Apache Beam编程指南
术语
- Apache Beam:谷歌开源的统一批处理和流处理的编程模型和SDK。
- Beam: Apache Beam开源工程的简写
- Beam SDK: Beam开发工具包
- **Beam Java SDK: Beam Java开发工具包
- Trigger: 触**发器
- Event Time: 事件时间,事件发生的时刻
- Process Time: 处理时间,即数据被系统处理的时刻
- PCollection: Beam中的表示数据集的对象
- Pipeline: Beam中表示数据处理流程的对象,包含参数、数据输入、处理逻辑、输出等,可以类比为一个工作流。
- PTransform: 变换,对PCollection中的每1个元素进行处理,生成一个新的PCollection
- ParDo: Beam中表示并行执行的对象,一般会内嵌一个DoFn。
- DoFn: Beam中ParDo中编写业务逻辑的对象。
- Combine: 组合,表达了比聚合更广泛的概念,聚合一般有Sum、Count、AVG等,组合可以实现自己的逻辑得出一个结果。
- CombineFn: Combine中具体实现逻辑的类。
- GroupBy: 分组,与Sql中的 group by类似。
- BoundedSource: 有限数据源,表示数据源中的数据是有限数据集,一般是批处理的场景。
- UnboundedSource: 无限数据源,表示数据会持续不断的产生,只要不中止程序,就会一直产生下去。
- Watermark: Beam中用来跟踪数据到达进度的标识
- Window: 窗口,用来切分无限数据流为可计算的小批量数据
- Fixed Window: 固定长度时间窗口,例如5分钟
- Sliding Window: 滑动时间窗口,例如每5分钟长度一个窗口,每10秒钟滑动一次产生一个新窗口
- Session Window: 会话窗口。
- Single Global Window: 单一全局窗口,一般用来在批处理中进行全局统计。
- Stateful Processing:有状态计算,对应的是无状态计算,无状态计算因为不需要共享状态,所以一般的大数据计算引擎都支持无状态计算。
- Coder: 编码器,用来序列化反序列化数据为二进制结构。
- Source/Sink: PipelineIO的数据来源和数据输出。
- Runner:执行引擎,Apache Beam中适配不同大数据引擎的模块。
入门
使用Beam,首先使用Beam SDK中编写一个Beam程序。 在Beam程序中定义了Pipeline,包括所有输入,变换和输出; 同时也包含了设置Pipeline的参数(通常使用命令行选项传递)。 包括Pipeline的执行引擎选项,用来确定Pipeline运行在那个执行引擎上(目前支持Beam的执行引擎包括Spark Flink Apex等)。
Beam SDK提供了一些抽象,可以简化大规模分布式数据处理的机制。 Beam用相同的抽象来统一表达批处理和流计算。 当创建Beam Pipeline时,可以根据这些抽象设计数据处理任务。 包括以下:
- Pipeline
Pipeline从头到尾封装整个数据处理任务。包括读取输入数据,变换数据和写入输出数据。所有Beam程序必须创建一个Pipeline。创建Piepline时,还必须指定执行选项,告诉Pipeline在哪里(如哪种执行引擎,Spark Flink等)和如何运行(批处理或流式)。
- PCollection
PCollection表示Beam Pipeline处理的的分布式数据集。数据集可以是有限的,例如来自于文件这样的不再变化的数据源,或是无限的,这意味着它来自于通过订阅或其他机制不断更新的数据源。Pipeline通常通过从外部数据源读取数据来创建初始PCollection,也可以从Beam程序中的内存数据创建PCollection。PCollection是Pipeline中每个步骤的输入和输出。
- Transform
Transform代表Pipeline中的数据处理操作或步骤。每个Transform将一个或多个PCollection对象作为输入,执行对该PCollection的元素提供的处理函数,并生成一个或多个输出PCollection对象。
- I / O Source和Sink
Beam提供Source和Sink API来分别表示读取和写入数据。 Source封装了从一些外部来源(如云端文件存储或订阅流式数据源)将数据读入Beam Pipeline所需的代码。 Sink同样封装将PCollection的元素写入外部数据接收器所需的代码。
典型的Beam程序的如下:
1. 创建Pipeline对象并设置Pipeline执行选项,包括Pipeline的执行引擎。
2. 为Pipeline创建初始数据集PCollection,使用Source API从外部源读取数据,或使用CreateTransform从内存数据构建PCollection。
3. 应用Transform到每个PCollection。Transform可以改变、过滤、分组、分析或以其他方式处理PCollection中的元素。Transform创建一个新的输出PCollection,而不改变输入集合(函数式编程特性)。 典型的Pipeline依次将后续的Transform应用于每个新的输出PCollection,直到处理完成。
4.输出最终的转换PCollection,一般使用Sink API将数据写入外部源。
5. 使用指定的执行引擎运行Pipeline代码。创建Pipeline
Pipeline封装了数据处理任务中的所有数据和步骤。 Beam程序通常从构建一个Pipeline对象开始,然后使用该对象作为创建管道数据集作为PCollections的基础,并将其作为Transforms操作。
要使用Beam,我们编写的程序必须首先创建Beam SDK类Pipeline的实例(通常在main()函数中)。 创建Pipeline时,还需要设置一些配置选项。 可以以编程方式设置管道的配置选项,但提前设置选项(或从命令行读取)通常更容易,并在创建对象时将其传递给Pipeline对象。
// 从创建Pipeline的options开始
PipelineOptions options = PipelineOptionsFactory.create();
// 然后创建Pipeline
Pipeline p = Pipeline.create(options);配置Pipeline的选项Configuring Pipeline Options
管道抽象封装了数据处理任务中的所有数据和步骤。通常从构建一个PipelinePipeline对象开始,然后使用该对象作为创建管道数据集作为PCollections的基础,并将其作为Transforms操作。
要使用Beam,必须首先创建Beam SDK类Pipeline的实例(通常在main()函数中)。 创建流水线时,您还需要设置一些配置选项。 您可以以编程方式设置管道的配置选项,但提前设置选项(或从命令行读取)通常更容易,并在创建对象时将其传递给管道对象。
通过命令行设置Pipeline的参数
虽然可以通过创建PipelineOptions对象并直接设置字段来配置Pipeline,但Beam SDK包含一个命令行解析器,可以使用它来使用命令行参数在PipelineOptions中设置字段。
要从命令行读取选项,首先要创建一个PipelineOptions对象,如以下示例代码所示:
MyOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().create();命令行的格式如下:
--<option>=<value><font color=red>注意: 使用 .withValidation会校验命令行的参数</font>使用命令行的方式可以为Pipeline创建任何的参数。
创建自定义的参数
除了标准的PipelineOptions之外,还可以添加自定义选项。 要添加自定义选项,需要为每个选项定义一个带有getter和setter方法的接口,如以下示例所示:
public interface MyOptions extends PipelineOptions {
String getMyCustomOption();
void setMyCustomOption(String myCustomOption);
} 还可以为每一个参数设定默认值和参数描述,当用户使用–help时显示的描述和默认值。设定方法如下:
public interface MyOptions extends PipelineOptions {
@Description("My custom command line argument.")
@Default.String("DEFAULT")
String getMyCustomOption();
void setMyCustomOption(String myCustomOption);
}
然后使用PipelineOptionsFactory 注册自定义参数的接口,创建PipelineOptions 的时候作为参数传递进去。只有当在PipelineOptionsFactory 中注册了接口之后,使用—help才能显示接口中定义的参数的默认值和描述,PipelineOptionsFactory 才会校验命令行中输入的参数,在所有已注册的自定义参数中是否有匹配的。
下边的代码示例中,展示了如何在PipelineOptionsFactory中注册自定义参数接口和如何使用自定义参数接口:
PipelineOptionsFactory.register(MyOptions.class);
MyOptions options = PipelineOptionsFactory.fromArgs(args) .withValidation() .as(MyOptions.class);现在就可以在Pipeline中使用 –myCustomOption=value 参数了。
使用 PCollections
PCollection抽象表示分布式数据集。 您可以将PCollection视为Pipeline数据; Bean中的Transform使用PCollection对象作为输入和输出。 因此,如果要处理Pipeline中的数据,则必须采用PCollection的形式。
创建Pipeline后,需要先创建一个至少一个PCollection。 创建的PCollection作为Pipeline中第一个操作的输入。
创建PCollection
可以使用Beam的Source API从外部源中读取数据来创建PCollection,也可以在程序中创建存储在内存中集合类中的数据的PCollection。 前者通常是在生产环境中Pipeline读取数据;Beam的源API提供了大量针对不同数据源的适配器从外部数据源读取数据(如大型基于云的文件,数据库或订阅服务)中读取。 后者主要用于测试和调试目的。
从外部数据源读取数据Reading from an external source
要从外部源读取,请使用Beam提供的I / O适配器之一。 适配器的用法有所不同,但它们的基本逻辑是读取自某些外部数据源, 以PCollection返回从源中读取的数据。
每个数据源适配器都有一个Read Transform,要读取,必须将该Transform应用于Pipeline。 例如,TextIO.Readio.TextFileSource从外部文本文件读取并返回其元素为String类型的PCollection,每个String表示文本文件中的一行。
以下是将TextIO.Readio.TextFileSource应用于Pipeline以创建PCollection的方法:
public static void main(String[] args) {
// 创建pipeline.
