【算法】笔试题记录
9.25
哇今天做了道特别有意思的题。
编程就给了两道,第一题特别简单,a、b两个数,每次选其中一个数*2,这样操作两次,问最后得到的两数之和的期望值是多少。
简单吧?因为每次选择都有两种可能性,操作两次后就会有四种可能的结果(22)。其中有两个结果是重复的(2a, 2b),剩下两个分别是(a, 4b)和(4a, b)。把这四个结果求和除以4就是期望值。或者还有种角度,分别计算两次操作后 a 的期望和 b 的期望,把两者相加就是两数之和的期望(期望的线性性)。
第二题上来就看懵了。定义2*2的相邻元素(上下、左右)互不相同的01矩阵为好矩阵(比如[1 0 0 1]),而一个矩阵中包含好子矩阵的数量为它的权值。输入n、m,问所有 n * m 的矩阵权值的总和是多少?
啥玩意?我真的想破脑袋。后来笔试结束了才猛然醒悟,这两题是有联系的!第一题看似简单,其实正暗示了第二道题的解法:期望!
问题描述
•矩阵定义:我们考虑所有可能的 n * m 的 0-1 矩阵。
•权值定义:每个矩阵的权值是其中包含的好子矩阵的数量。
•好子矩阵定义:一个 2 * 2 的子矩阵,满足相邻元素(上下、左右)互不相同。
变量定义
•总矩阵数 N :所有可能的 n * m 矩阵的数量。N = 2n*m(因为每个元素有 2 种可能,共有 n * m 个元素)
•子矩阵位置数 K :每个矩阵中可能的 2 * 2 子矩阵的数量。K = (n - 1) * (m - 1)(因为在 n * m 的矩阵中,横向有 n - 1 个位置,纵向有 m - 1 个位置)
•好子矩阵的概率 P :随机生成的 2 * 2 子矩阵是好子矩阵的概率。P = 2/16 = 1/8(因为共有 16 种可能的 2 * 2 0-1 矩阵,其中只有 2 种是好子矩阵)
推导过程
目标:计算所有可能的 n * m 矩阵的权值总和,即所有矩阵中好子矩阵的总数量。
思路:从整体角度考虑,我们可以将问题转化为计算所有位置上好子矩阵出现的总次数。
1. 计算单个位置上的好子矩阵数量
•在单个位置上,可能的子矩阵数量等于总矩阵数 N ,因为每个矩阵在该位置上都有一个对应的子矩阵。
•在该位置上,好子矩阵的总数量为: N * P(每个矩阵在该位置上有一个子矩阵,成为好子矩阵的概率为 P )
2. 计算所有位置上的好子矩阵数量
•总的位置数为 K ,每个位置独立且等价。
•所有位置上的好子矩阵总数为:总权值 = K * N * P
逻辑解释
有人可能疑惑了,每个位置怎么会独立呢?相邻子矩阵不是有共享的元素吗?
这里就要引入关键概念:期望的线性性。
期望的线性性是指,对于任意随机变量的和,其期望等于这些随机变量的期望之和,即使这些随机变量之间有相关性。这一点非常重要。
在我们的情境中:
•随机变量定义:对于矩阵中的每个可能的 2 * 2 子矩阵位置,我们定义一个指示变量 Xi ,如果该位置上的子矩阵是好子矩阵,其值为 1 ,否则为 0。
•总权值:所有矩阵的总权值等于所有 Xi 的和。
尽管这些 Xi 之间存在相关性(因为子矩阵共享元素),但在计算期望时,这种相关性并不影响总期望值的计算,期望的线性性仍然成立。
对于每个位置 i :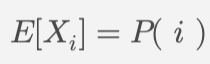
总期望值: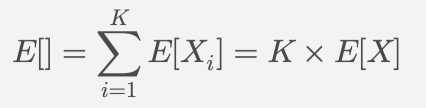
其中 E[X] 是任意一个位置上子矩阵为好子矩阵的概率 P 。
10.1
怕国庆过完彻底忘掉了,把前几天的笔试题复盘整理下。以下有些是GPT生成的,未必准确,仅供参考。
简答题
1-大模型如GPT具备哪些能力?请简单介绍。比如:内容生成(content generation)。
- 内容生成(Content Generation):GPT能够生成高质量的文本内容,应用于写作、对话生成、问答等场景。
- 语言理解(Language Understanding):模型能够理解和处理自然语言,进行语义分析和上下文理解。
- 文本摘要(Text Summarization):能够从长文本中提取关键信息,生成简洁的摘要。
- 翻译(Translation):支持多种语言之间的翻译,提供流畅的语言转换。
- 情感分析(Sentiment Analysis):能够识别文本中的情感倾向,如积极、消极或中性情感。
(这是gpt自己生成的答案,其实在我看来都属于内容生成。)
2-为什么训练GPT用GPU而不是CPU?14B参数的大模型训练/推理要用到多少显存?
选择GPU的原因主要有:
- 并行处理能力:GPU具有成千上万的核心,可以同时处理大量数据,而CPU核心数量有限,适合顺序处理任务。
- 计算效率:GPU在处理复杂数学计算时效率更高,非常适合矩阵运算和向量化操作,这是深度学习中的主要计算形式。此外,内存带宽也显著高于CPU,这进一步加速了训练过程。
模型有14B(140亿)个参数,通常每个参数占用4字节(FP32格式),那么训练时模型所需的显存可以粗略估算为:14B * 4 bytes = 56GB
同时,训练时还需要存储梯度、优化器状态等额外信息,通常倍数是2到3倍,即最终显存需求约为 112GB 到 168GB。
在推理时,显存需求较低,因为推理只涉及前向传播,不需要存储梯度,估算显存需求约为单倍参数大小,即至少需要约56GB显存。
3-文本、图片、视频有哪些数据标注方法?
文本数据:
1.分类标注(Classification Labeling):为文本分配预定义的类别标签,例如情感分类(积极、消极、中立)。
2.实体识别(Named Entity Recognition, NER):标注文本中的关键实体,如人名、地名、组织名等。
3.关系标注(Relation Extraction):标注文本中的实体关系,例如主语、谓语、宾语之间的关系。
4.句子对标注(Sentence Pair Labeling):为成对的句子标注关系,如推理任务中的前提和假设之间的关系(Entailment, Contradiction, Neutral)。
5.问答标注(Question-Answer Labeling):在给定的上下文中标注问题的答案,常用于构建问答系统的数据集。
图片数据:
1.分类标注(Image Classification):为整张图片打标签,例如狗、猫、汽车等类别。
2.目标检测(Object Detection):标注图片中每个目标的位置和类别,通常通过边界框的形式标注。
3.语义分割(Semantic Segmentation):将图片中的每个像素进行分类,标注出不同物体的区域。
4.实例分割(Instance Segmentation):类似语义分割,但需区分同一类别的不同个体。
5.关键点检测(Keypoint Detection):标注图片中目标的关键点,如人体姿态估计中的关节点位置。
视频数据:
1.视频分类(Video Classification):为整个视频片段打标签,例如运动、舞蹈等类别。
2.动作识别(Action Recognition):标注视频中发生的具体动作,例如“挥手”、“跑步”等。
3.时序分割(Temporal Segmentation):对视频中的时间段进行标注,识别不同场景或动作的开始和结束时间。
4.目标追踪(Object Tracking):对视频中的特定对象进行连续追踪,标注其在每一帧中的位置。
4-介绍常见的数据清洗方法,并简单说明
- 缺失值处理:
- 删除:删除缺失值较多的记录或特征。
- 插值法:用均值、中位数或众数填补缺失值。
- 异常值检测与处理:
- 删除异常值:对于明确的异常数据点,可以将其删除。
- 平滑异常值:对异常值进行平滑处理,或通过变换(如log变换)降低异常值的影响。
- 重复数据删除:
- 检查并删除重复记录,以确保数据唯一性。
- 数据规范化与标准化:
- 将不同格式的数据统一,例如日期格式、文本大小写等。
- 归一化:将数据缩放到[0, 1]区间。
- 标准化:将数据调整为零均值、单位方差。
- 特征编码:
- One-Hot Encoding:将类别值转化为二进制向量表示。
- Label Encoding:为每个类别赋予一个整数值。
5-什么是残差连接?解决了什么问题?
残差连接又称跳跃连接,其基本形式是将输入x通过某一层的变换得到的输出f(x)与输入x直接相加,即: y = f(x) + x
其主要解决的问题包括:
- 梯度消失问题:在深层网络中,梯度在反向传播过程中可能逐层减小,梯度可能会消失,从而导致训练困难。残差连接通过提供直接路径,使梯度能够有效传播,从而加速训练过程。
- 学习简单函数的能力:随着网络深度的增加,深层网络的性能可能比浅层网络更差。残差连接使得网络可以更容易地学习恒等映射,从而避免了中间层对信息的过度损失,提高了网络的表达能力和收敛速度,使得深层网络的训练变得更加容易。
6-简述大模型训练的全过程
大模型的训练主要分为两个阶段:预训练和微调。
1. 预训练
•目标:通过无监督学习,模型基于大量文本数据进行自回归预测,学会在给定上下文时预测下一个词。
•架构:基于Transformer,使用自注意力机制捕捉语言中的远距离依赖关系。
•过程:
•数据准备:使用大规模语料(如网页、书籍等)。
•输入处理:将文本分词并嵌入为向量,输入到Transformer层。
•损失计算:使用交叉熵损失函数来衡量预测与实际词的差距。
•反向传播与优化:通过Adam优化器调整模型参数,学习语言模式。
2. 微调
•目标:在特定任务数据集上进行有监督学习,使模型适应特定任务(如问答、情感分析)。
•过程:
•有监督学习:使用带标注的高质量数据,调整模型参数。
•迁移学习:预训练学到的通用语言特征被迁移到任务中,加快适应速度。
单选题
1-以下哪种方法适合不知道标签的数据分类?
