小a的八月每周进展
来了,八月
| 7.29~8.4 | 科研主线 | 运动 | 兴趣 |
|---|---|---|---|
| 周一 | 休息 | 休息 | 休息 |
| 周二 | 了解KAN; | 帕姐拉丁+手臂 | 日语;法语;看硅谷 |
| 周三 | 看UniTTA(针对连续域、时间相关性、类不平衡等场景统一框架,但对目前工作参考不大);看完CLIP-Apt,确定了要用adapter层做微调的想法,细节还没定 | 帕姐dance*2 | 日语;法语;阅读《闭经记》;苔岛岛主的心灵按摩,我爱苔岛!!!🥹 |
| 周四 | 看CLIP-Adapter代码;看TTN:用增广图像模拟分布变化 & 比较梯度来衡量偏移敏感度 | 帕姐dance+腹部 | 日语、法语、意大利语、粤语; |
| 周五 | 看TTN伪代码;看连续学习的文章: | 帕姐哑铃练背 | 日语、法语、意大利语、西语 |
| 周六 | 休息 | 安娜哑铃练手臂 | 日语、法语、西语、意大利语、韩语 |
| 周日 | 整理博客文章笔记 | 哑铃练胸 | 日语、法语、西语、意大利语 |
|
8.5~8.11 |
科研主线 |
运动 |
兴趣 |
|
周一 |
看师姐的UniCon |
拉丁dance;哑铃练臀 |
语言;阅读《闭经记》 |
|
周二 |
看UniCon实验和代码,尤其是loss设计 |
清晨普拉提;腹部;睡前拉伸 |
做桃子汽水,空气炸锅鸡翅娃娃菜;语言;剪辑 |
|
周三 |
看UniMoCo的loss设计,和SupCon的loss比较 |
清晨拉伸 |
剪辑;阅读《闭经记》;语言|去常州爷爷生日 |
|
周四 |
统一UniCon & SupCon损失,从三个角度解释(交叉熵,infoNCE,UniMoCo);看代码;看MixCo和UnMix |
拉丁dance;哑铃练背 |
做莓果汽水;语言;阅读《闭经记》 |
|
周五 |
看代码;跑baseline |
清晨普拉提;哑铃练肩 |
做哈佛浓汤,葡萄汽水;日语 |
|
周六 |
继续跑代码训练 |
dance有氧*2 |
百香果酸奶;日语;看番《我推的孩子》 |
|
周日 |
炼丹ing |
休息 |
语言;看《再见绘梨》 |
7.29~8.4
7.30 周二
🌀到家了,要多多出门学习啊!再坚持一下,你是最棒的!
🌀降低预期,放手去做!
💡KAN的优点是更高效、准确,有更快的收敛速度和scaling laws,直观可视化:可以单独检查学到的单变量函数,了解输入特征在训练过程的每个步骤中如何转换;缺点是训练速度慢,同样参数的情况下比MLP慢十倍。如果主需求是准确率和可解释性,并且能够在训练时间上作出妥协,那KAN是比MLP更好的选择
💡不过似乎KAN目前在现实场景的大数据集上表现很差,作者也在github里说“For users who are machine learning focus, I have to be honest that KANs are likely not a simple plug-in that can be used out-of-the box (yet). Hyperparameters need tuning, and more tricks special to your applications should be introduced.”所以现阶段大概了解下就好,等着大神去优化它再拿来用吧
✅ 看完KAN的博客1和博客2,前者侧重于MLP和KAN的原理和区别,后者给出了完整的训练流程和函数的参数解释。KAN所用定理的本质是每个多变量连续函数都可以用连续单变量函数的总和来表示,非线性的表示方式为B样条曲线。
7.31 周三
🌀七月的尾巴,在家还是不太能习惯
🌀不管怎样,我真的相信自己有学习任何事物的天赋,坚信不疑。我只需要调节心态,更坚韧,持续努力,快速迭代。一定会有很好的回报。
💡看了老板发的UniTTA,针对连续域变化、混合域、时间相关性、类不平衡等现实场景统一了benchmark,通过马尔可夫状态转移矩阵来生成各种现实场景的数据。还提出了一种多功能的UniTTA框架,包括平衡域归一化(Balanced Domain Normalization, BDN)层和相关特征适应(Correlated Feature Adaptation, COFA)方法,以减小领域和类别的分布差距。
💡UniTTA框架:
- 总体框架: 介绍了该框架的总体架构,包括三次前向传播来逐步预测类别标签和领域标签。
- 平衡领域归一化(BDN)层: 介绍了BDN层的核心思想,即通过计算域和类别的统计量来实现无监督的领域归一化,并消除类别偏差。
- 相关特征适应(COFA)方法: 介绍了COFA方法如何利用数据的相关性,通过使用上一个样本的信息来提高预测精度。
💡想法是UniTTA很落地很符合现实,毕竟应用场景比如视频连续帧、传感器数据都是时间强相关的,许多其他TTA论文往往是在同一个域、或单个数据集上做adaptation,很少关注连续适应的问题。包括VLM上的TTA似乎也不常讨论连续域适应问题, 不过VLM也不是在单一域上训练的了
🌟CLIP-Adapter原文里提到的有趣观察:“adapting fine-grained dataset requires more new knowledge than old knowledge, and the case is opposite for generic dataset.”
🌟CLIP-Adapter的bottleneck维数是原始图像特征维数的1/4,消融实验效果最好,可以借鉴
✅Tip-apt之前发的issue,TDA也发下
8.1 周四
✅ 看了CLIP-Adapter的代码实现,不太难,图像特征维数到时候需要再确认一下,可以用Lazy*函数
🌀早期不要想着一步到位,从更简单的的场景开始,边思考边实践,一点点transfer到复杂场景
✅看TTN:在CBN和TBN之间进行线性插值,根据每个BN层对域偏移的敏感性调整插值权重。这种敏感性先验是通过输入干净和增强后的图像,比较它们在BN层仿射参数梯度的余弦距离来确定的。用敏感性先验初始化插值权重并优化它,优化目标包括交叉熵损失和MSE正则化项(防止权重偏离初始值过多)
8.2 周五
✅ 看了TTN方法细节,公式+伪代码才是最清晰直观的
🥹再也不想熬夜了呜呜呜脑子转不动
✅ 看了关于AI模型连续学习(CL,continual learning)的博客:CL希望在保留先前学到知识的同时,能够适应新的任务,其实和clip适应的setting类似。有几类方法:
- 基于正则化,例如在损失函数中添加一个惩罚项,通过考虑参数对之前任务的贡献程度来惩罚参数的变化。
- 基于重放,侧重于恢复一些历史数据,比如在训练新任务时添加旧任务中的一些样本,使模型暴露于新旧任务类型的混合中,从而限制灾难性遗忘。局限在于可能无法访问历史数据。
- 基于优化,希望操纵优化方法来维持所有任务的性能,例如gradient projection是一种投影为新任务计算的梯度,以避免影响先前梯度的方法。
- 基于表征,获取鲁棒的特征表示,如通过自监督学习学到具有良好泛化能力的高质量特征
- 基于架构,如参数分配,在训练过程中,每个新任务都会在模型中被赋予一个专用子空间,从而消除了参数破坏性干扰的问题。然而,模型规模将随着新任务的数量而增长。
基于优化的方法中有个概念是梯度投影 & 识别重要参数方向 :

🌟这篇博客也提到一个很重要的点:当新样本可用或分布发生显著变化时,需要更新模型。持续学习可以通过仅更新受新样本影响的部分,而不是从头开始重新训练来提高此过程的效率。也就是有选择性的更新,固定那些general的部分,更新那些新任务相关的参数。but specifically how?
