
打造一个壁纸爬虫来爬你的老婆
好久没写东西了,随便水一篇文,也是比较简单的东西
可能每个喜欢二次元的人都有自己的老婆或者老公吧,之前在朋友那里看到了一个壁纸网站wall.alphacoders.com,要是我想要亚丝娜的壁纸,只需要搜索她的英文名Asuna即可看到一千多张有关亚丝娜的壁纸。壁纸收集爱好者肯定就和我一样想把它们给下载到自己的电脑上幻灯片当作壁纸了,当然手工下载是不可能的,必须写下爬虫,分析下壁纸下载流程。
请求分析
首先我们F12打开开发者工具,在一张图上找到下载
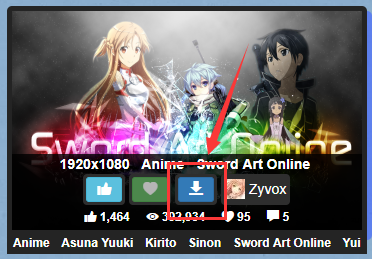
我们在开发者工具里面取元素,并没有看到下载链接,说明下载链接并没有包含在原始html中,但是点击是可以下载的,并且可以看到整个页面并没有进行刷新,判断是一个ajax请求,直接点进XHR,然后再次点击下载链接可以看到请求。
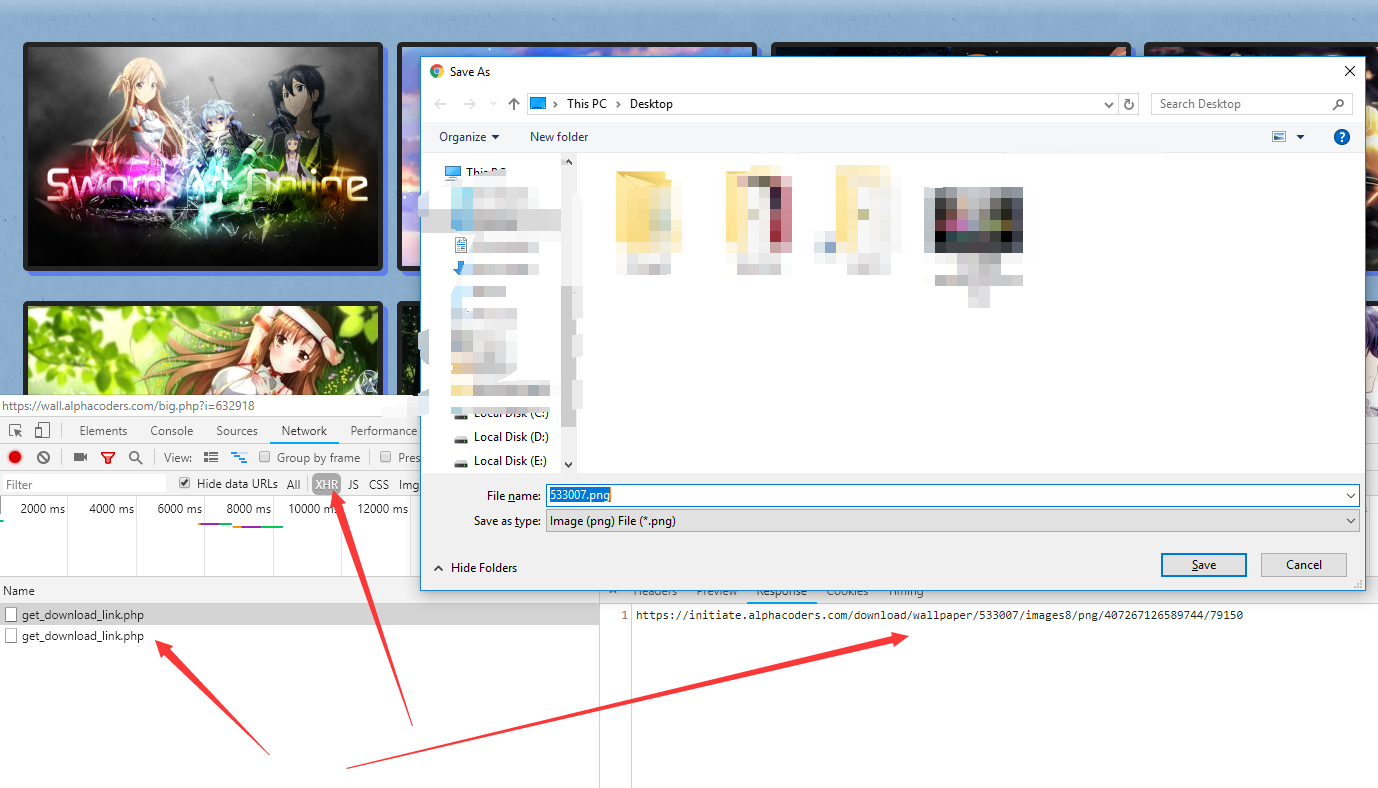
可以看到这个请求返回了一个链接,我们直接访问链接,发现是可以下载的,说明这就是下载链接了,那么这个链接是怎么来的呢?
