csapp-计算机存储
CSAPP- P6 计算机存储
计算机系统中,CPU进行执行指令,存储器系统用来为CPU存储指令和数据。
存储器系统是一个具有不同容量,成本和访问时间的多层次结构。
- 靠近CPU的高速存储器(cache memory)
- 主存(main memory)
- 磁盘(Disk)
存储技术
1.随机访问存储器(Random-Access Memory)
随机访问存储器分为静态(SRAM)和动态(DRAM)两类,静态RAM更快,但是更贵。在生产中SRAM长用作高速缓存存储器,在CPU芯片上使用,DRAM长用来作为主存或图片系统的缓存设备;
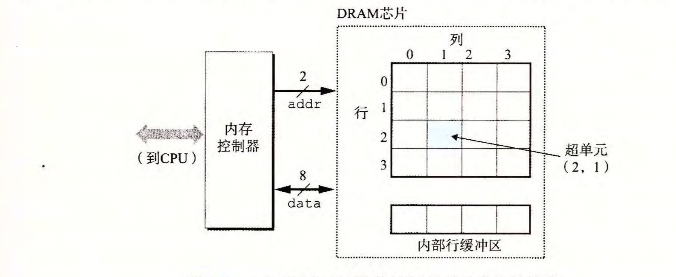
一个传统的DRAM的结构如图所示,内存会传输行地址,列地址到DRAM芯片,芯片会传输该路径的内容返回到控制器。
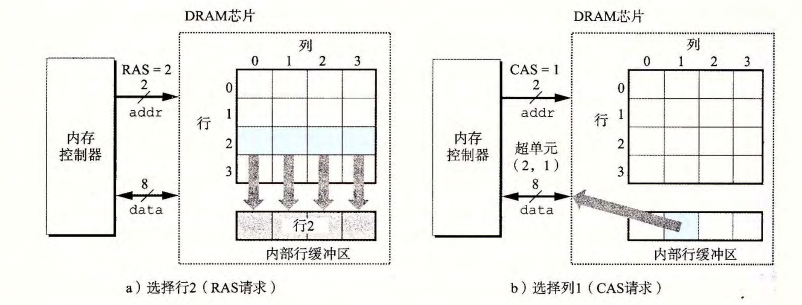
内存控制器通过先发送行地址,DRAM将行数据赋值到内部行缓冲区,再从行缓冲区中复制列信息作为相应。由于行和列信号共享引脚,这样设计有效的降低了引脚的数量。
2. 访问主存
数据流通过总线(Bus)在处理器和DRAM之间进行来回。每次CPU和主存之间的数据都通过总线事务来进行传输。
总线实际上是并行的导线,携带地址,数据,控制信号。
CPU执行 move A, %rax 时发生了什么?
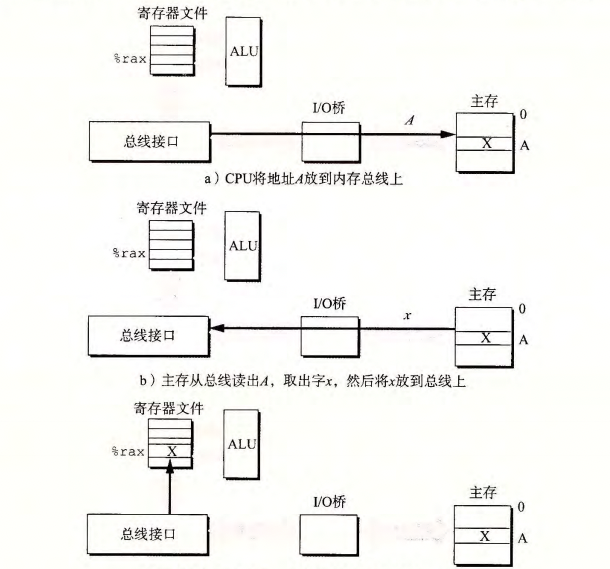
1.CPU的总线接口在电路总线上发起读事务。
1)CPU将地址A放在系统总线上。
2)I/O桥将信号传递到地址总线。
3)主存感知到总线上的地址信号,从内存总线读地址,获取数据,并回写至内存总线;
4)CPU将内存总线会传,并翻译过的数据回写至寄存器。
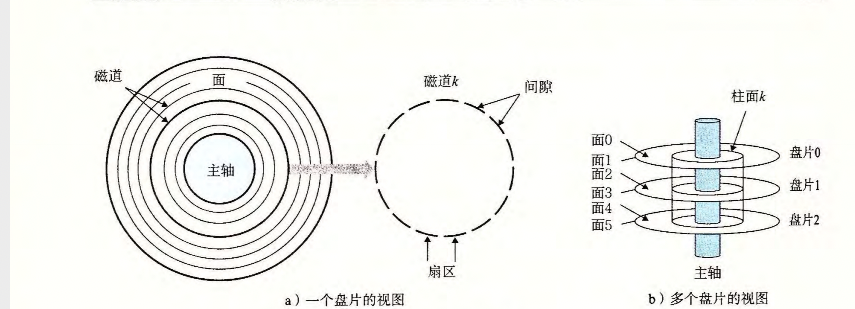
3.磁盘存储
机械磁盘
盘面 + 磁道 + 扇区共同定位block的传统结构,具体细节不在赘述
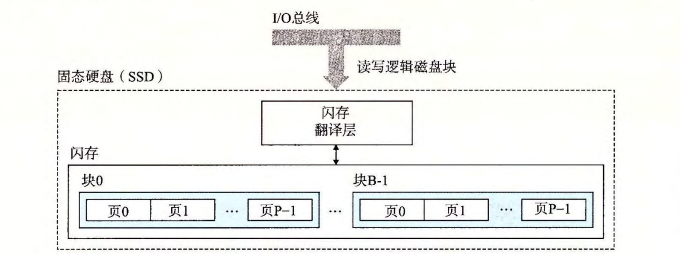
固态硬盘(Solid State Disk)