8.4 周日
🌀纪念一下回家之后第一次在家学习!嘿嘿所以周末/太热的时候可以带耳机在家学,工作日出门!
✅ 补了一下博客笔记,啧,半夜想把这周进展更新到notion上直接卡死
8.5~8.11
👩🔬周科研主线:着手做实验
南航会议9月8日截稿
💁♀️本周主题:结果导向,一次只做一件事
8.5 周一
✅看师姐的UniCon文
🌟原文:一些研究尝试将对比学习和Mixup结合起来,方法包括设计InfoNCE损失的Mixup版本 [21] ,或者简单地将InfoNCE损失和Mixup风格的交叉熵损失相加[22]。MoCHi [23]仅对memory bank中的困难负样本应用Mixup,以获得更多且更困难的负样本。然而,这些方法更多地关注于软化(softening)对比学习,而不是创新Mixup策略,忽视了Mixup产生负样本的内在潜力。
📚UniCon提出了一种基于MIU的监督对比学习方法,将Mixup生成的universum样本视为全局困难负样本,从而减小对比学习中对大批量样本的需求。
相关的SupCon方法把对比学习用在有监督场景下,对比损失中把同类样本都作为正样本。
UniCon设计了两种损失函数,其中L_add方法效果不理想,比不引入universum负样本loss效果还差,原因可能是:1-流形入侵,生成的混合样本更接近其中一个类别的样本;2-过度关注负样本,特别是universum负样本,导致训练过程中的不平衡,使得模型对正样本的学习不足。正样本提供的是类内一致性的信息,过于干净的正样本无法帮助模型处理含有噪声的负样本。
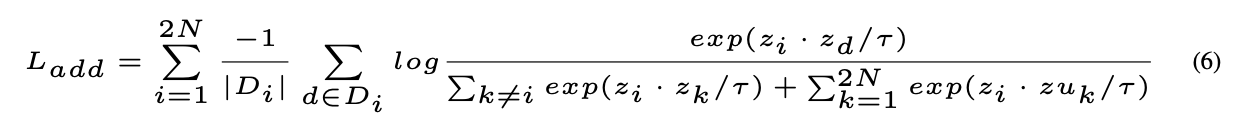
L_UniCon完全基于universum框架,universum数据既用于负样本对比,也用于推导类中心,效果更好。(所以这里生成类中心,是用了当前batch所有同类别样本生成的universum?✔️也会受到batch-size影响吧!看代码)

UniCon模型的无监督版本使用批次中样本的索引作为它们的伪标签。这里只有两个数据点来生成类中心,所以L_contrast是必要的。
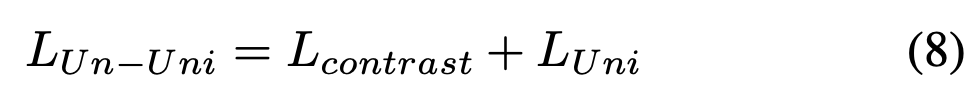
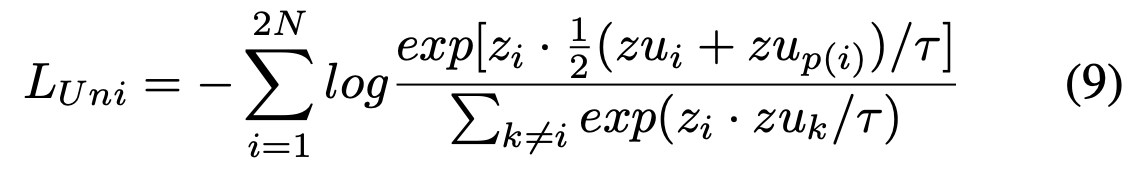
8.6 周二
🌀UniCon和SupCon的loss看着好费劲,花了半天,后面发现是参考了StableRep 论文的交叉熵对比loss设计:


✅ UniCon正负样本:负样本是batch内除了自身外、所有其他样本生成的universum,也就是2N-1个负样本;正样本是batch内除了自身外、所有同类样本生成的universum均值,也就是2N个正样本。
其实有奇怪为什么要除去当前样本的universum,完全没必要。看了下代码发现是从SupCon“移植”过来的,难怪…👩💻可尝试:只进行一次增广/ N个正样本/ 包含当前样本的universum(mask 对角线不置0)
👩💻IDEA:用不同类中心去生成新的universum负样本,或是其他类的类中心也能做负样本;正样本直接用同类样本而不是universum来做;正样本用同类样本+同类universum?
🤔❓对比学习里的负样本是hard一点好,还是general一点好?