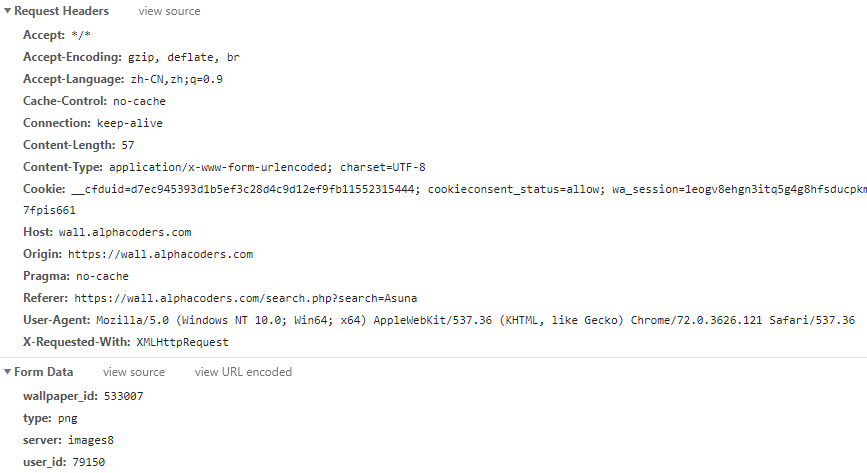
我们看看请求,这个post请求里面有一些参数,我们先不去考虑这些参数怎么来的,我们先模拟一下请求看看请求Header里面有没有什么东西是必须的,这里直接上postman或者curl都可以,如果你的机器上面安装了curl我推荐用这个,因为Chrome开发者工具,直接可以在请求上右键Copy as cURL,直接可以帮你复制出curl命令,我这里复制出来是这样的
curl "https://wall.alphacoders.com/get_download_link.php" -H "Pragma: no-cache" -H "Origin: https://wall.alphacoders.com" -H "Accept-Encoding: gzip, deflate, br" -H "Accept-Language: zh-CN,zh;q=0.9" -H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36" -H "Content-Type: application/x-www-form-urlencoded; charset=UTF-8" -H "Accept: */*" -H "Cache-Control: no-cache" -H "X-Requested-With: XMLHttpRequest" -H "Cookie: __cfduid=d7ec945393d1b5ef3c28d4c9d12ef9fb11552315444; cookieconsent_status=allow; wa_session=1eogv8ehgn3itq5g4g8hfsducpkm9lbu46q893vrkhph3ued4rm89gvk7ck4fdg9k73cmrcdesoqj4crm1575vj3lfid9e67fpis661" -H "Connection: keep-alive" -H "Referer: https://wall.alphacoders.com/search.php?search=Asuna" --data "wallpaper_id=533007^&type=png^&server=images8^&user_id=79150" --compressed
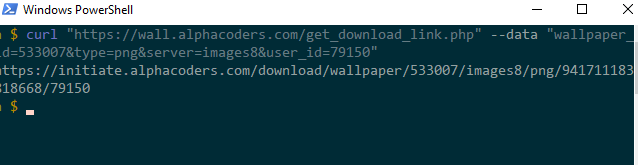
我们先去掉不必要的东西 curl "https://wall.alphacoders.com/get_download_link.php" --data "wallpaper_id=533007&type=png&server=images8&user_id=79150" ,直接执行,发现可以获取到地址,所以现在要考虑的只有这些参数是怎么来的了,下面我同样放一张postman的图,可以看到是同样的可以获取到下载链接
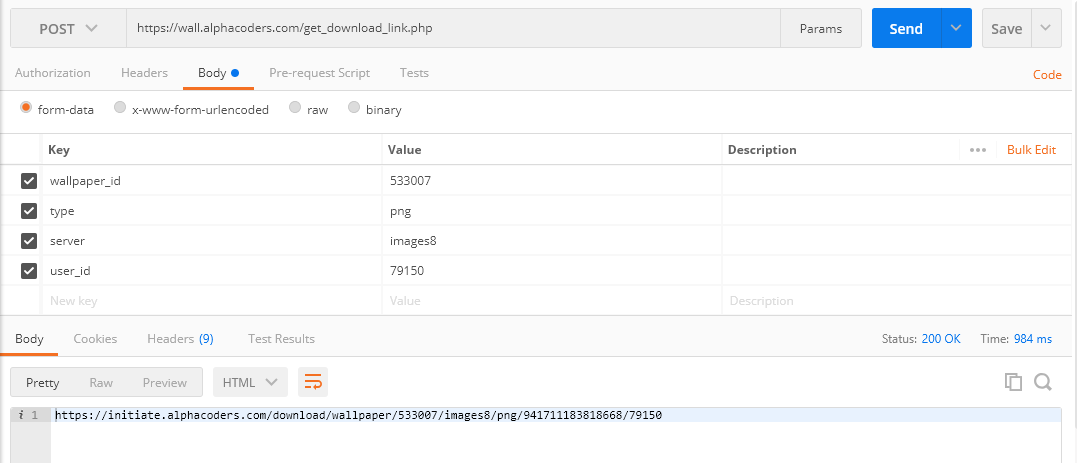
这些参数我们从两方面考虑,一是用js算出来的,一个就是在html中存在的。
我们首先在html里找找看有没有。
通过关键字搜索页面html,我们可以找到每一张图都有一串类似于下面的属性
data-id="533007" data-type="png" data-server="images8" data-user-id="79150"
和上面的post参数是一一对应的。
所以爬取思路就出来了。
访问一个页面,取到每一个图的特定属性,然后构造post请求得到下载地址,然后访问地址下载图片
那新问题是如果进行翻页并且判断是否到了最后一页。
