Python3爬虫_爬取Find47网站风景图片
Find47网站是展示日本47个县的风景图片,这个网站不用通过逆向,只要访问网站的地址就可以获取到对应的href 链接.
通过获取对应url在请求获得图片压缩包数据,保存至本地.
准备工作:
- 在pycharm IDE里安装好所需的库
- pip install requests
- pip install lxml
执行一下代码:
import os import time import random import requests from lxml import etree class GetPic(object): def __init__(self,url,pic_size): self.url = url self.pic_size = pic_size self.headers = {} # User-Agent 池 header_list = [ "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50" ,"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50" ,"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;" ,"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1" ,"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56" ] self.headers["User-Agent"] = random.sample(header_list,1)[0] def get_pic_url(self): # 获取网站的图片url count = 0 # 创建一个空字典存储图片的名称和 url短连接 self.pic_name_dict = {} # 使用requests请求网页链接 在利用etree对象分别获取 获取图片名和url page_text = requests.get(url=self.url,headers=self.headers) tree = etree.HTML(page_text.text) pic_urls = tree.xpath("//ul[@id='photos']//a/@href") print("以获取图片url数量:",len(pic_urls)) # //*[@id="photos"]/li[1]/a/div/div[1] pic_name = tree.xpath("//ul[@id='photos']//div[@class='detail']/div[2]") for i in pic_urls: self.pic_name_dict[pic_name[count].text] = i.split("/")[-1] count += 1 return self.pic_name_dict def save_pic(self,pic_dict): # 保存图片至本地 base_url = "https://search.find47.jp/" # xl尺寸的图片url : https://search.find47.jp/ja/images/NzJVV/download/xl filepath = f"{os.path.dirname(__file__)}\\PICFILE" # 判断文件夹是否存在 不存在则创建一个 if not os.path.isdir(filepath): os.mkdir(filepath) # 遍历字典 拼接下载链接 通过requests发送请求获取数据并保存 for k,v in pic_dict.items(): with open(f'{filepath}\\{k}.zip','wb') as fp: data = requests.get(f"{base_url}/ja/images/{v}/download/{self.pic_size}").content fp.write(data) print(f"{k}.zip 图片压缩包下载完毕...") # 等待随机时间在访问 time.sleep(random.randint(1,3)) def run(self): # 执行函数 try: pic_name_dict = self.get_pic_url() self.save_pic(pic_name_dict) except Exception as e: print("错误信息",e) if __name__ == '__main__': size_dict= {"S":"1280x960 px" ,"M":"1920x1440 px" ,"L":"3508x2631 px" ,"XL":"4608x3456 px" } url = input("请输入网站链接:").strip() for k,v in size_dict.items(): print(f"尺寸[ {k} ] :{v} 分辨率") size = input("请输入下载图片的尺寸字母:").strip() if size.upper() in size_dict and "http" in url: print("准备获取下载的图片URL...") # 测试链接 https://search.find47.jp/ja/images?area=hokkaido get_pic = GetPic(url,size.lower()) get_pic.run() else: print("字母或url错误,请重新输入")
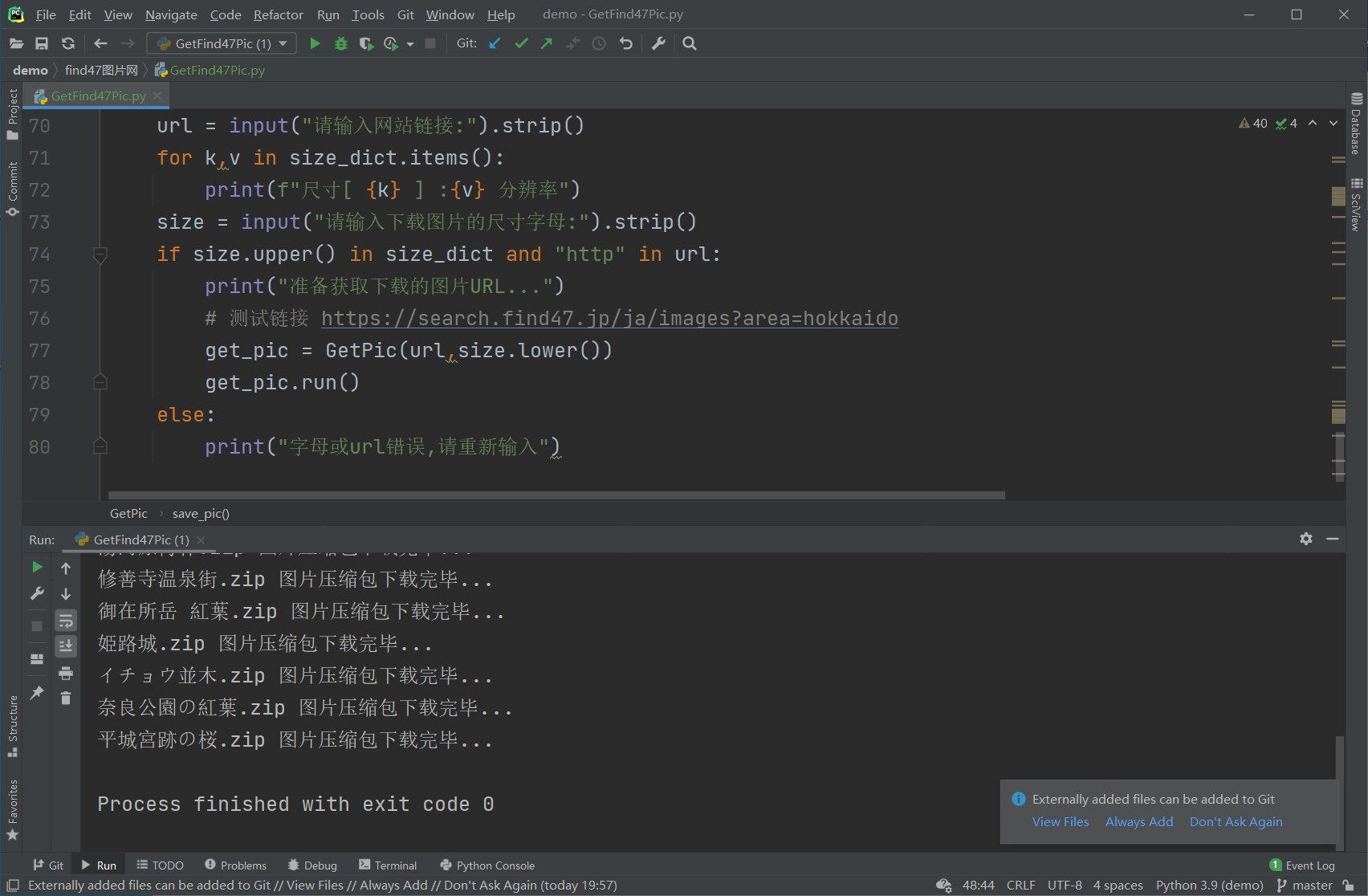
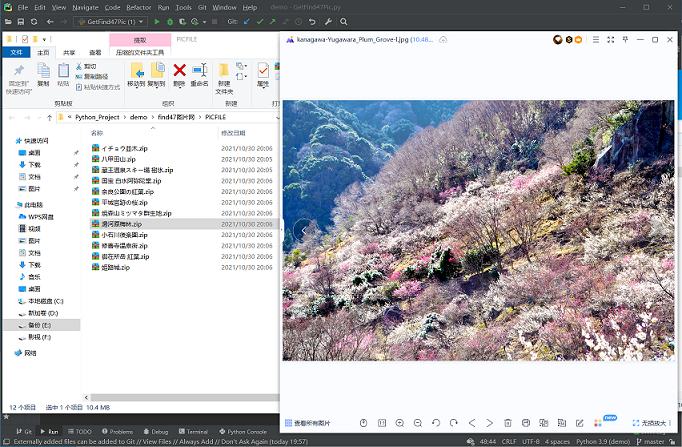
PS:需要注意的代码可以自行选择下载图片的分辨率,但有些图片是刚好没有对应的尺寸从而保存后的zip压缩包会是空文件.
学习更多Python爬虫技术请关注:Aitlo学习站
本文来自博客园,作者:Aitlo,转载请注明原文链接:https://www.cnblogs.com/Aitlo/p/15487450.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号