C++提高编程
模板
模板就说简历通用的模具,提高代码复用性
1、模板不可以直接使用,它只是一个框架
2、模板的通用并不是万能
模板机制分为两种机制:函数模板和类模板。
函数模板作用:
建立一个通用函数,起函数返回值类型和形参类型可以不制定,用一个虚拟的类型来代表
语法:
template<typename T>
函数声明或定义
解释:template --- 声明创建模板
typename --- 表明其后面的符号是一种数据类型,可以用class代替
T --- 通用的数据类型,名称可以替换,通常为大写字母
template<typename T>
template<class T>
函数模板的注意事项
模板必须确定出T的数据类型,才可以使用
template<class T> //不能推导出数据类型
void func( ){
cout<<"hello"<<endl;//执行错误。
}
void test02()[
func();//错误
func<int>();
1、自动类型推导,必须推导出一致的数据类型T才可以使用
2、模板必须确定出T的数据类型,才可以使用
函数模板案例
案例:
1、利用函数模板封装成一个排序函数,可以对不同数据类型数组进行排序
2、排序规则从大到小,排序算法为选择排序
3、分别利用char数组和int数组进行测试
普通函数与函数模板的区别:
1、普通函数调用时可以发生自动类型转换(隐式类型转换)
2、普通模板调用时,如果利用自动类型推导,不会发生隐式类型转换
3、如果利用显示指定类型的方式,可以发生隐式的类型转换。
myfunc<int>(a,c);
普通函数与函数模板的调用规则:
1、如果函数模板和普通函数都可以实现,优先调用普通函数。
2、可以通过空模板参数列表来强制调用函数模板 myfunc<>();
3、函数模板也可以发生重载
4、如果函数模板可以产生更好的匹配,优先调用函数模板。如
template <typename T>
void ChoSort(T a,T b) {
cout << "调用函数模板" << endl;
}
void ChoSort(int a,int b){
cout << "调用普通函数" << endl;
}
编译器不做隐私转换。
总结:既然提供了函数模板,最好不要提供普通函数,否则会出现二义性。
模板的局限性
局限性:
模板的通用性并不是万能的
//对比两个数据是否相等。
template<class T>
bool myCompare(T &a, T &b) {
if (a == b) {
return true;
}
else {
return false;
}
}
具体化的模板,针对于自定义数据类型
template<> bool myCompare(Person &p1, Person &p2) {
if (p1.age == p2.age&&p1.name == p2.name) {
return true;
}
else {
return false;
}
}
总结:
1、利用具体化的模板,可以解决自定义类型的通用化
2、学习模板并不是为了些模板,而是在STL能够运用系统的模板
类模板
语法:
template <typename T>
类模板和函数模板的区别:
1、类模板没有自动推导的使用方式
Person<string, int> p1("孙悟空", 99);//只能用显示指定类型。
2、类模板在模板参数列表中可以有默认参数
template<class NameType,class AgeType=int>
类模板成员函数创建时机
类模板对象做函数参数
1、指定传入的类型 --- 直接显示对象的数据类型
2、参数模板化 --- 将对象中的参数变为模板进行传递
3、整个类模板化 --- 将这个对象类型 模板化进行传递
//1、指定传入类型
void printPerson1(Person<string, int> &p) {
p.showPerson();
}
//2、参数模板化
template<class T1,class T2>
void printPerson2(Person<T1, T2> &p) {
p.showPerson();
cout << "T1的类型为:" << typeid(T1).name() << endl;
cout << "T2的类型为:" << typeid(T2).name() << endl;
}
void test01() {
Person<string, int>p("孙悟空", 200);
printPerson2(p);
}
//3、整个类模板化
template<class T>
void printPerson(T &p) {
p.showPerson();
cout << "T的数据类型为:" << typeid(T).name() << endl;
}
类模板和继承
当类模板碰到继承,需要注意一下几点:
1、当子类继承的父类是一个类模板时,子类在声明的时候,要指定出父类中T的类型。
2、如果不指定,编译器无法给子类分配内存。
3、如果想灵活指定出父类中T的类型,子类也需要变为类模板。
总结如果父类是类模板,子类需要指定出父类中T的数据类型。
//类成员函数的类外实现
template<class T1,class T2>
class Person {
public:
Person(T1 name, T2 age);// {
// this->m_Name = name;
// this->m_Age = age;
//}
void showPerson();/* {
cout << this->m_Name << this->m_Age << endl;
}*/
T1 m_Name;
T2 m_Age;
};
//构造函数的类外实现
template<class T1, class T2>
Person<T1,T2>::Person(T1 name, T2 age) {
this->m_Age = age;
this->m_Name = name;
}
//成员函数的类外实现
template<class T1, class T2>
void Person<T1,T2>::showPerson() {
cout << "类内函数" << endl;
}
//总结:类模板中 成员函数在类外实现时,需要加上模板的参数列表
void test() {
Person<string, int> P("tom", 20);
P.showPerson();
}
类模板分文件编写
问题:类模板中成员函数创建时机是在调用阶段,导致部份文件编写时链接不到。
解决:1、直接包含cpp源文件,2、将声明和实现写到同一个文件中,并更改后缀名为.hpp,hpp是约定的名称,并不是强制。(第二种 包含源文件.cpp .cpp中包含了头文件.h )
类模板与友元
全局函数类内实现-直接在类内声明友元即可
全局函数类外实现-需要提前在编译器知道全局函数的存在
类模板案例
template<class T>
class MyArray {
private:
T *pAddress;//指针指向堆区开辟的真实数组
int m_Capacity;//数组容量
int m_Size;//数组大小
public:
//有参构造
MyArray(int capacity) {
this->m_Capacity = capacity;
this->m_Size = 0;
this->pAddress = new T[this->m_Capacity];
cout << "myArray有参构造" << endl;
}
//拷贝构造
MyArray(const MyArray& arr) {