我们可以发现页数是通过get的网址决定的,https://wall.alphacoders.com/search.php?search=asuna&page=10 ,更改page后面的值即可。
判断是否到了尾页,我们可以打开最后一页,然后查看一下html,我们可以看到下一页按钮的链接已经变成了 <a id='next_page' href='#'>Next ></a> ·,那我们就可以根据href的值是否为 # 来判断了。
Python库的选择
唯一用到的第三方库就是 Requests ,以前解析html的Dom树喜欢用BeautifulSoup,但是后来发现解析速度上确实和re有很大差距,并且当html有很特殊的字符时会又是莫名出错,故工程量不大的情况下,我现在还是优选正则。
代码
#coding=utf-8
import requests
import re
import os
import sys
proxies = { "http": "http://127.0.0.1:1080", "https": "http://127.0.0.1:1080", }
#proxies = {}
download_dir = './pic/'
downloaded_num = 0
total = 0
def download_pic(url, name, pic_type):
global proxies
global download_dir
global downloaded_num
global total
# if dir isn't exist, create a dir to download pic
if not os.path.exists(download_dir):
os.makedirs(download_dir)
# download pic to special dir
r = requests.get(url, proxies=proxies)
downloaded_num += 1
with open('%s/%s.%s'%(download_dir, name, pic_type), 'wb') as f:
f.write(r.content)
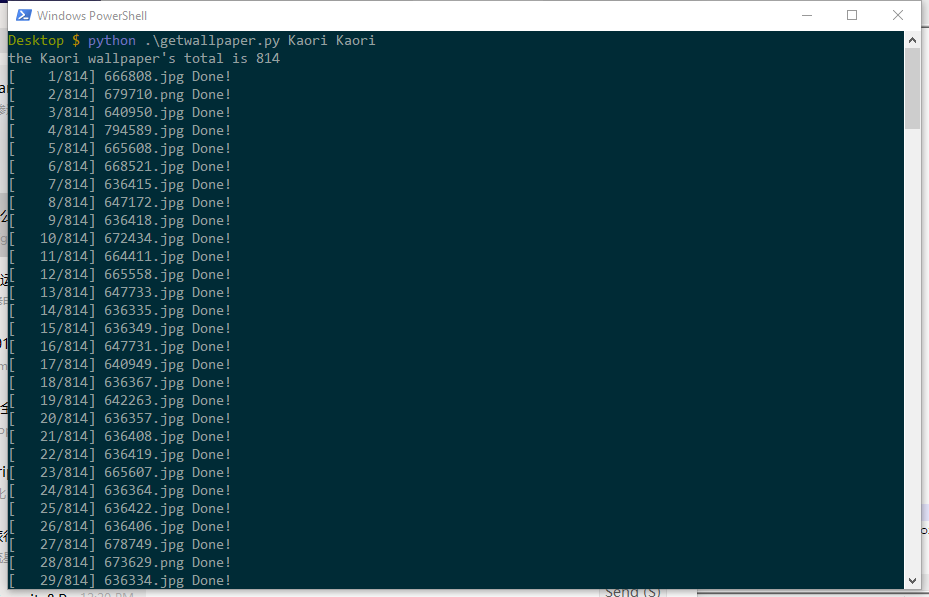
print('[{:5d}/{}] {}.{} Done!'.format(downloaded_num, total, name, pic_type))
def get_download_link(wallpaper_id, wallpaper_type, server, user_id):
global proxies
post_data = {
'wallpaper_id': wallpaper_id,
'type': wallpaper_type,
'server': server,
'user_id': user_id,
}
r = requests.post('https://wall.alphacoders.com/get_download_link.php', data=post_data, proxies=proxies)
download_pic(r.text, wallpaper_id, wallpaper_type)
def getwallpaper(keyword):
global proxies
global total
p_nextpage = re.compile(r"<a id='next_page' href=[\'\"](.+?)[\'\"]>")
