浙大AI导论(入门)兴趣向(第六课)
损失函数与梯度下降
在机器学习中,我们需要定义一个 损失函数(Cost function 𝐶, Loss Function 𝐿)
这个函数是用来测量:预测的 𝑦∗ 与实际的 𝑦 之间的差别
模型训练 即 损失函数优化
损失函数是关于什么的函数?
找到一种𝜃, 使得y∗=Fθ(x) 与 𝑦 之间差别最小(即 L(y∗,y)最小)
那你肯定会有这样一种疑问:损失函数是关于谁的函数?
回答:它不是关于(x,y)的函数,而是关于模型参数的函数(也就是通过模型参数(a,b) {这里的(a,b)我是自己设出来的},变化使得让L最小)
所以机器学习其实就是找到这个函数的参数,让他的极值达到最小,就是不断优化这个模型。也相当于求函数的极值(求损失函数最小的问题嘛),可以通过求导来求出它的最值!也可以通过数学推导求出!
但是往往用数学推导是 complex ,so 我们引入了一个全新概念:
梯度下降
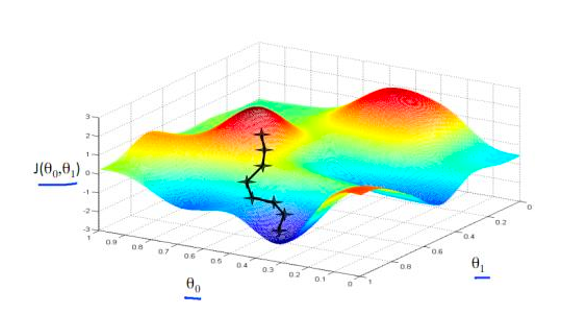
根据上图,问题就变成了如何在这个曲面上找最低点。
其实类比一下到我们日常生活中的 爬山 例子
就是我们从一个点出发,找一个方向最快能下山的那一条走下去,然后继续找哪一个方向是最快能下山的,依次迭代,直到我们走到最后 发现没有哪个方向比我们目前所在的点要更低,那我们就找到了最低点!那么对应的(a,b)就是我们最优参数。所以综上,我们的模型就训练完了!
这个方法就称为梯度下降法!有对应的公式,可以去百度搜一搜!(缺点:没法完全找到最优的策略)
接下来我们即将了解到:
线性回归
本文来自博客园,作者:Alaso_shuang,转载请注明原文链接:https://www.cnblogs.com/Alaso687/p/17031244.html