题目其实忘了,就直接来分析下选项吧,记下来了“隐马尔可夫”和“关联分析”。我大概是选了“聚类”。
隐马尔可夫模型(HMM):隐马尔可夫模型是一种用于时间序列数据的统计模型,适用于有隐含状态的序列预测。它通常用于语音识别、自然语言处理等领域,但不适合处理没有标签的数据。
关联分析:关联分析主要用于发现变量之间的关系,常见于市场篮子分析(如购物篮分析),用于找出哪些产品经常一起被购买。虽然它可以处理无标签数据,但主要关注的是变量之间的关系,而不是将数据分组。
2-数据量超出可用RAM(内存),有哪些策略可以有效训练?
SGD(随机梯度下降):每次只使用一小部分样本(mini-batch)来更新模型参数。这种方法不仅减少了内存消耗,还能加快收敛速度,因为它引入了随机性,有助于跳出局部最优解。
Full Batch SGD(全批量梯度下降):需要将整个数据集加载到内存中进行计算,这在数据集较大时会导致内存不足的问题。
应该选SGD。
3-try-except-else-finally知识点
又是一个题目忘了的。大概说下知识点,首先是基本结构:
- try: 包含可能会引发异常的代码块。
- except: 用于捕获并处理异常。
- else: 当try块中的代码没有引发异常时执行。
- finally: 无论是否发生异常,最终都会执行的代码块。
然后是执行顺序:
- 首先执行 try 块中的代码。如果 try 块中的代码没有发生任何异常,则顺利执行到 else 块(如果有)。
- 如果在 try 块中发生了异常:
-
- try 块后面的代码不会继续执行,直接跳转到相应的 except 块。
- except 块会捕获这个异常并执行其代码。
- 如果有多个 except 块,Python 会按照从上到下的顺序检查每个 except,直到找到与异常匹配的类型(从具体的异常类型到更一般的异常类型)。
- 如果没有匹配的 except 块,finally 块执行完毕后,程序会向外层抛出该异常,直到被外层的 try-except 捕获,或者如果没有外层的异常处理机制,程序将终止,并打印异常的回溯(traceback)。
- 如果没有异常发生:在 try 块执行完毕之后,程序会进入 else 块(如果存在)。
- 无论是否发生异常,finally 块中的代码始终会执行。这是确保资源清理、状态恢复等重要操作的机制。
举个例子:
try:
# 可能会抛出异常的代码
result = 10 / 0 # 引发 ZeroDivisionError
except ValueError:
# 捕获 ValueError 错误
print("输入值错误")
finally:
# 无论是否发生异常,都会执行这里
print("执行 finally 块")执行结果:
执行 finally 块
Traceback (most recent call last):
File "example.py", line 2, in <module>
result = 10 / 0 # 引发 ZeroDivisionError
ZeroDivisionError: division by zero再举个例子:
try:
try:
result = 10 / 0 # 引发 ZeroDivisionError
except ValueError:
# 捕获 ValueError 错误
print("输入值错误")
finally:
# 无论是否发生异常,都会执行这里
print("执行 finally 块")
except ZeroDivisionError:
# 捕获外层的 ZeroDivisionError
print("捕获 ZeroDivisionError")执行结果:
执行 finally 块
捕获 ZeroDivisionError4-用ReLU激活函数代替tanh可能会出现什么问题?
- 计算简单:ReLU只需计算一次最大值运算,非常高效。
- 梯度不消失:当输入为正值时,ReLU的导数恒为1,避免了梯度消失问题,因此在深度神经网络中广泛应用。
- 神经元死亡问题:由于ReLU对负值的输入输出为零,长期训练过程中,有些神经元可能会因为总是接收到负输入而变得“永久失活”,导致这些神经元在训练中再也无法对模型输出产生影响,这被称为神经元死亡。
现在分析选项:
1. 神经元死亡
这是ReLU激活函数最常见的问题,原因是当ReLU的输入为负时,输出为零,且该零值区域的梯度也为零。如果一个神经元在训练过程中长期接收到负值输入,其输出始终为零,这样的神经元就无法再更新权重,最终导致神经元死亡。因此,ReLU激活函数与神经元死亡问题相关。
2. 梯度消失
梯度消失问题主要与tanh或sigmoid这样的S形激活函数有关。由于这些函数的输出在极端值时趋于平稳,导数会变得非常小,这会导致在深度网络中,靠近输入层的权重更新非常缓慢,甚至几乎不更新。ReLU激活函数则有效地避免了梯度消失问题,因为它在正区间的导数恒为1,不会出现梯度过小的情况。
选1,神经元死亡。
5-无法确定相关性数据用什么方法?
这题也是不记得了,写下来几个选项,来分析下。
- 最大似然比(Likelihood Ratio):
- 最大似然比是一种用于比较两个模型的统计方法,通常用于假设检验。它通过计算在给定数据下,两个模型的似然函数之比来评估哪个模型更适合数据。
- 适用于确定模型之间的相对优劣,但并不直接用于评估变量之间的相关性。
- 最大熵(Maximum Entropy):
- 最大熵原理用于构建概率模型,特别是在缺乏足够信息时,通过选择熵最大的分布来进行推断。
- 它强调在已知条件下,不做额外假设,选择最均匀的概率分布,因此在某种程度上可以用来处理不确定性,但主要用于概率分布建模,而非直接评估相关性。
- 卡方检验(Chi-Squared Test):
- 卡方检验是一种用于检验两个分类变量之间是否存在显著相关性的统计方法。它通过比较观察频数和期望频数来判断变量之间的独立性。
- 适合用来确定相关性,尤其是在分类数据中。
看起来卡方检验最相关。
6-以下哪一项是特征学习(representation learning)?
特征学习旨在从原始数据中提取出有用的信息表示,允许模型自主学习数据中的重要特征。
- 神经网络:
- 神经网络,特别是深度学习模型(如卷积神经网络CNN和循环神经网络RNN),非常擅长进行特征学习。它们通过多层结构自动提取数据的高级特征,例如在图像处理中,神经网络可以自动识别边缘、形状和更复杂的模式,从而实现有效的特征表示。
- 随机森林:
- 随机森林是一种集成学习方法,主要通过构建多个决策树来进行分类或回归。虽然它可以处理高维数据,但通常依赖于手动选择的特征,而不是自动提取特征。因此,它不属于特征学习的范畴。
- k近邻(k-NN):
- k近邻是一种基于实例的方法,通过计算样本之间的距离来进行分类或回归。它没有内置的机制来进行特征学习,而是直接使用原始数据进行决策,因此也不符合特征学习的定义。
选神经网络。
7-以下哪一项不属于特征选择?
- 过滤法(Filter):
- 通过评估特征与目标变量之间的统计关系(如相关性、方差等)来进行特征选择。它通常在模型训练之前进行,计算简单且速度快。
- 包装法(Wrapper):
- 将特征选择过程嵌入到模型训练中,评估不同特征子集在给定模型上的表现,并选择性能最好的特征组合。该方法通常需要多次训练模型,因此计算开销较大,但可以更准确地选择最优特征子集。
- 嵌入法(Embedded):
- 在模型训练过程中自动进行特征选择,利用某些算法(如L1正则化)来评估特征的重要性。这种方法结合了过滤法和包装法的优点。
- 抽样(Sampling):
- 抽样通常指的是从数据集中随机选择样本,以减少数据量或解决数据不平衡问题(如随机抽样、分层抽样、欠采样、过采样等),不是特征选择的一种方法。它用于减少数据量或创建样本集,以便进行后续分析或建模。
选抽样。
8-以下哪一项不适合文本分类中的特征选择?
- 信息增益(Information Gain):
-
信息增益是一种常用于文本分类中的特征选择方法。它基于熵的概念,用来衡量某个特征(通常是单词)对目标分类(类别标签)的区分能力。信息增益计算的是在已知特征的情况下,分类的不确定性减少的程度。
-
在文本分类任务中,特征往往是词袋模型中的单词或短语,而目标变量是文档的类别(如垃圾邮件与非垃圾邮件)。信息增益通过衡量每个单词对分类结果的影响大小,帮助选择最具区分能力的特征,是常用的特征选择方法。
-
- PCA(主成分分析):
- PCA是一种降维技术,主要用于减少数据的维度,提取主要特征。PCA通过将原始特征转化为一组不相关的主成分,通过保留数据中最大方差的方向来寻找最重要的主成分。虽然它可以帮助处理高维数据,但它并不专门用于特征选择,而是用于特征提取。
- 虽然PCA在高维数据的降维上有不错的效果,但它主要用于处理连续型数据,而文本分类任务中的特征通常是离散的(如词频、TF-IDF值)。此外,PCA生成的主成分是新的特征组合,难以直接解释为原始特征,因而它并不是文本分类中特征选择的常见方法。
- 互信息(Mutual Information):
-
互信息是一种度量特征和目标变量之间的相互依赖关系的统计量。它衡量的是一个特征对目标变量(分类结果)提供的信息量,互信息越大,说明该特征越能提供关于目标分类的有用信息。
- 在文本分类任务中,互信息可以用于衡量每个单词(特征)和文档类别(目标变量)之间的信息依赖性,从而选择对分类最有用的单词。因此,互信息在文本分类任务中是一种常见且有效的特征选择方法。
-
- 卡方检验值(Chi-Squared Test):
-
卡方检验是一种用于检测两个分类变量(如特征和目标变量)之间关联性的统计方法。在文本分类中,卡方检验常用来评估每个单词(特征)与目标分类之间的相关性,通过计算每个单词在不同类别中的分布差异来确定哪些单词对分类最有用。
- 卡方检验特别适用于处理离散型特征,如文本分类中的词袋模型或TF-IDF值,因此它是文本分类中特征选择的常见方法之一。卡方检验能够有效筛选出与分类结果强相关的单词特征。
-
选PCA。
9-哪项是Java的特性?
