LLM与强化学习(一)
很早之前就想了解一下LLM到底是怎么和强化学习结合的,今天凑巧查资料的时候看到亚马逊的一篇文章,把知识点整理记录一下。
1 什么是RLHF
RLHF 代表“Reinforcement Learning from Human Feedback”,即基于人类反馈的强化学习。它是一种机器学习技术,利用人类反馈来优化模型,从而更有效地进行自我学习。
强化学习技术训练软件做出能够最大限度提高回报的决策,使其结果更加准确。RLHF 将人类反馈纳入奖励功能,因此模型可以执行更符合人类目标、愿望和需求的任务。RLHF 广泛应用于生成式AI应用程序,包括大语言模型,帮助LLM学习生成更符合人类偏好的文本。
2 为什么RLHF很重要
人工智能(AI)应用范围广泛,但无论是什么应用,AI的最终目标都是模仿人类的反应、行为和决策,在完成复杂任务时更接近甚至超过人类。
RLHF 是一种特殊技术,用于与其他技术(例如有监督学习和无监督学习)一起训练人工智能系统,使其更加人性化。首先,将模型的响应与人类的响应进行比较。然后,人类会评测不同机器响应的质量,对哪些响应更人性化进行评分。分数可以基于人类的内在品质,例如友善、适当程度的情境化和心情。
增强人工智能性能
RLHF 使机器学习模型更加准确。与初始状态相比,增加额外的人工反馈回路可以显著提高模型性能。
例如,当文本从一种语言翻译成另一种语言时,模型生成的文本可能在技术上是正确的,但对读者而言听起来并不自然。专业译员可以先进行翻译,并对机器生成的翻译评分,然后对一系列机器生成的翻译进行质量评分。通过对模型进行进一步训练,可以更好地生成听起来自然的翻译。
引入复杂的训练参数
在某些情况下,生成式AI可能很难针对某些参数准确地训练模型。
例如,如何定义一首音乐的情绪? 可能有一些相关技术参数,例如音调和节奏,可以表明某种情绪,但是音乐作品的情绪相比一系列技术性细节而言要更加主观,定义也不太明确。您可以提供人工指导,让作曲家创作各种情绪的作品,然后根据情绪水平对机器生成的作品进行标记。这使机器能够更快速地学习这些参数。
提高用户满意度
尽管机器学习模型可能很准确,但可能与人类相去甚远。这时便需要 RL 来引导模型,为人类用户提供最具吸引力的最佳响应。
例如,如果您问聊天机器人外面的天气怎么样,它可能会回答“30 摄氏度,多云,湿度高”,也可能会回答“目前温度在 30 度左右。阴天潮湿,比较闷热!”尽管两个答案相似,但第二个听起来更自然,提供了更多上下文信息。
当人类用户就他们喜欢哪种模型的响应进行评分时,您可以使用 RLHF 来收集人类反馈并改进模型,以便更好地为真正的人类提供服务。
3 RLHF如何运作
这一部分非常关键!是本文重点。
RLHF 分四个阶段执行,我们以语言模型为例,使用 RLHF 进行完善。
我们简单概述一下学习过程。训练模型及其针对 RLHF 的策略优化存在巨大的数学复杂性。但是,这些复杂过程在 RLHF 中有明确定义,并且通常有预构建的算法,只需要您的特定输入即可。
数据收集
在使用语言模型执行机器学习任务前,会为训练数据创建一组人工生成的提示和响应。这组提示和响应将在模型的后期训练过程中使用。
例如,提示可能是:
- “Where is the location of the HR department in Boston?”
- “What is the approval process for social media posts?”
- “What does the Q1 report indicate about sales compared to previous quarterly reports?”
然后,公司的知识型员工会以准确、自然的响应回答这些问题。
对语言模型进行监督式微调
您可以使用预训练模型作为 RLHF 的基础模型,随后使用检索增强生成(RAG)等技术根据公司的内部知识库对模型进行微调。对模型进行微调时,您可以将其对预定提示的响应与上一步中收集的人工响应进行比较。数学方法可以计算出两者间的相似程度。(这一步也就是前面说的比较机器响应与人类响应,并为模型响应打分)
例如,可以为机器生成的响应分配介于 0 和 1 间的分数,其中 1 表示最准确,0 表示最不准确。确定好分数后,该模型便有了一项策略,即生成得分更接近人类响应的响应。此策略便是该模型未来所有决策的基础。
构建单独的奖励模型
RLHF 的核心是根据人类反馈训练单独的人工智能奖励模型,然后使用该模型作为奖励函数,通过强化学习优化决策。假设模型中有一组对相同提示的多个响应,人类可以指出其对每个响应质量的偏好。您可以使用这些响应评分偏好来建立奖励模型,该模型会自动估计人类对任何给定提示的响应给出多高的分数。
使用基于奖励的模型优化语言模型
然后,语言模型会使用奖励模型在响应提示前自动完善其决策。使用奖励模型,语言模型可内部评估一系列响应,然后选择最有可能获得最大奖励的响应。这意味着它以优化程度更高的方式满足了人类的偏好。
下图为 RLHF 学习过程的概述。(此图就是全文的精髓了!)
