



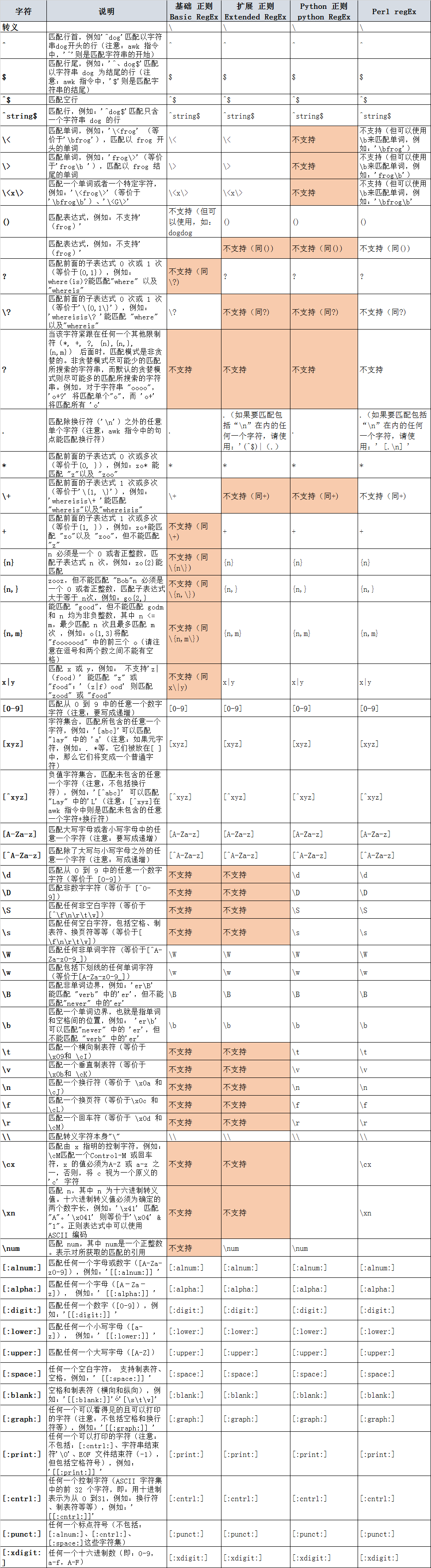
##什么是正则
'''
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符
串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,
并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引
擎执行.
'''
import re # print(re.findall('\w','hello_ | egon 123')) #匹配字母数字下划线,单个字符进行匹配 # print(re.findall('\W','hello_ | egon 123')) #匹配非字母数字下划线 # print(re.findall('\s','hello_ | egon 123 \n \t')) # print(re.findall('\S','hello_ | egon 123 \n \t')) # print(re.findall('\d','hello_ | egon 123 \n \t')) # print(re.findall('\D','hello_ | egon 123 \n \t')) # print(re.findall('h','hello_ | hello h egon 123 \n \t')) # # print(re.findall('\Ahe','hello_ | hello h egon 123 \n \t')) # print(re.findall('^he','hello_ | hello h egon 123 \n \t')) # # print(re.findall('123\Z','hello_ | hello h egon 123 \n \t123')) # print(re.findall('123$','hello_ | hello h egon 123 \n \t123')) # print(re.findall('\n','hello_ | hello h egon 123 \n \t123')) # print(re.findall('\t','hello_ | hello h egon 123 \n \t123'))
['h', 'e', 'l', 'l', 'o', '_', 'e', 'g', 'o', 'n', '1', '2', '3'] [' ', '|', ' ', ' '] [' ', ' ', ' ', ' ', '\n', ' ', '\t'] ['h', 'e', 'l', 'l', 'o', '_', '|', 'e', 'g', 'o', 'n', '1', '2', '3'] ['1', '2', '3'] ['h', 'e', 'l', 'l', 'o', '_', ' ', '|', ' ', 'e', 'g', 'o', 'n', ' ', ' ', '\n', ' ', '\t'] ['h', 'h', 'h'] ['he'] ['he'] ['123'] ['123'] ['\n'] ['\t']
#. [] [^] #.本身代表任意一个字符
# print(re.findall('a.c','a a1c a*c a2c abc a c aaaaaac aacc'))
#a.c
# print(re.findall('a.c','a a1c a*c a2c abc a\nc',re.DOTALL))
# print(re.findall('a.c','a a1c a*c a2c abc a\nc',re.S))
#[]内部可以有多个字符,但是本身只配多个字符中的一个
# print(re.findall('a[0-9][0-9]c','a a12c a1c a*c a2c a c a\nc',re.S))
# print(re.findall('a[a-zA-Z]c','aac abc aAc a12c a1c a*c a2c a c a\nc',re.S))
# print(re.findall('a[^a-zA-Z]c','aac abc aAc a12c a1c a*c a2c a c a\nc',re.S))
# print(re.findall('a[\+\/\*\-]c','a-c a+c a/c aac abc aAc a12c a1c a*c a2c a c a\nc',re.S))
['a12c'] ['aac', 'abc', 'aAc'] ['a1c', 'a*c', 'a2c', 'a c', 'a\nc'] ['a-c', 'a+c', 'a/c', 'a*c']
#\:转义
# print(re.findall(r'a\\c','a\c abc')) #rawstring
#? * + {}:左边有几个字符,如果有的话,贪婪匹配
#?左边那一个字符有0个或者1个 # print(re.findall('ab?','aab a ab aaaa')) #ab?
