CMU15-445 数据库导论 Storage02 其他存储方式
CMU15-445 数据库导论 Storage02 其他存储方式
1. 参考资料:
[1] CMU15-445:Database Systems [Andy Pavlo] https://15445.courses.cs.cmu.edu/fall2022
[2] DataBase System Concept[M].Abraham Silberschatz,Henry F. Korth,S. Sudarshan
[3] Simviso精选视频课程.知秋译:https://www.simtoco.com/#/albums?id=1000013
[4] 课件链接: 链接: 链接: https://pan.baidu.com/s/1UW3HjCDv0OduahOyx2FCyA?pwd=ws4u 提取码: ws4u
2.概述
本接主要讲述了除了常规的Page/行Tuple的其他数据存储组织的形式,和数据库的工作负载。
主要有以下几点:
- 面向日志的数据库存储形式(oriented-log);
- 不同类型的数据在磁盘上的组织形式,以及遇到的问题;
- 大数据的存储方案
- 数据库负载的两种形式OLTP 和 OLAP;
- 不同类型的业务特点和对应更合适的存储方法;
- 列存
3.数据表现
3.1 针对浮点数的存储
实际上大部分的数据类型数据库中的数据都是以C/C++的原生形式进行编码存储;
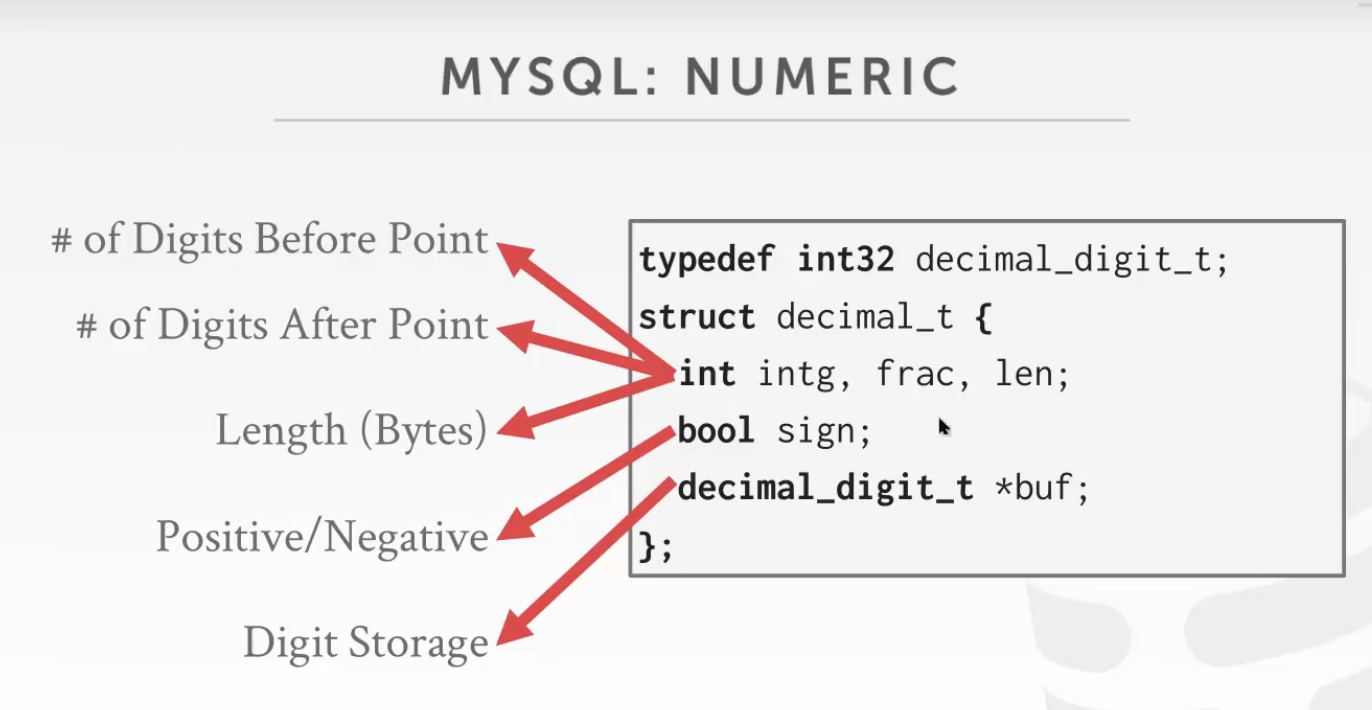
非原生存储的数据类型:浮点数
C/C++的浮点数实际是一种不定长数据,可以根据需求进行格式化存储和显示,当把这类不定长数据存储进数据库时,会造成系统业务数据和数据库数据的不匹配,当对数字要求较高时会出现问题;
数据库设计上,针对此类数据需要进行特殊处理,具体的方案是构造一类结构体,如DECIMAL or REAL(类似Java中的类,BIGDECIMAL),将一个不定长的数字,根据其需求取定长存入数据库。
