

抓取页面代码
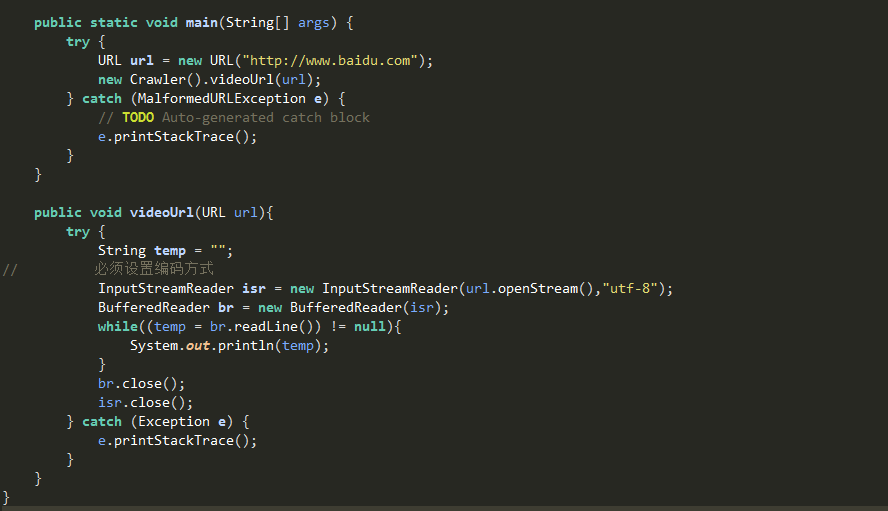
|
import java.io.BufferedReader; import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
public class Crawler {
public static void main(String[] args) {
try {
URL url = new URL("http://www.baidu.com");
new Crawler().videoUrl(url);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void videoUrl(URL url){
try {
String temp = "";
// 必须设置编码方式
InputStreamReader isr = new InputStreamReader(url.openStream(),"utf-8");
BufferedReader br = new BufferedReader(isr);
while((temp = br.readLine()) != null){
System.out.println(temp);
}
br.close();
isr.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号