✅ logits = outputs - outputs.logsumexp(dim=-1, keepdim=True)
log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))
都使用了减法操作来实现数值稳定的 softmax,logsumexp效果更好
✅ SupCon负样本只排除了自对比,仍然包含anchor同类样本吗?这个issue回答了问题并且引入有趣的视角,提到了UniMoCo方法
8.7 周三
✅ 看UniMoCo,维护特征/标签队列和统一对比损失,实现了从单一正样本对到多个正样本对的扩展。loss设计和SupCon不同(3.3节和4.5节),在负样本中把同类样本也排除了👉gpt读
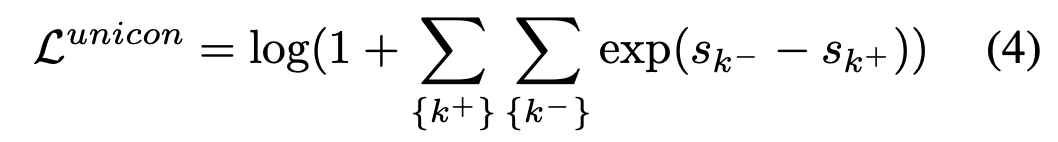
💡InfoNCE可以看作正样本标记为1,其他为0的交叉熵损失,难怪log项分母上要同时包含正负样本,其实就是一个softmax预测概率
🌀看了代码会发现其实师姐的UniCon损失和SupCon是一样的,只是一个用universum,一个用增广视图;但是推了遍公式确实可以等价(点积具有分配律),神奇
8.8 周四
🌟不管是UniCon还是SupCon的损失(本质上一样,只是用来对比的一个是universum,一个是增广视图),都可以看为两种形式:交叉熵 & infoNCE对比损失。视为infoNCE,正样本是对比样本中的同类均值(即近似的类中心,那么样本数量越多、质量越高,结果越准确);视为CE,可理解为“寻找”正类(universum),过程中学到更鲁棒的特征
👩💻既然两个本质上一样,而UniMoCo效果比SupCon好,那或许也可以试试用UniMoCo + universum来做,并且UniMoCo loss的log里可以试试不要+1
🌀看UniCon代码:
训练阶段 encoder 特征+ projection head 到对比空间,256 bs 跑1000 epochs;
评估阶段encoder特征+分类头,分类头训练 512 bs 跑100epochs
直接用images做mixup;🌟可以试试用特征来做mixup
✅ 看了MixCo,loss形式就是LossMix,或者说“软化”的对比损失,效果不错
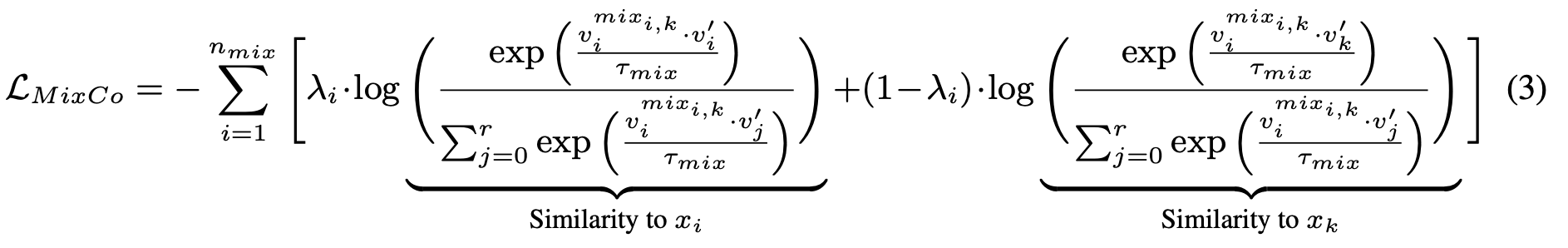
✅ UnMix 也是LossMix,但形式上更巧妙,同一批次数据通过倒序匹配来self-mixture;
SupCon + UnMix引入了同类样本都为正样本的概念,其他不变,效果提升很明显
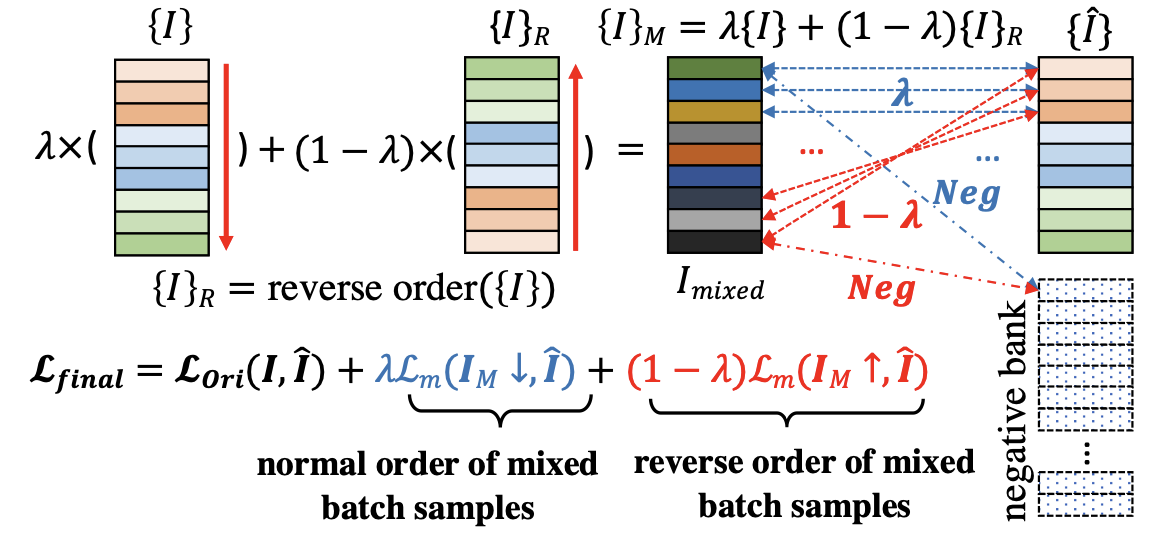
8.9 周五
🌀这篇CVPR2021文指出,对比损失中的温度系数控制着对困难负样本的惩罚力度。较小的温度会对困难负样本施加更大的惩罚,模型倾向于将这些负样本推得更远,从而使它们与正样本更容易区分开来;而较大的温度则使损失函数对困难负样本的敏感性降低,导致这些样本在特征空间中不会被强制推远,特征空间中的样本分布可能会变得更松散。
🌀训练真是费老劲了…1000epoch实在太耗时。要不直接拿imagenet预训练好的resnet50微调吧!感觉累疯球了
💡模型保存和加载看这篇,单卡/多卡写得很详细
本周进展8.12~8.18
|
8.12~8.18 |
科研主线 |
运动 |
兴趣 |
|
周一 |
看文思考 |
清晨普拉提;哑铃练臂肩 |
语言; |
|
周二 |
弄清AETTA和SwAV |
清晨普拉提;站立练腹 |
语言;阅读《闭经记》 |
|
周三 |
回看TENT实验setting |
哑铃练胸 |
语言;阅读《闭经记》 |
|
周四 |
看COTTA |
哑铃臀腿30m+拉伸10m |
语言;买咖啡用具 |
|
周五 |
周四没睡好,休息 |
跳舞10m+哑铃练上肢30m |
语言;做酸奶蓝莓冻 |
|
周六 |
COTTA代码和附录 |
休息 |
语言;做泡沫咖啡 |
|
周日 |
跑COTTA代码 |
舞10m+臀腿20m+腹10m |
语言;做冰拿铁 |
👩🔬周科研主线:定setting,做实验
南航会议9月8日截稿
💁♀️本周主题:快速迭代,劳逸结合
8.12 周一
🌟clip-apt的思路反过来,如果adapter和原模型的预测分布不一致程度高,或许就说明原域和测试域的语义gap大!
比如利用dropout inference或数据增强图像之间的概率分布一致程度来衡量是否出现“幻觉”
可以用平均余弦相似度来衡量分布之间的一致程度;用平均熵(并过滤低熵
❓TTN又是在干嘛?为啥可以用梯度来衡量?(看扰动 结合
❓对比学习微调编码器学特征,之后做分类任务,分类头需要重新训练吗
🤔原图裁剪-原编码器-弱增广 色彩抖动-动量编码器-2个强增广 模拟分布变化 评估logits差异?
