使用jmh框架进行benchmark测试
性能问题
最近在跑flink社区1.15版本使用json_value函数时,发现其性能很差,通过jstack查看堆栈经常在执行以下堆栈
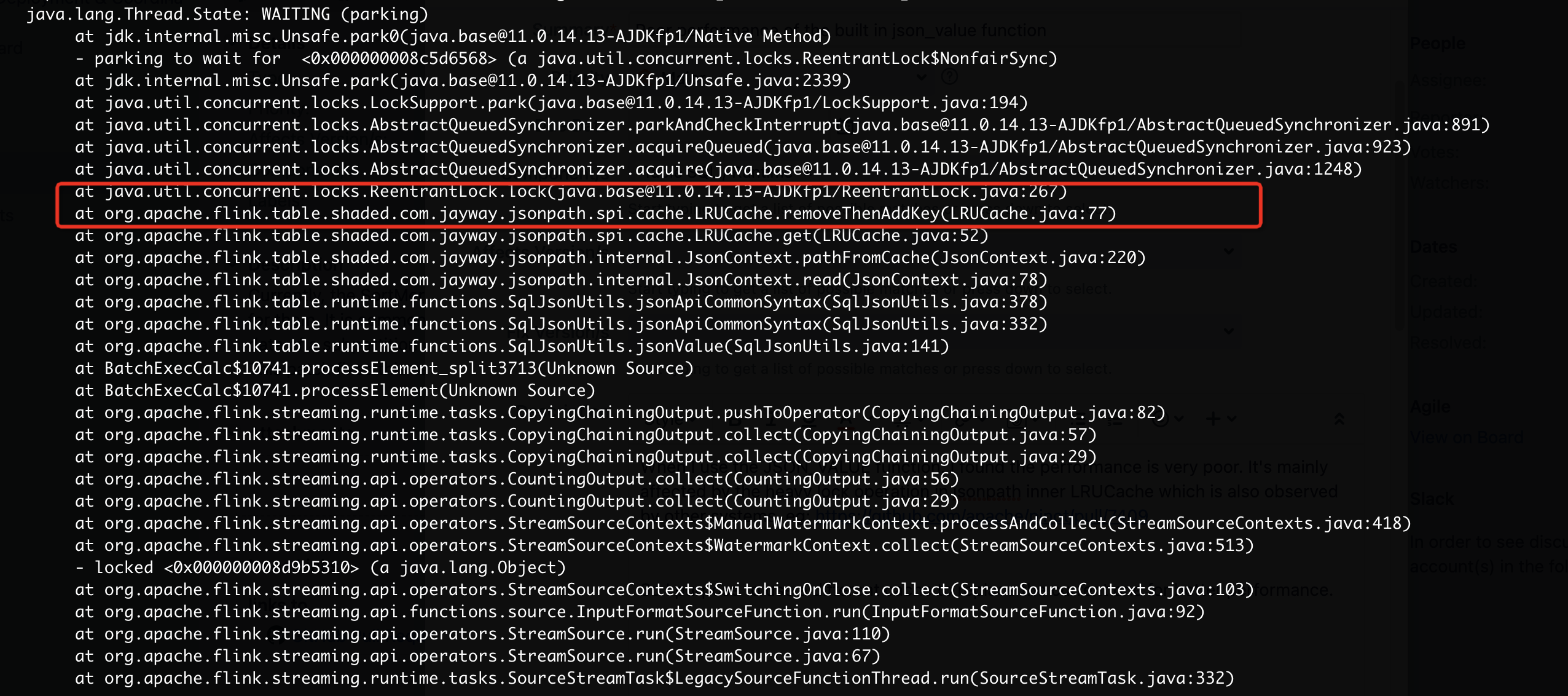
可以看到这里的逻辑是在等锁,查看jsonpath的LRUCache
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.apache.flink.table.shaded.com.jayway.jsonpath.spi.cache;
import java.util.Deque;
import java.util.LinkedList;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.locks.ReentrantLock;
import org.apache.flink.table.shaded.com.jayway.jsonpath.JsonPath;
public class LRUCache implements Cache {
private final ReentrantLock lock = new ReentrantLock();
private final Map<String, JsonPath> map = new ConcurrentHashMap();
private final Deque<String> queue = new LinkedList();
private final int limit;
public LRUCache(int limit) {
this.limit = limit;
}
public void put(String key, JsonPath value) {
JsonPath oldValue = (JsonPath)this.map.put(key, value);
if (oldValue != null) {
this.removeThenAddKey(key);
} else {
this.addKey(key);
}
if (this.map.size() > this.limit) {
this.map.remove(this.removeLast());
}
}
public JsonPath get(String key) {
JsonPath jsonPath = (JsonPath)this.map.get(key);
if (jsonPath != null) {
this.removeThenAddKey(key);
}
return jsonPath;
}
private void addKey(String key) {
this.lock.lock();
try {
this.queue.addFirst(key);
} finally {
this.lock.unlock();
}
}
private String removeLast() {
this.lock.lock();
String var2;
try {
String removedKey = (String)this.queue.removeLast();
var2 = removedKey;
} finally {
this.lock.unlock();
}
return var2;
}
private void removeThenAddKey(String key) {
this.lock.lock();
try {
this.queue.removeFirstOccurrence(key);
this.queue.addFirst(key);
} finally {
this.lock.unlock();
}
}
private void removeFirstOccurrence(String key) {
this.lock.lock();
try {
