【算法】topk之字节题
1. 合并两个有序列表 🔗
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]示例 2:
输入:l1 = [], l2 = []
输出:[]示例 3:
输入:l1 = [], l2 = [0]
输出:[0]提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
我的题解:
思路很简单,迭代遍历就可以了,每次把值更小的节点加到结果链表里。最开始我还试图把更短的链表换到l1,后面发现没必要。
时间复杂度:O(n+m),其中 n 和 m 分别为两个链表的长度。因为每次循环迭代中,l1 和 l2 只有一个元素会被放进合并链表中, 因此 while 循环的次数不会超过两个链表的长度之和。所有其他操作的时间复杂度都是常数级别的,因此总的时间复杂度为 O(n+m)。
空间复杂度:O(1)。我们只需要常数的空间存放若干变量。
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def mergeTwoLists(self, list1, list2):
"""
:type list1: Optional[ListNode]
:type list2: Optional[ListNode]
:rtype: Optional[ListNode]
"""
if list1 is None:
return list2
if list2 is None:
return list1
# 接下来处理的一定是非空列表
p1 = list1
p2 = list2
p = head = ListNode()
while p1 and p2:
if p1.val <= p2.val:
p.next = p1
p1 = p1.next
else:
p.next = p2
p2 = p2.next
p = p.next
p.next = p1 if p1 else p2
return head.next其它题解:
还有个思路是递归求解,递归算法的空间复杂度 = 每次递归的空间复杂度 * 递归深度。递归看起来很简洁但是很容易出错,而且复杂度更高,我更倾向先把迭代逻辑写出来,再去想怎么改成递归。
时间复杂度:O(n+m),其中 n 和 m 分别为两个链表的长度。因为每次调用递归都会去掉 l1 或者 l2 的头节点(直到至少有一个链表为空),函数 mergeTwoList 至多只会递归调用每个节点一次。因此,时间复杂度取决于合并后的链表长度,即 O(n+m)。
空间复杂度:O(n+m),其中 n 和 m 分别为两个链表的长度。递归调用 mergeTwoLists 函数时需要消耗栈空间,栈空间的大小取决于递归调用的深度。结束递归调用时 mergeTwoLists 函数最多调用 n+m 次,因此空间复杂度为 O(n+m)。
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def mergeTwoLists(self, list1, list2):
"""
:type list1: Optional[ListNode]
:type list2: Optional[ListNode]
:rtype: Optional[ListNode]
"""
if list1 is None:
return list2
if list2 is None:
return list1
if list1.val <= list2.val:
list1.next = self.mergeTwoLists(list1.next, list2)
return list1
else:
list2.next = self.mergeTwoLists(list1, list2.next)
return list2
2. 二叉树的锯齿形层序遍历 🔗
给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[[3],[20,9],[15,7]]示例 2:
输入:root = [1]
输出:[[1]]示例 3:
输入:root = []
输出:[]提示:
- 树中节点数目在范围
[0, 2000]内 -100 <= Node.val <= 100
我的题解:
这题看起来花里胡哨的,其实还是在考察层序遍历,利用队列先进先出的特点,从左到右一层一层的去遍历二叉树。层序遍历写出来了就很简单,加个奇偶判断和层级列表反转就可以。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def zigzagLevelOrder(self, root):
"""
:type root: TreeNode
:rtype: List[List[int]]
"""
if not root:
return []
res = []
que = deque([root])
cnt = 0
while que:
level = []
for _ in range(len(que)):
curr = que.popleft()
level.append(curr.val)
if curr.left:
que.append(curr.left)
if curr.right:
que.append(curr.right)
if cnt%2 == 0:
res.append(level) # 从左到右
else:
res.append(level[::-1]) # 从右到左
cnt += 1
return res3. 二叉树的最近公共祖先 🔗
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:

输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。示例 2:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1提示:
- 树中节点数目在范围
[2, 105]内。 -109 <= Node.val <= 109- 所有
Node.val互不相同。 p != qp和q均存在于给定的二叉树中。
我的题解:
这题乍一看有点懵,弄明白最近公共祖先的判断逻辑之后,想清楚要用递归来做。
