Paimon的写入流程
基于Paimon 0.5版本
写入流程的构建org.apache.paimon.flink.sink.FlinkSinkBuilder#build
算子的流向
BucketingStreamPartitioner 分区 -> RowDataStoreWriteOperator 写入 -> CommitterOperator 提交
Primary key表写入
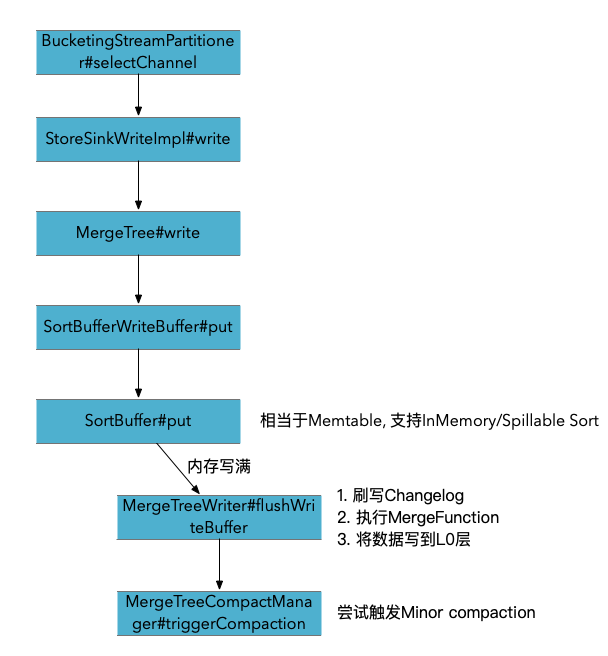
BucketingStreamPartitioner 根据数据的bucket和partition计算数据应该发送的通道
RowDataStoreWriteOperator#processElement
try {
// GlobalFullCompactionSinkWrite
// StoreSinkWriteImpl
record = write.write(new FlinkRowWrapper(element.getValue()));
} catch (Exception e) {
throw new IOException(e);
}
// 同步写到logSystem中. SinkRecord 中包含了partition,bucket,primary key信息
if (logSinkFunction != null) {
// write to log store, need to preserve original pk (which includes partition fields)
SinkRecord logRecord = write.toLogRecord(record);
logSinkFunction.invoke(logRecord, sinkContext);
}
如果配置了logSystem, 其实就相当于数据双写, 导一份到Paimon表, 另一份到消息队列用于其他对时延要求更低的场景. 这也是当前Paimon表没法提供消息队列秒级时延的订阅的折中方案. 实际场景用处应该不大, 支持在表的层面屏蔽了背后的消息队列的表
org.apache.paimon.mergetree.MergeTreeWriter#flushWriteBuffer
内存满后 刷写writeBuffer. 排序后, 遍历buffer. 应用merge函数, 并创建level 0的 file writer, 将数据写入到datafile中. 如果同时配置了Changelog producer是input,那么会将原始的数据写出到Changelog文件中.
// 如果配置了ChangelogProducer.INPUT 那么再刷写WriteBuffer的时候会同时将原始数据写入到changelog里面
final RollingFileWriter<KeyValue, DataFileMeta> changelogWriter =
changelogProducer == ChangelogProducer.INPUT
? writerFactory.createRollingChangelogFileWriter(0)
: null;
final RollingFileWriter<KeyValue, DataFileMeta> dataWriter =
writerFactory.createRollingMergeTreeFileWriter(0);
try {
writeBuffer.forEach(
keyComparator,
mergeFunction,
changelogWriter == null ? null : changelogWriter::write,
dataWriter::write); // 最终使用的Orc/Parquet Writer来将数据写出
} finally {
if (changelogWriter != null) {
changelogWriter.close();
}
dataWriter.close();
}
数据合并
在写入的过程中会调用MergeFunction来进行合并, 以DeduplicateMergeFunction为例, 就是不断保留最新的一条数据. merge的顺序是, 同一条key下, 按照key + sequence number的增序传入. 所以就是保留每个key的最新的数据.
那么当最后一条数据是DELETE消息时, 其实这条数据也会被保留, 并被写入到数据文件中.