this.queue.removeFirstOccurrence(key);
} finally {
this.lock.unlock();
}
}
...
}
可以看到get操作时,如果获取到的是有值的,那么会更新相应key的数据从双端队列移到首位,借此来实现LRU的功能,但是这样每次get和put操作都是需要加锁的,因此并发情况下吞吐就会比较低,也会导致cpu使用效率较低。
从jsonpath社区查看相应的问题,也有相关的反馈
https://github.com/json-path/JsonPath/issues/740
https://github.com/apache/pinot/pull/7409
比较方便的是,jsonpath 提供了spi的方式可以自定义的设置Cache的实现类,可以通过以下方式来设置新的cache实现。
static {
CacheProvider.setCache(new JsonPathCache());
}
从pinot的实现中,我们看到他是用了guava的cache来替换了默认的LRUCache实现,那么这样实现性能优化有多少呢,这里我们是用java的性能测试框架jmh来测试下性能提升的情况
性能测试
这里为了方便,直接在flink-benchmark工程里添加了两个benchmark的测试类.
GuavaCache
LRUCache
这里面需要注意,因为cache是进程级别共享的,所以我们需要将设置@State(Benchmark)级别,这样我们构建的cache就是进程级别共享,而不是线程级别共享的。
写的测试是4个线程运行,缓存大小均为400
为了避免在本机运行时受本机的其他程序影响,最好是build jar之后放到服务器上跑
java -jar target/benchmarks.jar -rf csv org.apache.flink.benchmark.GuavaCacheBenchmark
得到一个测试结果
Benchmark Mode Cnt Score Error Units
GuavaCacheBenchmark.get thrpt 30 4480.563 ± 203.311 ops/ms
GuavaCacheBenchmark.put thrpt 30 1774.769 ± 119.198 ops/ms
LRUCacheBenchmark.get thrpt 30 441.239 ± 2.812 ops/ms
LRUCacheBenchmark.put thrpt 30 350.549 ± 12.285 ops/ms
可以看到使用guava的cache后,get性能提升8倍左右,put性能提升5倍左右。
这块性能提升的主要来源是cache的实现机制上,和caffeine 的作者在github上也简单了解了下相关的推荐实现
后面会写一篇文章来专门分析下caffeine cache的优化实现。
参考
https://github.com/ben-manes/caffeine/wiki/Benchmarks#read-100-1 caffeine benchmark
https://github.com/ben-manes/caffeine/blob/master/caffeine/src/jmh/java/com/github/benmanes/caffeine/cache/GetPutBenchmark.java caffeine benchmark
https://www.jianshu.com/p/ad34c4c8a2a3 jmh 框架常见参数
http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/ jmh 常见用例
本文来自博客园,作者:Aitozi,转载请注明原文链接:https://www.cnblogs.com/Aitozi/p/16560168.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号