【学习笔记】Transformer (1)
在看Transformer之前,建议先学习一下Self-attention。
同样,这边笔记是参考李宏毅老师的课程和ppt,感兴趣的可以去看原视频~
补充了Transformer论文精读笔记,建议结合本文食用: )
Sequence-to-Sequence
没错!Transformer是一个sequence-to-sequence (Seq2Seq) 的模型,也就是输入一个sequence,模型会输出一个sequence。
前面讲self-attention提到模型有三种输出:1. 每个向量都有一个label;2. 整个序列有一个label;3. 输出sequence的长度由模型自己决定,也就是这边的Seq2Seq。
经典的应用包括:机器翻译、语义识别、问答机器人...几乎什么样五花八门的任务,只要输入和输出是sequence,就都可以拿来用Seq2Seq硬做,并且效果居然也不错。当然啦,针对不同的任务客制化model会比Seq2Seq效果更好,但足以看出Seq2Seq的应用之广泛。
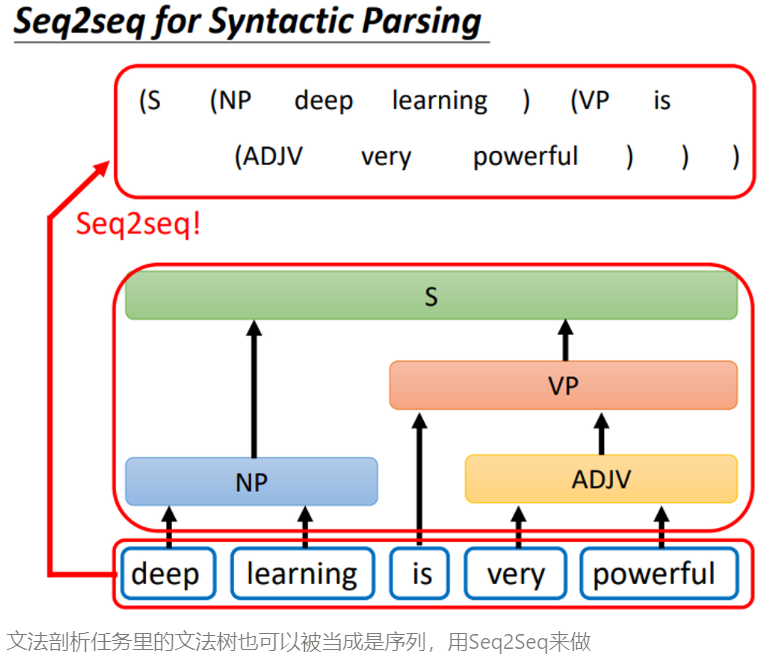
模型结构
简单来说,Transformer就是经典的Encoder-Decoder结构:输入序列进入编码器,编码器的输出再进入解码器,最终输出一个序列。
下面来分别讲一讲Encoder和Decoder具体在做些什么。
Encoder
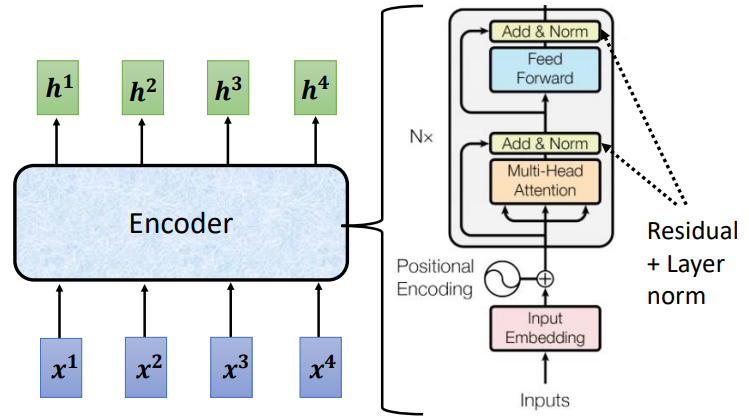
下面这张图的左边是不是和上一讲的Self-attention很像?每个输入向量都会经过Encoder输出一个向量,当然,RNN和CNN也可以办得到这一点!
把Encoder放大,右边就是Transformer编码器的结构啦。可以看出,它的主体其实就是Self-attention,中间灰色的框框被视为一个block,输入向量要经过N个这样的block。
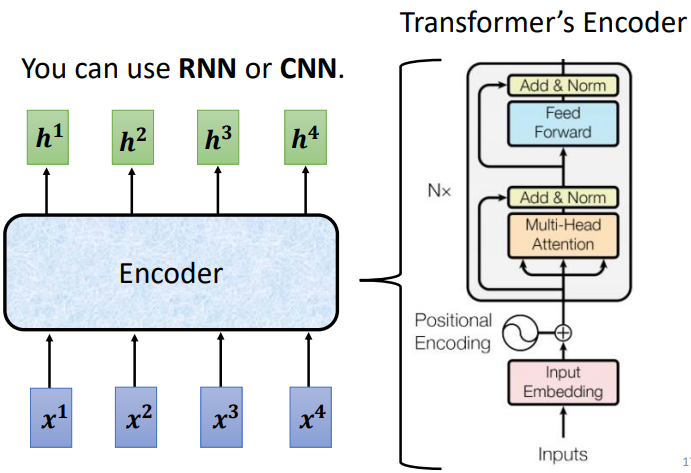
可是,右边的图花花绿绿看起来好复杂!