记下来的问题和选项没写清楚,我大概分析下。
1. 单继承(Single Inheritance)
单继承是Java的一个特性。Java的类层次结构中,一个类只能继承一个父类,即Java不允许一个类同时继承多个类。这就是所谓的单继承。通过单继承,Java避免了多继承中可能出现的复杂性问题(如菱形继承问题)。因此,在Java中,一个类只能通过关键字 extends 继承一个父类的属性和方法。
class A {
// 父类的属性和方法
}
class B extends A {
// 子类继承了父类A
}2. 多继承(Multiple Inheritance)
多继承指的是一个类可以继承多个父类。C++等语言支持多继承,即一个类可以从多个类中继承属性和方法。然而,Java不支持多继承,因为这会引发复杂的依赖关系和冲突问题,特别是当多个父类中存在相同方法时(菱形继承问题)。
不过,Java提供了一个替代方案,允许类通过实现多个接口来达到类似多继承的效果。接口中定义的是方法签名,没有具体实现,而一个类可以实现多个接口,并在该类中实现这些接口的方法。这种方式避免了多继承中的冲突问题。
interface A {
void methodA();
}
interface B {
void methodB();
}
class C implements A, B {
// C 实现了 A 和 B 接口中的方法
public void methodA() {
// 实现方法
}
public void methodB() {
// 实现方法
}
}3. 双向继承(Bi-directional Inheritance)
双向继承并不是Java语言中的概念,甚至在大多数面向对象编程语言中都不存在这种继承模式。在Java中,继承的方向是单向的,即子类继承父类,而不是父类继承子类。子类可以访问父类的属性和方法(除非它们被声明为private),但反过来不行,父类不能访问子类的属性和方法。
4. 不可继承(Non-inheritable)
在Java中,虽然大多数类是可以被继承的,但通过特定的修饰符,可以阻止类被继承。例如,Java提供了 final 关键字,用于防止某个类被继承。将类声明为 final,意味着该类不能作为其他类的父类,也就是说它是不可继承的。
同样,final 也可以用于方法,表示该方法不能在子类中被重写。这是Java的设计之一,目的是为那些不希望被修改的类或方法提供保护。
final class A {
// 这个类不能被继承
}
class B extends A {
// 这行代码会报错,因为 A 是 final 类,不能被继承
}| 特性 | extends |
implements |
|---|---|---|
| 继承关系 | 用于继承单个父类或接口 | 用于实现多个接口 |
| 代码重用 | 允许子类重用父类的方法和属性 | 不提供代码重用,只定义行为 |
| 方法实现 | 子类可以重写父类的方法 | 必须实现所有接口中的方法 |
| 多重继承 | 不支持(单继承) | 支持(可以实现多个接口) |
多选题
1-以下哪项关于GPT是正确的?
- pre-train,Mask LM:
- “Mask LM”是BERT的特性,而不是GPT的,这一选项不正确。
-
GPT 使用的是自回归语言模型(Autoregressive Language Model),即模型在生成下一个单词时,仅依赖先前的单词,不使用未来的信息。GPT 的预训练任务是通过最大化下一个单词的预测概率来进行的,因此它是一个从左到右的单向模型。
-
BERT 则不同,它采用的是双向掩码语言模型(Masked Language Model, MLM)。在BERT的预训练过程中,输入序列中的一部分单词会被随机掩码,模型需要预测被掩码的单词,因此它能够同时利用上下文信息,是一个双向模型。
- 基于解码:
- 正确。GPT是基于Transformer的解码器架构,采用自回归的方法生成文本。
- GPT 的架构实际上是基于Transformer解码器(Decoder)部分的。Transformer 模型最初由 Vaswani 等人提出,分为两个主要部分:编码器(Encoder)和解码器(Decoder)。其中,编码器通常用于处理输入数据(如句子的上下文理解),而解码器用于生成输出(如翻译或文本生成)。
-
GPT 仅使用 Transformer 架构中的解码器部分,它不具备 BERT 这样的双向编码能力,而是一个自回归生成模型,只考虑当前词和之前的词,而不考虑未来的词。
- 最后一个时刻的输出作为分类依据:
- 部分正确。在某些任务中,GPT可以使用最后一个时刻的输出进行分类,但这并不是它的唯一用途。通常情况下,它会生成整个序列。
-
BERT 也可以使用类似的策略,尤其是在文本分类任务中,常常使用特殊标记 [CLS] 对应的输出作为分类依据。
- 比BERT更适合NLP生成:
- 正确。GPT 的架构是自回归语言模型,即它通过预测下一个单词来生成完整的文本,这使得 GPT 在自然语言生成任务上表现出色,如文本生成、对话系统等。由于 GPT 是单向的,它非常适合需要生成连续文本的任务,因为它可以基于上下文来生成流畅的句子。
-
BERT 则采用的是双向编码,它擅长从整体上理解句子的语义,特别适合用于自然语言理解任务(NLU),如分类、命名实体识别、问答系统等。BERT 并不擅长生成任务,因为它的预训练目标是预测掩码部分的单词,而不是生成新的文本。
这里再进行一点小拓展,分析下BERT和GPT的预训练任务。
BERT(Bidirectional Encoder Representations from Transformers)的预训练主要包括两个任务:
- 掩码语言建模(Masked Language Modeling, MLM):
- 在这个任务中,BERT随机选择输入句子中的15%的单词进行掩码处理(用[MASK]标记替代),然后模型需要根据上下文预测这些被掩码的单词。这个任务旨在让模型学习语言的语义信息和上下文关系。
- 下一句预测(Next Sentence Prediction, NSP):
- 该任务要求模型判断给定的两个句子是否是连续的。具体来说,模型会接收一对句子作为输入,并预测第二个句子是否是第一个句子的下一个句子。这个任务帮助模型理解句子之间的逻辑关系。
GPT(Generative Pre-trained Transformer)与BERT不同,其预训练主要基于自回归语言模型。其主要特点包括:
- 自回归语言建模:
- GPT通过预测下一个单词来进行训练。给定一个词序列,模型会根据前面的单词生成下一个单词。这种方法使得GPT在生成文本时能够考虑到之前的所有上下文信息。
- GPT只使用解码器部分,采用单向(从左到右)的方式处理文本。
总结下:
- BERT的预训练任务包括掩码语言建模和下一句预测,强调双向上下文理解。
- GPT则采用自回归语言建模,专注于生成文本,使用单向上下文。
2-以下哪些属于文本预处理?
- 文本摘要:
- 不属于文本预处理。文本摘要是通过压缩或提炼文本的核心内容来生成简短的摘要。文本摘要可以是基于抽取(extractive)或生成式(abstractive)的。
• 抽取式摘要:直接从文本中提取出关键信息或句子,拼接为摘要。
• 生成式摘要:通过模型生成与原文本意义一致的简洁语言描述。
-
尽管文本摘要是自然语言处理中的一个重要任务,但它通常被看作是一个应用层的任务,而不是预处理的步骤。预处理是为模型准备输入数据的过程,而摘要是在数据已经经过处理后的进一步分析或生成。因此,文本摘要通常不算作预处理的一个步骤。
- 不属于文本预处理。文本摘要是通过压缩或提炼文本的核心内容来生成简短的摘要。文本摘要可以是基于抽取(extractive)或生成式(abstractive)的。
- 去除特殊符号:
- 属于文本预处理。去除特殊符号是清理文本的一部分,能够减少噪声,提高后续分析的准确性。
- 分词:
- 属于文本预处理。在自然语言处理中,分词指的是将文本分割为单个的词语、子词或字元(token)。这些分割的单元通常是语言模型的输入。
- 去除停用词:
- 属于文本预处理。停用词是那些在文本中出现频率很高,但通常对理解文本内容贡献较少的词语,例如英文中的 “the”, “is”, “at”, “which”, “on”,以及中文中的 “的”, “了”, “是” 等等。去除停用词的目的是减少模型输入的噪声,突出更具信息量的词语。
-
去除停用词是一种常见的文本预处理操作,尤其在文本分类或情感分析任务中,这一步可以帮助降低模型的复杂度,同时提高其性能。不过,在某些特定任务中(例如机器翻译或生成任务),停用词的存在可能依然重要,因此是否去除停用词要视具体任务需求而定。
3-以下哪项是python中的可变数据类型?
在Python中,数据类型分为可变(mutable)和不可变(immutable)两类:
- 可变类型:对象的值可以在原地修改,而无需创建新的对象。可变类型的操作通常是原地操作(in-place),修改后对象的内存地址不变。常见的可变类型包括:
- 列表(list)
- 字典(dict)
- 不可变类型:对象的内容不能被改变,任何修改都会创建一个新的对象,且内存地址发生变化。常见的不可变类型包括:
- 字符串(str)
- 元组(tuple)
- 数字(int、float等)
因此,选择列表和字典。我还误选了字符串,一直觉得字符串就类似数组或列表,可以通过索引访问其中的值,这里需要特别注意它们的区别。
my_str = "hello"
print(my_str[0]) # 输出 'h'
my_str[0] = 'H' # 这将会引发错误:TypeError: 'str' object does not support item assignment字符串只能存储字符,数组可以存储多种类型的同类数据,列表则可以存储任意类型的元素,包括字符串本身。
当操作字符串时,比如拼接两个字符串,实际上 Python 会创建一个新的字符串对象,原来的字符串保持不变。这和列表的原地操作不同。
str1 = "hello"
str2 = str1 + " world" # str1 没有被修改,而是创建了一个新字符串 str24-以下哪项关于卷积层是正确的?
