Paimon Compaction实现
Compact主要涉及以下几个组件
- CompactManager 管理Compact task
- CompactRewriter 用于compact过程中数据的重写实现, 比如compact过程中产生changelog等
- CompactStrategy 决定哪些文件需要被compact
Append Only表
对于Append Only表, compaction过程主要是为了合并小文件, 主要实现逻辑在AppendOnlyCompactManager 在每次Checkpoint或者主动触发compact时 会进行Compaction.
Compaction会分为Full Compaction和Auto Compaction. 一个会处理本批的全部文件,一个是处理部分文件.
CompactRewriter的行为就是把老数据读出来重写
Primary Key表
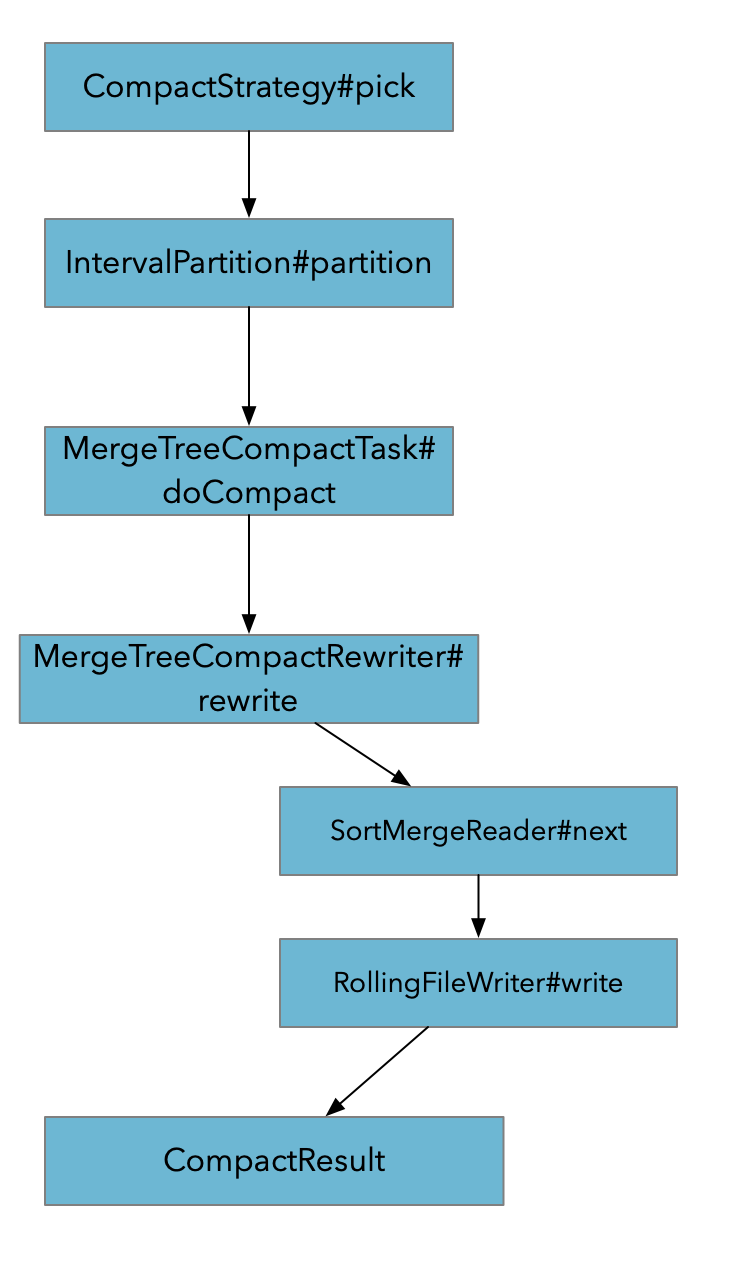
- pick 会根据CompactStrategy挑选需要Compact的文件. 如果是Full compact的话会将所有的文件挑选出来
- 对SortedRun 进行partition.
- 通过SortMegeReader将原文件中数据读取出来合并
- 合并完的结果写入新的文件, 如果过程中有产生Changelog的需求, 那么会在MergeFunction的实现中产生出Changelog, 并写到Changelog文件中去.
- CompactResult包含了 三组文件: before , after, changelog文件
CompactStrategy
Paimon的LSM结构
L0 每一个文件对应一个sorted run, L0往下每一层有一个sorted run. 每一个sorted run 对应一个或多个文件,文件写到一定大小就会rolling out. 所以同一层的sorted run看做是一个全局按照pk排序的文件.
一个文件中的文件会按照primary key排序. 一个Sorted Run中的各个文件之间的key range不会重叠. 但是不同的sorted run之间key range是会重叠的.
