在 window 上安装 pyspark 并使用( 集成 jupyter notebook)
参考了https://blog.csdn.net/m0_37937917/article/details/81159193
预装环境:
1、安装了Anaconda ,可以从清华镜像下载。
2、环境安装了java,版本要7以及更高版本
在前面的环境前提下
开始下载安装pyspark
下载 Apache Spark ,访问 Apache Spark 官网下载
1、 选择一个 Spark 版本 (Choose a Spark release)
2、选择软件包类型 (Choose a package type)
3、点击下载

4、选择一个开始下载,只是镜像位置不一样而已,内容无差
一般选择最新版本就行,也就是默认选择版本
ps:这边有个我直接下载好的,需要可以直接点击链接下载

5、将你下载得到的 spark-2.4.3-bin-hadoop2.7.tgz 解压,得到 spark-2.4.3-bin-hadoop2.7
我这边下载下来的文件名是这样的,根据实际为准。
将解压下来的 spark-2.4.3-bin-hadoop2.7 文件夹放到你想放的位置,我这边是 E:\MyDownloads\pyspark

6 . 从链接下载 winutils.exe 并放到你电脑中的 spark-2.4.3-bin-hadoop2.7\bin 文件夹下。
winutils.exe 是用来在windows环境下模拟文件操作的。
7、修改环境变量
添加以下变量到你的环境变量:
变量名 变量值
-
SPARK_HOME spark-2.4.3-bin-hadoop2.7
HADOOP_HOME spark-2.4.3-bin-hadoop2.7
PYSPARK_DRIVER_PYTHON jupyter
PYSPARK_DRIVER_PYTHON_OPTS notebook
-
- 添加 ;E:\MyDownloads\pyspark\spark-2.4.3-bin-hadoop2.7\bin 到 PATH ps:这里的路径以你的实际为准
此时安装已经基本完成了
8 、打开 cmd,输入命令行 spark-shell ,看到如下字样,说明安装成功

pyspark 案例实验一下
打开cmd ,输入 jupyter notebook 启动

新建个python文件,然后
输入以下代码,点运行

代码:
import os
import sys
spark_name = os.environ.get('SPARK_HOME',None)
if not spark_name:
raise ValueErrorError('spark环境没有配置好')
接着输入以下代码,点运行
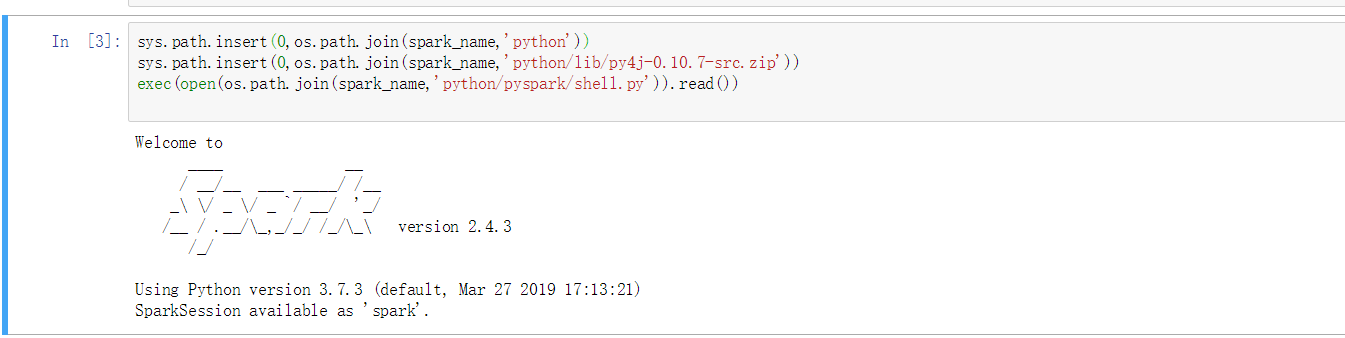
sys.path.insert(0,os.path.join(spark_name,'python')) sys.path.insert(0,os.path.join(spark_name,'python/lib/py4j-0.10.7-src.zip')) exec(open(os.path.join(spark_name,'python/pyspark/shell.py')).read())
这样说明pyspark引入成功了!
报错处理:
如果出现 无法加载 pyspark ,提示错误:No module named 'pyspark' 。
原因是: Anaconda 的环境变量中没有加入 pyspark 。
解决方案:将目录 spark-2.4.3-bin-hadoop2.7\python 中 spark 文件夹复制放入目录 Anaconda3\Lib\site-packages 中。(你安装Anaconda的地方)
创建RDD实例试验

myRDD = sc.parallelize(range(6), 3) print(myRDD.collect()) print(myRDD.count())
自此,安装pyspark 成功结束,欢迎指教,欢迎交流讨论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号