在卷积神经网络(CNN)中,卷积层的输出形状受到多个因素的影响,包括填充(padding)和步幅(stride)。
1. 填充(Padding)
-
定义:在输入数据的边缘添加额外的像素(通常是零),以控制输出特征图的尺寸。
-
作用:填充可以防止在卷积操作中丢失边缘信息,并可以使输出的高和宽与输入相同。
2. 步幅(Stride)
-
定义:卷积核在输入特征图上滑动时,每次移动的距离。
-
作用:步幅的大小直接影响输出特征图的尺寸。较大的步幅会导致输出尺寸减小。
选项分析:
- stride单独调整输出的高:
- 错误。步幅(stride)同时影响输出的高和宽,不能单独调整输出的高。步幅在高和宽两个方向上是同时应用的。
- padding可以调整输出的高和宽:
- 正确。填充(padding)可以增加输入特征图的高和宽,从而影响输出特征图的尺寸。通过适当设置填充,可以使得输出与输入具有相同的高和宽。
公式用于计算卷积层输出的高和宽:
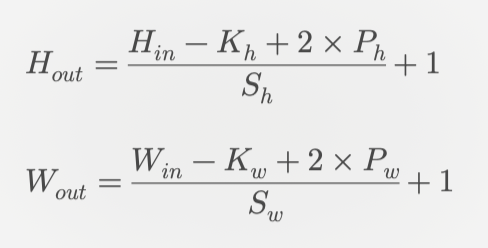
5-以下哪项关于try-except 语句是正确的?
前面关于try-except-finally语句的知识点已经详细分析过了,这里直接给出选项和简单解释。
- 一个try包含一个except:
- 错误。一个
try块可以包含多个except块,用于处理不同类型的异常。因此,try并不限制只能有一个except。
- 错误。一个
- 一个except一次处理一个异常:
- 部分正确。虽然一个
except块通常处理一种类型的异常,但它也可以通过元组同时处理多种异常。因此,这个说法不够准确。 -
try: # 可能发生异常的代码 except (ValueError, TypeError): # 处理 ValueError 和 TypeError 两种异常
- 部分正确。虽然一个
- 如果没有异常与except匹配,返回上层try块中:
- 正确。如果在当前的
try块中抛出异常,但没有找到匹配的except,则该异常会向上抛出,传递到调用该代码的上层try块中。
- 正确。如果在当前的
- 执行try块出现异常时,try块中剩余部分将会忽略:
- 正确。如果在
try块中发生了异常,控制流会立即跳转到相应的except块,后续的代码将被忽略。
- 正确。如果在
正确答案是3和4。
6-one-hot编码相较词嵌入有哪些问题?
这题选项没记下来,直接分析下。
1. 维度灾难
-
问题:One-hot编码的维度等于词汇表的大小,因此在处理大规模文本数据时,向量的维度会非常高。例如,如果词汇表有10,000个单词,则每个单词将被表示为一个10,000维的向量,其中大部分元素都是0(稀疏向量)。
-
影响:这种高维度会导致存储和计算资源的浪费,降低模型的计算效率。
-
解决:词嵌入通过将每个单词映射到一个低维的、密集的向量空间中(通常是几十到几百维),这些向量通过模型训练学习得到。这大大减少了向量维度和稀疏性,从而提高了计算效率和内存使用效率。
2. 无法捕捉语义关系
-
问题:One-hot编码无法反映单词之间的语义关系。即使两个单词在语义上非常相似,它们在One-hot编码中也是完全不相关的,彼此之间没有任何联系。不同的单词向量之间的距离是相同的,因为这些向量是互相正交的。例如,单词“cat”和“dog”在One-Hot编码下的表示形式与“cat”和“car”之间的相似性是一样的,即它们之间的余弦相似度都是0,这显然不能反映它们之间的真实语义关系。
-
影响:这使得模型在理解和处理文本时缺乏上下文信息,无法利用单词间的相似性。
- 解决:词嵌入模型通过在大规模语料上进行训练,学习到单词的语义信息。比如,Word2Vec 通过上下文信息学习到相似的单词在向量空间中具有相似的表示。这样,词嵌入可以捕捉到单词之间的语义相似性,例如“cat”和“dog”的词嵌入向量之间的距离会比“cat”和“car”之间的距离更近。
3. 对词汇表外单词无能为力
-
问题:如果训练时的词汇表较小,或者在测试时出现了词汇表外的单词,One-Hot编码根本无法处理这些单词。
-
影响:这在实际应用中经常会导致模型性能的下降,尤其是当处理领域特定的文本或新的词汇时。
- 解决:词嵌入模型能够通过学习语料中的上下文关系,处理OOV单词。现代词嵌入技术(如BERT、GPT)可以通过子词嵌入(Subword Embeddings) 来解决OOV问题。即使一个单词未曾见过,它也可以通过其组成的子词(subword)或者字符级别的嵌入来进行表示,因而能够在一定程度上缓解词汇表外问题。
4. 无法适应上下文变化
-
问题:One-Hot编码是一个静态的表示,无论单词出现在什么上下文中,都会被编码为相同的向量。例如,单词“bank”在“river bank”(河岸)和“bank account”(银行账户)中具有不同的含义,但 One-Hot编码无法区分这两种不同的语义。它总是将“bank”编码为相同的向量。
-
影响:这样一来,One-Hot编码无法处理同一个单词在不同上下文中的多义性。
- 解决:现代的上下文敏感词嵌入模型(如 BERT、GPT)通过考虑上下文来生成词向量。每次遇到一个单词时,模型会根据上下文生成不同的向量表示,这样可以更好地捕捉单词的不同语义。例如,“bank”在不同的句子中会有不同的嵌入向量,能够更准确地反映其语义。
5. 无法捕捉句法和语法信息
-
问题:One-Hot编码只为每个单词提供一个独立的符号表示,无法捕捉句子的句法结构或语法信息。对于需要理解句子结构的任务,One-Hot编码显得极为有限。
-
影响:句子中单词的顺序、语法结构对理解句子非常重要,但One-Hot编码无法捕捉这些信息,导致它在文本分析任务中的表达能力非常有限。
- 解决:词嵌入模型,尤其是基于注意力机制(如Transformer架构)的模型,通过编码整个上下文的信息来捕捉句法结构和语法关系。例如,BERT 可以通过双向编码来捕捉句子的整体结构,并通过注意力机制处理长距离的依赖关系,这使得词嵌入模型能够捕捉到复杂的句法信息。
相比之下,词嵌入通过将每个单词表示为低维稠密向量,可以有效捕捉到单词之间的语义关系,更好地适应上下文变化,提高计算效率和模型性能。通过训练得到的词嵌入能够使相似的单词在向量空间中靠近,从而更好地反映它们之间的关系。
7-以下关于归一化和标准化正确的是?
1. 归一化(Normalization)
-
定义:将数据缩放到一个特定范围(通常是[0, 1])内。
-
目的:消除量纲,使得不同特征之间可以进行比较。
-
公式:
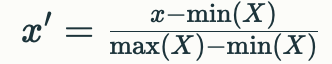
2. 标准化(Standardization)
- 定义:将数据的均值调整为0,标准差调整为1。
- 目的:使得数据符合标准正态分布,特别适用于特征值遵循高斯分布的情况。
- 公式:
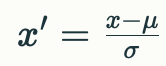
分析选项:
- 归一化消除量纲:
- 正确。归一化通过将数据缩放到相同的范围(如[0, 1]),消除了不同特征之间的量纲影响,使得它们可以进行直接比较。
- 对取值范围有要求选标准化:
- 错误。标准化并不特别要求取值范围。它主要是为了使数据符合标准正态分布,而不是限制在某个具体范围内。通常在处理不符合正态分布的数据时也可以使用标准化。
- 归一化是线性变换:
- 正确。归一化是一种线性变换,通过最小值和最大值进行线性缩放,将数据映射到[0, 1]区间。
10.12
小米的题,编程题考到动规,刚好没看这块,回去学去。
单选题
1-什么是动态规划的核心思想?
动态规划(Dynamic Programming,简称DP)是一种解决复杂问题的方法,通过将原问题分解为相对简单的子问题并逐步求解。其核心思想包括:
- 拆分子问题:将复杂问题拆分成多个相互联系的子问题。
- 记住过往:保存已经计算过的子问题的结果,以避免重复计算。
- 最优子结构:原问题的最优解可以通过其子问题的最优解构造而成。
选项分析:
- 递推:
- 正确。动态规划通常使用递推的方法来求解,通过已知的子问题结果推导出更大问题的解。
- 递归:
- 部分正确。动态规划可以使用递归实现,尤其是带备忘录的递归方法,但单纯的递归可能导致重复计算,不一定符合动态规划的高效性。
- 分治:
- 错误。分治法与动态规划不同,分治法通常将问题分解为独立子问题,而动态规划关注的是有重叠子问题和最优子结构的问题。
- 回溯:
- 错误。回溯是一种通过尝试所有可能的解来寻找最佳解的方法,与动态规划不同,后者通过保存中间结果来避免重复计算。
选递推。
2-哪项不可以正确访问到x?
1. *(*p).next->next->x
2. p->next->next->x
这题考查符号优先级和对链表结构体的理解。
.(成员访问运算符):优先级较高,用于访问结构体或联合体的成员。->(指针成员访问运算符):优先级与.相同,也用于访问结构体或联合体的成员,但适用于指针。*(解引用运算符):优先级较低,用于解引用指针。
可以发现选项1最外层的*是不必要的,选1。
3-protected变量、函数和继承
考查知识点,题目没记全。
在C++、Java、Python等面向对象编程语言中,类中的成员变量和成员函数有不同的访问控制权限,主要有三种:public、protected 和 private。其中:
•public:该类的成员对所有外部代码都可见(类外、类内、子类等都可以访问)。
•private:该类的成员仅能在该类内部访问,类外和子类无法访问。
•protected:介于 public 和 private 之间,类的成员可以在 类内部 及其 子类 中访问,但在类的外部(非继承者)是不可访问的。
protected 继承:
基类中的 public 成员变为 protected;基类中的 protected 成员保持 protected 状态;基类中的 private 成员不可访问。
private 继承:
基类中的 public 成员变为 private;基类中的 protected 成员变为 private;基类中的 private 成员不可访问。
4-模式串长m,主串长n,Boyer-Moore算法最坏情况的时间复杂度是多少?
