个人学习-STL:Set前置-tree
参考资料:
[1]程杰.大话数据结构[M].
[2][美]Robert Sedgewic,Jevin Wayne. 算法Algorithms[M].谢路云译
1.基本脉络:
树实际是链表的衍生结构,从链表到二叉树,到二叉搜索树,到平衡二叉树(AVL),进行一个总结;
2.树的一些基本概念:
1)树实际是n个节点的有限集。n = 0 时称为空树;任何一个非空树,有且仅有一个根节点(root); n > 0 时,其余节点又可分为m个不相交的有限集,每个集合都可看作一个树,即根的子树(subtree)
2)节点所拥有的子树称为子树的度(Degree)。度为0的节点称为叶节点(leaf)或者终端节点;
3)节点衍生出子树的根节点,称为子节点(child),同一根节点下子树节点为兄弟节点(slibing);
3.二叉树:
3.1二叉树的基本构造:
二叉树是最多存在两个子树的树形结构,每个节点单独看都是一个二叉树;
几种特殊的二叉树:
1)斜树:仅有左子树或者右子树的二叉树,实际就是一个线性表;
2)满二叉树:所有节点的度都是2,且所有的叶子节点都在一层上,称为满树
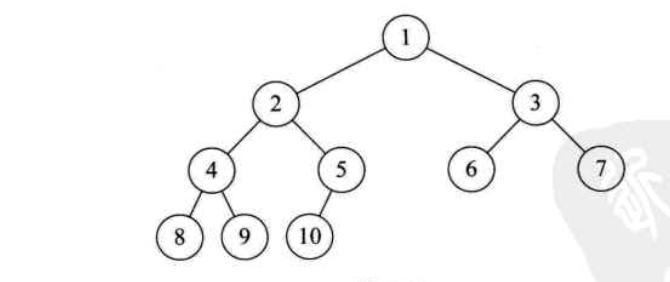
3)完全二叉树:概念定义比较难理解的一种二叉树,简单这样理解[1,2,3,4,5,6,7,8];这样的序列容器,把它以层序优先进行二叉树,它就可以构成一个完全二叉树,类似于广度优先的遍历;(详情见按层遍历二叉树)
3.2 简单二叉树的存储:
typedef struct BinTree
{
int element;
struct BinTree * ltree;
struct BinTree * rtree;
};
3.3二叉树构造和遍历:
前序,中序,后序
实际就是节点,左子叶,右子树之间的顺序;
前序:
若二叉树为空,则空操作返回,否则先访问节点,再先序访问左树,结束后先序访问右树;上图的先序结果为1,2,4,8,9,5,10,3,6,7;(节点在左右子树前被访问)
先遍历节点,再遍历左子树,再遍历右子树
void pre_search_BinTree(struct BinTree * tree)
{
if (tree == NULL)
{
return;
}
preintf("%d", tree ->element);
pre_search_BinTree(tree -> ltree);
pre_search_BinTree(tree -> rtree);
}
中序:
若二叉树为空,则空操作返回,否则先中序遍历左树,再访问元素,再中序遍历右树
void on_search_BinTree(struct BinTree * tree)
{
if (tree == NULL)
{
return;
}
pre_search_BinTree(tree -> ltree);
preintf("%d", tree ->element);
pre_search_BinTree(tree -> rtree);
}
后序:
二叉树为空,则空操作返回,否则先后序遍历左树,再后序遍历右树,再访问元素;
void pos_search_BinTree(struct BinTree * tree)
{
if (tree == NULL)
{
return;
}
pre_search_BinTree(tree -> ltree);
pre_search_BinTree(tree -> rtree);
preintf("%d", tree ->element);
}
深度遍历和广度遍历(层序遍历)
深度遍历-先序:先序遍历的非递归版,实际就是一个简单的深度遍历,以访问最深的路径为目的;(在图的部分会被广泛使用)
// 直接用了STL里的stcak,note:设计上把弹出栈顶元素拆成里top()和pop()两个函数,具体原因需要研究一下
void DFS(struct BinTree* tree)
{
// 节点栈,利用先进后出的特性来处理
if(tree == nullptr)
return;
stack<BinTree*> node_stack;
// 根节点入栈
node_stack.push(tree);
while (!node_stack.empty())
{
// 访问元素;
BinTree* top_elem = node_stack.top();
node_stack.pop(); // 移除;
// 先进后出,想先访问左子树的话,右边先入栈
if(top_elem ->rtree)
{
node_stack.push(top_elem -> rtree);
}
if(top_elem -> ltree)
{
node_stack.push(top_elem -> ltree);
}
// 需要delete一下,可能会内存泄漏-->待验证;
delete top_elem;
}
广度优先遍历(BFS):
按照每一层的顺序对二叉树进行遍历,root->层1 -> 层2 -> 层3 ;如上文,如果把一个容器里的数据,按层序展开,得到的就是一个完全二叉树
/* 队列实现,先进先出;
tree- A
/ \
B C
/ \ / \
D E F G
queue: 1. push(A) A
2. front_pop:A, pushback:BC BC
3. front_pop:B, pushback:DE CDE
4. front_pop:C, pushback:GF DE
5. frint_pop .....
*/
void BFS(struct BinTree * tree)
{
if(tree == nullptr)
{
return;
}
queue<BinTree *> node_queue;
// 根节点入队列;
node_queue.push(tree);
while (!node_queue.empty())
{
BinTree * node = node_queue.front();
node_queue.pop(); // 尾进头出FIFO;
if(node -> ltree)
{
node_queue.push(node ->ltree);
}
if(node -> rtree)
{
node_queue.push(node -> rtree);
}
}
}
3.4基础二叉树的缺点:
1.当节点n的数量比较多的时候,子叶上会有大量空指针;
2.找不到前驱点,需要找到某个节点元素的前驱点,需要再去遍历;
由于这两个缺点,需要把原始二叉树进行改进,引出了线索二叉树;
4.线索二叉树:
鉴于上述的两个原因,在结构设计上,添加进了一个思路:
将节点中的空指针,指向本节点的前驱点和后继点,就可以实现二叉树的线索化,把此时如果只考虑前驱和后继,不考虑节点间的亲缘关系的话,此时数据类型就是一个双向链表。
常用的线索化思路:中序遍历,将空的rtree ptr指向后继点,ltree ptr指向前驱点;(枚举后较为便捷的做法其他case更为复杂);
此时,节点需要两个标识位,来分辨指针表示的是实际的子树,还是前驱后继关系;
typedef char TelemType;
typedef enum{Link, Thread} PointerFlag;
typedef struct BiThrNode
{
TelemType elem;
struct BiThrNode * ltree;
struct BiThrNode * rtree;
PointerFlag lflag;
PointerFlag rflag;
};
// 遍历线索化
// 需要一个量,定义前一个访问的节点;
BiThrNode* pre;
void InThreading(struct BiThrNode * tree)
{
if (tree == NULL)
{
return;
}
InThreading(tree -> ltree);
if(!tree ->ltree)
{
tree -> lflag = Thread;
tree -> ltree = pre;
}
if(!pre -> rtree)
{
pre ->rflag = Thread;
pre ->rtree = tree;
}
pre = tree;
InThreading(tree -> rtree);
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?