cout << "myArray拷贝构造" << endl;
this->m_Capacity = arr.m_Capacity;
this->m_Size = arr.m_Size;
//深拷贝
this->pAddress = new T[arr.m_Capacity];
//将原array数据拷贝到现在数组中
for (int i = 0; i < this->m_Size; i++) {
pAddress[i] = arr.pAddress[i];
}
}
//operator= 防止浅拷贝问题a=b=c
MyArray& operator=(const MyArray& arr) {
//先判断原来堆区是否有数据
//如果有限释放
if (this->pAddress != NULL) {
delete[] this->pAddress;
this->pAddress = NULL;
this->m_Capacity = 0;
this->m_Size = 0;
}
//深拷贝
this->m_Capacity = arr.m_Capacity;
this->m_Size = arr.m_Size;
this->pAddress = new T[arr.m_Capacity];
for (int i = 0; i < this->m_Size; i++) {
this->pAddress[i] = arr.pAddress[i];
}
return *this;
}
//析构函数
~MyArray() {
cout << "myArray析构构造" << endl;
if (pAddress != NULL) {
delete[] this->pAddress;
this->pAddress = NULL;
}
}
};
STL基本概念
STL(standardtemplate library,标准模板库)
STL从广义上分为:容器container算法algorithm迭代器iterator
容器和算法之间通过迭代器无缝连接
STL几乎所有的代码都采用了模板类或者模板函数
STL六大组件
STL大体分为六大组件,分别为:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
1、容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据
2、算法:各种常用的算法,如sort、find、copy、for_each等
3、迭代器:扮演了容器与算法之间的胶合剂
4、仿函数:行为类似函数,可作为算法的某种策略
5、适配器:一种用来修饰容器或者仿函数或迭代器接口的东西
6、空间配置器:负责空间的配置与管理
容器分为了:
1、序列式容器:强调值的排序,序列式容器中每个元素都有固定的位置 1 3 5 4 2
2、关联式容器:二叉树结构,各元素之间没有严格的物理上的顺序关系 1 2 3 4 5
算法分为:质变算法和非质变算法
质变算法:是指运算过程中会更改区间内的元素的内容。例如拷贝,替换、删除
非质变算法:是指运算过程中不会更改区间内的元素的内容。例如查找、计数、寻找极值
迭代器:容器和算法之间的迭代器
提供一种方法,使之能够依序寻访某个容器所含的各个元素,而无需暴露该容器的内部表示方法
每个容器都有自己专属的迭代器。
Vector存放内置数据类型
容器:vector
算法:for_each
迭代器:vector<int>::iterator
示例:
//vector容器中存放自定义数据类型
class Person {
public:
Person(string name, int age) {
this->m_Name = name;
this->m_Age = age;
}
string m_Name;
int m_Age;
};
//存放自定义数据类型
void test01() {
vector<Person> v;
Person p1("aaa",10);
Person p2("bbb",10);
Person p3("ccc",10);
Person p4("ddd",10);
Person p5("eee",10);
Person p6("fff",10);
//向容器中添加数据
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
v.push_back(p4);
v.push_back(p5);
v.push_back(p6);
//遍历容器中的数据
for (vector<Person>::iterator it = v.begin(); it != v.end(); it++) {
cout << "姓名:"<<(*it).m_Name << endl;
cout << "姓名:"<<it->m_Name << endl;
cout << "年龄:"<<(*it).m_Age << endl;
cout << "年龄:"<<it->m_Age << endl;
}
}
int main() {
test01();
}
嵌套容器
void test01() {
vector<vector<int>> v;
//创建小容器
vector<int>v1;
vector<int>v2;
vector<int>v3;
vector<int>v4;
//向小容器中添加数据
for (int i = 0; i < 4; i++) {
v1.push_back(i + 1);
v2.push_back(i + 2);
v3.push_back(i + 3);
v4.push_back(i + 4);
}
//将小容器中插入到大的容器中
v.push_back(v1);
v.push_back(v2);
v.push_back(v3);
v.push_back(v4);
//通过大容器,把所有的数据遍历一次。
for (vector<vector<int>>::iterator it = v.begin(); it != v.end(); it++) {
for (vector<int>::iterator vit = (*it).begin(); vit != (*it).end(); vit++) {
cout << *vit << " ";
}
cout << endl;
}
}
String基本概念
string和char*的区别
char*是一个指针
string 是一个类,类的内部封装了char*,来管理这个字符串,是一个char*型的容器
特点
string类内部封装了很多方法
查找fInd、拷贝copy,删除delete替换replace,插入insert
string管理char*所分配的内存,不用担心复制越界和取值越界,由类内部进行负责。
string构造函数
构造函数原型
string();//创建一个空的字符串 例如string str;
string(const char* s);//使用字符串S初始化
string(const string& str);//使用一个string对象初始化另一个string对象
string(int n,char c);使用n个字符c初始化
总结:灵活运用,没有可比性。
void test04() {
string s1;//默认构造
const char *str = "hello world";
string s2(str);
cout << "s2=" << s2 << endl;
string s3(10, 'a');
cout << "s4=" << s3 << endl;
}
字符串拼接