只学过KMP,这个算法没啥印象了,大概了解一下。
Boyer-Moore算法的核心在于两个启发式规则:
- 坏字符规则(Bad Character Rule):当模式串中的字符与文本串不匹配时,算法会根据不匹配字符在模式串中最后出现的位置来决定模式串的移动距离。
- 好后缀规则(Good Suffix Rule):如果模式串的某个后缀与文本串的子串匹配成功,算法会根据该后缀在模式串中出现的位置来决定如何移动模式串。
算法步骤:
- 预处理阶段:
- 构建坏字符表和好后缀表,以便在匹配失败时快速计算移动距离。
- 匹配阶段:
- 从文本串的末尾开始与模式串进行比较。如果发现不匹配,使用前述规则计算移动距离,并继续匹配。
性能特点:
- 时间复杂度:
- 最坏情况下为 O(n+m),其中 n 是文本串的长度,m 是模式串的长度。在实际应用中,由于其高效的跳过策略,平均情况下通常表现更好。
- 空间复杂度:
- 需要 O(m)的空间来存储坏字符和好后缀表。
KMP算法的最坏时间复杂度也是 O(n+m)。构建部分匹配表的时间复杂度为 O(m),而在主串中进行匹配时,时间复杂度为 O(n)。
5-单纯形表的特点
这个没太接触过啊,有机会再看看吧。
- 检验数:
- 在单纯形表中,检验数用于判断当前解是否最优。
- 如果所有检验数均为非正(对于最大化问题)或非负(对于最小化问题),则当前解为最优解;否则,需要进行变量替换以改进解。
- 基矩阵列向量:
- 单纯形表中的基矩阵由基变量对应的列向量组成,这些列向量是线性方程组的解空间的基础。
- 基矩阵的列向量必须是线性无关的,以确保解的唯一性和可行性。通过高斯消元法,可以对基矩阵进行操作,从而求得新的基变量。
6-以下关于排序哪项正确?
- 快排是不稳定排序
- 正确。快速排序(Quick Sort)是一种不稳定的排序算法。这是因为在排序过程中,相同元素的相对位置可能会发生改变。
- 希尔排序利用插入排序的最佳性质
- 正确。希尔排序(Shell Sort)确实利用了插入排序在局部有序情况下的高效性。它通过对间隔元素进行插入排序,从而逐步减少无序度,最终达到整体有序。
- 冒泡排序的最好情况是逆序
- 错误。冒泡排序(Bubble Sort)的最好情况是当数组已经是有序时,此时只需进行 n−1 次比较,时间复杂度为 O(n)。而逆序情况下,冒泡排序需要进行最多的比较和交换。
- 插入排序的最好情况是顺序
- 正确。插入排序(Insertion Sort)的最好情况确实是当数组已经是有序时。在这种情况下,它只需进行 n−1 次比较而不需要任何交换,时间复杂度为 O(n)。
其实排序忘得差不多了。。稳定排序是指在排序过程中,如果两个元素相等,它们在排序后的相对位置与排序前保持一致;不稳定排序则不保证相等元素在排序后保持原始的相对顺序。
以下是稳定排序:
- 冒泡排序:在比较相邻元素时,不会交换相等的元素,因此保持了它们的顺序。
- 插入排序:新元素插入时,如果遇到相等的元素,新元素会被放置在后面,保持了原有顺序。
- 归并排序:合并阶段时,先合并前面的序列中的相等元素,保持了它们的顺序。
- 基数排序:按照位数进行多次排序,确保低位优先时不会影响高位的顺序。
以下是不稳定排序:
- 选择排序:在选择最小值时,如果选择的最小值与一个相等的元素交换位置,就会破坏它们的顺序。例如,在数组 [5, 8, 5, 2, 9] 中,第一次选择最小值 2 时,会使得第一个 5 和 2 交换,从而改变了两个 5 的相对位置。
- 快速排序:在分区过程中,可能会将一个相等的元素移动到另一个位置,从而破坏其顺序。
- 希尔排序:由于多次插入操作,相同元素可能在不同插入过程中改变位置,因此不保证稳定性。
- 堆排序:在调整堆结构时,相同元素之间可能会被交换,从而导致不稳定。
7-print输出r"a\\\name" 和"a\\\name",分别输出什么?
在 Python 中,字符串前加 r 表示原始字符串(raw string),这意味着反斜杠 \ 不会被解释为转义字符,而是作为字面字符处理。
1. 字符串 r"a\\\name"
- 解析:
r表示这是一个原始字符串。\\被视为两个反斜杠,因此它们会被保留为字面值\\。\n会被视为字面字符,而不是换行符。
- 输出:因此,打印这个字符串的结果是:
a\\\name2. 字符串 "a\\\name"
- 解析:
- 在普通字符串中,
\\被解析为一个反斜杠\。 - 接下来的
\n被解释为换行符。
- 在普通字符串中,
- 输出:因此,打印这个字符串的结果是:
a\
ame惊了,我完全没注意到有个\n啊。。
8-优先队列有无greater参数有什么影响吗
在C++的STL库中,优先队列(priority_queue)是一种特殊的队列,它在每次访问时总是返回当前最大的(或者最小的)元素。这是通过维护一个堆(默认是最大堆)来实现的。
C++ 的 priority_queue 默认是 最大堆,也就是说,队列中的元素按照从大到小的顺序排列,最大的元素总是在队首。greater 参数用于改变这个默认的顺序,使得优先队列按照最小堆的方式运作。具体地说:
- 默认情况下(无 greater 参数),priority_queue 是一个最大堆,即每次 top() 返回队列中的最大值。
- 带有 greater 参数时,priority_queue 是一个最小堆,即每次 top() 返回队列中的最小值。
9-Personal Rank算法基于哪种数据结构?
Personal Rank 是一种常用于推荐系统中的算法,它是基于 PageRank 算法的一个变种。PageRank 本身用于衡量网页的重要性,而 Personal Rank 则用于衡量一个节点(用户或物品)相对于某个特定节点(例如某个用户)之间的相关性。PageRank 算法通过全局图结构来衡量所有节点的重要性,而 Personal Rank 更加个性化,它以特定用户为出发点,只关注与该用户相关的部分图。它被广泛应用于推荐系统,尤其是基于图的推荐系统。
Personal Rank 是基于图结构的,它的基本思想是在一个用户物品图(User-Item Graph)上进行随机游走,通过用户与物品节点之间的关系,计算出与该用户最相关的物品。在这个图中:
- 顶点(节点)可以表示用户或物品。
- 边(链接)表示用户和物品之间的交互,例如用户对某物品的点击、浏览、购买等行为。
随机游走从某个用户节点开始,每次随机选择相邻的节点(物品节点),再继续随机游走,最终计算每个物品节点的相关性得分。一种常见的计算方法是迭代更新用户和物品之间的权重,类似于求解线性方程组,直到权重收敛。
10-连通图的生成树的边数至少是?
连通图的生成树的边数至少是 n−1,其中 n 是图中顶点的数量。这是因为生成树必须包含所有顶点,并且在不形成回路的情况下连接这些顶点。
11-以下哪项是计算查找法?
- 哈希查找:
- 哈希查找通过哈希函数将键值映射到哈希表中的位置,从而实现快速查找。其查找时间复杂度为 O(1),即使在数据量较大的情况下,查找速度依然保持高效。
- 它的基本原理是将输入的键值通过哈希函数计算出一个哈希值,并使用该哈希值作为索引来访问存储在哈希表中的数据。
- 顺序查找:
- 顺序查找是最简单的查找方法,它通过逐个检查列表中的元素来找到目标值,时间复杂度为 O(n)。与哈希查找相比,效率较低。
- 分块查找:
- 分块查找是一种改进的顺序查找方法,通过将数据分成若干块来减少查找范围,但其效率仍然不及哈希查找,时间复杂度通常为 O(n)。
- 二叉排序树:
- 二叉排序树(或二叉搜索树)通过树结构存储数据,支持快速插入和查找操作,其平均时间复杂度为 ,但在最坏情况下(例如数据按顺序插入)可能退化为 O(n)。
“计算查找” 指通过某种计算来决定查找过程的方式,典型的例子就是哈希查找,因为它通过哈希函数进行计算,从而直接定位元素的位置。相比之下,顺序查找和分块查找主要是基于遍历或局部遍历的方式,二叉排序树则是基于树形结构的递归或迭代。因此选哈希查找。
多选题
1-以下哪项是聚类算法?
- 层次聚类:这是一种聚类方法,通过构建层次结构(树状图)来将数据分组。它可以是自底向上(凝聚)或自顶向下(划分)的方式,因此属于聚类。
- K-means:这是一种常见的聚类算法,通过将数据分为 K 个簇,使得每个样本与其所属簇的中心的距离之和最小。它是无监督学习中的基本聚类算法,因此也是聚类的一种。
- KNN(K-近邻):这是一种监督学习算法,通常用于分类而非聚类。它通过计算样本与训练集中 K 个最近邻的距离来进行分类。因此,KNN 不是聚类。
- SVM(支持向量机):这也是一种监督学习算法,主要用于分类和回归任务,而不是用于聚类。因此,SVM 也不是聚类。
选层次聚类和K-means。
2-AlphaGo用到哪些技术?
强化学习是 AlphaGo 的核心组成部分之一。在强化学习中,系统通过与环境互动,从成功和失败中不断学习。AlphaGo 使用强化学习来训练其策略网络和价值网络,通过自我对弈来提高下棋的水平。
AlphaGo 使用了多个神经网络来进行围棋的决策。特别是,它使用两个不同的神经网络:策略网络(Policy Network)和价值网络(Value Network)。策略网络用于预测下一步的走法,价值网络用于评估当前棋局的胜负情况。
深度学习 是 AlphaGo 的基础技术,它指的是使用深层神经网络进行复杂任务的学习和推理。AlphaGo 的策略网络和价值网络都是基于深度学习技术,通过大量的棋局数据进行训练。
蒙特卡洛树搜索 是 AlphaGo 中用于决策的关键技术之一。在每一步选择时,AlphaGo 通过蒙特卡洛树搜索来模拟多个可能的走法并评估其结果。蒙特卡洛树搜索通过模拟大量可能的棋局分支,找到最优的走法。
3-SGD调节哪些参数来得到最优解?