(然后自监督对比学习来调节adapter?)继续看ada contrast & moco
8.13 周二
✅看SwAV方法和伪代码,核心是将图像的不同视图进行在线聚类分配,并交换预测这对视图在聚类中的分配
✅AETTA的本质是通过比较模型输出与dropout inference输出之间的不一致性来估计当前批次的平均预测准确率。依赖dropout independence的前提假设,即同一个模型在不同的dropout推理过程中的输出是独立的,且在整体分布上与原模型一致。(dropout次数N=10,bs=64,dropout rate为 0.4/ 0.3/ 0.2 for 10/ 100/ 1000类)
🌀AETTA可以用来评估TTA过程是否出现failure,但似乎无法评估单测试样本的预测置信度(bs=1);有点好奇dropout系数和bs哪个对结果影响更大

🌀REALM:当模型在新数据分布上进行预测时,如果遇到与训练数据分布差异很大的样本,模型可能会对这些样本的预测非常不确定,导致高熵。(所以不确定性也可以用来衡量语义gap)模型可能会因这些不可靠的高熵样本而进行过度调整,使得模型偏离原有的训练分布。尤其是在单样本更新的情况下,一个高熵样本的影响可能会非常大,导致模型参数在错误的方向上调整。
🌀AdvPerturb:通过计算adapted模型和源模型之间的一致性来估计OOD准确率,其中在测试批次上应用对抗性扰动,以惩罚决策边界附近的不确定样本。需要注意的是,原始论文的目标是预测源模型的准确率
8.14 周三
🌀回看TENT:如果在表示层上定义损失,那么更新将需要更少的前向和后向计算。(对比学习就是表示层损失)
- 熵损失可能与校准(calibration)相互作用,因为更好的不确定性估计可以推动更好的适应。(可以和AETTA一类的OOD不确定性/准确性估计方法结合,不确定性高(语义gap大)就用更多新知识,OOD不确定性低(语义gap小)就用更多原来的知识
- 而且这边的alpha好像不是针对样本,而是针对数据集而言的!如果能自适应调整alpha的话,是不是可以针对batch/样本来做呢
🌟从TTN的可视化结果来看,模型浅层对域偏移更加敏感,也就是浅层TBN用更多、深层CBN用更多。可能是因为深层提取到的是语义信息,而浅层提取到的是样式信息,和域偏移直接挂钩;那么adapter是不是可以放在编码器前面?理念或许类似Prefix-Tuning
🌀test-batch越小,用原域统计量CBN就越好(这时候算出来的TBN完全无法代表目标域统计量;但预测logits什么的不一定)
🌟robust bench好像有预训练好的模型啊啊啊救我一命啊啊啊TT (以下来自CoTTA
- CIFAR10-to-CIFAR10C: WideResNet-28-10 in RobustBench
- CIFAR100-to-CIFAR100C: ResNeXt-29 (AugMix
- ImageNet-to- ImageNet-C: standard pre-trained resnet50 model in RobustBench
8.15 周四
🤔低熵过滤+平均熵最小化微调adapter?以及adapter放在编码器前面(加不加残差连接之后再考虑吧!
🌀TTA的分类头需要调整吗,还是只调节编码器?起码tent用的source模型是编码器和分类头都训练好的,adaptation过程不需要调整分类头;
🌟来自CoTTA:“我们考虑了测试时的域偏移,并通过预测置信度来近似域差异,只有在域差异较大时才应用增强,以减少错误累积。通过使用预训练模型计算当前输入的预测置信度(如公式4),我们试图近似估计源域与当前目标域之间的差异。我们假设,较低的置信度表明域差异较大,而相对较高的置信度则表明域差异较小。” 所以用置信度/不确定性来评估域gap是合理的!
这里置信度高的情况,直接用教师模型预测输入,其实类似用原域模型预测,因为动量更新的系数很大0.999,保留了大量原域知识,和之前clip-adapter的alpha系数类似。这边的动量更新教师模型也可以看成是时间集成模型
但这里有个关键问题,用原域模型的预测置信度来判断domain gap是危险的,如果原域模型没有well-calibrated的话,可能会出现“过度自信”(overconfidence)现象,虽然置信度高,但模型的预测可能完全不准确。这会导致错误的判断,认为当前输入与源域数据分布接近,实际上却可能存在较大的域差异。
这时候就可以结合AETTA里的dropout inference,对目标域样本多次进行推理,通过计算不同推理结果,如果方差较大,说明模型对该样本的预测不确定性较高,可能存在较大的域差异。GPT推荐使用 0.1 到 0.3 之间的 Dropout 率,并进行 10 到 30 次推理,用平均预测熵或方差来衡量不确定性(比如平均熵/最大熵,阈值0.5判断,或者0.8~1不一致,0~0.2较一致)
或者我能不能直接最小化dropout平均预测熵啊?或者和数据增强结合
🌀“过滤步骤至关重要,因为我们观察到,对具有高置信度且域差异较小的样本应用随机增强,有时会降低模型性能。” 这个也很有意思,这种下降可能是因为增强后的样本偏离了真实分布,或者引入了不必要的噪声,从而导致模型对这些样本的预测变得不稳定。
✅ 记录和GPT关于不确定性估计的种种问题
8.17 周六
🌀来自TTN:“As shown in Table 4 and 6, CBN employing source statistics is superior to TBN when the distribution shift between source and target domains is small.” 现在有点纠结要不要用TBN,但bs=1的时候明显用CBN好吧
🥹原来CoTTA不是单样本做adaptation来的…大失望
🌀来自CoTTA附录:如果用TENT做连续适应但更新所有参数,错误率从20.7上升到90.0,但如果固定最后一层并调低100倍学习率,错误率下降到19.8,好神奇
🌀看文《Predicting with Confidence on Unseen Distributions》,提出用原域-目标域的平均置信度差异(DoC)和平均熵差异(DoE)来做准确性估计
8.18 周日
🌀跑通COTTA
[24/08/18 10:50:02] [cifar10c.py: 57]: error % [gaussian_noise5]: 24.36%
[24/08/18 10:50:02] [cifar10c.py: 50]: not resetting model
[24/08/18 10:53:11] [cifar10c.py: 57]: error % [shot_noise5]: 21.73%
[24/08/18 10:53:11] [cifar10c.py: 50]: not resetting model
[24/08/18 10:56:20] [cifar10c.py: 57]: error % [impulse_noise5]: 26.18%
[24/08/18 10:56:20] [cifar10c.py: 50]: not resetting model
[24/08/18 10:59:28] [cifar10c.py: 57]: error % [defocus_blur5]: 11.85%
[24/08/18 10:59:28] [cifar10c.py: 50]: not resetting model
[24/08/18 11:02:37] [cifar10c.py: 57]: error % [glass_blur5]: 27.11%
[24/08/18 11:02:37] [cifar10c.py: 50]: not resetting model
[24/08/18 11:05:45] [cifar10c.py: 57]: error % [motion_blur5]: 12.14%
[24/08/18 11:05:45] [cifar10c.py: 50]: not resetting model
🌀试图把bs设为1但好像要很久
本周进展8.19~8.25
|
8.19~8.25 |
科研主线 |
运动 |
兴趣 |
|
周一 |
写PACE代码 |
普拉提;哑铃练肩臂 |
做葡萄气泡水;语言 |
|
周二 |
写代码,改bug |
休息 |
做西瓜奶昔;语言 |
|
