同粉丝共同关注等。
4.2 sadd、spop,smembers,sismember,scard,sinterstore,sunion等
4.3 需要存放的数据不能重复以及需要获得数据的交集和并集等
5、zset ziplist+跳表
5.1 和set相比,sorted增加了一个权重参数score,使得集合中的元素能够按score进行有序排列,还可以通过score的范围获取元素。有点像java hashmap和treeset的结合体
5.2 常用命令:zadd、zcard,zscore、zrange,zrevrange,zrem等
5.3 需要对数据某个权重进行排序的场景。比如直播系统中,实时排行信息,包含直播间礼物排行,在线用户列表,各种礼物排行等。
6、bitmap
6.1 bitmap存储的是连续的二进制数字(0和1),通过bitmap,只需要一个bit位来表示某个元素对应的值,key就是对应元素本身。bitmap很节省空间
6.2 常用命令:setbit、getbit、bitcount、bitop
6.3 应用场景:适合需要保存状态信息(签到、登录)并需要进一步对这些信息进行分析的场景,用户签到情况,活跃用户情况,用户行为统计,比如用户是否点赞过某个视频
SpringCache 与 Redis 区别
1、Spring cache是代码级的缓存,一般是使用一个ConcurrentMap,也就是实际上还是使用JVM的内存来缓存对象,势必造成大量的内存消耗。
2、Redis是一个缓存数据库,内存级的,支持分布式存储。
3、集群环境下,每天服务器的Spring Cache是不同步的,这样会出问题,SpringCache只适合单机环境
4、Redis是设置单独的缓存服务器,所有集群服务器可以统一访问Redis,不会出现缓存不同步的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号