p_item = re.compile(r'data-id="(\d+?)" data-type="(\w+?)" data-server="(\w+?)" data-user-id="(\d+?)"')
page_num = 1
while 1:
r_page = requests.get('https://wall.alphacoders.com/search.php?search=%s&lang=Chinese&page=%d' % (keyword.lower(), page_num), proxies=proxies)
nextpage_link = p_nextpage.search(r_page.text)
# if there isn't any search result, it will exit the loop
if nextpage_link == None:
print("Sorry, we have no results for your search!")
break
if page_num == 1:
total = int(re.search(r"<h1 class='center title'>\s+?(\d+)(.+?)\s+?</h1>", r_page.text).group(1))
print("the %s wallpaper's total is %d" % (keyword, total))
for item in p_item.findall(r_page.text):
wallpaper_id = item[0]
wallpaper_type = item[1]
server = item[2]
user_id = item[3]
get_download_link(wallpaper_id, wallpaper_type, server, user_id)
# if there isn't the next page's link, it will exit the loop
if nextpage_link.group(1) == '#':
print("All wallpaper done!")
break
page_num += 1
if __name__ == '__main__':
if len(sys.argv) < 2 or len(sys.argv) > 3:
usage_text = "Usage:\n\tpython getwallpaper.py miku [miki_pic]\nFirst param: the name of script\nSecond param: the wallpaper's keyword which you want to search\nThird param: the dir's name where you want to download in, optional, default in ./pic"
print(usage_text)
elif len(sys.argv) == 3:
download_dir = str(sys.argv[2])
getwallpaper(str(sys.argv[1]))
else:
getwallpaper(str(sys.argv[1]))
多说的
里面我用了下本机的代理,懂的人自然懂,主要是因为直连下载确实有点慢。
另外自己懒,本来就是临时十多分钟写的一个脚本,就懒得加多线程了。
本文作者:Akkuman
本文链接:https://www.cnblogs.com/Akkuman/p/10525857.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?