周三 |
跑实验 |
哑铃练胸背;Afro+Hiphop |
做梨子气泡水;语言 |
|
周四 |
跑实验 |
自由拳击+举铁 |
语言;看脱口秀 |
|
周五 |
看文 |
经期有氧30m |
语言;做牛油果奶昔 |
|
周六 |
CBN小实验 |
🐳dance;经期拉伸 |
语言;做冰葡美式 |
|
周日 |
看AdaIN,做实验 |
哑铃练上肢 |
语言;做空气炸锅土豆片 |
👩🔬周科研主线:做实验验证想法
南航会议9月8日截稿
💁♀️本周主题:积极运动,保证睡眠
8.19 周一
🌀学到了,在 eval() 模式下,BN层会使用在训练时计算的均值和方差,而不是当前批次的统计数据;Dropout 层不会在前向传播中随机丢弃神经元,但仍然可以对模型进行反向传播计算并使用优化器更新参数
🤯想用COTTA测试dropout一致性的想法,但阈值的选择有点头疼…先用这个和AETTA结合吗...不过多次dropout可以用输入的广播矩阵来做,就不用for循环了,应该可以加速吧
✅ 设计dropout和adapter WRN网络结构,修改dropout inference和batch预测准确率估计的代码
8.20 周二
✅ 初版代码写完,疯狂debug
✅ 测试模型在train/eval模式下对BN层统计量的影响,修改代码
8.21 周三
✅ 设计下模型不同模式对dropout层的影响实验、根模块及Adapter层模块实验
✅让gpt完整看下代码逻辑,找错
✅ 跑实验(终于跑起来了…
🌀晕一直以为自己用的CBN结果不是…终于把模型eval、train模式和BN层、dropout层的关系搞懂了,警惕!(以及eval不影响梯度更新)
==========================================================
BS=200 / LR=1e-3 / N_ITER=5 / REDUCTION=4 / TBN但source inference用了CBN / Not resetting
[24/08/21 08:19:19] [cifar10c.py: 60]: error % [gaussian_noise5]: 28.16%
[24/08/21 08:23:10] [cifar10c.py: 60]: error % [shot_noise5]: 25.50%
[24/08/21 08:27:00] [cifar10c.py: 60]: error % [impulse_noise5]: 35.68%
[24/08/21 08:30:51] [cifar10c.py: 60]: error % [defocus_blur5]: 12.71%
[24/08/21 08:34:42] [cifar10c.py: 60]: error % [glass_blur5]: 34.38%
[24/08/21 08:38:34] [cifar10c.py: 60]: error % [motion_blur5]: 13.93%
[24/08/21 08:42:25] [cifar10c.py: 60]: error % [zoom_blur5]: 11.89%
[24/08/21 08:46:17] [cifar10c.py: 60]: error % [snow5]: 17.31%
[24/08/21 08:50:08] [cifar10c.py: 60]: error % [frost5]: 17.29%
[24/08/21 08:54:00] [cifar10c.py: 60]: error % [fog5]: 15.03%
[24/08/21 08:57:52] [cifar10c.py: 60]: error % [brightness5]: 8.41%
[24/08/21 09:01:43] [cifar10c.py: 60]: error % [contrast5]: 12.51%
[24/08/21 09:05:35] [cifar10c.py: 60]: error % [elastic_transform5]: 23.34%
[24/08/21 09:09:26] [cifar10c.py: 60]: error % [pixelate5]: 19.41%
[24/08/21 09:13:18] [cifar10c.py: 60]: error % [jpeg_compression5]: 27.21%
Avg_loss : 20.184
==========================================================
BS=200 / LR=1e-3 / N_ITER=5 / REDUCTION=2 / TBN 但source inference用了CBN/ Not resetting
Avg_loss:20.22867
==========================================================
跑了版都用TBN的,看起来差不多就没继续跑了
BS=200 / LR=1e-3 / N_ITER=5 / REDUCTION=4 / TBN / Not resetting
[24/08/21 18:16:43] [cifar10c.py: 60]: error % [gaussian_noise5]: 27.77%
[24/08/21 18:20:40] [cifar10c.py: 60]: error % [shot_noise5]: 25.89%
[24/08/21 18:24:39] [cifar10c.py: 60]: error % [impulse_noise5]: 36.07%
[24/08/21 18:28:37] [cifar10c.py: 60]: error % [defocus_blur5]: 12.73%
[24/08/21 18:32:36] [cifar10c.py: 60]: error % [glass_blur5]: 34.92%
[24/08/21 18:36:34] [cifar10c.py: 60]: error % [motion_blur5]: 14.14%
8.22 周四
🌀改成CBN之后又出问题,排查bug到半夜…发现平均熵算出来很小,但err似乎没有问题,不知道怎么个事儿
(但是直接用err做adapter_ratio错误率还是非常非常高啊啊啊为什么为什么?!到底是哪里出问题了啊啊啊啊
💡TBN + 更新BN的话,还可以利用err估计来随机恢复参数(CoTTA或AETTA的方法
==========================================================
消融:TBN & 在分类头后再mixup,效果也是差不多
BS=200 / LR=1e-3 / N_ITER=5 / REDUCTION=4 / TBN / Not resetting
[24/08/22 07:35:51] [cifar10c.py: 60]: error % [gaussian_noise5]: 27.77%
[24/08/22 07:39:51] [cifar10c.py: 60]: error % [shot_noise5]: 25.91%
[24/08/22 07:43:50] [cifar10c.py: 60]: error % [impulse_noise5]: 36.07%
8.23周五
✅看TTMA,通过测试数据和不同类别随机采样的训练数据mixup做预测,然后反推测试数据的标记。把所有推断的软标签转换为硬标签,通过多数投票确定测试标签,然后计算所有推断标签直方图的熵来估计数据不确定性。(这个方法我用不了,拿不到训练数据)(实验部分对比方法用了test-time aug和MCdropout,MCDO的结果看起来好糟糕我好慌==
💡能不能换个角度,source不一定要保留原域知识,但需要学习更general的东西,而adapter去灵活学习那些task- specific的知识=》持续学习可以通过仅更新受新样本影响的部分,而不是从头开始重新训练来提高效率。也就是有选择性的更新,固定那些general的部分,更新那些新任务相关的参数。
8.24周六
🌀测试了下,原来不是CBN做dropout inference出来的置信度太低,而是over- confident(置信度能有0.9+但实际准确率非常低)…所以熵才会那么低。那纯CBN做肯定是不行了,需要换思路