str3.append(str2,0,2); //0是起始,2是长度 参数2是从那个位置开始截,参数3是截取的个数
字符串查找

rfind和find区别
rfind从右往左
find是从做往右
字符串比较大小

string字符存取

可以修改。
string插入和删除

string字串

Vector

void printVector(vector<int> &v) {
for (vector<int>::iterator it = v.begin(); it != v.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
//复制string
void test04() {
vector<int>v1;//默认构造 无参构造
for (int i = 0; i < 10; i++) {
v1.push_back(i);
}
printVector(v1);
//通过区间方式构造
vector<int> v2(v1.begin(), v1.end());
printVector(v2);
//n个elem方式构造
vector<int> v3(10, 100);//第一个参数是个数 第二个是元素
printVector(v3);
//拷贝构造
vector<int> v4(v3);
printVector(v4);
}

//vector赋值
void test04() {
vector<int> v1;
for (int i = 0; i < 10; i++) {
v1.push_back(i);
}
printVector(v1);
if (v1.empty()) {//为真 代表容器为空
cout << "v1为空" << endl;
}
else {
cout << "v1不为空" << endl;
}
cout << "v1的容量:" << v1.capacity() << endl;//容量都大于等于size
cout << "v1的容量:" << v1.size() << endl;
v1.resize(15);//如果重新制定的比原来的长了,用0来进行填充新的位置。
v1.resize(15, 10);//用10来填充
v1.resize(5);//比原来短了,超出部分被删除
printVector(v1);
}
vector插入和删除

void test04() {
vector<int> v1;
v1.push_back(5);//尾插
v1.push_back(5);//尾插
v1.push_back(5);//尾插
v1.push_back(5);//尾插
v1.push_back(5);//尾插
printVector(v1);
v1.pop_back();//尾删
printVector(v1);
//插入第一个参数是迭代器
v1.insert(v1.begin(), 100);//在第一个位置插入100
printVector(v1);
//删除第一个参数也是迭代器
v1.erase(v1.begin());//删除第一个元素
printVector(v1);
v1.erase(v1.begin(), v1.end());//从头清空到尾
v1.clear();//全部清空
printVector(v1);
}
Vector数据存取