PipelineOptions options =
PipelineOptionsFactory.fromArgs(args).create();
Pipeline p = Pipeline.create(options);
// 使用Read Transform创建PCollection 名为'lines'
PCollection<String> lines = p.apply(
"ReadMyFile", TextIO.read().from("protocol://path/to/some/inputData.txt"));
}参考 I/O部分了解Beam支持的适配器。
从内存数据创建PCollection
从内存中的Java集合创建PCollection,可以使用Beam提供的Create Transform。 很像数据适配器的Read,可以在Pipeline中使用Create。
Create接受Java Collection和Coder对象作为参数。 Coder指定如何对集合中的元素进行序列化反序列化。
要从内存中的List创建PCollection,可以使用Beam提供的Create Transform。
下边的代码示例中,展示了如何从内存中的List中创建PCollection:
public static void main(String[] args) {
// 创建一个Java Collection ,元素类型为String.
static final List<String> LINES = Arrays.asList(
"To be, or not to be: that is the question: ",
"Whether 'tis nobler in the mind to suffer ",
"The slings and arrows of outrageous fortune, ",
"Or to take arms against a sea of troubles, ");
// 创建pipeline.
PipelineOptions options =
PipelineOptionsFactory.fromArgs(args).create();
Pipeline p = Pipeline.create(options);
// 使用Create Transform,用给定的字符串编码器将上边创建的Java Collectio转换为PCollection
p.apply(Create.of(LINES)).setCoder(StringUtf8Coder.of())
}PCollection 特性
PCollection由创建它的特定Pipeline对象拥有; Pipeline之间不能共享PCollection。 PCollection看起来很像集合类。 但是,PCollection和集合在几个关键方面有所不同:
-
元素类型
PCollection的元素可以是任何类型的,但都必须是相同的类型。 然而,为了支持分布式处理,Beam需要能够将每个单独的元素编码为字节串(因此元素可以传递给分布式工作人员)。 Beam SDK提供了一种数据序列化反序列化,内置了很多常用类型的Coder,也支持根据需要自定义Coder。 -
不变性
PCollection是不可变的。 创建后,无法添加,删除或更改单个元素。 Beam Transform可以处理PCollection的每个元素并生成新的Pipeline数据(作为新的PCollection),但不会改变输入的PCollection。 -
随机访问
PCollection不支持随机访问单个元素。 相反,Beam Transform可以单独考虑PCollection中的每个元素。 -
Size和边界
PCollection是一个大的,不可变的“包”元素。 PCollection可以包含多少元素没有上限;任何给定的PCollection可以是在单机内容能够容纳的数据集,也可能表示来自于数据存储中的非常大的分布式数据集。
PCollection可以是有限的的或无限的。PCollection表示已知固定大小的数据集,而无限PCollection表示无限大小的数据集。 PCollection是有限还是无限取决于它所代表的数据集的来源。从批量数据源(如文件或数据库)读取可创建有界的PCollection。从流或连续更新的数据源(如Pub / Sub或Kafka)读取会创建一个无限的PCollection(除非您明确告诉它不要)。
根据PCollection的有限(或无限),Beam会采用不同的方式处理数据。使用批处理作业来处理有限PCollection,批处理作业可以读取整个数据集一次,并在有限长度的作业中执行处理。使用持续运行的流式作业来处理无限PCollection,流式的数据永远不会在哪一时刻整个数据集是完整的,总会有数据源源不断的进来。
当对无限PCollection中的元素进行分组的操作时,Beam需要一个称为 窗口(Window)的概念,将连续更新的数据集划分为有限大小的逻辑窗口。Beam将每个窗口处理为一个批次(bundle),并且随着数据集的生成,处理继续进行。这些逻辑窗口由与诸如时间戳之类的数据元素相关联的一些特性来确定。 -
元素时间戳
PCollection中的每个元素都具有相关联的时间戳。每个元素的时间戳记最初由创建PCollection的数据源分配。创建无限PCollection的数据源通常会为每个新元素分配一个对应于元素被读取或添加的时间戳。注意:Beam 数据源在创建有限PCollection的时候,会为每个元素自动分配时间戳。最常规的做法是,所有的元素都赋予相同的时间戳。- 1
时间戳对于包含具有固有时间概念的元素的PCollection是有用的。 如果Pipeline正在读取一系列事件,例如推文或其他社交媒体消息,则每个元素可能会将事件发布的时间用作元素时间戳。
如果Beam源没有分配时间戳,也可以手动将时间戳分配给PCollection的元素。 如果元素具有固有的时间戳,但是时间戳在元素本身的结构中(例如服务器日志条目中的“时间”)字段,则您需要执行此操作。 Beam提供了Transform将原始的PCollection作为输入并输出具有附加时间戳的PCollection; 有关如何执行此操作的更多信息,请参阅分配时间戳。
使用Transform
在BeamSDK中,Transform是Pipeline中的操作。Transform将PCollection(或多个PCollection)作为输入,对集合中的每一个元素执行我们编写的操作(代码),并生成新的输出PCollection。必须Transform应用于输入PCollection才能起作用。
Beam SDK包含许多不同的Transform,可以将其应用于Pipeline的PCollection。包括通用的核心转换,如ParDo或Combine。还包括SDK中包含的内置的组合Transform,将一个或多个核心变换组合在有用的处理模式中,例如计数或组合集合中的元素。还可以自定义定义的更复杂的复合转换,以满足Pipeline的业务用例场景。
Beam SDK中的每个Transform都有一个通用的apply 方法(在python中是管道符|)。调用多个Beam变换类似于方法链。一般形式如下:
[输出PCollection] = [输入PCollection].apply([Transform])由于Beam使用PCollection的通用应用方法,因此您可以依次链接变换,也可以应用包含嵌套在其中的其他变换的转换(在Beam SDK中称为复合Transform)。
Pipeline中的处理顺序取决于Pipeline的结构,Pipeline可以理解为一张有向无环图,图中的节点是PCollection,边是Transform。如下图所示,可以在Pipeline中进行链式调用:
[最终输出PCollection] = [原始输入PCollection]
.apply([First Transform])
.apply([Second Transform])
.apply([Third Transform])Beam SDK中的Transform
Beam SDK提供了一些通用的Transform框架,可以以函数对象(俗称“用户代码”)的形式编写编写处理逻辑,处理输入的PCollection的元素。 用户代码在实际执行的时候,可能在集群中的很多不同的worker上并行执行,具体取决于选择执行Beam Pipeline的执行引擎。 在每个worker上运行用户代码,每个worker输出PCollection的一部分,最终汇总成1个完整的输出PCollection。
Beam核心Transform
Beam提供了以下Transform,对应于不同的处理范式:
• ParDo
• GroupByKey
• Combine
• Flatten 和Partition
ParDo
ParDo是用于并行处理的通用Beam Transform。 ParDo处理范例与Map / Shuffle / Reduce样式算法的“Map”阶段相似:ParDo转换考虑了输入PCollection中的每个元素,对该元素执行一些处理函数(用户代码),并输出0个,1个或多个元素到输出PCollection。
ParDo可用于各种常见的数据处理操作,包括:
-
过滤
使用ParDo来判断PCollection中的每个元素,是否该元素输出到新集合,或者将其丢弃。 -
格式化或类型转换
如果输入PCollection包含元素的类型或者格式不是所期待的,,则可以使用ParDoto对每个元素执行转换,并将结果输出到新的PCollection。. -
提取数据集中数据
例如,如果有一个具有多个字段的记录的PCollection,则可以使用ParDo将您想要考虑的字段解析为新的PCollection。 -
对数据集中的每个元素进行处理
使用ParDo对PCollection的每个元素或某些元素执行简单或复杂的计算,并将结果输出为新的PCollection。
在这样的场景里中,ParDo是一个通用的中间步骤。 可以使用它从一组原始输入记录中提取某些字段,或将原始输入转换为不同的格式; 还可以使用ParDo将处理后的数据转换为适合输出的格式,例如如数据库表行或可打印字符串。
当进行ParDo转换时,需要以DoFn对象的形式提供用户代码。 DoFn是一个定义分布式处理功能的Beam SDK类。
使用ParDo
在PCollection 上调用apply 方法,用ParDo 作为参数,如下代码所示:
// 元素类型为字符串类型的输入PCollection
PCollection<String> words = ...;
// DoFn子类,用来具体计算每1个元素的长度
static class ComputeWordLengthFn extends DoFn<String, Integer> { ... }
// 使用ParDo计算PCollection "words" 中每一个单词的长度
PCollection<Integer> wordLengths = words.apply(
ParDo
.of(new ComputeWordLengthFn())); 在该示例中,我们的输入PCollection包含String类型的值。 我们使用一个ParDo Transform,ParDo中使用函数(ComputeWordLengthFn)来计算每个字符串的长度,并将结果字符串的长度作为值,输出到一个新的元素类型为Integer的PCollection中。
使用DoFn
传递给ParDo的DoFn对象中包含对输入集合中的元素的进行处理的。 当使用Beam时,通常最重要的代码是这些DoFn函数,函数里实现了业务逻辑。
DoFn从输入的PCollection一次处理一个元素。 当创建DoFn的子类时,需要提供与输入和输出元素的类型相匹配的类型参数。 如果DoFn处理传入的String元素并生成输出集合的整数元素(像之前的例子ComputeWordLengthFn),类声明将如下所示:
static class ComputeWordLengthFn extends DoFn<String, Integer> { ... }
- 1
- 2
在DoFn子类中,使用@ProcessElement注解方法,在被注解的方法中实现处理逻辑。 不需要从输入集合手动提取元素, Beam SDK已经封装好。 @ProcessElement方法应该接受类型为ProcessContext的对象。 ProcessContext对象提供了获取输入元素和发出输出元素的方法:
static class ComputeWordLengthFn extends DoFn<String, Integer> {
@ProcessElement
public void processElement(ProcessContext c) {
// Get the input element from ProcessContext.