• 递归终止条件:当节点为空时返回 None,或者当前节点是 p 或 q 时返回当前节点。
• 递归逻辑:对当前节点的左子树和右子树进行递归查找,得到的结果分别存储在 left 和 right 中。
• 结果判断:如果左右子树都找到目标节点,说明当前节点是最近公共祖先。如果只有一个子树找到目标节点,则返回该子树的结果。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def lowestCommonAncestor(self, root, p, q):
"""
:type root: TreeNode
:type p: TreeNode
:type q: TreeNode
:rtype: TreeNode
"""
# 如果当前节点是空,返回 None
if not root:
return None
# 如果当前节点是 p 或 q,直接返回当前节点
if root == p or root == q:
return root
# 递归查找左子树和右子树
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
# 如果p 和 q在不同分支,说明当前节点是最近公共祖先
if left and right:
return root
# 如果只在左子树找到 p 或 q,返回左子树的结果
elif left:
return left
# 如果只在右子树找到 p 或 q,返回右子树的结果
elif right:
return right
# 如果左右子树都没有找到,返回 None
else:
return None4. 路径总和 🔗
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:
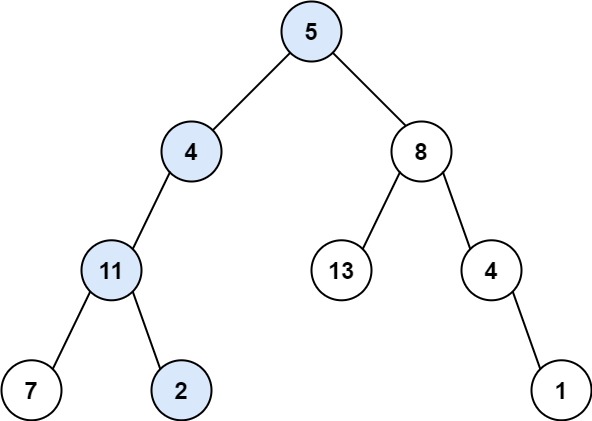
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。示例 2:
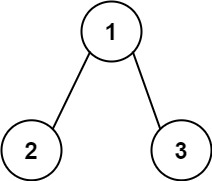
输入:root = [1,2,3], targetSum = 5
输出:false
解释:树中存在两条根节点到叶子节点的路径:
(1 --> 2): 和为 3
(1 --> 3): 和为 4
不存在 sum = 5 的根节点到叶子节点的路径。示例 3:
输入:root = [], targetSum = 0
输出:false
解释:由于树是空的,所以不存在根节点到叶子节点的路径。提示:
- 树中节点的数目在范围
[0, 5000]内 -1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
我的题解:
思路就是通过递归遍历二叉树,每次递归时,将当前节点的值从目标和中减去,目标和随着递归的深入逐渐减少。如果当前节点是叶子节点,并且在递归的过程中,剩余的 targetSum 恰好等于当前节点的值,说明找到了符合条件的路径,返回 True。如果没有找到符合条件的路径,则继续递归到左右子树进行查找。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def hasPathSum(self, root, targetSum):
"""
:type root: TreeNode
:type targetSum: int
:rtype: bool
"""
if not root: # 空节点
return False
if not root.left and not root.right: # 叶子节点
return root.val == targetSum
# 递归检查左右子树
return self.hasPathSum(root.left, targetSum - root.val) or self.hasPathSum(root.right, targetSum - root.val)5. K个一组反转链表 🔗
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]示例 2:
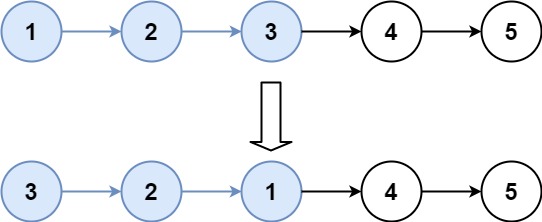
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
我的题解:
第一道困难题,难点其实在于逻辑判断。在纸上画画图,把逻辑理顺再写代码会更好。我的代码看起来还是乱了点,之后看下官方题解重新理一下。
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def getLen(self, head):
curr = head
l = 0
while curr:
l += 1
curr = curr.next
return l
def reverseKGroup(self, head, k):
"""
:type head: ListNode
:type k: int
:rtype: ListNode
"""
if k==1 or head is None:
return head
l = self.getLen(head)
curr = head
nxt = curr.next
pre_tail = None
my_head = None
for group in range(l//k):
curr_tail = curr
curr_tail.next = None
for _ in range(k-1):# k个一组,需要操作k-1次
tmp = nxt.next
nxt.next = curr
curr = nxt
nxt = tmp
if group == 0: # 第一组
my_head = curr
# 不同轮次的首尾连接
if pre_tail:
pre_tail.next = curr
pre_tail = curr_tail
# 切换到下一组
if nxt:
curr = nxt
nxt = nxt.next
if l % k != 0:
pre_tail.next = curr
return my_head


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