3.2 针对时间的存储
对于时间,采取的是单位+时间戳的方式共同构造进行存储;
3.3 针对大文件的存储
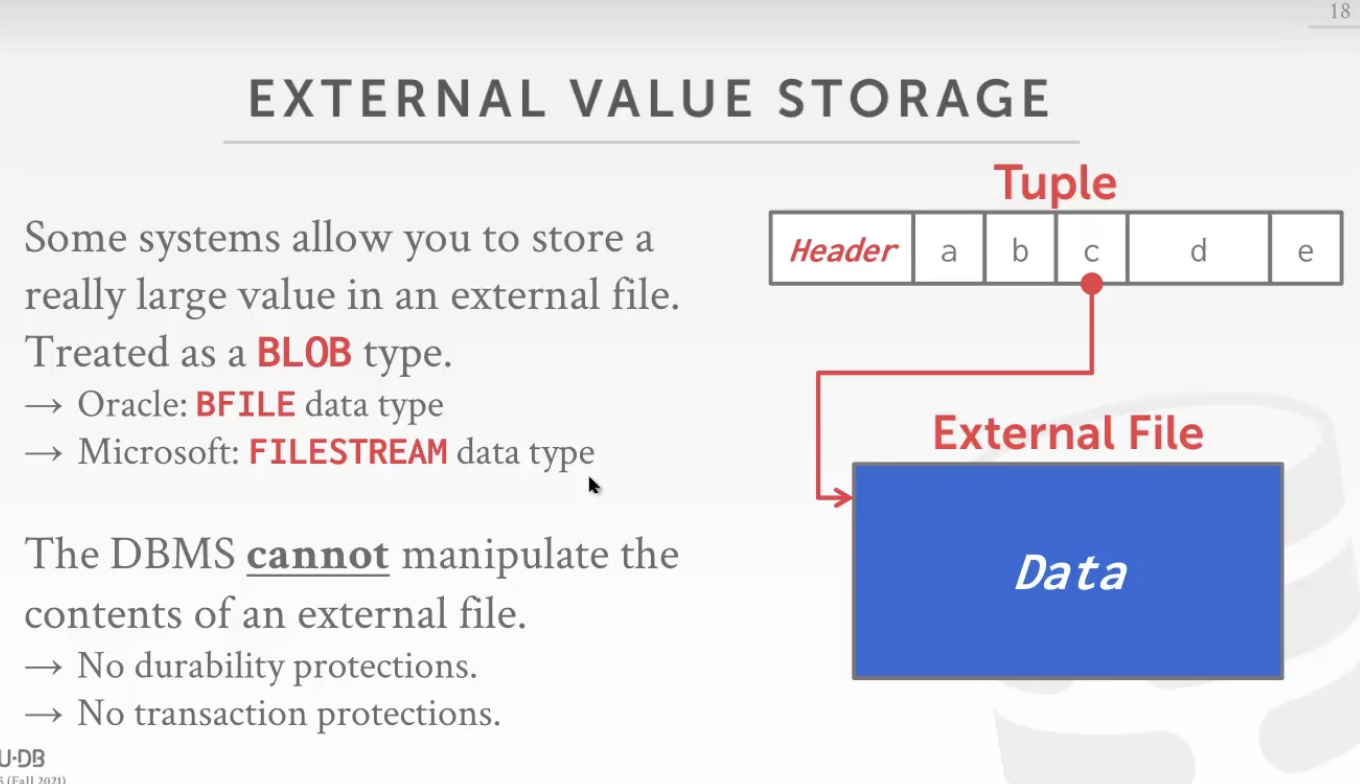
当用户想把一个大的value存入数据时,这个数据可能会把整个Page占满(如一个视频),此时往往会采取overflow的方式来进行存储,即存储一个指向大value的指针,另外开辟一片空间对其进行存储。

同样,对于连续的大文件进行管理的话,同样存在一种组织方式,即不把数据存在数据库内,可以存在可以调用到的网络空间上,仅仅在数据库内进行连接的存储。
3.4 系统目录(System Catalog)
数据库需要专门设计一个区域,用来存储库,表,表子段等meta数据;
在数据库标准中Information_shchema这个库要求存放这些数据
4. 面向日志的数据库(Log-Structured File Organization)
和Page组织的面向disk存储的形式不同,log-oriented日志,每次存储的是对数据库的操作。如果需要读一条数据的value,需要在日志中进行查找,再把相关日志聚合得到最终数据。

这样存储的优势:
将非顺序写入数据库的行为变成顺序写入,可以告诉写入;
劣势:(设计者需要注意的地方)
- 需要大量空间来存储日志;
- 需要定期进行压缩处理数据
- 数据在读时,效率较低;
5.数据库工作负载(WorkLoad)
数据库的工作负载即数据库的主要工作业务,可以分为两类:
1.在线事务进程 OLTP(On-Line Transaction Processing);
2.在线分析进程 OLAP(On-Line Anatical Processing)
5.1 OLTP
OLTP往往是那种短平快的简单查询语句,有较少的查询语句构成一个事务,这个事务仅仅需要修改较少的tuple。但是往往是高并发的,经常是多进行快速读写。线上交易就是一个典型的OLTP;
