[java源码解析]对HashMap源码的分析(一)
最近有空的时候研究了下HashMap的源码,平时我用HashMap主要拿来当业务数据整理后的容器,一直觉得它比较灵活和好用,
这样
的便利性跟它的组成结构有很大的关系。
直接开门见山,先简要说明一下HashMap的数据结构(结构层面)以及基本的实现思路(算法层面)
HashMap的数据结构是哈希表,我们都知道数组的特点是:寻址容易,插入删除困难。链表的特点是寻址困难,插入删除容易。HashMap的哈希表实现方式
折中了数组以及链表各自的优点。
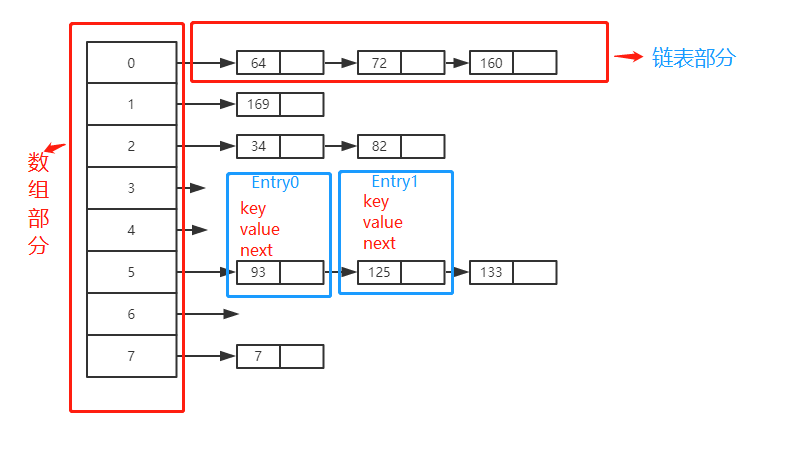
上图就是HashMap的数据结构,数组+链表的形式。由上图为例,上图的数组是一个长度为8的数组,每个元素存储的是链表的头结点。链表部分存储的就是HashMap的元素,一个个元素就是一个个的实体Entry(包括key,value,next)。
数组逻辑结构部分:
那么HashMap的元素的存入数组的规则是怎样的呢。一般通过hash(key) % len 获得。
用一个公式表示就是 : index = hash(key) % len;
注:index是数组的下标,key是HashMap元素的key值,len是数组的长度。
比如上图数组的长度是8,64%8,72%8,160%8 都等于0,所以都存入数组index=0的位置里。也就是说咱们的HashMap的容器就是一个线性数组。
链表逻辑结构部分:
那么问题来了,数组怎么直接用键(key)来存取数据的,处理方式就是我们的链表部分了。比如从上图我们看到链表的每一个元素存储的就是一个Entry实体类,每个Entry包含(key,value,next)。key,value我们都很熟悉啦,不就是我们平时使用hashMap的两个属性吗。next是连接同一个index的数据,因为总存在取模一样的hash(key)呀~,比如上图的64,72,160直接的连接。从上面可以看出Entry就是HashMap键值对实现的一个基础bean。
我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。下面是代码实现
/** * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
下篇我们介绍HashMap的算法层面,也就是它的实现部分。敬请期待

 浙公网安备 33010602011771号
浙公网安备 33010602011771号