360搜索引擎取真实地址-python代码
还是个比较简单的,不像百度有加密算法
分析
http://www.so.com/link?url=http%3A%2F%2Fedu.sd.chinamobile.com%2Findex%2Fnews.do%3Faction%3DnoticeDetail%26id%3D22452&q=inurl%3Anews.do&ts=1488978912&t=89c5361a44fe3f52931d25c6de262bb&src=haosou
网址是上面这个样子,没加密直接取就好了,去掉头http://www.so.com/link?url=和尾&q=一直到末尾的部分,剩下的就可以吃了
那么规则我们就可以写出来了
a['href'][a['href'].index('?url='):a['href'].index('&q=')][5:]
a['href']是待处理网址,a['href'].index('?url='):a['href'].index('&q=')的部分为?url=http%3A%2F%2Fedu.sd.chinamobile.com%2Findex%2Fnews.do%3Faction%3DnoticeDetail%26id%3D22452
最后还需要用unquote解码
- 在python3中是
urllib.parse.unquote - 在python2中是
urllib.unquote
code
import requests
from bs4 import BeautifulSoup
from urllib.parse import unquote
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#爬取360搜索引擎真实链接,第一个参数关键词str,第二个参数爬取页数int
def parse360(keyword, pagenum):
keywordsBaseURL = 'https://www.so.com/s?q=' + str(keyword) + '&pn='
pnum = 1
while pnum <= int(pagenum):
baseURL = keywordsBaseURL + str(pnum)
try:
request = requests.get(baseURL, headers=headers)
soup = BeautifulSoup(request.text, "html.parser")
urls = [unquote(a['href'][a['href'].index('?url='):a['href'].index('&q=')][5:]) for a in soup.select('li.res-list > h3 > a')]
for url in urls:
yield url
except:
yield None
finally:
pnum += 1
用法示例:
def main():
for url in parse360("keyword",10):
if url:
print url
else:
continue
if __name__ == '__main__':
main()
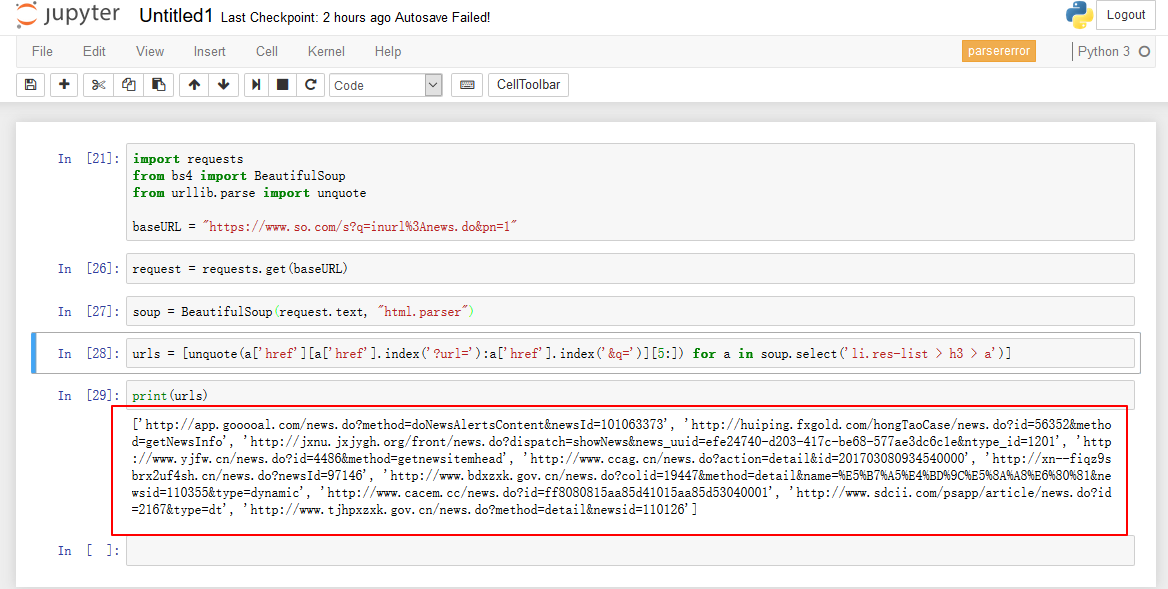
最后上一张测试图
转载请注明出处

 浙公网安备 33010602011771号
浙公网安备 33010602011771号