8.25周日
🌟AdaIN论文提出了一个新颖的解释,即IN能够通过归一化特征统计量来实现风格归一化。具体来说,卷积神经网络的特征统计量(如通道的均值和方差)被认为可以捕捉图像的风格信息。因此,IN通过归一化这些统计量来调整图像的风格。AdaIN在特征空间中通过转移特征统计量(特别是通道均值和方差)来进行风格迁移。
🌟BN倾向于将一批样本的特征统计量归一化到一个中心风格,这对于希望将所有图像转移到相同风格的任务来说是不理想的。而IN则能够将每个样本的风格归一化到目标风格,这对于风格迁移任务更为合适。通过这种方式,网络可以专注于内容的操作,而不必再去处理原始的风格信息。不同的仿射参数可以将特征统计量归一化为不同的值,从而将输出图像归一化为不同的风格。
🤔mixup也是一种样式和内容的mixup,或许也可以从统计量的角度去看、去改进
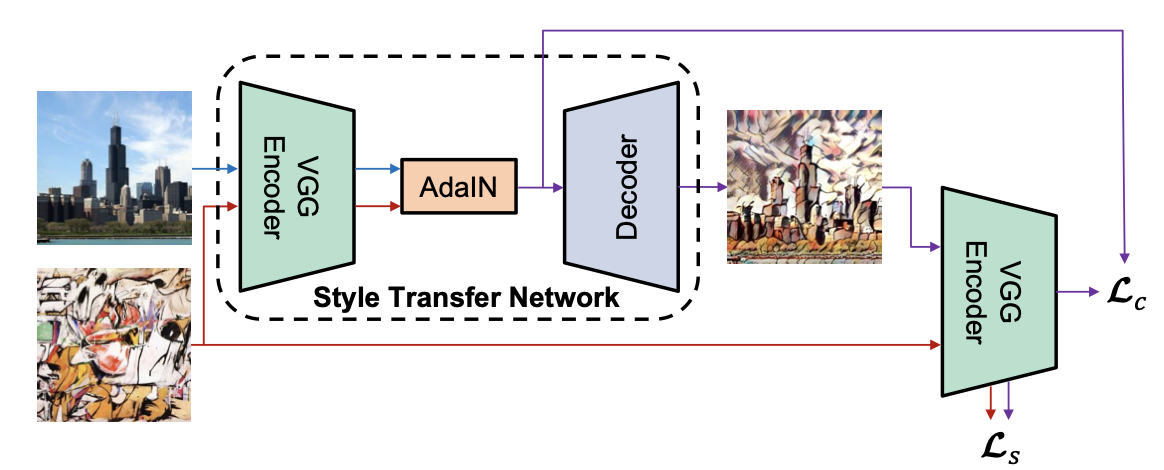

本周进展8.26~9.01
|
8.26~9.01 |
科研主线 |
运动 |
兴趣 |
|
周一 |
跑TBN/IN实验 |
帕姐dance+拉伸 |
语言;柠檬美式 |
|
周二 |
读AdaBN;跑IN实验 |
普拉提+tabata |
语言 |
|
周三 |
嘎嘎跑实验 |
哑铃练胸 |
语言;牛油果芒芒;番茄牛肉面 |
|
周四 |
跑实验;休息 |
拉伸+dance+腹肌撕裂者 |
语言;吃三文鱼喝精酿 |
|
周五 |
看BN相关文 |
休息 |
语言 |
|
周六 |
跑实验 |
普拉提+内啡肽三部曲 |
语言 |
|
周日 |
休息 |
哑铃练肩 |
语言;看各类采访 |
👩🔬周科研主线:优化实验,着手论文
💁♀️本周主题:给自己空间、信任和爱❤️
8.26 周一
✅做TBN/IN/CBN不同层的消融实验,观察到block1和block2的layer0-1、block3的layer0更多是样式相关,block3的layer0之后更多是内容语义相关
==========================================================
📊 全用TBN(0.24),部分BN换成IN
|
block1.layer0 |
0.31 |
block1.layer1 |
0.25 |
|
block1.layer2 |
0.22 |
block1.layer3 |
0.23 |
|
block2.layer0 |
0.34 |
block2.layer1 |
0.23 |
|
block2.layer2 |
0.26 |
block2.layer3 |
0.24 |
|
block3.layer0 |
0.39 |
block3.layer1 |
0.25 |
|
block3.layer2 |
0.25 |
block3.layer3 |
0.24 |
|
block1 |
0.32 |
Block2 |
0.39 |
|
Block1-2 |
0.43 |
block3 |
0.53 |
📊 全用CBN(0.71),部分BN换成IN
|
block1.layer0 |
0.62 |
block1.layer1 |
0.69 |
|
block1.layer2 |
0.70 |
block1.layer3 |
0.72 |
|
block2.layer0 |
0.52 |
block2.layer1 |
0.63 |
|
block2.layer2 |
0.66 |
block2.layer3 |
0.69 |
|
block3.layer0 |
0.54 |
block3.layer1 |
0.68 |
|
block3.layer2 |
0.71 |
block3.layer3 |
0.71 |
|
block1 |
0.61 |
Block2 |
0.54 |
|
Block1-2 |
0.47 |
block3 |
0.53 |
|
Block1 & block2.layer0 |
0.41 |
Block1-2 & block3.layer0 |
0.51 |
|
block1-3 |
0.53 |
|
|
8.27 周二
🌀看了2016版的AdaBN,核心观点是“BN层的统计数据包含域特征”。方法就是简单的把目标域所有图像都一起输入网络,计算每一层输出的统计量;在推理的时候把BN层统计量换成目标域的,保持仿射参数不变。类似TBN的global版。“We hypothesize that the label related knowledge is stored in the weight matrix of each layer, whereas domain related knowledge is represented by the statistics of the Batch Normalization (BN) [7] layer. Therefore, we can easily transfer the trained model to a new domain by modulating the statistics in the BN layer. ”
🌀看了2020版的AdaBN,嗯这才是我要的,CBN和TBN的mix,就是有点复杂…
==========================================================
📊 Pace TBN 交叉熵+熵最小化 优化adapter
[24/08/27 01:37:27] [cifar10c.py: 60]: error % [gaussian_noise5]: 27.72%
[24/08/27 01:38:03] [cifar10c.py: 60]: error % [shot_noise5]: 25.87%
[24/08/27 01:38:40] [cifar10c.py: 60]: error % [impulse_noise5]: 35.95%
[24/08/27 01:39:16] [cifar10c.py: 60]: error % [defocus_blur5]: 12.72%
[24/08/27 01:39:53] [cifar10c.py: 60]: error % [glass_blur5]: 34.86%
[24/08/27 01:40:29] [cifar10c.py: 60]: error % [motion_blur5]: 14.13%
[24/08/27 01:41:05] [cifar10c.py: 60]: error % [zoom_blur5]: 12.15%
[24/08/27 01:41:42] [cifar10c.py: 60]: error % [snow5]: 17.27%
[24/08/27 01:42:18] [cifar10c.py: 60]: error % [frost5]: 17.36%
[24/08/27 01:42:55] [cifar10c.py: 60]: error % [fog5]: 15.19%
[24/08/27 01:43:31] [cifar10c.py: 60]: error % [brightness5]: 8.39%
[24/08/27 01:44:07] [cifar10c.py: 60]: error % [contrast5]: 12.61%
[24/08/27 01:44:44] [cifar10c.py: 60]: error % [elastic_transform5]: 23.49%
[24/08/27 01:45:20] [cifar10c.py: 60]: error % [pixelate5]: 19.52%
[24/08/27 01:45:57] [cifar10c.py: 60]: error % [jpeg_compression5]: 27.21%
Avg_loss : 20.296
8.28 周三
✅ 试了AETTA那个移动平均,‘updated = est_ema_dropout * 0.6 + updated * 0.4’,效果一般
✅ 试了TBN+只更新前几个BN层的参数,效果好;前TBN后CBN效果不行;加上交叉熵损失,效果不如直接熵最小化
✅ 试了Pace只用熵最小化,不用Aug和交叉熵,效果很差
✅ 试了余弦退火给予不同层BN不同的更新权重,得换个函数
✅ 看下“只更新浅层BN参数”在更复杂的数据集是否仍然适用(适用的!
