Spark 宽窄依赖和stage的划分
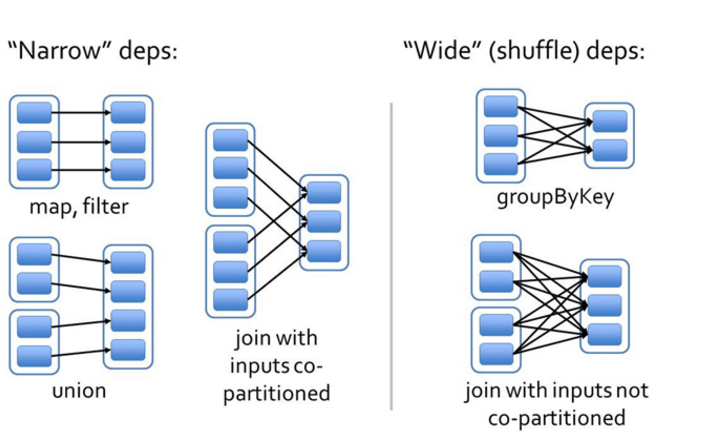
窄依赖
父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。
不会有shuffle的产生,父RDD的一个分区去到子RDD的一个分区。
多对一或者一对一
可以理解为独生子女
宽依赖
父RDD与子RDD partition之间的关系是一对多。
会有shuffle的产生,父RDD的一个分区的数据去到子RDD的不同分区里面。
一对多
可以理解为超生
常见的宽窄依赖
窄依赖:filter map flatmap mapPartitions
宽依赖:reduceByKey grupByKey combineByKey,sortByKey, join(no copartition)
Stage
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage
划分stage的整体思路
从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号