String word = c.element();
// Use ProcessContext.output to emit the output element.
c.output(word.length());
}
}注意: 如果 PCollection 的元素是key/value键值对,可以通过ProcessContext.element().getKey()获取键(key), ProcessContext.element().getValue()获取值(value)
- 1
给定的DoFn实例通常被调用一次或多次来处理一些任意的元素组。 然而,Beam并不保证确切的调用次数; 可以在worker节点上多次调用它,以解决故障和重试。 因此,可以将多个调用中的信息缓存到处理方法中,但是如果这样做,请确保实现不依赖于调用数量。
处理方法中需要满足一些不可变性要求,以确保Beam和执行引擎可以安全地序列化并缓存Pipeline中的值。 方法应符合以下要求:
-
不应以任何方式修改ProcessContext.element()或ProcessContext.sideInput()返回的元素(输入集合中的传入元素)。
-
使用ProcessContext.output()或ProcessContext.sideOutput()输出一个值后,不应该以任何方式修改该值。
轻量级DoFn和其他抽象
如果功能相对简单,可以通过提供一个轻量级的DoFn作为匿名内部类实例来简化对ParDo的使用。这是以前的例子,ParDo与ComputeLengthWordsFn,DoFn指定为匿名内部类实例:
// 输入PCollection.
PCollection<String> words = ...;
// 创建一个匿名类处理PCollection “words”.
// 输出单词的长度到新的输出PCollection
PCollection<Integer> wordLengths = words.apply(
"ComputeWordLengths",// Transform 的自定义名称
ParDo.of(new DoFn<String, Integer>() {// DoFn作为匿名内部类
@ProcessElement
public void processElement(ProcessContext c) {
c.output(c.element().length());
}
}));如果ParDo将输入元素与输出元素进行一对一映射,即对于每个输入元素,对应一个输出,可以使用更高级的MapElements Transform。 MapElements可以使用匿名的Java 8 lambda函数来进一步简化代码。
以下是使用MapElements的上一个示例:
// 输入PCollection.
PCollection<String> words = ...;
// 在MapElements中使用匿名lambda函数处理 PCollection “words”.
//输出单词的长度到新的输出PCollection.
PCollection<Integer> wordLengths = words.apply(
MapElements.into(TypeDescriptors.integers())
.via((String word) -> word.length()));注意: java8 lambda函数写法,只能在Filter,FlatMapElements和Partition使用。使用GroupByKey
GroupByKey 是一个用于处理键/值对集合的Bean Transform,是一个并行Reduce操作,类似于Map / Shuffle / Reduce-style算法的Shuffle阶段。 GroupByKey 的输入是表示多重映射的键/值对的集合,其中集合包含具有相同键但具有不同值的多个对。给定这样的集合,可以使用GroupByKey 来收集与每个唯一键相关联的所有值。
GroupByKey 是汇总具有共同点的数据的好方法。例如,有一个存储客户订单记录的集合,需要将来自同一邮政编码的所有订单组合在一起(其中键/值对的键(key)是邮政编码字段,而值(value)是记录的剩余部分)。
来看一下GroupByKey 的一个简单的例子,其中我们的数据集由文本文件中的单词和出现的行号组成。我们想将所有共享相同单词(键)的行号(值)组合在一起,让我们看到文本中出现特定单词的所有位置。
输入是一个键/值对的PCollection ,其中每个单词都是一个键,该值是该文本出现的文件中的行号。以下是输入集合中的键/值对列表:
cat, 1
dog, 5
and, 1
jump, 3
tree, 2
cat, 5
dog, 2
and, 2
cat, 9
and, 6
...GroupByKey 使用相同的键收集所有值,并输出一个新的键值对,最后输出一个包含唯一键和与输入集合中的该关键字所关联的所有值的集合。 如果我们将GroupByKey 应用于上面的输入集合,则输出集合将如下所示:
cat, [1,5,9]
dog, [5,2]
and, [1,2,6]
jump, [3]
tree, [2]
..因此,GroupByKey表示从多重映射(多个键到各个值)到单一映射(唯一键到值集合)的转换。
使用CoGroupByKey进行Join
CoGroupByKey关联两个或多个具有相同键类型的键/值PCollection,然后输出KV<K, CoGbkResult>集合。 Design Your Pipeline展示了如何在Pipeline中使用Join。
如下两个PCollection:
// collection 1
user1, address1
user2, address2
user3, address3
// collection 2
user1, order1
user1, order2
user2, order3
guest, order4
...CoGroupByKey从所有PCollection中收集具有相同键的值,并输出一个由唯一键和包含与该键相关联的所有值的对象CoGbkResult组成的对。 如果将CoGroupByKey应用于上述输入集合,则输出集合将如下所示:
user1, [[address1], [order1, order2]]
user2, [[address2], [order3]]
user3, [[address3], []]
guest, [[], [order4]]
...键/值对的注意事项:根据使用的语言和SDK不同,Beam表示键/值的方式对略有不同。 在Beam SDK for Java中,使用KV<K, V>类型的对象来表示一个键/值对。 在Python中,使用2-tuple表示键/值对。
使用Combine
Combine是一种用于组合数据中元素或值集合的Beam Transform。Combine有一种实现是对键值对PCollection进行处理,根据键值对中的键组合值。
应用Combine Transform时,必须提供一个函数用于组合元素或者键值对中的值。组合函数应该满足交换律和结合律,因为函数不一定在给定键的所有值上精确调用一次。由于输入数据(包括价值收集)可以分布在多个worker之间,所以在每个worker上都会计算出部分结果,所以可以多次调用Combine函数,以在值集合的子集上执行部分组合。Beam SDK还提供了一些预先构建的组合功能,用来对数值型的PCollection进行组合,如sum,min和max。
简单的组合操作(如sum)通常可以实现为一个简单的功能。更复杂的组合操作可能需要创建一个具有与输入/输出类型不同的累加类型的CombineFn 的子类。
使用简单的函数实现简单的组合
// Sum a collection of Integer values. The function SumInts implements the interface SerializableFunction.
public static class SumInts implements SerializableFunction<Iterable<Integer>, Integer> {
@Override
public Integer apply(Iterable<Integer> input) {
int sum = 0;
for (int item : input) {
sum += item;
}
return sum;
}
}使用CombineFn 实现高级组合
通过继承CombineFn 类可以实现复杂的组合功能。如需要一个复杂的累加器,必须进行预处理或者后处理,输出的类型和输入的类型不一样,组合的时候需要考虑键值对的键(key)等,则需要使用CombineFn来实现。
组合由4种操作组成。当实现一个CombineFn 的子类的时候必须重写这4个操作:
- 创建累加器
创建一个本地变量 accumulator。以计算均值为例,accumulator变量需要记录当前的总和和元素个数,在分布式环境下,具体会执行多少次,在哪台机器上执行都是不确定的。 - 添加输入
把一个新的输入元素追加到accumulator,返回accumulator的值。在本例中,会更新总和,然后元素个数+1。这个操作也可能是并行执行的。 - 合并累加器Merge Accumulators
因为是分布式的,所以每个机器上计算了部分结果,在最终输出结果之前,需要将所有的局部累加器合并起来。 - 输出结果Extract Output
最终计算出全局的均值,该操作只会在合并累加器的基础上执行1次。
代码示例如下:
public class AverageFn extends CombineFn<Integer, AverageFn.Accum, Double> {
public static class Accum {
int sum = 0;
int count = 0;
}
@Override
public Accum createAccumulator() { return new Accum(); }
@Override
public Accum addInput(Accum accum, Integer input) {
accum.sum += input;
accum.count++;
return accum;
}
@Override
public Accum mergeAccumulators(Iterable<Accum> accums) {
Accum merged = createAccumulator();
for (Accum accum : accums) {
merged.sum += accum.sum;
merged.count += accum.count;
}
return merged;
}
@Override
public Double extractOutput(Accum accum) {
return ((double) accum.sum) / accum.count;
}
}通常情况下,对元素为键值对的PCollection 进行组合运算,CombineFn就够了。有一些特殊情况下,需要根据不同的key做不同的处理,例如对某些用户计算最小值,对另外的用户计算最大值。使用KeyedCombineFn 可以在代码中获取到key。
对PCollection进行组合运算输出单个值
对于输入的PCollection,使用全局的组合运算,最终输出只有1个值的PCollection。如下例所示,使用Beam SDK中内置的Sum组合运算,处理输入的PCollection,最终得到一个元素类型为Integer的PCollection:
// Sum.SumIntegerFn() combines the elements in the input PCollection.
// The resulting PCollection, called sum, contains one value: the sum of all the elements in the input PCollection.