==========================================================
📊TENT更新block1和block2参数/cifar10/TBN/ bs=200/熵最小化
[24/08/28 16:14:21] [cifar10c.py: 60]: error % [gaussian_noise5]: 25.38%
[24/08/28 16:14:31] [cifar10c.py: 60]: error % [shot_noise5]: 19.50%
[24/08/28 16:14:40] [cifar10c.py: 60]: error % [impulse_noise5]: 27.54%
[24/08/28 16:14:50] [cifar10c.py: 60]: error % [defocus_blur5]: 12.11%
[24/08/28 16:15:00] [cifar10c.py: 60]: error % [glass_blur5]: 28.82%
[24/08/28 16:15:09] [cifar10c.py: 60]: error % [motion_blur5]: 13.06%
[24/08/28 16:15:19] [cifar10c.py: 60]: error % [zoom_blur5]: 10.60%
[24/08/28 16:15:29] [cifar10c.py: 60]: error % [snow5]: 14.79%
[24/08/28 16:15:38] [cifar10c.py: 60]: error % [frost5]: 13.77%
[24/08/28 16:15:48] [cifar10c.py: 60]: error % [fog5]: 12.66%
[24/08/28 16:15:58] [cifar10c.py: 60]: error % [brightness5]: 7.98%
[24/08/28 16:16:07] [cifar10c.py: 60]: error % [contrast5]: 10.45%
[24/08/28 16:16:17] [cifar10c.py: 60]: error % [elastic_transform5]: 19.56%
[24/08/28 16:16:27] [cifar10c.py: 60]: error % [pixelate5]: 13.85%
[24/08/28 16:16:36] [cifar10c.py: 60]: error % [jpeg_compression5]: 19.09%
Avg:16.61
📊TENT更新block1和block2参数/cifar10/TBN/ bs=200/交叉熵
Avg:17.92
📊TENT更新block1和block2参数/cifar10/TBN/ bs=200/熵最小化+交叉熵(1:1)
Avg:17.41
📊TENT更新block1和block2参数/cifar10/TBN/ bs=200/熵最小化+交叉熵(1.5:1)
Avg:17.30
==========================================================
📊TENT余弦退火更新BN层参数/cifar10/TBN/ bs=200/熵最小化/reset?
Avg:20.41
📊TENT余弦退火更新BN层参数/cifar10/TBN/ bs=200/熵最小化+交叉熵(1.5:1)
Avg:26.83
==========================================================
📊TENT更新stage3前的参数/cifar100/bs=200/熵最小化
Avg:31.01
📊TENT更新stage3前的参数/cifar100/bs=200/熵最小化+交叉熵(1:1)
Avg:30.68
📊TENT更新stage3前的参数/cifar100/bs=200/熵最小化+交叉熵(1.5:1)
Avg:30.66
8.29 周四
🌀余弦退火效果不行,需要换成tanh之类的;
🌀最前面IN层优化也不行,之前试了个block1的BN换成IN效果也不好,不想试IN了
✅ 试了PACE的优化
==========================================================
📊 Pace TBN 交叉熵+熵最小化 优化adapter(bias=False)
Avg_loss : 20.296
📊 Pace TBN 交叉熵+熵最小化 优化adapter(bias=True)
Avg_loss : 20.298
📊 Pace TBN 交叉熵 优化adapter(bias=True)
Avg_loss : 20.30
8.30 周五
🌀守护进程https://www.autodl.com/docs/daemon/
🌟“Based on domain adaptation theory (Ben-David et al., 2010), the domain shift can be reflected by the error of the ideal target hypothesis based on the target representations learned by source model.”
🌟TTN:“we can conjecture that CBN is more active (i.e., α closer to 0) in deeper layers because domain information causing the distribution shift has been diminished. In contrast, TBN has a larger weight (i.e., α closer to 1) in shallower layers since the domain information induces a large distribution shift. This interpretation is consistent with the observations of previous studies (Pan et al., 2018; Wang et al., 2021; Kim et al., 2022a) that style information mainly exists in shallower layers, whereas only content information remains in deeper layers.”
🌟 我发现这一类调节BN统计量但不更新参数的方法都具备不错的few-shot adaptation能力。猜测是仅调整BN统计量避免了参数更新带来的过拟合风险
✅ 看了ECB方法,将ViT与CNN结合,Finding to Conquering阶段通过最大化和最小化两个分类器之间的差异来定义类特定的边界,并优化目标特征的聚类。Co-training阶段ViT和CNN分支互相生成伪标签以进行交叉学习,进一步缩小知识差距,提高模型对无标签目标数据的泛化能力。
✅ 看UBNA方法,核心是动量更新BN层的统计量:适应开始时,BN统计参数(均值和方差)初始化为预训练阶段的全局值;在适应阶段,动量更新每个批次的均值和方差。为了逐步适应目标域,动量采用时间指数衰减的形式;以及BN层在不同深度的域偏移程度可能不同,因此还引入了层级权重动量衰减调整。“This also follows the idea to further improve the trade-off between adapting to the target domain (with the initial layers) and keeping the task-specific knowledge learned during pre-training in the source domain (in the later layers).”
🌀TTN用的AdaBN参数:In detail, we set N as 256, 128, 64, 32, and 16 for test batch size 200, 64, 16, 4, 2, and 1, which yields α as 0.44, 0.33, 0.2, 0.11, 0.06, and 0.06, respectively.