#*左边那一个字符有0个或者无穷个
# print(re.findall('ab*','a ab abb abbb abbbb bbbbbb'))
# print(re.findall('ab{0,}','a ab abb abbb abbbb bbbbbb'))
['a', 'ab', 'abb', 'abbb', 'abbbb'] ['a', 'ab', 'abb', 'abbb', 'abbbb']
#+左边那一个字符有1个或者无穷个
# print(re.findall('ab+','a ab abb abbb abbbb bbbbbb'))
# print(re.findall('ab{1,}','a ab abb abbb abbbb bbbbbb')) #{n,m}左边的字符有n-m次
# print(re.findall('ab{3}','a ab abb abbb abbbb bbbbbb'))
# print(re.findall('ab{2,3}','a ab abb abbb abbbb bbbbbb')) # .* .*?
['ab', 'abb', 'abbb', 'abbbb'] ['ab', 'abb', 'abbb', 'abbbb'] ['abbb', 'abbb'] ['abb', 'abbb', 'abbb']
#.*贪婪匹配 找最多的 # print(re.findall('a.*c','a123c456c'))
#.*?非贪婪匹配 # print(re.findall('a.*?c','a123c456c')) #| 或者 任意批配
# print(re.findall('company|companies','Too many companies have gone bankrupt, and the next one is my company'))
# company|companies
# print(re.findall('compan|companies','Too many companies have gone bankrupt, and the next one is my company'))
['companies', 'company'] ['compan', 'compan']
#():分组
# print(re.findall('ab+','abababab123'))
# print(re.findall('ab+123','abababab123'))
['ab', 'ab', 'ab', 'ab'] ['ab123']
# print(re.findall('ab','abababab123')) # print(re.findall('(ab)','abababab123')) # print(re.findall('(a)b','abababab123')) # print(re.findall('a(b)','abababab123')) # print(re.findall('(ab)+','abababab123')) # print(re.findall('(?:ab)+','abababab123')) #?: 匹配完整词语
['ab', 'ab', 'ab', 'ab'] ['ab', 'ab', 'ab', 'ab'] ['a', 'a', 'a', 'a'] ['b', 'b', 'b', 'b'] ['ab'] ['abababab']
# print(re.findall('(ab)+123','abababab123')) # print(re.findall('(?:ab)+123','abababab123')) # print(re.findall('(ab)+(123)','abababab123'))
['ab']
['abababab123']
[('ab', '123')]
# print(re.findall('compan(y|ies)','Too many companies have gone bankrupt, and the next one is my company')) # print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))
['ies', 'y'] ['companies', 'company']
#re的其他方法 search 找成功一次就结束 match 从头开始是匹配 # print(re.findall('ab','abababab123')) # print(re.search('ab','abababab123').group()) # print(re.search('ab','12aasssdddssssssss3')) # print(re.search('ab','12aasssdddsssssssab3sssssss').group())
['ab', 'ab', 'ab', 'ab'] ab None ab
# print(re.search('ab','123ab456')) # print(re.match('ab','123ab456'))
# print(re.search('^ab','123ab456'))
# split 切分
# print(re.split('b','abcde')) # print(re.split('[ab]','abcde'))
# sub 替换 # print(re.sub('alex','SB','alex make love alex alex',1)) #1是替换一次,也可不用该参数 # print(re.subn('alex','SB','alex make love alex alex',1)) #显示替换几次 # print(re.sub('(\w+)(\W+)(\w+)(\W+)(\w+)',r'\5\2\3\4\1','alex make love')) #\w 匹配单词 \W 匹配非单词 12345 代表匹配的组 # print(re.sub('(\w+)( .* )(\w+)',r'\3\2\1','alex make love')) # obj=re.compile('\d{2}') #定义一个正则表达式,数字出现两次 # print(obj.search('abc123eeee').group()) #12 # print(obj.findall('abc123eeee')) #12
<_sre.SRE_Match object; span=(3, 5), match='ab'> None
None ['a', 'cde'] ['', '', 'cde'] SB make love alex alex ('SB make love alex alex', 1) love make alex love make alex 12 ['12']
print(re.findall('\-?\d+\.?\d+',"1-12*(60+(-40.35/5)-(-4*3))")) print(re.findall('\-?\d+\.?\d*',"1-12*(60+(-40.35/5)-(-4*3))")) # print(re.findall('\-?\d+\.\d+',"1-12*(60+(-40.35/5)-(-4*3))")) # print(re.findall('\-?\d+',"1-12*(60+(-40.35/5)-(-4*3))")) # print(re.findall('\-?\d+\.\d+|(\-?\d+)',"1-12*(60+(-40.35/5)-(-4*3))")) # print(re.findall('\-?\d+\.\d+|\-?\d+',"1-12*(60+(-40.35/5)-(-4*3))")) # print(re.findall('\-?\d+|\-?\d+\.\d+',"1-12*(60+(-40.35/5)-(-4*3))"))
['-12', '60', '-40.35'] ['1', '-12', '60', '-40.35', '5', '-4', '3'] ['-40.35'] ['1', '-12', '60', '-40', '35', '5', '-4', '3'] ['1', '-12', '60', '', '5', '-4', '3'] ['1', '-12', '60', '-40.35', '5', '-4', '3'] ['1', '-12', '60', '-40', '35', '5', '-4', '3']