PCollection<Integer> pc = ...;
PCollection<Integer> sum = pc.apply(
Combine.globally(new Sum.SumIntegerFn()));- 全局窗口
如果输入PCollection使用默认的全局窗口,则默认行为是返回包含一个元素的PCollection。 元素的值来自于在组合运算中指定的组合函数中的累加器。 例如,提供的sum组合函数返回零值(空输入的和),而min组合函数返回一个最大或无穷大的值。
如果输入为空,要使用Combine代替返回空的PCollection,则在调用CombineFn时指定.withoutDefaults,如下面的代码示例所示:
PCollection<Integer> pc = ...;
PCollection<Integer> sum = pc.apply(
Combine.globally(new Sum.SumIntegerFn()).withoutDefaults());-
非全局窗口
如果输入PCollection使用任何非全局窗口函数,则Beam不提供默认行为。 进行组合运算时,必须指定以下选项之一:1、指定.withoutDefaults,其中输入PCollection中为空的窗口在输出集合中同样为空。
2、指定.asSingletonView,其中输出立即转换为PCollectionView,当用作边输入时,它将为每个空窗口提供默认值。 一般来说,如果Pipeline组合运算的结果在后面的Pipeliine中被用作旁路输入(side inputs),那么通常只需要使用此选项。
对以key分组的集合进行组合计算
在创建以key分组的集合(例如,通过使用GroupByKey Transform)之后,常规模式是将与每个key相关联的值的集合合并成单个值。 根据GroupByKey的前一个例子,一个名为groupingWords的按键组合的PCollection如下所示:
cat, [1,5,9]
dog, [5,2]
and, [1,2,6]
jump, [3]
tree, [2]
...在上述PCollection中,每个元素都有一个字符串类型的键(例如“cat”)和一个可迭代的整数集合(在第一个元素中,包含[1,5,9])。 如果Pipeline的下一个处理步骤组合这些值(而不是单独考虑它们),则可以组合整数集合,以创建要与每个键配对的单个合并值。 GroupByKey然后接着对值进行合并,这种处理模式相当于Beam的Combine PerKey转换。 Combine PerKey提供的Combine函数必须是满足结合律的Reduce函数或CombineFn的子类。
// 对PCollection按照key进行分组,对每个分组中的Double类型的值进行求和 ,值类型与之前一样
PCollection<KV<String, Double>> salesRecords = ...;
PCollection<KV<String, Double>> totalSalesPerPerson =
salesRecords.apply(Combine.<String, Double, Double>perKey(
new Sum.SumDoubleFn()));
// 聚合之后的值与PCollection原始值的类型不同
// PCollection的元素为KV类型的,Key是String,Value是Integer,聚合之后的值是Double
PCollection<KV<String, Integer>> playerAccuracy = ...;
PCollection<KV<String, Double>> avgAccuracyPerPlayer =
playerAccuracy.apply(Combine.<String, Integer, Double>perKey(
new MeanInts())));使用Flatten和Partition
Flatten和Partition是存储相同数据类型的PCollection对象的的Beam Transform。 Flatten将多个PCollection对象合并到1个PCollection中,并且Partition将单个PCollection拆分为固定数量的较小集合。
Flatten
如下代码示例,展示了如何将Flatten应用在PCollection上。
// Flatten接受一个PCollectionList,PCollectionList是一组具有相同元素类型的PCollection
//将PCollectionList中所有子PCollection的元素放到一个新的PCollection中,并返回这个新的PCollection
PCollection<String> pc1 = ...;
PCollection<String> pc2 = ...;
PCollection<String> pc3 = ...;
PCollectionList<String> collections = PCollectionList.of(pc1).and(pc2).and(pc3);
PCollection<String> merged = collections.apply(Flatten.<String>pCollections());合并之后的PCollection中数据编码
默认情况下,输出PCollection的Coder与输入PCollectionList中第一个PCollection的Coder相同。 但是,输入的PCollection对象可以分别使用不同的Coder,只要Java包含相同的数据类型即可。
合并窗口集合
当使用Flatten合并应用了窗口策略的PCollection对象时,要合并的所有PCollection对象必须使用兼容的窗口策略和窗口大小。 例如,合并的所有集合必须全部使用(假设)相同的5分钟长度固定窗口或4分钟长度的滑动窗口每30秒滑动一次。
如果Pipiline尝试使用Flatten将PCollection对象与不兼容的窗口合并,则当构建Pipeline时,Beam会生成IllegalStateException错误。
Partition
Partition用来切分PCollection。 Partition功能包含确定如何将输入PCollection的元素分解为每个生成的分区PCollection的逻辑。 分区数必须在Pipeline构建时确定。 例如,可以在运行时将分区数作为命令行选项传递(然后用于构建Pipeline图),但不能在运行时流水线中的再确定分区数(基于以后计算的数据) 例如,您的流水线图是构建的)。
// Provide an int value with the desired number of result partitions, and a PartitionFn that represents the partitioning function.
// In this example, we define the PartitionFn in-line.
// Returns a PCollectionList containing each of the resulting partitions as individual PCollection objects.
PCollection<Student> students = ...;
// Split students up into 10 partitions, by percentile:
PCollectionList<Student> studentsByPercentile =
students.apply(Partition.of(10, new PartitionFn<Student>() {
public int partitionFor(Student student, int numPartitions) {
return student.getPercentile() // 0..99
* numPartitions / 100;
}}));
// You can extract each partition from the PCollectionList using the get method, as follows:
PCollection<Student> fortiethPercentile = studentsByPercentile.get(4);编写Beam Transform的通用要求
当编写一个Beam Transform代码时,需要理解最终的代码是要分布式执行的。 例如,编写的代码,会生成很多副本,在不同的机器上并行执行,相互独立,而无需与任何其他机器上的副本通信或共享状态。 根据Pipeline的执行引擎,可以选择Pipeline,代码的每个副本可能会重试或运行多次。 因此应该谨慎地在代码中包括状态依赖关系。
简单来说,编写的代码至少要满足以下两个要求:
• 函数必须是可序列化的。
• 函数必须是线程兼容的,Beam SDK并不是线程安全的。除了一样的要求,强烈建议函数是满足幂等特性。
注意:以上的要求适用于DoFn(ParDo 内使用),ConbineFn( Combine 内使用)和WindowFn(Window 内使用)序列化Serializability
提供给Transform的任何函数必须是完全可序列化的。 这是因为函数的副本需要序列化并传输到处理集群中的远程worker。 用户代码的父类,如DoFn,CombineFn和WindowFn,已经实现了Serializable; 但是,在子类不能添加任何不可序列化的成员。
需要时刻记住的序列化要点如下:
• 函数对象中的瞬态字段不会传输到工作实例,因为它们不会自动序列化。
• 在序列化之前避免加载大量数据的字段。
• 函数对象实例之间不能共享数据。
• 函数对象在应用后会变得无效。
• 通过使用匿名内部类实例来内联声明函数对象时要小心。 在非静态上下文中,内部类实例将隐含地包含一个指向封闭类和该类的状态的指针。 该内部类也将被序列化,因此适用于函数对象本身的相同注意事项也适用于此外部类。线程兼容Thread-compatibility
编写的函数应该兼容线程的特性。在执行时,每一个worker会启动一个线程执行代码,如果想实现多线程,需要在代码中自己实现。但是Beam SDK不是线程安全的,所以实现多线程需要开发者自己控制同步。注意,静态变量并不会序列化传递到不同的worker上,还可能会被多个线程使用。
幂等Idempotence
强烈建议开发者编写的函数符合幂等性—即无论重复执行多少次都不会带来意外的副作用。Beam模型中,并不能保证函数的执行次数,鉴于此,符合幂等性,可以让Pipeline的是确定的,Transform的行为是可预测的,更容易测试。
旁路输入Side Inputs
PCollection主输入PCollection,还可以以旁路输入(side inputs)的形式为ParDo Transform提供额外的输入。 旁路输入是DoFn每次处理输入PCollection中的元素时可以访问的附加输入。 当指定边输入时,可以创建一个可以在ParDo Transform的DoFn中读取的其他数据的视图,同时处理每个元素。
如果ParDo在处理输入PCollection中的每个元素时需要注入附加数据,旁路输入会非常有用,但需要在运行时确定附加数据(而不是硬编码)。 这些值可能由输入数据确定,或者取决于Pipeline的不同分支。
传递旁路输入到ParDo
// 调用.withSideInputs将为ParDo添加旁路输入 side input
//在DoFn内,通过DoFn.Processecontext.sideInput可以使用旁路输入 side input
// ParDo的输入PCollection.
PCollection<String> words = ...;
//包含了单词长度的PCollection,将PCollection中的值聚合为1个值
PCollection<Integer> wordLengths = ...; // Singleton PCollection
// 使用Combine.globally and View.asSingleton来计算单词的总长度,生成一个一个单例的PCollectionView
final PCollectionView<Integer> maxWordLengthCutOffView =
wordLengths.apply(Combine.globally(new Max.MaxIntFn()).asSingletonView());
// 在ParDo中使用maxWordLengthCutOffView作为side input.
PCollection<String> wordsBelowCutOff =
words.apply(ParDo
.of(new DoFn<String, String>() {
public void processElement(ProcessContext c) {
String word = c.element();
// 在DoFn内使用side input.
int lengthCutOff = c.sideInput(maxWordLengthCutOffView);
if (word.length() <= lengthCutOff) {
c.output(word);
}
}
}).withSideInputs(maxWordLengthCutOffView)
);旁路输入与窗口
窗口化的PCollection可能是无限的,因此不能被压缩成单个值(或单个集合类)。当创建一个基于窗口化PCollection的PCollectionView时,PCollectionView表示每个窗口的一个实例(可以是每窗口一个值,也可以是每个窗口一个列表等)。
Beam使用主输入元素的窗口来查找旁路输入元素的适当窗口。Beam将主输入元素的窗口投影到侧面输入的窗口集合中,然后使用来自窗口的旁路输入。如果主输入和侧输入具有相同的窗口,投影将提供准确的相应窗口。然而,如果输入具有不同的窗口,则Beam使用投影来选择最合适的旁路输入窗口。
例如,如果使用1分钟的固定时间窗口对主输入进行了窗口化,并且使用1个小时的固定时间窗口对边输入进行了窗口化,则Beam将主输入窗口映射到为旁路输入窗口,并从旁路输入中的合适窗口选择值。
如果主输入元素存在于多个窗口中,那么processElement被调用多次,每个窗口一次。对processElement的每个调用都会为主输入元素投射“当前”窗口,因此可能会每次提供不同的旁路输入视图。
如果侧面输入有多个触发器,则Beam将使用最近触发器触发的值。使用用带有触发器的单个全局窗口的旁路输入时,此功能特别有用。
多路输出Additional Outputs
虽然ParDo总是生成主输出PCollection(作为从apply方法返回值),但是也可以让ParDo生成任意数量的附加输出PCollection。 如果使用具有多个输出,ParDo将返回捆绑在一起的所有输出PCollection(包括主输出)。
使用Tags多路输出的代码示例:
// 为了将数据元素发送给多个下游PCollection,需要创建TupleTag来标示每个PCollection
//例如如果想在ParDo中创建三个输出PCollection(1个主输出,两个旁路输出),必须要创建3个TupleTag
// 下边的代码示例中展示了如何创建为3个输出PCollection创建TupleTag
// 输入PCollection
PCollection<String> words = ...;
// 输入PCollection中低于cutoff的单词发送给主输出PCollection<String>
// 如果单词的长度大于cutoff,单词的长度发送给1个旁路输出PCollection<Integer>
// 如果单词一"MARKER"开头, 将单词发送给旁路输出PCollection<String> // ou
final int wordLengthCutOff = 10;
//为每个输出PCollection创建1个TupleTag
// 单子低于cutoff长度的输出PCollection
final TupleTag<String> wordsBelowCutOffTag =
new TupleTag<String>(){};
// 包含单词长度的输出PCollection
final TupleTag<Integer> wordLengthsAboveCutOffTag =
new TupleTag<Integer>(){};
// 以"MARKER"开头的单词的输出PCollection
final TupleTag<String> markedWordsTag =
new TupleTag<String>(){};
// 将输出TupleTag传给ParDo
//调用.withOutputTags为每个输出指定TupleTag
// 先为主输出指定TupleTag,然后旁路输出
//在上边例子的基础上,为输出PCollection设定tag
// 所有的输出,包括主输出PCollection都被打包到PCollectionTuple中。
PCollectionTuple results =
words.apply(ParDo
.of(new DoFn<String, String>() {
//DoFn内的业务逻辑.