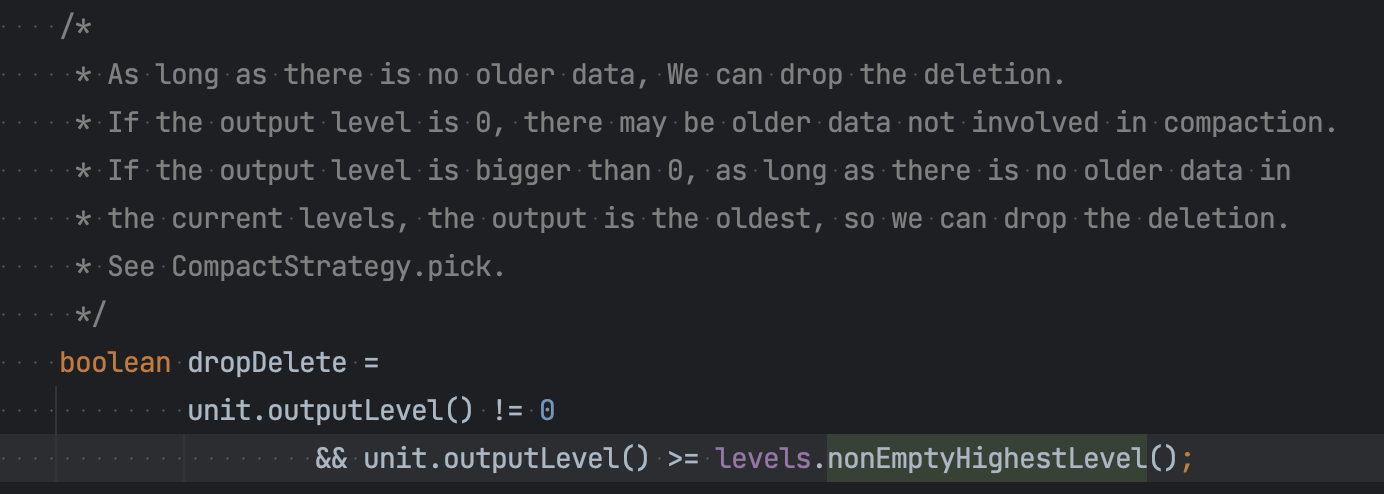
什么时候被真正删除的呢? 首先构建snapshot read的时候, 会通过DropDeleteReader 来读取数据, 所以直接select查询就不会看到了.
而数据在compact阶段, 如果某个数据的compact的target level是最高非空的那层(意味着这个数据后续不会在使用了) 那么就可以安全的drop掉这行数据.
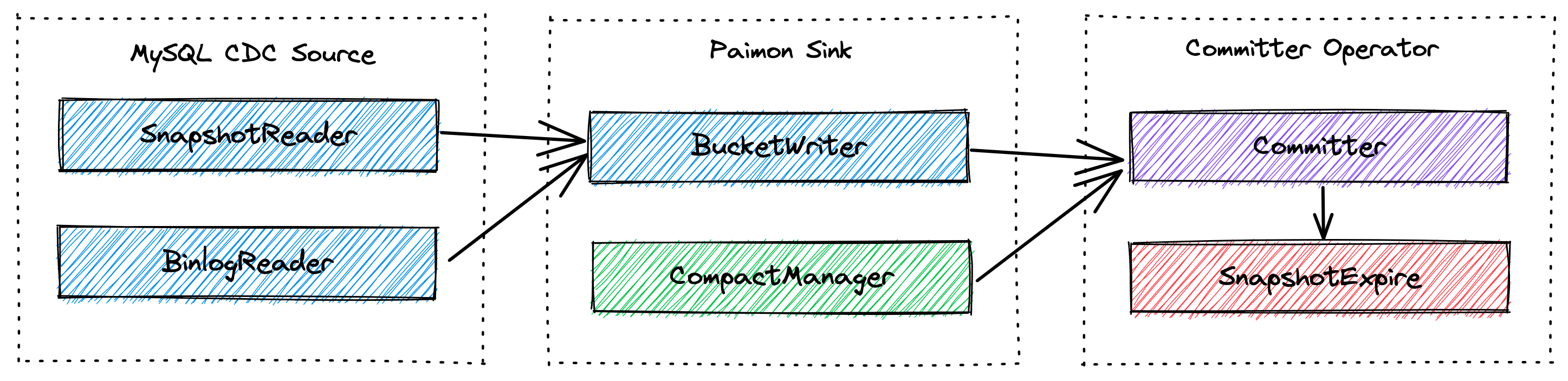
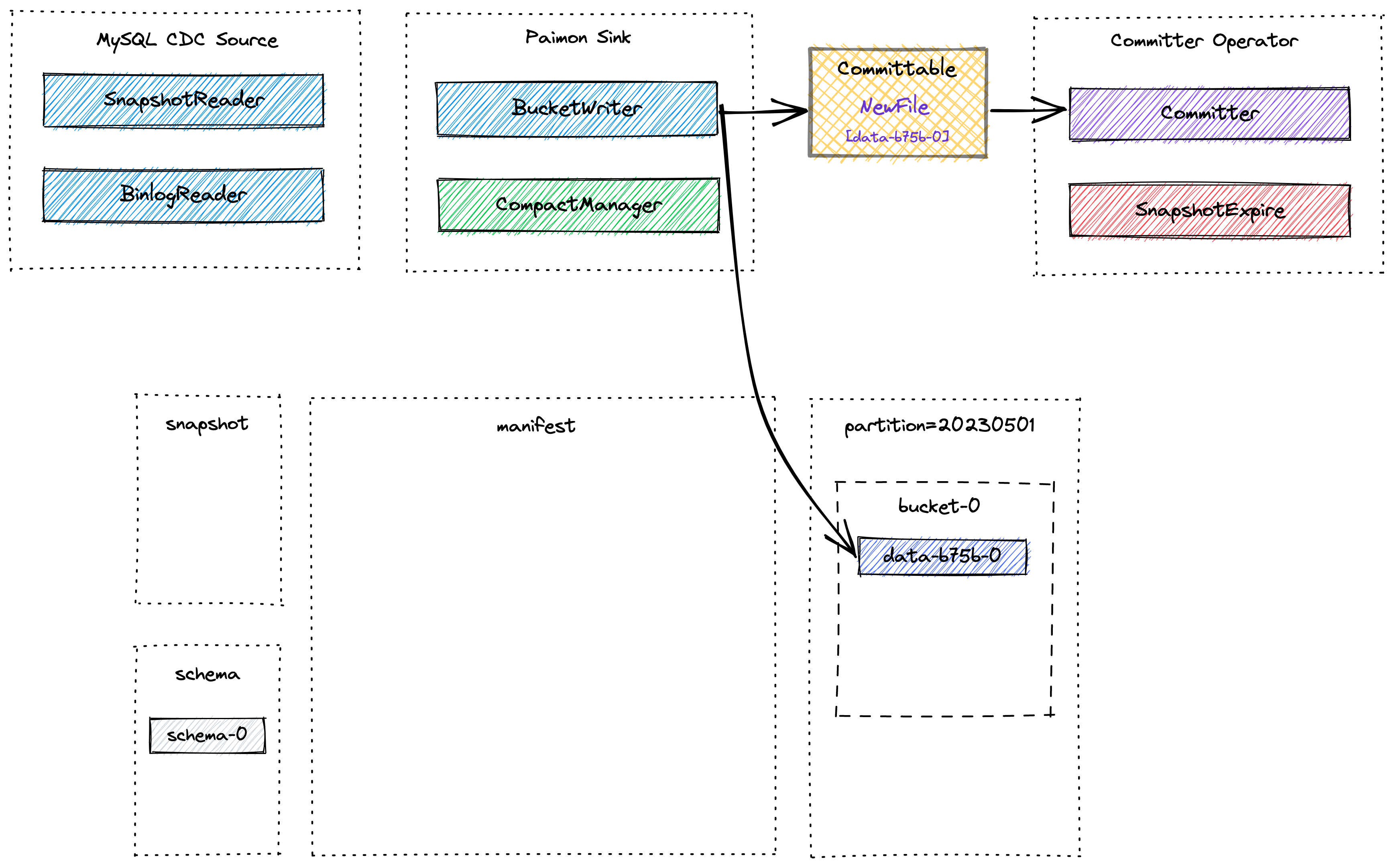
Snapshot 流程
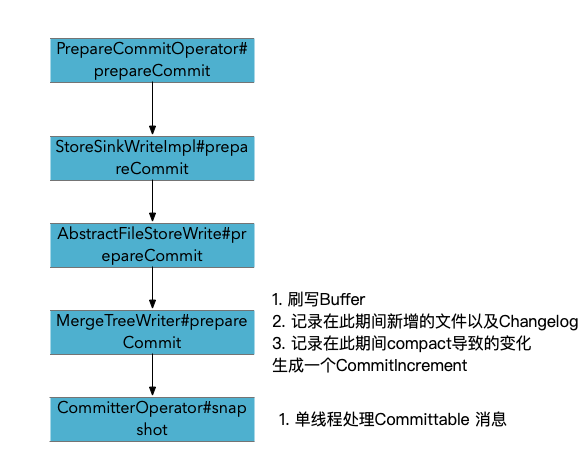
Checkpoint阶段 commit流程


Append-only表写入
Append-only的表是没有Pk的表, 在创建表的时候就已经根据pk和write-mode参数确定了表的类型, 一般来说,没有PK的就是Append-only的表, Append-only的表意味着不处理变更流的数据
org.apache.paimon.operation.AbstractFileStoreWrite#write
org.apache.paimon.operation.AppendOnlyFileStoreWrite#createWriter 创建AppendOnlyWriter
org.apache.paimon.io.RollingFileWriter#write append-only 表直接写文件了, 没有pk表中的write buffer
本文来自博客园,作者:Aitozi,转载请注明原文链接:https://www.cnblogs.com/Aitozi/p/17500201.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号