该类事务的特点,实际是更适合by行去查询的,因为涉及较少的tuple,但是往往需要全部的相关信息;
5.2 OLAP
分析性事务,需要数据库大量对数据进行查询,然后对查询到的数据进行聚合分析,然后结果展示。本类的事务往往需要读大量的数据的某个字段,然后对其趋势和数据特点进行分析。这对数据库的要求就是大量数据查询能力;
5.3 Hybrid Transaction
混合型事务,即将上述两种结合的数据库负载类型,但是目前似乎没有一个典范型解决方案。笔者之前的工作经历中,对于OLTP的业务实际是云数据库集群进行支持,当T天的数据结果产出后,T+1日的凌晨往往会把当天的数据进行同步至离线表,进行OLAP的业务支持,在OLAP中将分区进行索引,来存储每天的数据。
6. Storage Models
如上文所述,数据库的两种业务实际有着适合各自的存储方案;
6.1 N-Ary Storage Model(NSM)
行存(row storage),在行存的模式下,Page中将连续存储一个Tuple的所有属性(attribute)。这实际上就是针对OLTP衍生的一种解决方案,正好对应量其特点,需要完整快速的处理较少的事务。
优势:
1.快速的增删改;
2.更好的完全查询小规模tuple;
劣势:
当需要大规模的扫描表时,获取某个属性的聚合分析值时,需要先把其他无用属性也一并拿出来,影响性能;

6.2 Decompositiom Storage Model(DSM)
分解式存储,将一个tuple的不同属性进行分解,然后将属性进行合并存储。仅需要保持一个tuple在这些相关联的Page中处于一个偏移量即可。
这样如果需要针对某属性进行大规模扫描时,我们能很快获取需要的数据。
优势:
1.减少大批量查询时的浪费,可以直接获取需要的目标属性;
2.由于相同的数据都连续存储,更易于压缩
劣势:
查询单tuple时效率低;




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?