...
})
// 为主输出指定tag.
.withOutputTags(wordsBelowCutOffTag,
// 使用TupleTagList为旁路输出设定ta
TupleTagList.of(wordLengthsAboveCutOffTag)
.and(markedWordsTag)));DoFn中多路输出代码示例:
// 在ParDo的DoFn中,在调用ProcessContext.output的时候可以使用TupleTag指定将结果发送给哪个下游PCollection
// 在ParDo之后从PCollectionTuple中解出输出PCollection
// 在前边例子的基础上,本例示意了将结果输出到主输出和两个旁路输出
.of(new DoFn<String, String>() {
public void processElement(ProcessContext c) {
String word = c.element();
if (word.length() <= wordLengthCutOff) {
// 将长度较短的单词发送到主输出
// 在本例中,是wordsBelowCutOffTag代表的输出
c.output(word);
} else {
// 将长度较长的单词发送到 wordLengthsAboveCutOffTag代表的输出中.
c.output(wordLengthsAboveCutOffTag, word.length());
}
if (word.startsWith("MARKER")) {
// 将以MARKER为开头的单词发送到markedWordsTag的输出中
c.output(markedWordsTag, word);
}
}}));复合Transform
Transform可以嵌套,复杂变换执行多个更简单的变换(例如多个ParDo,Combine,GroupByKey或甚至其他复合Transform)。 将多个Transform嵌入到单个复合变换中可以使代码更加模块化,更易于理解。
Beam SDK包含许多有用的复合转换。 有关转换列表,请参阅API参考页面:
复合Transform的示例
WordCount 示例程序中的CountWordsTransform是复合Transform的示例。 CountWords是由多个嵌套Transform组成的PTransform子类。
在expand展方法中,CountWordsTransform逻辑如下:
- 在文本行的输入PCollection上调用ParDo,产生包含单个词的输出PCollection。
-
它将 Beam SDK库中的Count Transform应用于PCollection的单词,产生一个键/值对的PCollection。 每个键表示文本中的一个单词,每个值表示单词在原始数据中出现的次数。
注意,这也是嵌套复合Transform的示例,因为Count本身就是复合Transform。- 1
复合Transform的参数和返回值必须与整个变换的初始输入类型和最终返回类型相匹配,即使Transform的处理过程中的中间数据的数据类型变化多次。
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
//将每行文本分割成单词
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// 统计每个单词出现的次数
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}创建一个复合Transform
要创建复合Transform,集成PTransform类,并重写expand方法,在方法中实现具体的逻辑。 然后,就可以像使用Beam SDK的内置Transform一样使用此复合Transform。
对于PTransform类类型参数,您将传递您的Transform所用的PCollection类型作为输入,并生成输出。 要将多个PCollections作为输入,或者产生多个PCollections作为输出,从多个PCollection中的选取一个PCollection的类型,作为Transform的输出类型参数。
如下例所示,Transform使用子元素为String类型的PCollection作为输入,子元素为Integer的PCollection作为输出:
static class ComputeWordLengths
extends PTransform<PCollection<String>, PCollection<Integer>> {
...
}重写expand方法
在继承PTransform子类中,需要重写expand方法。 expand方法是添加PTransform的处理逻辑的地方。 重写的expand方法必须接受适当类型的输入PCollection作为参数,并将输出PCollection指定为返回值。
以下代码示例显示如何覆盖上一个示例中声明的ComputeWordLengths类的expand方法:
static class ComputeWordLengths
extends PTransform<PCollection<String>, PCollection<Integer>> {
@Override
public PCollection<Integer> expand(PCollection<String>) {
...
// 转换逻辑
...
}只要重写的PTransform子类中的expand方法来接受适当的输入PCollection并返回相应的输出PCollection,就可以包含任意数量的Transform。 这些变换可以包括Beam核心Transform,复合Transform或Beam SDK库中包含的Transform。
注意:PTransform的expand方法并不意味着转换用户直接调用。 相反,您应该在PCollection本身调用apply方法,以变换为参数。 这允许将转换嵌套在管道的结构中。Pipeline I/O
创建Pipeline时,经常需要从外部数据源或数据库中读取数据。 同样,Pipeline会将其结果数据输出到类似的外部数据接收器。 Beam为许多常见的数据存储类型提供读写Transform。 如果要让Pipeline读取或写入内置Transform中还不支持的数据存储格式,可以 实现自定义的读写Transform。
读取输入数据
读取Transform从外部源读取数据并返回数据的PCollection,供Pipeline使用。 一般在Pipeline创建时读取数据是最常见的,同时也允许在Pipeline中任何需要的地方读取数据。
使用读取Transform
PCollection<String> lines = p.apply(TextIO.read().from("gs://some/inputData.txt"));写入输出数据
写入Transform将PCollection中的数据写入外部数据源。一般在Pipeline结束时读取数据是最常见的,同时也允许在Pipeline中任何需要的地方写入数据到外部数据源。
使用写入Transform
output.apply(TextIO.write().to("gs://some/outputData"));基于文件的读取和写入
从多个位置读取
许多读取Transform支持用glob运算符匹配的多个输入文件中读取数据。 请注意,glob运算符是特定于文件系统的,并遵循文件系统特定的一致性模型。 以下TextIO示例使用glob运算符(*)读取在给定位置中具有前缀“input-”和后缀“.csv”的所有匹配输入文件:
p.apply(“ReadFromText”,
TextIO.read().from("protocol://my_bucket/path/to/input-*.csv");要将来自不同来源的数据读取到单个PCollection中,可以分别读取每个数据源,然后使用FlattenTransform创建合并成单个PCollection。
写入多个文件
对于基于文件的输出数据,默认情况下,写入Transform写入多个输出文件。 将输出文件名传递给写入Transform时,文件名将用作文件的前缀。 可以通过指定一个后缀来为每个输出文件附加一个后缀。
以下写入变换示例将多个输出文件写入到某个位置。 每个文件都有前缀“数字”,数字标签和后缀“.csv”。
records.apply("WriteToText",
TextIO.write().to("protocol://my_bucket/path/to/numbers")
.withSuffix(".csv"));Beam内置的 I/O Transform
数据编码和类型安全
当Beam的执行引擎运行Pipeline时,经常需要序列化反序列化PCollections中的中间数据,这就需要将元素转换为二进制字节码和从二进制字节码中转换。 Beam SDK使用被称为“Coders”的对象来描述如何对给定的PCollection的元素进行编码和解码。
请注意,Coder与外部数据源或汇点交互时与解析或格式化数据无关。 这种解析或格式化通常应该在诸如ParDo或MapElements之类的Transform中明确指定。在Beam Java SDK中,Coder提供编码和解码数据所需的方法。 Java SDK为Java中的标准类型提供了Coder的实现,例如Integer,Long,Double,StringUtf8等。 可以在Coder包中找到所有可用的Coder子类。
请注意,Coder与类型不定是1:1的关系。 例如,整数类型可以有多个有效的编码器,输入和输出数据可以使用不同的整数编码器。 Transform可能使用使用BigEndianIntegerCoder输入数据,而使用VarIntCoder输出数据。
设置Coder
Beam要求Pipeline中的每个PCollection都有Coder。在大多数情况下,Beam SDK能够根据PCollection元素类型或生成它的Transform来自动推断PCollection的Coder,但是在某些情况下,Pipeline的开发者需要明确指定Coder,或者开发一个自定义类型的Coder。
可以使用PCollection.setCoder方法显式设置现有PCollection的Coder。请注意,无法在已完成的PCollection上调用setCoder(例如,调用.apply之后)。
可以使用getCoder方法获取现有PCollection的Coder。如果Coder尚未设置且不能推断PCollection的Coder,则此方法将调用失败,并抛出IllegalStateException。
Beam SDK在尝试自动推断PCollection的Coder时使用了多种机制。
每个Pipeline对象都有一个CoderRegistry。 CoderRegistry表示Java类型与Pipeline应用于每种类型的PCollection的默认Coder的对应关系。
默认情况下,Beam Java SDK 会自动使用Transform函数对象的类型参数(如DoFn)作为PTransform生成的PCollection的Coder。在ParDo的情况下,例如,DoFn
默认Coder和CoderRegistry
每个Pipeline对象都有一个CoderRegistry对象,它将语言类型映射到Pipeline要使用的类型的默认Coder。 您可以自己使用CoderRegistry查找给定类型的默认编码器,或者为给定类型注册新的默认编码器。CoderRegistry包含了Beam Java SDK创建的Pipeline的Coder与标准Java类型的默认映射。
下表显示了标准对应关系:
| Java 类型 | 默认Coder |
|---|---|
| Double | DoubleCoder |
| Instant | InstantCoder |
| Integer | VarIntCoder |
| Iterable | IterableCoder |
| KV | KvCoder |
| List | ListCoder |
| Map | MapCoder |
| Long | VarLongCoder |
| String | StringUtf8Coder |
| TableRow | TableRowJsonCoder |
| Void | VoidCoder |
| byte[ ] | ByteArrayCoder |
| TimestampedValue | TimestampedValueCoder |
查找默认Coder
使用CoderRegistry.getDefaultCoder方法可以获取Java类型的默认Coder。 使用Pipeline.getCoderRegistry方法可以访问Pipeline的CoderRegistry。 这样就可以基于每个流水线确定(或设置)Java类型的默认Coder:即“对于此Pipeline,验证是否是使用BigEndianIntegerCoder对Integer值进行编码”。
为类型设置默认编码器
要为Pipeline为Java类型设置默认编码器,可以获取并修改管道的CoderRegistry。 可使用Pipeline.getCoderRegistry方法获取CoderRegistry对象,然后使用CoderRegistry.registerCoder方法为目标类型注册新的Coder。
以下示例代码演示了如何为流水线的整数值设置默认Coder(在本例中为BigEndianIntegerCoder)。
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
CoderRegistry cr = p.getCoderRegistry();
cr.registerCoder(Integer.class, BigEndianIntegerCoder.class);使用注解为自定义类型设置默认Coder
如果Pipeline使用了自定义数据类型,则可以使用@DefaultCoder注释来指定要与该类型一起使用的Coder。 例如,假设要使用SerializableCoder的自定义数据类型,可以使用@DefaultCoder注释,如下所示:
@DefaultCoder(AvroCoder.class)
public class MyCustomDataType {
...