for (int i = 0; i < v1.size(); i++) {
cout << v1[i] << " "<< v1.at(i) <<endl;
}
cout << "获取第一个元素" << v1.front()<<endl;
cout << "获取最后一个元素" << v1.back()<<endl;
vector互换容器
将vec与本身互换。
reserve vector预留函数
v1.reserve(10000);
总结:如果数据量较大的时候,可以一开始利用reserve预留空间
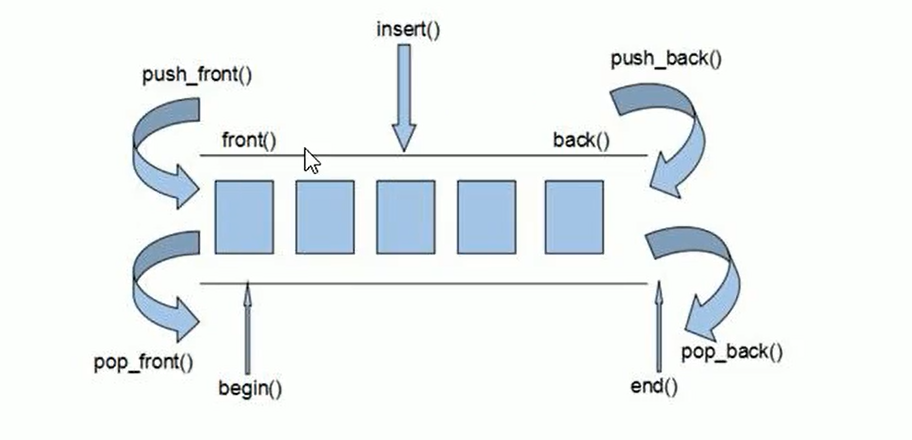
deque容器基本概念
功能:双端数组,可以对头端进行插入删除操作。
deque与vector区别
1、vector对于头部的插入删除效率低,数据量越大,效率越低。
2、deque相对而言,对头部插入删除的速度比vector更快
3、vector访问元素时的速度会比deque快,这和两者内部实现有关
deque容器的迭代器也支持随机访问
deque构造函数

deque赋值操作

deque大小操作

没有容量的概念。 没有capacity这个方法。
deque插入和删除

deque排序

stack栈

总结
入栈-push
出栈-pop
栈顶-top
判断栈是否为空--empty
返回栈大小--size
Queue队列
一种先进先出的数据结构,他又两个出口

List容器
功能:将数据进行链式存储
STL是一个双向循环链表
优点:动态存储分配,不会造成内存浪费和溢出
缺点:链表灵魂,但是空间指针域和时间遍历额外耗费较大
List有一个重要的性质,插入操作和删除操作都不会造成list迭代器的失效,这在vector中不成立的。
总结:STL和Vector是两个最被使用的容器,各有优缺点。


it++//支持双向
it--
不支持随机访问[] at it=it+1;

L1.reverse();
sort(l1.begin(),l1.end());//支持随机访问
L1.sort(Mycompare);
//所有不支持随机访问迭代器的容器,不可以用标准算法
//不支持随机访问迭代器的容器,内部会提供对应的方法。
bool compareObject(const Person p1,const Person p2) {
if (p1.m_Age - p2.m_Age >= 0)
return true;
else
return false;
}
总结:
对于自定义数据类型,必须指定排序规则,否则编译器不知道如何进行排序
高级排序在排序规则上再进行一次逻辑规则指定。
set/multiset容器
所有元素在插入时会自动排序‘
本质:set/mulset属于关联式容器,底层结构是用二叉树实现
set和multiset区别
set不允许容器中有重复元素
multiset允许容器中有重复元素


set容器和multiset容器区别
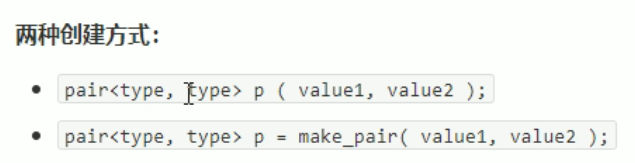
pair对组创建
功能描述:
成对出现的数据,利用对组可以返回两个数据
set容器 自定义排序
利用仿函数,可以改变排序规则
map/multimap容器

map<int,int> m;默认构造
m.insert(pair<int,int>(10,10));//插入

m.swap(m1);

m.erase(3) 删除key为3的对


总结:对于自定义数据类型,map必须指定排序规则同set容器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号