sqoop 导入增量数据到hive
版本
hive:apache-hive-2.1.0
sqoop:sqoop-1.4.6
hadoop:hadoop-2.7.3
导入方式
1.append方式
2.lastmodified方式,必须要加--append(追加)或者--merge-key(合并,一般填主键)

创建mysql表并添加数据
-- ---------------------------- -- Table structure for `data` -- ---------------------------- DROP TABLE IF EXISTS `data`; CREATE TABLE `data` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` char(20) DEFAULT NULL, `last_mod` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of data -- ---------------------------- INSERT INTO `data` VALUES ('1', '1', '2019-08-28 17:34:51'); INSERT INTO `data` VALUES ('2', '2', '2019-08-28 17:31:57'); INSERT INTO `data` VALUES ('3', '3', '2019-08-28 17:31:58');
先将mysql表数据全部导入hive
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy --username root --password 123456 --table data --hive-import --fields-terminated-by ',' -m 1
注意:fields-terminated-by 要是不指定值的话,默认分隔符为'\001',并且以后每次导入数据都要设置 --fields-terminated-by '\001',不然导入的数据为NULL。建议手动设置 --fields-terminated-by的值

成功导入之后,会在HDFS的/soft/hive/warehouse/data看到数据文件
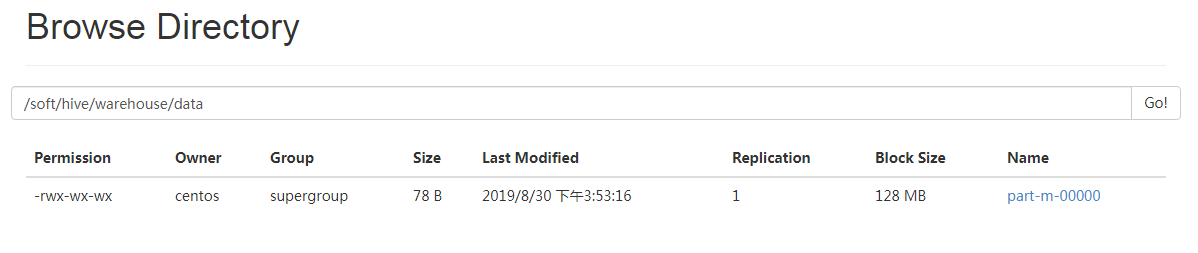
默认生成的hive表为内部表,内部表的数据文件默认保存路径为/user/hive/warehouse,我在hive-site.xml中,把hive.metastore.warehouse.dir值设成了/soft/hive/warehouse
hive表数据
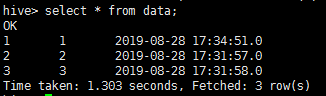
增量导入--append方式导入
官网说append方式下,append 用于自增的 id 列(lastmodified 用于更新的日期列),但是我自己动手发现append方式下,也可以通过时间类型增量导入
官网原文:You should specify append mode when importing a table where new rows are continually being added with increasing row id values. You specify the column containing the row’s id with --check-column. Sqoop imports rows where the check column has a value greater than the one specified with --last-value.
1.last-value是数字类型(推荐)
往mysql插入2条数据
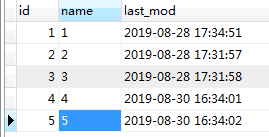
--targrt-dir的值设置成hive表数据文件存储的路径。假如你的hive表为外部表,则--targrt-dir要指向外部表的存储路径
--last-value 3,意味mysql中id为3的数据不会被导入
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \ --username root \ --password 123456 \ --table data \ --target-dir '/soft/hive/warehouse/data' \ --incremental append \ --check-column id \ --last-value 3 \ -m 1
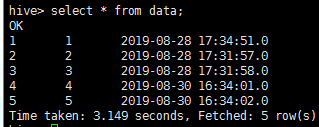
导入成功之后查看数据
2.last-value是时间类型(不推荐)
mysql新增2条数据

执行sqoop命令,按 --check-column last_mod --last-value '2019-08-30 16:34:02' 条件查找
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \ --username root \ --password 123456 \ --table data \ --target-dir '/soft/hive/warehouse/data' \ --incremental append \ --check-column last_mod \ --last-value '2019-08-30 16:34:02' \ -m 1
查看hive数据(mysql中,时间值为2019-08-30 16:34:02的数据不会被导入)

增量导入--lastmodified方式导入
lastmodified 用于更新的日期列
1.--incremental lastmodified --append
将mysql新插入3条数据,并且把id为7的name做了修改
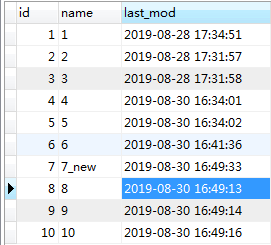
执行sqoop命令 (--incremental lastmodified --append方式下,mysql中和--last-value指定的值相等的数据也不会被导入,所以想要让id为8的数据也导入进去,last-value的值就应该比id为8的数据的时间要小)
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \ --username root \ --password 123456 \ --table data \
--target-dir '/soft/hive/warehouse/data' \ --check-column last_mod \ --incremental lastmodified \ --last-value '2019-08-30 16:49:12' \ --m 1 \ --append
结果
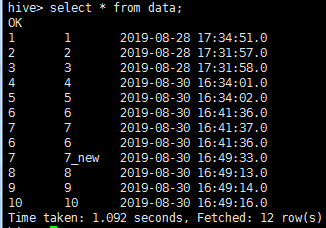
可以看到,7,8,9,10都导入进来了,表中出现了2个id为7的数据,出现了数据重复
--incremental lastmodified --append的作用:把大于last-value时间的数据都导入进来,之前就存在但是后期修改过的数据并不会进行合并,只会当做新增的数据加进来,所以使用--incremental lastmodified --append有可能导致数据重复的问题
2.--incremental lastmodified --merge-key
往mysql插入2条数据,并且把id为10的数据做了修改

执行sqoop命令(--merge-key的值一般填主键,merge-key方式下,mysql中时间和last-value相同的数据会被导入)
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \ --username root \ --password 123456 \ --table data \ --target-dir '/soft/hive/warehouse/data' \ --check-column last_mod \ --incremental lastmodified \ --last-value '2019-08-30 17:05:49' \ --m 1 \ --merge-key id
结果

可以看到,新数据11,12都被加了进来,id为10的值做了合并操作,修改后的"10_new"替换了原来的"10",没有数据重复的现象
并且,id为7的数据也被合并了,可是last-value的值明明比id为7的时间要大,原因是:只要出现id重复的情况,就合并数据,不考虑时间条件。id不为重复的情况下,才会考虑时间条件
--incremental lastmodified --merge-key的作用:修改过的数据和新增的数据(前提是满足last-value的条件)都会导入进来,并且重复的数据(不需要满足last-value的条件)都会进行合并

 浙公网安备 33010602011771号
浙公网安备 33010602011771号