}如果创建了一个自定义Coder来匹配数据类型,并且要使用@DefaultCoder注释,则自定义的Coder类必须实现静态Coder.of(Class )工厂方法。
public class MyCustomCoder implements Coder {
public static Coder<T> of(Class<T> clazz) {...}
...
}
@DefaultCoder(MyCustomCoder.class)
public class MyCustomDataType {
...
}窗口(Window)
窗口根据PCollection中的每个元素的时间戳细分PCollection。 聚合运算(如GroupByKey和Combine)在每个窗口的基础上隐式工作 - 它们将每个PCollection作为多个有限窗口的连续过程进行处理,尽管整个集合本身可能是无限大小的。
触发器用来决定何时在无限数据到达时发出聚合结果,使用触发器可有优化PCollection的窗口策略。 触发器允许处理迟到的数据或在窗口结束前预先计算不完整的结果。 有关详细信息,请参阅触发器部分。
窗口的基础概念Windowing basics
一些Beam Transform,如GroupByKey和Combine,通过公共key对多个元素进行分组。 通常,分组操作将在整个数据集中具有相同key的所有元素分组。 使用无限数据集,由于新元素不断被添加并且可能是无限多的(例如流数据),所以不可能在某一个时刻是PCollection包含了所有的元素,此时窗口特别有用。
在Beam模型中,任何PCollection(包括无限PCollections)都可以使用逻辑上的窗口进行切分。 PCollection中的每个元素根据PCollection的窗口功能分配给一个或多个窗口,每个窗口包含有限数量的元素。 分组Transform然后在每个窗口的基础上处理PCollection的每个元素。 GroupByKey,例如,通过键和窗口隐式地分组PCollection的元素。
注意:Beam的默认窗口行为是将PCollection的所有元素分配到单个全局窗口,并丢弃迟到的数据,即使对于无限PCollections也是如此。 在无限PCollection使用GroupByKey之类的分组变换之前,必须至少执行以下操作之一:
• 设置一个非全局的窗口函数,参见为PCollection设置窗口函数.
• 设置一个非默认的 触发器,这可以防止触发窗口的默认行为(等待所有的数据到达).如果没有为无限PCollection设置非全局窗口函数或非默认触发器,随后使用GroupByKey或Combine等分组Transform是,在构建Pipeline时将会发生错误,作业会失败。
窗口的限制
为PCollection设置窗口函数后,下次将组合Transform应用于PCollection时,将使用窗口作为基础。 窗口分组根据需要进行。 如果您使用Window转换设置了一个窗口函数,则将每个元素分配给一个窗口,只有在GroupByKey或Combine这样的操作中才会用到窗口。 这可能会对Pipeline产生不同的影响。 考虑下图中的示例Pipeline:
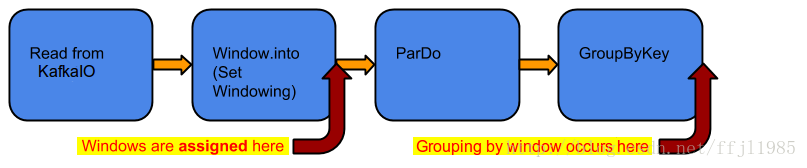
在上述Pipeline中,使用KafkaIO读取一组键/值对来创建一个无限PCollection,然后使用WindowTransform将该窗口函数应用于该集合, 然后将ParDo应用于该集合,然后使用GroupByKey将ParDo的结果分组。 窗口函数对ParDoTransform没有影响,因为在GroupByKey需要之前,窗口实际上并没有被使用。 然后,GroupByKey之后的处理就是基于键和窗口的分组。
在有限数据集上使用窗口
在有限PCollections中可以使用具有固定大小的窗口。 但是,请注意,窗口仅考虑附加到PCollection的每个元素的隐式时间戳,创建固定数据集的数据源(如TextIO)会为每个元素分配相同的时间戳。 这意味着默认的所有元素都属于单个全局窗口。
要在限数据集上使用窗口,可以为每个元素分配自己的时间戳。 要为元素分配时间戳,请使用具有DoFn的ParDo转换,在DoFn中为每个元素附加一个新的时间戳(例如,在Beam Java SDK中的WithTimestamps Transform)。
为了说明如何使用有限PCollection进行窗口化可能会影响Pipeline如何处理数据,如下图所示:
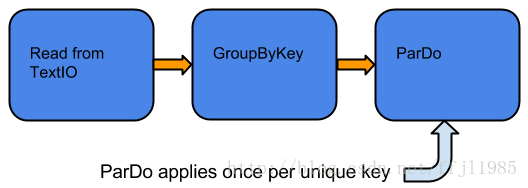
图: 有限数据集,GroupByKey 和ParDo 没有使用窗口.
在上面的Pipeline中,使用TextIO读取一组键/值对来创建一个有限PCollection。 然后,使用GroupByKey对集合进行分组,并将ParDo转换应用于分组的PCollection。 在此示例中,GroupByKey创建一个唯一的键值对(值是输入元素的值的集合),然后ParDo对每个key处理1次。
请注意,即使没有设置窗口函数,仍然有1个窗口 - PCollection中的所有元素都分配给单个全局窗口。
现在对相同的Pipeline使用窗口函数,如下图所示:
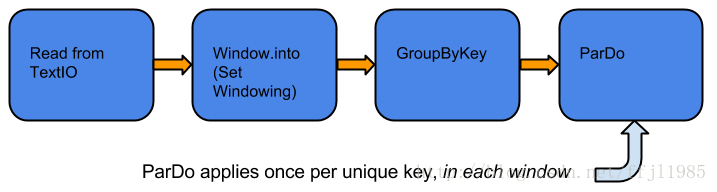
图: 在有限PCollection上应用窗口,使用GroupByKey 和ParDo 处理
如上所示,Pipeline创建一个元素为键值对的PCollection,然后为PCollection设置一个窗口函数,GroupByKeyTransform基于窗口,通过键和窗口对PCollection的元素进行分组。 随后的ParDo Transform对每个key应用多次,每个窗口一次。
窗口函数
可以使用不同类型的窗口来切分PCollection的元素。 Beam提供了几个窗口功能,包括:
• 固定时间窗口Fixed Time Windows
• 滑动时间窗口Sliding Time Windows
• 会话窗口Per-Session Windows
• 单一全局窗口Single Global Window
• 基于日历的时间窗口Calendar-based Windows 注意:每个元素可以逻辑上属于多个窗口,具体取决于使用的窗口函数。 例如,滑动时间窗口创建重叠的窗口,其中可以将单个元素分配给多个窗口。
固定时间窗口
最简单的窗口形式是使用固定时间窗口:有1个持续更新的时间戳PCollection,每个窗口可以捕获(例如)所有时间戳在5分钟时间间隔内的元素。
固定时间窗口表示数据流中一致的连续、不重叠的时间间隔。 比如5分钟固定长度窗口:无限PCollection中的所有元素,时间戳值从0:00:00到(但不包括)0:05:00属于第一个窗口,时间戳值为0的元素 :05:00(但不包括)0:10:00属于第二个窗口,依此类推。
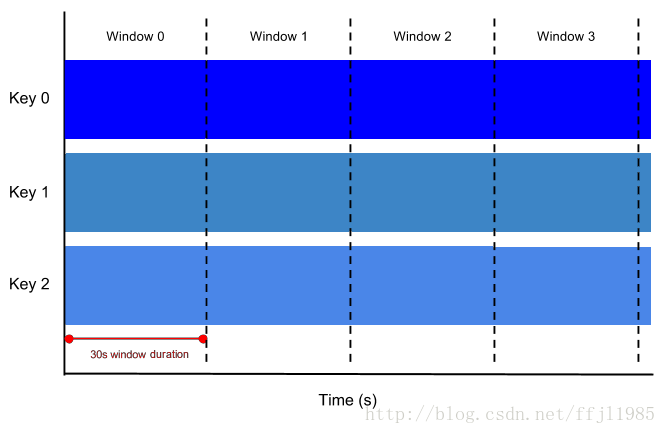
图30.秒时间长度的固定时间窗口
滑动时间窗口
滑动时间窗口也表示数据流中的时间间隔; 然而,滑动时间窗口可以重叠。 例如,每个窗口可能捕获五分钟的数据,但是每十秒钟会启动一个新窗口。 滑动窗口开始的频率称为周期。 因此,示例中的窗口的时间长度为5分钟,滑动周期为10秒钟。
由于多个窗口重叠,数据集中的大多数元素将属于多个窗口。 这种窗口对于计算不断变化的数据的均值非常有用; 使用滑动时间窗口,可以在示例中计算过去5分钟的数据的运行平均值,每10秒更新一次。
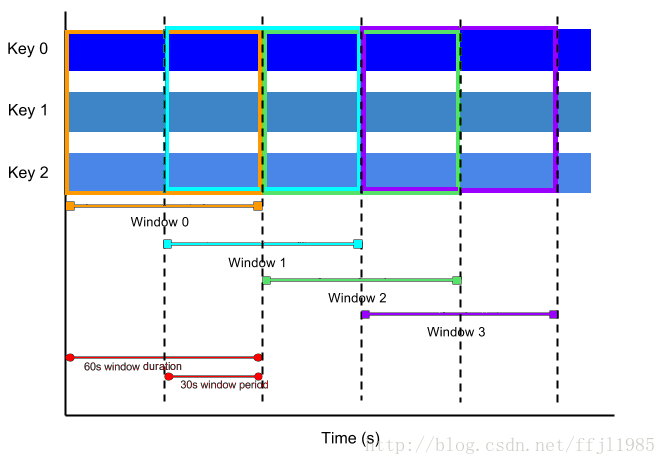
图:滑动窗口,长度时间1分钟,30秒一个周期
会话窗口
会话窗口是一种在时间上非连续的窗口。 会话窗口适用于每个key,对于在时间上呈现不规则分布的数据很有用。 例如,表示用户鼠标活动的数据流可能具有长时间的空闲时间,而在另一个时间范围内点击很多。 如果数据在最小时间隙之后到达,则启动一个新的窗口。
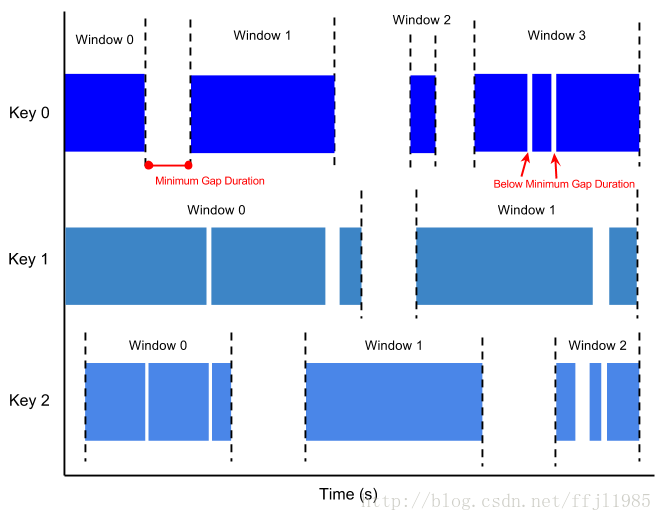
图: 会话窗口,以1分钟作为最小时间间隔。
注意: 每一个key因为数据在时间分布上的差异,而具有不同的窗口。
单一全局窗口
默认情况下,PCollection中的所有数据都被分配给单一全局窗口,并且丢弃迟到的数据。 如果是有限数据集,则可以使用PCollection的全局窗口默认值。
如果是无限数据集(例如来自流式数据源),也可以使用单个全局窗口,但在应用聚合Transform时(如GroupByKey和Combine)时要小心。 带有默认触发器的单个全局窗口通常要求整个数据集在处理之前可用,这在连续更新数据时是不可能的。 要在使用全局窗口的无限PCollection上执行聚合,应为该PCollection指定非默认触发器。
在PCollection上使用窗口函数