一种基于闪存的存储技术。一块封装好的SSD由一个or多个闪存芯片和闪存翻译层(flash translation layer)组成。
局部性原则(locality)
程序倾向于引用已经引用过的数据临近的数据,这被称为局部性原理。
存储器层次结构
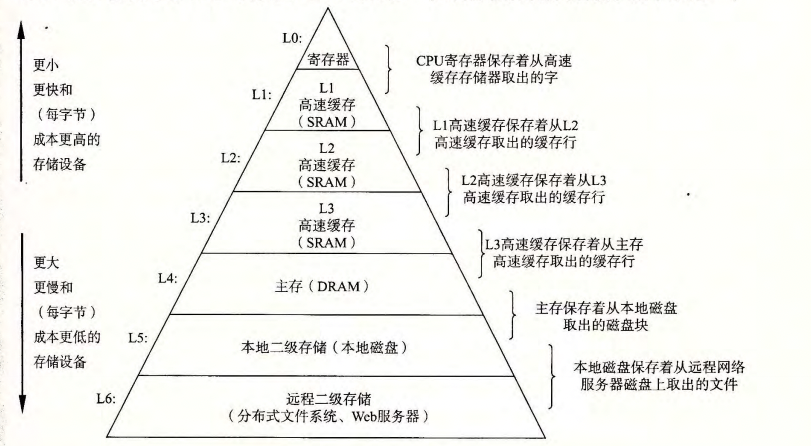
存储器层次结构下的缓存
层次中的每一层都缓存来自下一层的数据对象。如,主存为磁盘上的数据缓存,高速缓存为主存做缓存。
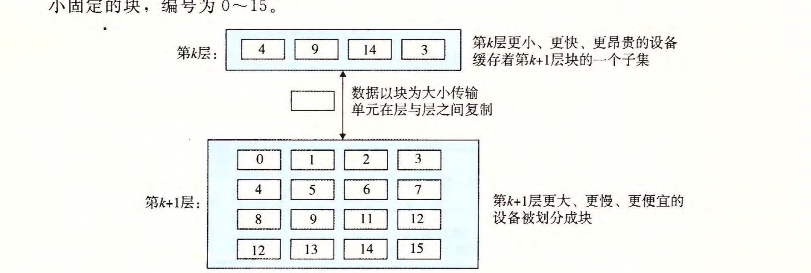
如图展示了存储器层次结构中缓存的一般性概念。第k+1的存储器被划分为练粗的数据对象组块(chunk),称其为(block)。每个block存在标记,区分于其他块,块可以是固定大小的,也可以是可变大小的。
第K层会以block为基本单元缓存K+1层的数据。数据总是以block大小为传送单元(transfer unit)在两层之间复制。
缓存命中
CPU想要取K+1的某个block数据,如果在K层缓存,就直接取出返回即可。
缓存不命中
如果缓存不命中时,会去k+1层将数据返回,并缓存至k层;
如果k层已经全部缓存,则需要驱逐一块,具体驱逐哪一块存在两种策略。常用的是随机替换和 LRU两种策略。
缓存不命中存在不同的情况:
- 如果k层的缓存是空的,则对任何数据对象的访问都会不命中。一个空的缓存有时会被称为冷缓存(cold cache),此类不命中,表示其是存储系统往往是处于初始化or其他非常态的情况,是一个短暂态,不会在反复访问存储器,使得缓存稳定后出现。
- 只要发生了不命中,缓存系统就必须执行放置策略,来确定将K+1层的数据放置在哪里。高层的缓存是使用硬件来实现的,速度是最优的。硬件缓存通常是使用更严格的放置策略,将K+1层的某个块限制放置在第k层块的第一个小的子集中。(实际就是硬件上,k+1层的block,每次会映射到k层的固定几个位置)。但是这样就会引发冲突不命中(conflict miss)问题。
高速缓存存储器
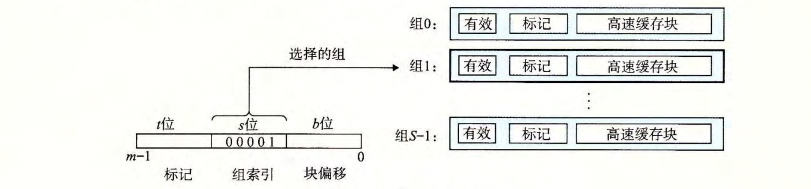