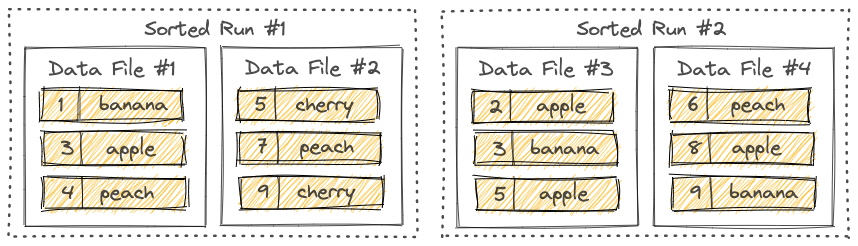
和Rocksdb中sorted run的定义也是一样
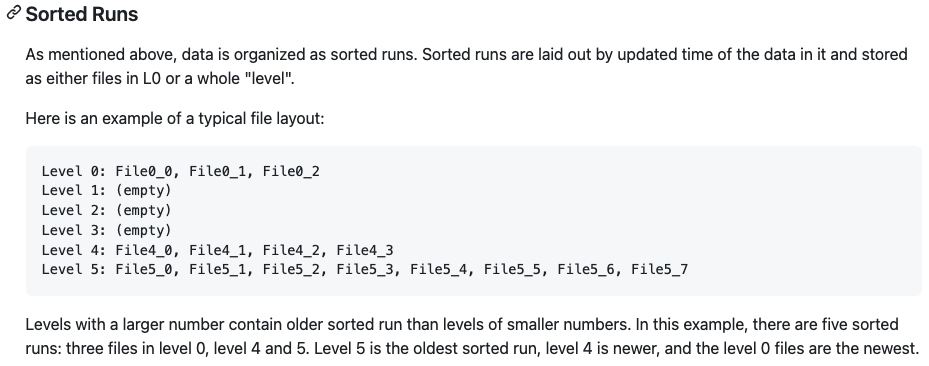
Universal Compaction
CompactionStrategy主要就是决定有哪些文件要参与compaction, compaction的目的是为了减少不同的sorted run之间key的overlap, 提升查询效率, 减少数据重复.
Paimon中默认采用的是类似RocksDB Universal compaction. Compacion的策略分为两大类level compaction 和 size tiered compaction. Universal compaction 是Rocksdb的size tiered compaction的实现. size tiered compaction 比较适合 write intensive 的 workload, 数据湖场景也是高密度写入的场景, 猜测因此把Universal compaction 策略作为默认的compaction策略.
如Rocksdb的wiki所描述, Universal compaction是一个写放大相对较小, 但是读放大和空间放大比较大.
Universal Compaction Style is a compaction style, targeting the use cases requiring lower write amplification, trading off read amplification and space amplification.
这个算法策略的基本思想
The basic idea of the compaction style: with a threshold of number of sorted runs N, we only start compaction when number of sorted runs reaches N. When it happens, we try to pick files to compact so that number of sorted runs is reduced in the most economic way: (1) it starts from the smallest file; (2) one more sorted run is included if its size is no larger than the existing compaction size. The strategy assumes and itself tries to maintain that the sorted run containing more recent data is smaller than ones containing older data.
- 有限个sorted run,当达到这么多sorted run时就触发compact
- 触发compact时 使用最经济的方式减少sorted run的个数
- 从最小的文件开始
- 如果其大小不大于下一个的Sorted run的大小,则再包含一个Sorted run
- 该策略假设并试图保持包含较新数据的Sorted run 的个数小于包含较旧数据的Sorted run
由Space Amplification触发的合并
判断R1-R(n-1) sorted run大小有没有超过 最高层(最老数据)的两倍, 超过了那就触发一次full compaction.
size amplification ratio = (size(R1) + size(R2) + ... size(Rn-1)) / size(Rn)空间放大为什么这么算

由Individual Size Ratio触发的合并
size_ratio_trigger = (100 + options.compaction_options_universal.size_ratio) / 100我们从R1开始,如果size(R2) / size(R1) <= size_ratio_trigger, 那么(R1,R2)被合并到一起。我们以此继续决定R3是不是可以加进来。如果size(R3) / size(R1+r2) <= size_ratio_trigger,R3应该被包含,得到(R1,R2,R3)。然后我们对R4做同样的事情。我们一直用所有已有的大小总和,跟下一个排序结果比较,直到size_ratio_trigger条件不满足。
1 1 1 1 1 => 5
1 5 (no compaction triggered)
1 1 5 (no compaction triggered)
1 1 1 5 (no compaction triggered)
1 1 1 1 5 => 4 5
1 4 5 (no compaction triggered)
1 1 4 5 (no compaction triggered)
1 1 1 4 5 => 3 4 5
1 3 4 5 (no compaction triggered)
1 1 3 4 5 => 2 3 4 5paimon中默认size ratio 是1%, 也就是前N个的size 之和 / 第N+1个的 size <= 101/100, 那么就合并这N+1个sorted run.
这个策略的效果有点类似于是除了最高层之外, 把各个sorted run的大小尽可能靠近对齐
Full Compaction
全部文件参与compaction, 并合并到maxlevel
参考
https://github.com/facebook/rocksdb/wiki/Universal-Compaction
https://blog.csdn.net/qq_40586164/article/details/117914647
本文来自博客园,作者:Aitozi,转载请注明原文链接:https://www.cnblogs.com/Aitozi/p/17506198.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号