可以通过apply窗口Transform来设置PCollection的窗口函数。 进行WindowTransform时,必须提供一个WindowFn。 WindowFn用来确定PCollection使用哪种窗口函数来切分PCollection,如固定或滑动时间窗口。
Beam为此处描述的基本窗口功能提供预定义的WindownFn。 如有更复杂的需求,您还可以自定义WindowFn。
设置窗口函数时,可能还需要为PCollection设置触发器(trigger)。 触发器用来决定每个窗口何时被聚合和发出,并且能让窗口函数能够对迟到的数据的处理和在窗口超时前预先计算结果有更好的方式。 有关详细信息,请参阅触发器部分。
使用固定时间窗口
以下示例代码显示了如何1分钟长度的固定时间窗口应用在PCollection上:
PCollection<String> items = ...;
PCollection<String> fixed_windowed_items = items.apply(
Window.<String>into(FixedWindows.of(Duration.standardMinutes(1))));使用滑动时间窗口
以下示例代码显示了如何使用滑动时间窗口将PCollection切分。 每个窗口长度为30分钟,每5秒钟开1个新窗口:
PCollection<String> items = ...;
PCollection<String> sliding_windowed_items = items.apply(
Window.<String>into(SlidingWindows.of(Duration.standardMinutes(30)).every(Duration.standardSeconds(5))));使用会话时间窗口
以下示例代码显示了如何使用会话窗口切分PCollection,最小的时间跨度为10分钟:
PCollection<String> items = ...;
PCollection<String> session_windowed_items = items.apply(
Window.<String>into(Sessions.withGapDuration(Duration.standardMinutes(10))));注意:会话窗口首先是基于key的,每个key有自己的会话窗口,有多少个会话窗口,取决于数据在时间上的分布。
使用单一全局窗口
如果您的PCollection是有限的(大小是固定的),可以将所有元素分配给单一全局窗口。 以下示例代码显示如何为PCollection设置单一全局窗口:
PCollection<String> items = ...;
PCollection<String> batch_items = items.apply(
Window.<String>into(new GlobalWindows()));Watermark和延迟数据
在任何数据处理系统中,数据事件产生时间(由数据元素本身的产生的时刻,确定的“事件时间”)与实际数据元素的处理时刻之间存在一定的滞后(“处理时间”,由系统上数据被处理的时刻决定)。此外,不能保证数据事件将按照生成的顺序在Pipeline中进行处理。
例如,假设我们有一个使用固定时间窗口的PCollection,窗口长度为五分钟。对于每个窗口,Beam必须在给定的窗口范围内(例如在第一个窗口的0:00和4:59之间)收集所有的数据,判断依据是事件时间。时间戳超出该范围(5:00或更晚的数据)的数据属于不同的窗口。
然而,数据无法保证按照事件时间的顺序到达Pipeline,或者始终以可预测的延迟到达。Beam使用Watermark的概念,即认为某个窗口中的所有数据都到达的时刻。在Watermark之后的数据叫做延迟数据。
从我们的例子中,假设我们有一个简单的水印,假设数据时间戳(事件时间)和数据出现在Pipeline的时间(处理时间)之间大约30秒的滞后时间,那么Beam将在5 :30关闭第一个窗口。如果数据记录到达5:34,但是时间戳记会在0:00-4:59窗口(比如说3:38)中,那么该记录是延迟数据。
注意:为简单起见,我们假设使用了一个非常简单的Watermark来估计滞后时间。实际上,PCollection的数据源决定了Watermark,并且Watermark可能更精确或更复杂。Beam的默认窗口配置,会基于数据源的类型,尝试确定所有数据何时到达,然后将Watermark提前移动到窗口的末尾。此默认配置下延迟数据会被丢弃。使用触发器(Trigger)可以修改和优化PCollection的窗口策略,来决定每个窗口何时聚合并报告其结果,同时包含了窗口如何处理延迟数据的策略。
处理延迟数据
设置PCollection的窗口策略时,调用.withAllowedLateness操作来允许延迟数据。 以下代码示例演示了窗口策略,允许在窗口结束后最多两天的延迟数据。
PCollection<String> items = ...;
PCollection<String> fixed_windowed_items = items.apply(
Window.<String>into(FixedWindows.of(Duration.standardMinutes(1)))
.withAllowedLateness(Duration.standardDays(2)));当在PCollection中设置.withAllowedLateness时,设置的允许延迟时间会向前传播到该PCollection的任何后续PCollection。 如果要稍后在Pipeline中更改允许的延迟,则必须通过显式调用Window.configure().withAllowedLateness()来修改。
为PCollection的元素赋予时间戳
无限数据源为每个元素附加了时间戳。但是由于数据来源类型的不同,时间戳可能不符合需要,可能需要从原始数据流中重新提取时间戳。有限数据源(例如来自TextIO的文件)不提供时间戳, 如果需要时间戳,则必须将它们添加到PCollection的元素中。
可以通过使用ParDo Transform为PCollection的元素分配新的时间戳,在ParDo Transform中添加时间戳后,输入一个新的PCollection。例如:如果Pipeline从输入文件读取日志记录,并且每个日志记录都包含时间戳字段; 由于Pipeline从文件读取记录,文件源不会自动分配时间戳。 此时需要从每个记录中解析时间戳字段,并使用带DoFn的ParDo Transform将时间戳附加到PCollection中的每个元素。
PCollection<LogEntry> unstampedLogs = ...;
PCollection<LogEntry> stampedLogs =
unstampedLogs.apply(ParDo.of(new DoFn<LogEntry, LogEntry>() {
public void processElement(ProcessContext c) {
// 从当前处理的日志记录中解析出时间戳E
Instant logTimeStamp = extractTimeStampFromLogEntry(c.element());
// 使用ProcessContext.outputWithTimestamp (而不是
// ProcessContext.output)发出带有时间错的日志记录 c.outputWithTimestamp(c.element(), logTimeStamp);
}
}));触发器
当收集数据并将数据按照窗口进行分组时,Beam使用触发器来确定何时发出每个窗口的聚合结果(称为窗格)。 如果使用Beam的窗口默认设置和默认触发器,Beam会在估计所有数据到达时输出聚合结果,并丢弃该窗口的所有延迟数据。
可以为PCollections设置触发器来更改此默认行为。 Beam提供了一些内置触发器:
-
事件时间触发器
这类触发器根据事件时间进行触发,Beam的默认触发器是事件时间触发器。 -
处理时间触发器
这类触发器根据事件的处理时间(在Pipeline中的每个阶段处理数据元素的时间)进行触发。 -
数据驱动触发器
这类触发器通过在数据到达每个窗口时检查数据,并在数据满足某个属性时触发操作。 目前,数据驱动的触发器只支持在一定数量的数据元素之后触发。 -
复合触发器
这类触发器组合使用事件时间触发器、处理时间触发器、数据驱动触发器等。
从更高的层次看,与简单的在窗口结束时输出数据相比,触发器提供两个附加功能:
-
触发器允许Beam在窗口中的所有数据到达之前,先计算并发出结果。
例如,在经过一段时间之后或在一定数量的元素到达之后计算并发出,此时窗口尚未关闭. -
触发器提供了在事件时间的Watermark超过窗口结束时间之后处理延迟数据的机会。
这些特性让开发者能够控制数据流和在不同约束之前取舍:
- 完整性
在计算结果之前是否必须要确保所有的数据都达到了? - 延迟时间
能容忍想等待数据多久? 例如,是否等到您认为拥有所有数据? 在数据到达时处理数据? - 成本
愿意为降低延迟而花费多少计算能力/资金?