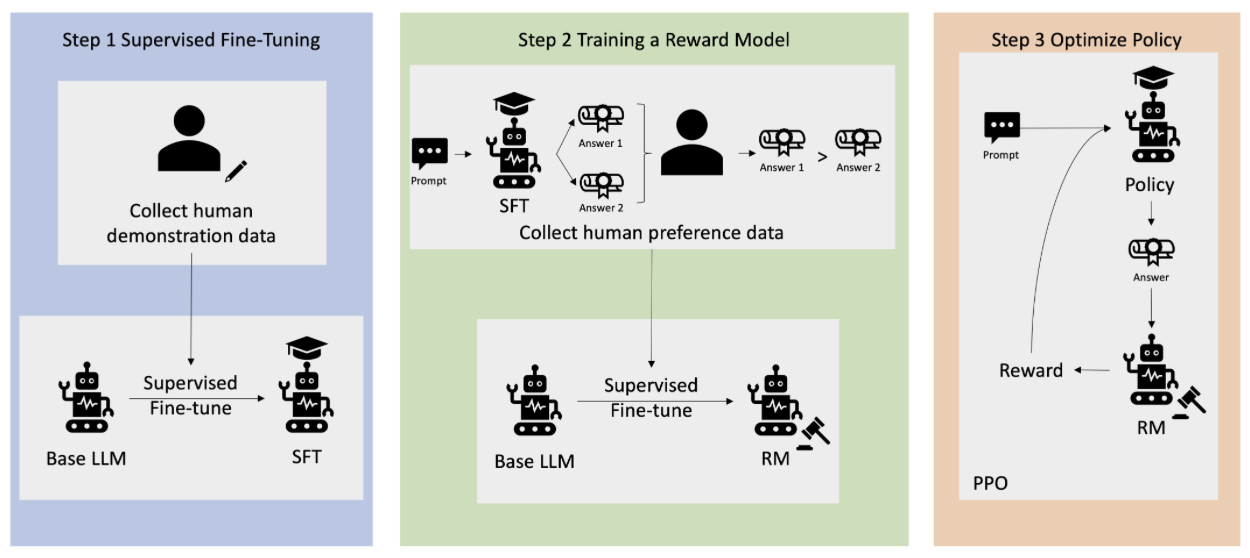
第一步是有监督微调,利用人工生成的“提示-响应”示例对来微调基础模型,得到一个微调后的模型;第二步在同一提示下,将微调后模型给出的多个响应与人类响应进行比较,越接近人类响应评分就越高,通过评分偏好训练一个奖励模型;第三步是优化,微调后模型对输入提示做出响应,奖励模型在内部评估响应,微调后模型再根据评估选择可能获得最大奖励的响应。
RLHF 在生成式人工智能领域有哪些应用
RLHF 是公认的确保 LLM 制作真实、无害且有用的内容的行业标准技术。但是,人类沟通是一个主观的创造性过程,而 LLM 输出的有用性则深受人类价值观和偏好的影响。每个模型的训练方式都略有不同,所用的人类响应者也不尽相同,因此即使是竞争力相当的 LLM,输出也会有所差异。每个模型涉及人类价值观的程度完全取决于创建者。
RLHF 的应用超出了 LLM 的范围,扩展到了其他类型的生成式人工智能。下面是一些示例:
- RLHF 可用于 AI 图像生成:例如衡量艺术品的现实性、技术性或意境
- 在音乐生成中,RLHF 可以帮助创作与活动的特定情绪和音轨相匹配的音乐
- RLHF 可以用在语音助手中,引导语音,使其听起来更友好、充满好奇、更值得信赖
--------------------------------------
由于笔者对微调以及RLHF技术的了解还不够深入,有些表达可能会不太准确/有误,欢迎大家在评论区指出,我们一起讨论、学习、进步!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2019-02-13 【蓝桥杯】算法训练 素因子去重