🌀TTN发现channel-wise的插值权重是最优的(优于layer-wise),并且如果是固定权重的话,在cifar-10C上bs=200时固定权重为0.3(TBN占比)效果最好。
🌀这几篇都是把CBN和TBN结合,其中UBNA是用动量更新的方式逐渐适应目标域,并且动量权重随着适应批次的增加和层深度的增加衰减(TBN带来的影响变小);AdaBN每层的插值系数都是固定的n/(N+n) ,并且目标域统计量只用当前批次的值,不会随着适应过程动量更新;α-BN也是每层插值权重固定,分类任务α为0.9(原域占比),并且更新仿射参数;TTN根据每个BN层对域偏移的敏感度进行插值,其中插值权重是在post-training阶段针对每个BN 层的每个通道分别学到的。(MixNorm不想看了)
8.31 周六
✅ 继续跑BN层实验
==========================================================
📊 AdaBN方法(N/(N+n))
Avg:20.61
📊 Constant-alpha(0.7)
Avg:21.88
==========================================================
📊 余弦退火alpha 插值
Avg:20.44
📊 余弦退火alpha * decay 0.02 插值
20.45
📊 余弦退火alpha * decay 0.03 插值
Avg:20.46
📊 余弦退火alpha 插值 所有仿射参数可学习 熵最小化
结果特别差,到后面错误率直线上升到89%了
📊 余弦退火alpha 插值 block1仿射参数可学习 熵最小化
Avg:19.70
📊 余弦退火alpha 插值 block1-2仿射参数可学习 熵最小化
Avg:20.85
==========================================================
📊 余弦退火alpha 插值+ BN层余弦退火更新权重+所有仿射参数可学习
结果特别差,到后面错误率直线上升到87%了
📊 余弦退火alpha插值+ BN层余弦退火更新权重+block1可学习
Avg:19.72
📊 BN层余弦退火更新权重+所有仿射参数可学习
Avg:20.41
📊 BN层余弦退火 * decay 0.03更新权重+所有仿射参数可学习
Avg:21.11
📊 BN层余弦退火更新权重+block1仿射参数可学习
Avg:17.546 (Avg:17.556 w/o)
📊 BN层余弦退火更新权重+block1-2仿射参数可学习
Avg:16.6067 (Avg:16.61 w/o)
📊 BN层余弦退火更新权重+block1-3仿射参数可学习
Avg:18.7147(Avg:18.50 w/o)
本周进展9.02~9.08
|
9.02~9.08 |
科研主线 |
运动 |
兴趣 |
|
周一 |
看论文格式,整理BN相关 |
哑铃臀腿+拉伸 |
语言;椰子水冷萃好好喝 |
|
周二 |
跑实验(无必要);参考论文结构 |
哑铃练背 |
语言 |
|
周三 |
写了一点点也是进步! |
休息 |
语言;订机票 |
|
周四 |
写论文 |
普拉提唤醒&腰腹 |
语言 |
|
周五 |
写论文 |
(或许随便举了会铁 |
语言 |
|
周六 |
写论文 |
- |
- |
|
周日 |
写论文 |
- |
语言 |
👩🔬周科研主线:写论文
💁♀️本周主题:有条不紊,沉心静气🫂
9.02 周一
✅ 看论文格式要求
✅ 整理了下BN层仿射参数的作用、不同调整BN层做适应方法的优缺点
✅ 睡前跑了点实验,IN优化其实是可行的,不过需要调大学习率;跑了个BN-less少样本也还可以啦
🌟看文DSBN,论文里可以写一写“域不变学习”、“域特定学习”,以及两者的区别和联系:域不变学习旨在找到在两个领域中都适用的共同特征表示,而域特定学习则强调分别学习每个领域的特定特征;域不变学习试图消除领域间的差异,统一特征分布,而域特定学习则承认并利用这些差异,通过学习独特的领域特征来提高适应性。而我们的工作就是求同存异,相同的是内容和语义,不同的是样式和风格。
🌀“We expect DSBN to capture the domain-specific information by estimating batch statistics and learning affine parameters for each domain separately. We believe that DSBN allows the network to learn domain-invariant features better because domain-specific information within the network can be removed effectively by exploiting the captured statistics and learned parameters from the given domain.” IN同理,域特定的信息可以帮助网络在去除领域差异的同时,更加专注于学习领域间的共同特征(即域不变特征)。
🌀PLUTO里读到,“In PET (Parameter-efficient tuning), the pretrained model remains frozen and only the domain-specific (extra) parameters designated for the target domain are updated based on the training data. PET has found notable success as it significantly reduces memory usage and facilitates modular adaptation of the model while often being competitive with fine-tuning.”只更新域特定信息,还可以和连续学习串起来。相关方法部分也可以参考,以及利用注意力机制去计算输入与模块之间的相关性,得到注意力权重。
🌀《Revisiting Learnable Affines for Batch Norm in Few-Shot Transfer Learning》这篇文或许可以参考,这么简单的文可以中2020年的CVPR啊啊啊呜呜呜呜羡慕了🥹
🌀做了原图与增广在每个block输出的相似度实验
📊 TBN 把仿射参数都禁用(29.48)
📊 TBN 后面层禁用仿射参数,前面层更新(21.24)
📊 IN+优化 block1 block2仿射参数,用bn原参数值初始化(24.89)
📊 IN+优化 block1 block2仿射参数,用0、1值初始化(29.94)
📊 IN+优化 block1 仿射参数,用bn原参数值初始化(21.20)
📊 IN+优化 block1.layer.0 仿射参数,用bn原参数值初始化(22.08)
📊 IN+优化 block1 仿射参数,用bn原参数值初始化,lr调大到2e-3(20.44)
📊 IN+优化 block1 仿射参数,用bn原参数值初始化,lr调大到5e-3(19.88)
📊 我的方法少样本 同样学习率 bs=128(16.82)/bs=64(16.93)/ bs=32 (18.12)/ bs=16(19.87)/ bs=8(24.35)
9.03 周二
🌀除非必要,勿增实体!
📊 熵损失与校准相互作用:
- dropout inference 平均熵最小化 (20.64)
- dropout inference 加权平均熵最小化 原0.6/ drop 0.4 (20.83)
- 0.9 熵最小化+ 0.1 dropout inference平均熵最小化 (21.21)
9.04 周三
🌀五号必须写出第一版,利用好时间
🌀图表一般放在每页最上方
🌀咱们A人大脑内存很小,所以事情不要堆,速战速决或挪到固定的时间段内去做。注意力是非常宝贵的资源,我们要守护它不轻易被外界夺走。也可以借用外接硬盘(记录本等等),但同样,记在硬盘里的东西就不要放在内存里去想了。
9.05 周四
🌀SATA:在测试期间,模型只能访问一批中的少数测试样本,这可能不能代表相应的目标分布。因此,完全根据可用的目标数据修改模型参数可能会同时导致少数目标样本的过度拟合以及源信息的灾难性遗忘。 CoTTA [ 38 ]通过以下方式解决了这一挑战:(i)通过结合源模型和不断适应的学生模型来学习教师模型,其中教师逐渐变化以进行鲁棒预测,并且还使用(ii)随机恢复将一些模型参数重置为每批次后的源模型。尽管这提供了令人印象深刻的性能,但它有两个局限性,即(i)需要存储完整的教师、学生和源模型,以及(ii)需要确定计算教师模型和随机恢复所需的超参数,这对于不同的数据集可以有不同的最佳值。
🌀GrepBN:To verify the effectiveness of our proposed GpreBN, inspired by [52], we also choose Entropy as the minimizing loss function to optimize the affine parameter of the BN layer.
9.06 周五
🌀COTTA平均用时:188.6s;LessBN平均用时:9.64s
🌟 “In our experiments, we found that the choice of p has a significant impact on adaptation efficiency. For tasks with high domain variance, a larger p value may be needed to update more layers, while for tasks with moderate shifts, smaller p values, such as 0.1 to 0.2, often sufficed.”(impulse是大gap,brightness是小gap)
🌟Looking forward, LessBN could be extended to a broader range of transfer learning tasks, particularly in cases where domain shifts are subtle but persistent. Future work may explore integrating adaptive p values or leveraging additional layers of modulation for better balance between adaptation speed and accuracy.
✅ 按照实验大纲去完善实验
✅ 写完相关方法、问题定义
9.07 周六
🌀加油啊宝贝!!你一定可以的!!!
写《方法》部分,讲好故事 2h ✅
仿照COTTA结构写《实验》部分,不求完美!先写出来再说 3h ✅
看一下别人论文的《导言》结构,写导言 2h ✅
写《结论》 ✅
写《讨论》/《分析》,一股脑写出来 ✅
导言根据老师的建议润色 ,发给老师看 ✅
9.09 周一
🌀一波三折还是交上去了…感谢老板🙏总算结束了——


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