例如,时间敏感的系统可能会使用严格的基于时间的触发器,每N秒发出一个窗口,数据的时效性的重要程度大于完整性。 数据完整性超过结果的时效性的系统可能会选择使用Beam的默认触发器,该触发器在窗口的末尾触发。还可以为无限PCollection设置触发器,该触发器使用单个全局窗口进行PCollection切分。 当希望Pipeline在无限数据集上提供定期更新时,这可能会很有用 - 例如,当前所拥有的数据的平均值,每N秒更新一次或每N个元素。
事件时间触发器 Event Time Trigger
AfterWatermark触发器以事件时间为基础触发。 当Watermark超过窗口末尾时触发,将窗口中的数据发送到下游。Watermark是全局的进程指标,在Beam的概念中,表示输入是否完整。 AfterWatermark.pastEndOfWindow()仅在Watermark通过窗口的末尾时触发。 此外,可以使用.withEarlyFirings(trigger)和.withLateFirings(trigger)来配置触发器,当Pipeline在窗口结束之前或之后收到数据,则触发器将触发。
// 在月末的时候生成账单
AfterWatermark.pastEndOfWindow()
//持续的实时产生预计账单
.withEarlyFirings(
AfterProcessingTime
.pastFirstElementInPane()
.plusDuration(Duration.standardMinutes(1))
// 当延迟数据到达的时候持续的修正账单,最终账单是准确的F
.withLateFirings(AfterPane.elementCountAtLeast(1))默认触发器Default Trigger
PCollection的默认触发是基于事件时间,当Beam的Watermark超过窗口的末尾时,发出窗口的结果,然后每当延迟数据到达时触发。
但是,如果同时使用窗口默认设置和默认触发器,则默认触发器将会发出一次,并且丢弃延迟的数据。 这是因为默认窗口配置的允许的延迟值为0.有关修改此行为的信息,请参阅处理延迟数据部分。
处理时间触发器
AfterProcessingTime触发器根据处理时间进行触发。 例如,AfterProcessingTime.pastFirstElementInPane()触发器在收到数据后经过一定的处理时间后会发出一个窗口。 处理时间由系统时钟决定,而不是数据元素的时间戳。AfterProcessingTime触发器可用于触发窗口的早期结果,特别是时间跨度非常大的窗口(如单个全局窗口)。
数据驱动触发器Data-Driven Triggers
Beam提供了一个数据驱动的触发器AfterPane.elementCountAtLeast()。 该触发器对元素计数起作用; 它在当前窗格至少收集了N个元素后触发。 这允许窗口发出早期的结果(在所有数据已经累积之前),如果使用单个全局窗口,这可能特别有用。需要注意的是,例如,如果使用.elementCountAtLeast(50)并且只有32个元素到达,则这32个元素永远没有机会触发,如果32个元素很重要,考虑使用复合触发器来组合多个触发条件,例如“当我收到50个元素或每1秒触发”时。
设置触发器
使用Window Transform为PCollection设置窗口函数时,可以指定触发器。通过在Window.into()转换结果上调用方法.triggering()来设置PCollection的触发器,如下所示:
PCollection<String> pc = ...;
pc.apply(Window.<String>into(FixedWindows.of(1, TimeUnit.MINUTES))
.triggering(AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(Duration.standardMinutes(1)))
.discardingFiredPanes());此代码示例为PCollection设置基于时间的触发器,该触发器在该窗口中的第一个元素已被处理后1分钟发出结果。 代码示例中的最后一行.discardingFiredPanes()是窗口的累加模式。
窗口累积模式Window Accumulation Modes
当指定触发器时,还必须设置窗口的累积模式。 当触发器触发时,它将窗口的当前内容作为窗格发出。 由于触发器可以多次触发,所以累积模式决定系统是否在触发器触发时累加窗口窗格,或者丢弃它们。
要设置窗口以累积触发器触发时生成的窗格,请在设置触发器时调用.accumulatingFiredPanes()。 要设置一个窗口来放弃已触发的窗格,请调用.discardingFiredPanes()。
我们来看一个使用具有固定时间窗口和基于数据的触发器的PCollection的例子。 例如,如果窗口长度为10分钟,然后计算数据的均值,但是希望在UI中更新频繁显示当前平均值,而不是每10分钟更新一次。
- 假设以下条件:
-
- PCollection 使用了一个10分钟长度的固定窗口
-
- PCollection 使用了一个每来3个新元素触发一次的可重复触发器。
下图显示了具有key = X事件,到达PCollection并将其分配给窗口。 为了使图表更简单,假设事件都按顺序到达:

累积模式Accumulating Mode
如果触发器设置为.accumulatingFiredPanes,触发器将在每次触发时发出以下值。 记住,每次3个新元素到达时触发器都会触发:
第1次触发: [5, 8, 3]
第2次触发: [5, 8, 3, 15, 19, 23]
第3次触发: [5, 8, 3, 15, 19, 23, 9, 13, 10]丢弃模式Discarding Mode
如果触发器设置为 .discardingFiredPanes,触发器每次触发时,发出的数据如下:
第1次触发: [5, 8, 3]
第2次触发: [15, 19, 23]
第3次触发: [9, 13, 10]处理延迟数据Handling Late Data
如果希望Pipeline处理Watermark超过窗口末尾后到达的数据,可以在设置窗口时设置允许的延迟时间。 这使触发器有机会处理延迟数据。 如果设置了允许的延迟时间,默认的触发器会在延迟数据到达时立即发出新的结果。
使用.withAllowedLateness() 允许的延迟时间:
PCollection<String> pc = ...;
pc.apply(Window.<String>into(FixedWindows.of(1, TimeUnit.MINUTES))
.triggering(AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(Duration.standardMinutes(1)))
.withAllowedLateness(Duration.standardMinutes(30));允许的延迟时间会向下传播,设置了PCollection的后续PCollection都会继承。 如果要稍后在Pipeline中更改允许的延迟时间,可以显式调用Window.configure().AllowedLateness()。
复合触发器
可以组合多个触发器来形成复合触发器,并且可以指定触发器的触发方式:重复发出结果,最多一次或其他自定义条件。
复合触发器的类型
Beam包括以下复合触发器:
-
可以通过.withEarlyFirings和.withLateFirings向AfterWatermark.pastEndOfWindow添加额外的提前触发或延迟启动。
-
Repeatedly.forever指定一个永远重复执行的触发器。任何触发条件满足时,都会导致窗口发出结果,然后重置并重新开始。将Repeatedly.forever与.orFinally组合可以指定重复触发器停止的条件。
-
AfterEach.inOrder组合多个触发器以特定的顺序启动。每次序列中的触发器发出一个窗口,然后指向下一个触发器。
-
AfterFirst需要多个触发器,并且首次发出任何一个参数触发器都被满足。相当于多个触发器的逻辑OR运算。
-
AfterAll需要多个触发器,并在其所有参数触发器都满足时发出。相当于多个触发器的逻辑AND运算。
- orFinally 可以作为最后的条件,引起任何触发器最后一次启动,再也不能再次触发。
与 AfterWatermark.pastEndOfWindow复合
当Beam估计所有的数据已经到达时(即当水印通过窗口的末端)与以下两者或两者结合使用时,一些最有用的复合触发器触发一次:
-
Watermark超过窗口末尾之前的推测性触发,以允许更快地处理但有可能只发出部分结果(不是完整的)。
-
**Watermark超过窗口的末尾之后发生的延迟触发,以允许处理延迟数据
可以使用AfterWatermark.pastEndOfWindow来表达此模式。 例如,以下示例代码表示在如下条件下触发:
•当Beam估计,所有的数据已经到达(Watermark超过窗口的末尾)时触发。
•经过10分钟延迟后,每一次延迟数据到达触发。
•2天后,我们认为再也不会有新数据到达,触发器停止执行。.apply(Window
.configure()
.triggering(AfterWatermark
.pastEndOfWindow()
.withLateFirings(AfterProcessingTime
.pastFirstElementInPane()
.plusDelayOf(Duration.standardMinutes(10))))
.withAllowedLateness(Duration.standardDays(2)));其他组合触发器
触发器可以组合使用,构建其他类型的复合触发器。 以下示例代码显示了一个简单的复合触发器,每当窗格至少有100个元素或每1分钟触发1次。
Repeatedly.forever(AfterFirst.of(
AfterPane.elementCountAtLeast(100),
AfterProcessingTime.pastFirstElementInPane().plusDelayOf(Duration.standardMinutes(1))))
 浙公网安备 33010602011771号
浙公网安备 33010602011771号