一个计算机系统中,每个存储器地址有m位,形成M = 2 ^ m 个不同的地址。每个机器的高速缓存被组织成一个有S = 2 ^ s 个高速缓存组(cache set)的数组。每个数组包含E个高速缓存行(cache line)。每个行是由一个B = 2 ^ b字节的数据块组成的。一个有效位(valid bit)指明该行是否包含有意义的信息。 t = m - (b + s)个标记位(tag bit) ,作为该块的唯一标志位。
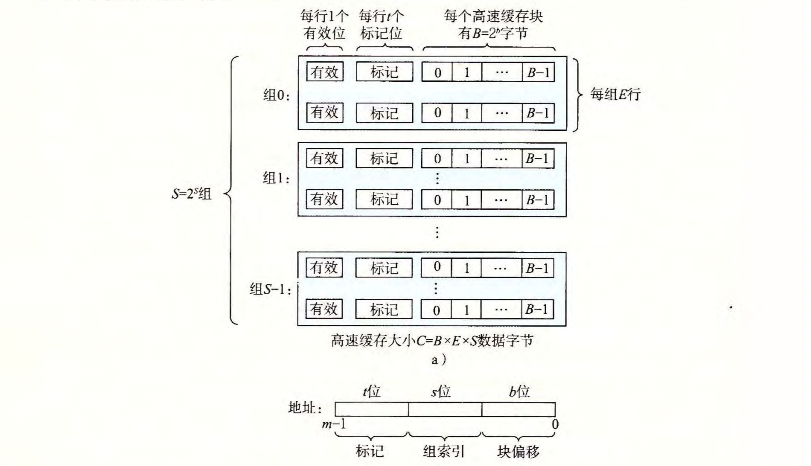
可以用这样的形式组织(S,E,B,m); S 个cache sets, 每个set E 行,每行数据块为B字节,总计m个地址。
当CPU从主存地址A读一个字时,其会将地址发送至高速缓存,如果已经被缓存,则立刻返回。高速缓存可以通过地址位检查,就能快速的校验数据是否被缓存。 简单的工作原理如下:
参数S和B将m个地址位分为三段,地址A中的s位,让我们确定在那个组中,t中告知我们在那个行中存在该字,block位,告知字在整个block中的偏移量,协助我们定位到字。
直接映射高速缓存
当cache set中仅存在一个行时,被称为直接映射高速缓存。通过这个简单的模型,来对工作原理进行解析。
假设存在一个系统,存在一个CPU,一个寄存器文件,一个L1高速缓存和一个主存。当CPU执行一条读内存字w的指令,它向L1高速缓存请求这个字,如果L1高速缓存存有一个w的副本,则命中返回。否则L1则向主存请求w。请求的过程可以分解成三步:1)组选择;2)行匹配 ;3)字抽取。
1.组选择
从地址w中抽取出s位,作为组索引位。可以将cache sets看作一个一维数组,那么我们就能通过索引选择目标组;
2.行匹配
当选择组中的行,有效位为1 且 标记位 和 地址中标记位一致时,命中目标行
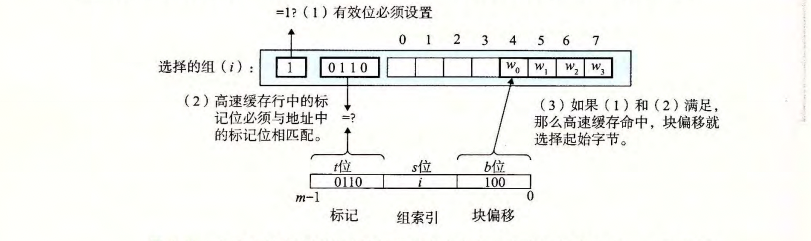
3.字匹配
如上图,偏移量决定了目标字地址,将其内容返回。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?