1.学习率:学习率决定了每次更新参数的幅度,适当的学习率可以加速收敛,而过大的学习率可能导致发散。
2.初始参数:选择合适的初始参数可以影响模型的收敛速度和最终性能,不同的初始值可能会导致不同的局部最优解。
3.迭代次数:增加迭代次数可以使模型有更多的机会学习数据,但过多的迭代可能导致过拟合。
4. 损失函数一般是在模型设计阶段确定的,而不是通过SGD来调节的。
因此,正确的选项是 学习率、初始参数和迭代次数。
4-动态链接发生在程序运行的哪个阶段?
1. 调用:动态链接通常在程序运行时进行,因此在调用相关函数时,动态链接会将所需的库加载到内存中并进行符号解析。
2. 装入:在程序装入(Loading)阶段,操作系统会加载可执行文件及其依赖的动态链接库,并进行必要的重定位和符号绑定。
3. 编译:编译阶段主要是将源代码转换为目标文件,并不涉及动态链接的具体过程。
4. 紧凑:紧凑(Compaction)一般指的是内存管理中的一种技术,与动态链接无直接关系。
选调用和装入。不翻译成英文我都不知道紧凑和装入是啥。。😓
编程题
1. 可以无限次翻转数组相邻元素的符号,使得最后数组的和最大***(这题好难,现在都还不会)
2. 宝石项链
10.18
58的题,做了几次笔试开始顺手了。考虑到前几次记录整理花了太多时间,这次主要以知识点为主,答案为AI生成。
单选题
1-数据库哪些操作会导致脏读?
- 事务隔离级别设置不当:
- 读未提交(Read Uncommitted):这是最容易导致脏读的隔离级别,允许一个事务读取另一个事务尚未提交的数据。
- 并发事务:在高并发环境下,多个事务同时对数据库进行读写操作时,如果一个事务在另一个事务未提交前读取了数据,就会发生脏读。
- 锁机制不完善:
- 如果数据库的锁机制无法有效地防止未提交数据的读取,那么就可能出现脏读。例如,若一个事务没有对其修改的数据加锁,其他事务仍然可以读取这些未提交的数据。
- 数据库故障:
- 在数据库崩溃或断电等情况下,未提交的数据可能会丢失或被其他事务读取,从而导致脏读的发生。
解决脏读的方法:
- 调整事务隔离级别:选择更严格的隔离级别,如读已提交(Read Committed)或可重复读(Repeatable Read),可以有效避免脏读现象。
- 使用锁机制:合理使用行级锁或表级锁来控制并发事务的访问,以确保数据一致性和隔离性。
2-入栈顺序:abcde;以下哪种不可能是出栈顺序?
- edcba:可以实现。入栈顺序为
abcde,可以先入栈a,b,c,d,e,然后依次出栈e,d,c,b,a。 - abcde:可以实现。直接按照入栈顺序出栈。
- added:不可能实现。因为在栈中,
d必须在e之前出栈,而这里的顺序是先出a和d,这与后进先出的原则相悖。 - dcbae:可以实现。可以先入栈
a,b,c,d, 然后出栈d, 再依次出栈c,b,a。
因此,唯一不可能的出栈顺序是 added。
3-信号量的主要用处是什么?
在讨论信号量的用处时,信号量(Semaphore)是一种用于控制多线程或多进程并发访问共享资源的机制,因此它的核心作用与线程同步和资源的同步互斥密切相关。在给出的选项中,最符合信号量主要用途的选项是:资源同步互斥。
1. 进程调度:信号量并不是直接用于进程调度的工具。进程调度是操作系统根据某种算法(如时间片轮转、优先级调度等)决定哪个进程或线程在某一时刻获得 CPU 使用权的过程。进程调度涉及到时间管理和优先级调度,而不是资源访问的同步。信号量虽然可能间接影响进程的调度(例如,进程等待某些资源时被阻塞),但它不是直接用于调度的工具。
2. 线程同步:信号量的确是用来解决线程同步问题的一种机制,特别是在多线程编程中,当多个线程需要访问共享资源时,必须确保某种同步机制来保证资源的正确访问。信号量通过计数器限制资源的访问次数,从而有效地防止了多个线程同时访问某个临界区或共享资源。
例如,如果有一个临界区,只允许一个线程访问(即二元信号量或互斥量的应用场景),信号量会确保在一个线程进入临界区时,其他线程会被阻塞,直到当前线程释放信号量。信号量在这种情况下解决了线程之间的同步问题,确保多个线程可以有序地、安全地共享资源,而不会导致竞态条件(race condition)或数据不一致问题。因此,线程同步也是信号量的一项重要功能。
3. 进程通信:信号量虽然可以在某些特定情况下间接用于进程通信,但它不是典型的进程通信机制。通常,进程通信涉及的工具有管道(pipes)、消息队列、共享内存、信号等,而信号量主要用于同步,而非直接的消息传递或数据共享。信号量可以用于进程间同步,即控制多个进程对共享资源的有序访问。比如,多个进程可能会尝试访问同一个文件或共享内存段,这时候信号量可以防止多个进程同时写入导致数据损坏。然而,信号量并不会直接传递数据或信息,因此它不属于典型的进程通信机制,而更多是用作进程间的同步工具。
4. 资源同步互斥:信号量的经典应用就是用于资源同步互斥。在操作系统和多线程编程中,当多个线程或进程需要共享某些资源时,必须确保这些资源的有序访问,以避免竞态条件。信号量通过允许有限个线程或进程同时访问某个共享资源,确保了资源访问的互斥和同步。
- 互斥量(Mutex) 是信号量的一个特例,只允许一个线程访问某个资源。即线程A占用资源时,线程B必须等待,直到线程A释放资源。
- 计数信号量(Counting Semaphore) 可以用来控制多个线程对有限资源的访问。例如,有5个线程,但只有2个数据库连接池的资源,信号量可以设置为2,确保只有两个线程能同时访问数据库资源,其他线程必须等待。
信号量通过维护一个内部计数器来追踪可用的资源数量,计数器的增减决定了资源的分配和释放,从而确保多个进程或线程之间对资源的有序竞争。
4-操作系统中页表的作用?
页表在操作系统中扮演着重要的角色,主要用于管理虚拟内存。其主要作用包括:
1. 地址转换:页表的基本功能是将虚拟地址转换为物理地址。在使用虚拟内存的操作系统中,每个进程认为自己拥有一块连续的内存,但实际上,这些内存可能分散在物理内存的不同位置。页表记录了虚拟地址与物理地址之间的映射关系,使得CPU能够通过页表快速找到对应的物理地址。
2. 权限管理:页表还负责管理对物理内存的访问权限,例如读、写和执行权限。这种权限控制可以防止进程间的不当访问,确保系统安全性。例如,用户进程无法访问内核空间,从而保护操作系统的稳定性和安全性。
3. 隔离地址空间:每个进程都有自己的页表,这样可以实现进程间地址空间的隔离。通过这种方式,一个进程无法直接访问或干扰另一个进程的内存,提供了更高的安全性和稳定性。这种隔离使得每个进程都能认为自己拥有完整的虚拟内存空间。
4. 支持内存共享:页表还可以支持多个进程共享同一块物理内存。例如,在使用共享库时,多个进程可以通过页表映射同一物理页面,从而节省内存资源。
5. 实现页面调度:在物理内存不足时,操作系统可以使用页表来管理页面调度,将不活跃的页面换出到磁盘,并在需要时再将其加载回内存。这样,操作系统能够有效利用有限的物理内存资源。
5-OSI模型中()层负责数据的加密解密
在OSI模型中,负责数据的加密和解密的层是 表示层(Presentation Layer),也称为第六层。表示层的主要功能包括数据的翻译、加密和压缩,以确保数据以接收系统可以理解的格式进行传输。
- 数据加密:在发送数据之前,表示层会将其转换为加密格式,以保护敏感信息。
- 数据解密:在接收端,表示层负责将加密的数据解密回其原始格式,使应用层能够处理这些数据。
6-补码的主要作用是?
1. 表示负数:
- 补码是一种用二进制表示有符号数的方法。正数的补码与其原码相同,而负数的补码则是其绝对值的二进制表示取反后加一。这种表示方式使得计算机能够有效地存储和处理负数。
2. 简化运算:
- 使用补码进行减法运算时,可以将减法转换为加法。例如,要计算 A−B,可以将 B 转换为其补码,然后执行 A+(−B)。这样,所有的加法和减法都可以通过同一加法电路来实现,从而简化了硬件设计。
3. 避免零的二重表示:
- 在补码系统中,零只有一种表示方式(即全为0),这与反码系统不同(反码系统中零有两种表示)。这简化了零值的判断和处理。
4. 支持溢出检测:
- 在进行补码运算时,如果最高位(符号位)有进位,则可能发生溢出。这种特性使得在设计计算机系统时,可以更容易地检测和处理溢出情况。
7-Java封装知识点
封装的定义:封装是将对象的状态(属性)和行为(方法)组合在一起,并通过访问修饰符控制对这些属性和方法的访问。它允许对象内部的实现细节被隐藏,只暴露必要的接口给外部使用。
封装的主要特点:
- 信息隐藏:
- 通过将类的属性声明为私有(private),外部代码无法直接访问这些属性,确保了数据的安全性和完整性。
- 公共接口:
- 通过公共(public)的方法(通常称为getter和setter),外部代码可以安全地访问和修改对象的状态。例如,使用
getName()和setName(String name)方法来访问和修改name属性。
- 通过公共(public)的方法(通常称为getter和setter),外部代码可以安全地访问和修改对象的状态。例如,使用
- 灵活性和可维护性:
- 封装使得类的内部实现可以随时更改,而不影响使用该类的外部代码。这种特性提高了代码的灵活性和可维护性。
- 减少耦合:
- 封装促进了模块化设计,使得不同模块之间的依赖关系降低,从而减少了耦合度,提高了系统的可扩展性。
封装的优点
- 安全性:保护对象状态,避免无效或不当的数据修改。
- 可维护性:内部实现变更不影响外部调用,方便后期维护。
- 易于理解:通过清晰的接口定义,增强代码可读性。
- 控制访问:可以对属性进行更精确的控制,例如在setter方法中添加验证逻辑。
多选题
1-进程间通信机制有?
1. 管道(Pipe)
-
无名管道:用于具有亲缘关系的进程(如父子进程)之间的单向通信。
-
有名管道:允许无亲缘关系的进程间通信,使用文件系统中的特殊文件作为通信媒介。
2. 消息队列(Message Queue)
-
消息队列是一种在内核中维护的消息链表,允许进程以异步方式发送和接收消息。它支持多个进程之间的通信,且消息可以在队列中等待接收。
3. 共享内存(Shared Memory)
-
共享内存允许多个进程访问同一块物理内存区域,提供了高效的数据交换方式。由于不需要数据拷贝,速度较快,但需要额外的同步机制来避免数据竞争。
4. 信号量(Semaphore)
-
信号量是一种用于控制对共享资源访问的计数器,通常用于实现进程间和线程间的同步。
5. 信号(Signal)
-
信号是一种通知机制,用于告知接收进程某个事件已发生。信号可以用于处理异步事件,但信息量较小。
6. 套接字(Socket)
-
套接字是一种通用的通信机制,可以用于同一台机器上的进程间通信,也可以用于不同机器之间的网络通信。
7. 文件映射
-
文件映射允许多个进程通过映射同一文件到各自的地址空间来进行通信。这种方式适合于需要持久化的数据交换。
2-Java垃圾回收机制知识点
Java的垃圾回收机制(Garbage Collection, GC)是自动管理内存的一种方式,旨在回收不再使用的对象所占用的内存,以防止内存泄漏和提高程序的性能。以下是关于Java垃圾回收机制的主要知识点:
1. 垃圾回收的必要性
-
内存管理:在Java中,程序员不需要手动释放内存,GC会自动监控对象的生命周期并回收不再使用的对象。
-
防止内存泄漏:通过定期回收未使用的对象,GC可以有效地防止内存泄漏,从而提高应用程序的稳定性。
2. 垃圾回收的工作原理
-
标记-清除算法:GC首先标记所有可达的对象,然后清除未被标记的对象。这种方法简单,但可能导致内存碎片。
-
复制算法:将内存分为两个区域,每次只使用其中一个区域,回收时将存活对象复制到另一个区域,避免了内存碎片问题。
-
标记-整理算法:在标记后,将所有存活对象移动到一起,整理内存空间,减少碎片。
编程题
1. 合并有序数组的中位数
简单题,双指针即可。
2. 求反码值
解法一:
n = 7
bit_length = n.bit_length()
mask = (1 << bit_length) - 1
complement = mask ^ n
return complement-
bit_length计算有效位数:n.bit_length()计算整数n的有效二进制位数,即去掉前导零后的位数。例如,5的二进制是101,它有 3 位,所以bit_length = 3。
-
左移运算
(1 << bit_length):1 << bit_length是将数字1向左移动bit_length位,相当于生成了一个在第bit_length+1位上有1的数,而低位全是0。- 比如对于
bit_length = 3,1 << 3就是1000,即十进制的8。
-
减1
(1 << bit_length) - 1:- 将
1 << bit_length得到的数减去1,可以得到一个低bit_length位全为1的掩码。 - 对于
bit_length = 3,1 << 3 = 8,减去1得到7,也就是二进制的111。
- 将
这样做的目的是为了构造一个与 n 位数相同且全为 1 的掩码。然后我们可以通过与原数 n 进行异或运算(n ^ mask)来得到它的反码。掩码的每一位都是 1,这确保了原数的每一位都被翻转。
解法二:
# 将数字转换为二进制字符串,去掉前缀'0b'
binary = bin(num)[2:]
# 生成反码
inverse = ''.join('1' if bit == '0' else '0' for bit in binary)
# 将反码转回十进制数
inverse_num = int(inverse, 2)
return inverse_num3. 背包问题
N种商品,X积分,每种商品i的数量counts[i],积分points[i]。恰好用完X积分兑换商品,最少要选择多少件商品?如果无法恰好用完,返回-1。
吐槽下这题竟然不给用python = =
int n = points.size();
vector<int> dp(X + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < counts[i]; j++) {
for (int k = X; k >= points[i]; k--) {
if (dp[k - points[i]] != INT_MAX) {
dp[k] = min(dp[k], dp[k - points[i]] + 1);
}
}
}
}
return dp[X] == INT_MAX ? -1 : dp[X];- 我们创建一个dp数组,其中dp[i]表示恰好兑换i积分所需的最少商品数量。
- 初始化dp[0] = 0,表示兑换0积分不需要任何商品。其他位置初始化为INT_MAX,表示还未找到有效的兑换方式。
- 我们遍历每种商品,对于每种商品,我们考虑使用0到counts[i]件。
- 对于每件商品,我们从X到points[i]逆序遍历积分值。这是为了避免重复使用同一件商品。
- 如果dp[k - points[i]]不是INT_MAX(即存在有效的兑换方式),我们更新dp[k]为当前值和dp[k - points[i]] + 1中的较小值。
- 最后,如果dp[X]仍然是INT_MAX,说明无法恰好兑换X积分,返回-1。否则,返回dp[X]。
10.27
pdd笔试题。确实挺难,有的写出来但超时了,只通过了部分样例,对时间复杂度要求很高,也是太久没做oj判题这种模式的了。
1-只要相邻字符不同,就是完美字符串,现在给出一个字符串,输出最长的完美子串的长度。
我用的动态规划,dp(i)为第i个元素结尾的最长完美子串长度,if s[i]!=s[i+1]: dp(i+1)=dp(i)+1 else: dp(i+1)=1
自认为O(n)时间复杂度可以了,也不会走回头路。但还是超时了。可能因为空间复杂度也是 O(n)?
结束搜了下发现还可以用双指针(滑动窗口)来解,能有效减少不必要的重复计算,适合大多数情况下相邻字符不同的问题。
思路如下:
- 使用两个指针
left和right来表示当前的子串窗口。 right指针逐步向右扩展,如果遇到当前字符与前一个字符相同,则更新left到right的位置,这样保证了窗口内的字符始终是相邻不相同的。- 记录窗口的长度,并维护一个变量
max_len来存储最长的完美子串长度。 - 最终返回
max_len。
def longest_perfect_substring(s: str) -> int:
n = len(s)
if n < 2:
return n # 字符串长度小于2时直接返回自身长度
max_len = 1 # 记录最长完美子串长度
left = 0 # 滑动窗口左指针
for right in range(1, n):
# 如果当前字符与前一个字符相同,更新左指针到当前字符位置
if s[right] == s[right - 1]:
left = right
# 更新最长完美子串长度
max_len = max(max_len, right - left + 1)
return max_len这样时间复杂度 O(n),空间复杂度也为 O(1)。
我又想,或许不需要每移动一次right指针就去比较一次max_len,只在移动left指针时计算。但如果遇到"aaab"这样的字符串,在末尾不会再遇到重复字符,left指针也不会变动,这样就会输出为1;所以除了只在移动left指针时计算max_len,移动到末尾时也需要计算一次。这样应该会更快一点。
def longest_perfect_substring(s: str) -> int:
n = len(s)
if n < 2:
return n # 字符串长度小于2时直接返回自身长度
max_len = 1 # 记录最长完美子串长度
left = 0 # 滑动窗口左指针
for right in range(1, n):
# 如果当前字符与前一个字符相同,更新左指针到当前字符位置
if s[right] == s[right - 1]:
max_len = max(max_len, right - left)
left = right
# 末尾时也更新最长完美子串长度
max_len = max(max_len, right - left + 1)
return max_len但是如果遇到"aaaaa...aaa"这样的字符串,能否不用每次都计算max_len并且同时移动left和right指针呢?加个while判断感觉能解决:
def longest_perfect_substring(s: str) -> int:
n = len(s)
if n < 2:
return n # 字符串长度小于2时直接返回自身长度
max_len = 1 # 记录最长完美子串长度
left = 0 # 滑动窗口左指针
right = 1
while right < n:
if s[right] == s[right - 1]:
while right < n and s[right] == s[right - 1]:
right += 1
left = right - 1
else:
right += 1
max_len = max(max_len, right - left)
return max_len但是现在没有了判题系统,不知道能否通过所有样例。
2-长为m的空哈希表,给一个长n的数组nums,插入元素,插入下标为nums%m。如果当前位置为空就插入,否则向右查看直到遇见空位置。如果哈希表满了,或者已经存在的元素就不再插入。
我用了defaultdict去判断是否已经插入过,用cnt记录已经插入的元素个数去判断哈希表是否满了。也是逻辑应该正确,但超时了。
问了gpt也没有什么更好的思路,只说可以用集合来存储已经插入的元素,用 O(1) 的时间复杂度判断元素是否已经存在。其他也没有啥改动,不知道有没有更优解法。
def insert_into_hash_table(nums, m):
hash_table = [None] * m # 初始化哈希表
seen = set() # 用于快速查重
count = 0 # 记录哈希表中已插入的元素数量
for num in nums:
if num in seen: # 如果元素已经存在,跳过
continue
index = num % m
original_index = index
while hash_table[index] is not None: # 线性探测
index = (index + 1) % m
if index == original_index: # 如果回到原位置,表示哈希表已满
return hash_table
hash_table[index] = num # 插入元素
seen.add(num) # 记录插入的元素
count += 1 # 更新已插入的元素个数
if count == m: # 哈希表已满
break
return hash_table3-输入比赛项目数n,后面n行是每个项目中C国和A国拿金牌的概率,比如: ''' 3 / 0.6 0.2 / 0 0.5 / 0.7 0 ''' 现在希望求出C国拿到金牌数大于A国的概率(每个项目只有一个金牌)。
这题就比较复杂了,我没完全写出来。题目里样例的计算方式可以是: #3-0 + 2-0 + 2-1 + 1-0 win3 = 0.6*0*0.7;win2 = (1-0.6)*0*0.7 + 0.6*(1-0)*0.7 + 0.6*0*(1-0.7);win1 = 0.6*(1-0-0.5)*(1-0.7-0) + 0 + 0.7*(1-0.6-0.2)*(1-0-0.5) ,最终答案是win3+win2+win1=0.58。
这题我的思路是:除了C国和A国,假设还有一个B国(其他所有国),每个项目中,用B国获胜概率=1-C国获胜概率-A国获胜概率。C国获胜次数+A国获胜次数+B国获胜次数=n,求解C国获胜次数>A国获胜次数的概率。 但是有了思路我还是不太会写,因为从n个项目里根据不同获胜次数来选取项目数,对应的ABC国不同情况很复杂。又是结束了求助gpt,原来也是用动态规划做。
可以将问题视为一个分步累积的过程:每次遇到一个新的比赛项目,更新当前获胜次数的概率分布,直到计算出所有比赛的情况。
-
定义状态:设
dp[i][j][k]表示在前i个比赛中,C国获胜j次,A国获胜k次的概率。- 对于每场比赛,有三种可能性:
- C国获胜,概率为
p_c[i] - A国获胜,概率为
p_a[i] - B国获胜,概率为
p_b[i] = 1 - p_c[i] - p_a[i]
- C国获胜,概率为
- 根据以上三种情况更新
dp状态。
- 对于每场比赛,有三种可能性:
-
初始化状态:
dp[0][0][0] = 1,表示没有比赛时,三国都没有获胜的概率为 1。 -
状态转移:
- 对于每个比赛项目
i,我们需要用p_c[i]、p_a[i]、p_b[i]更新dp表。 - 如果 C国获胜,则
dp[i][j+1][k] += dp[i-1][j][k] * p_c[i] - 如果 A国获胜,则
dp[i][j][k+1] += dp[i-1][j][k] * p_a[i] - 如果 B国获胜,则
dp[i][j][k] += dp[i-1][j][k] * p_b[i]
- 对于每个比赛项目
-
目标结果:最后遍历所有可能的
j > k的状态,累加这些状态的概率dp[n][j][k],即为 C 国获胜次数大于 A 国获胜次数的概率。
def c_win_probability(n, probabilities):
# dp[i][j][k] 表示前 i 个项目中,C国获胜 j 次,A国获胜 k 次的概率
dp = [[[0.0] * (n + 1) for _ in range(n + 1)] for _ in range(n + 1)]
dp[0][0][0] = 1.0 # 初始状态,没有比赛时三国都没获胜的概率为 1
for i in range(1, n + 1):
p_c, p_a = probabilities[i - 1]
p_b = 1 - p_c - p_a
for j in range(i + 1): # j 为 C 国获胜次数
for k in range(i + 1): # k 为 A 国获胜次数
if j > 0: # C 国获胜一次的情况
dp[i][j][k] += dp[i - 1][j - 1][k] * p_c
if k > 0: # A 国获胜一次的情况
dp[i][j][k] += dp[i - 1][j][k - 1] * p_a
# B 国获胜的情况
dp[i][j][k] += dp[i - 1][j][k] * p_b
# 累加所有 j > k 的情况,即 C 国获胜次数 > A 国获胜次数
result = sum(dp[n][j][k] for j in range(n + 1) for k in range(j))
return result时间复杂度为 O(n3)。
4-小明没有糖,他想和别的小朋友买糖吃,第一行输入的数是其他小朋友有糖的个数(比如:10 4就说明还有两个小朋友,一个小朋友有10颗糖,一个有4颗糖),第二行是他们愿意卖出糖的价格(比如:5 2)现在问小明能用多少最少的钱,让他买到糖后,比其他小朋友的糖都要多(比如他从小朋友1那买了5颗,小朋友2那买1颗,现在小明有6颗糖,小朋友1有10-5=5颗,小朋友2有4-1=3颗)
这题没来得及写全,感觉用贪心,先从糖数最多的那里买,达成一定条件后(比如其他每个人的糖都不超过总糖果数/小朋友数)之后再从最便宜的那里买。这题gpt也回答不对,直接题意都理解不了了。
后面有空再回来看看吧。
10.28
时间有限简单记录下。
1-周末营业额高于平时属于
- 循环变动:指经济周期中的波动,通常与经济增长和衰退相关,持续时间较长。
- 季节变动:指在一年中某些特定时期(如周末、节假日等)因季节性因素导致的规律性波动。
- 长期趋势:指数据随时间推移而表现出的长期变化方向,例如持续增长或下降的趋势。
- 不规则变动:指无法预测的随机波动,通常由突发事件或偶然因素引起。
因此,周末营业额高于平时主要反映了季节性消费模式,而不是其他类型的变动。
2-25匹马,找出最快的三匹,只有五个赛道,至少比几次
至少需要进行7场比赛。以下是详细的步骤和逻辑分析:
- 分组比赛:
- 将25匹马分为5组,每组5匹马。
- 进行5场比赛,确定每组的名次(例如,A组的马为A1, A2, A3, A4, A5,B组为B1, B2, B3, B4, B5,以此类推)。
- 冠军赛:
- 从每组中选出第一名(即A1, B1, C1, D1, E1)进行第6场比赛,以确定这5匹马中最快的马。
- 假设A1在这场比赛中获胜,那么A1是所有马中最快的。
- 确定亚军和季军:
- 由于A1是第一名,我们需要找出第二名和第三名。可以排除掉D组和E组的所有马,因为它们无法进入前3名。
- 剩下的马是:A2, A3(来自A组),B1, B2(来自B组),C1(来自C组)。
- 进行第7场比赛,从这5匹马中选出第二名和第三名。
通过上述步骤,总共进行了7场比赛。这样可以确保找到25匹马中的前三名。
3-52张牌,抽三张,抽到同花色概率更大还是同大小概率更大
先看同花色的概率。首先,我们需要选择一个花色,然后从该花色中选择三张牌。
- 选择花色:有4种选择(红桃、黑桃、方块、梅花)。
- 选择牌:每种花色有13张牌,从中选择3张的组合数为 C(13,3)。
因此,同花色的组合数为:4×C(13,3)=4×13×12×113×2×1=4×286=1144
总的抽取三张牌的方式为:C(52,3)=52×51×503×2×1=22100
所以,同花色的概率为:P=1144 / 22100≈0.0518=5.18%
再看同点数的概率。要抽到三张相同点数的牌,首先需要选择一个点数(如A、2、3等),然后从该点数的四张牌中选择三张。
- 选择点数:有13种选择。
- 选择牌:对于每个点数,从4张中选3张的组合数为 C(4,3)=4。
因此,同大小的组合数为:13×C(4,3)=13×4=52
同样,总的抽取三张牌的方式仍然是22100。因此,同大小的概率为:P=5222100≈0.00236=0.236%
- 同花色的概率:约5.18%
- 同大小的概率:约0.236%
因此,从52张牌中抽取三张得到同花色的概率更大。
4-一个木棍折为三段,能构成三角形的概率是多少
设木棍阶段后的三段长度,分别是x, y, z。则它们能构成三角形的条件是两边之和大于第三边,即x+y>z, y+z>x, z+x>y。此为“三角不等式”。
然后对我们的木棍,设其总长度为1。两个切断点的位置设为a和b。则得到的三段木棍长度分别为a,b-a,和1-b。分别代入上述三角不等式,得:



有了上述公式,我们可以把a,b的取值情况“可视化”如下:

以上阴影部分即为可以构成三角形的情况,很直观的可以看出答案是1/4!
5-随机取三根长度从0到1的木棍,这三根木棍能构成三角形的概率是多少
这一题我们是随机取三根木棍,必须取三个变量,这样如果想可视化,我们就必须画出一个边长为1的立方体来。
为了帮助解决这个问题,我们考虑一下答案的反例,即何种情况不能构成三角形。比如考虑x>y+z的情况,在这种情况下,所有不能构成三角形的点会位于以下若干平面包围的“金字塔”中:y=0, z=0, x=1和x=y+z。这个“金字塔”的体积正好是立方体的1/6。一共有三个这样的“金字塔”不能构成立方体,因此不能构成三角形的概率是3*(1/6)=1/2。则能构成三角形的概率也是1/2。
11.05
shopee的题,刚好来月经肚子超痛,在陌生的北京做完了。
1-Adam优化器的主要优点
Adam优化器结合了动量和自适应学习率调整,能够更快收敛。
- 动量的加速效果:Adam利用动量的概念,通过记录历史梯度方向加速优化过程。这种方法帮助模型在“下山”时避免被局部极小值卡住,使得收敛速度更快。
- 自适应学习率调整:Adam根据每个参数的历史梯度动态调整学习率。在陡峭的坡道上,降低学习率以避免过冲;在平缓的坡道上,提高学习率以加速接近目标。这种灵活性特别适合处理稀疏数据。
- 较快的收敛速度:结合了RMSProp和SGD的优点,Adam能够更平滑地下降,快速找到合理的最小值。与传统SGD相比,Adam在路径上更稳定。
- 处理稀疏梯度问题:对于某些参数更新量小而其他更新量大的情况,Adam能有效调整学习率,确保整体优化过程不受小摩擦影响。
- 较少的超参数调节需求:Adam的主要超参数(如beta_1和beta_2)有默认值,通常适用于大多数深度学习问题,使得使用者无需频繁调整。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