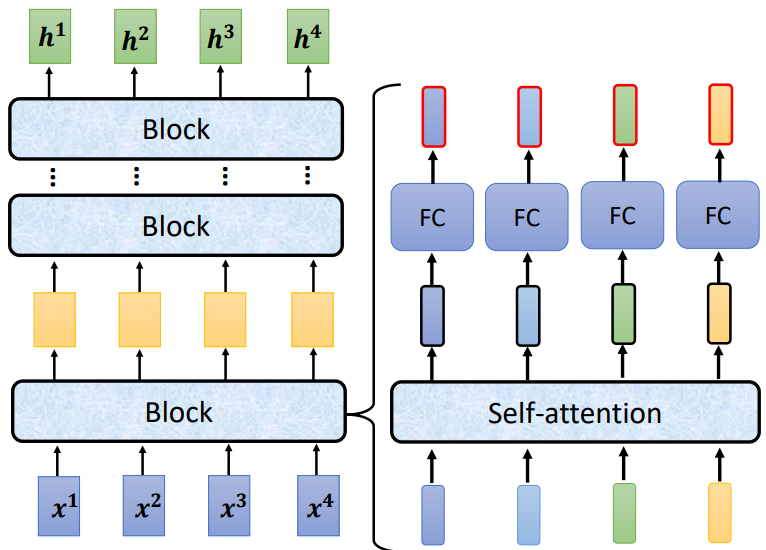
我们来看下面这张图:输入向量经过一个block,得到的输出再作为下一个block的输入...最终得到输出向量。
每个block做的事情也很简单:经过self-attention得到的各个向量分别喂给一个全连接层得到输出。
简单复习一下,self-attention做的事情就是整合序列信息,每个向量经过投影后得到query、key、value,计算每个query和所有key的相似度 (attention score) 作为各个value的权值,而加权和就是最后的输出。
但是,Transformer编码器做的事情要稍微复杂一点点,每个向量经过self-attention得到的输出,还要加上原始的输入(这就是ResNet里的残差连接)!如果b是输入向量,对应self-attention的输出向量为a,那么b + a才是我们需要的。
这之后,还要再经过一个Norm层。注意,这里不是常见的Batch Normalization,而是Layer Normalization。BN是对整个batch的样本在特征维上做normalization,而LN是每个样本自己做normalization,不需要考虑整个batch。这是合理的,每个序列长度都不统一,自己做normalization效果自然会更好。
经过LN之后的输出,才是要进入全连接层的输入。同样,这边也要用到残差连接和LN:FC的输出加上FC的输入,经过LN后得到这一个block的最终输出。
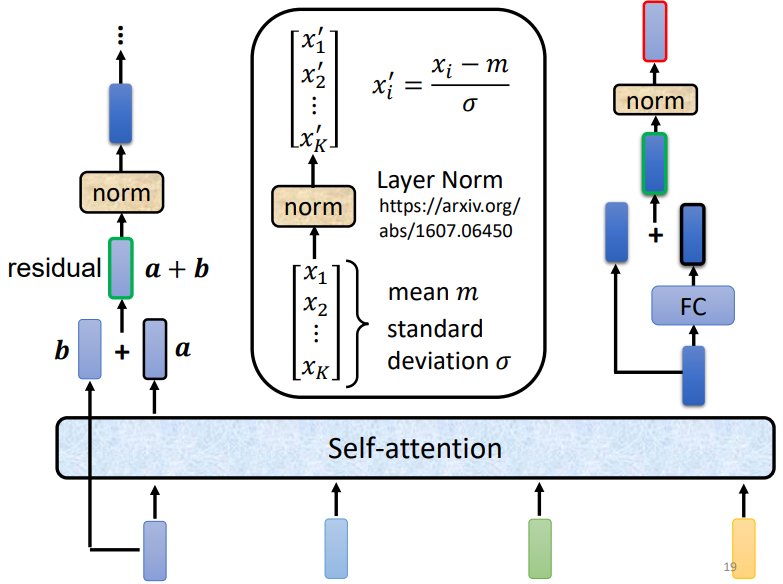
听起来很像绕口令对不对?但是仔细看懂上面的图片在做什么之后,再回过来看Transformer的Encoder会豁然开朗。
输入向量经过embedding层,加上位置编码(同样在self-attention里提到过),进入第一个block:先做multi-head attention,输出+输入做Layer norm,经过全连接层后再做一次残差连接和LN,得到block的输出。这样的block会重复N次。
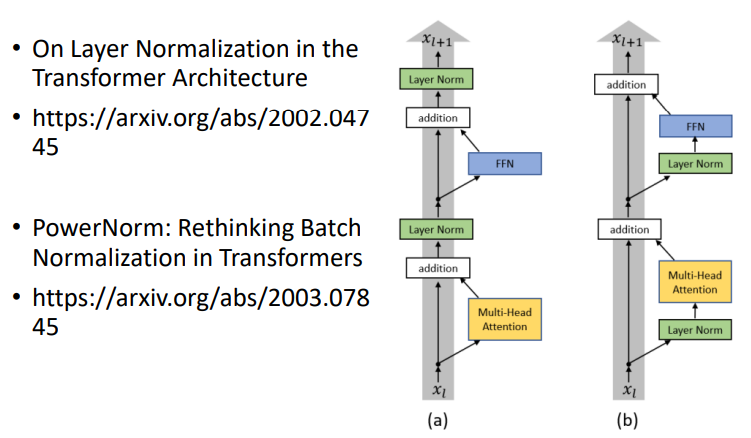
block一定要这么设计吗?当然不一定。在Transformer之后,有不少论文做了相关的研究,比如下面这个就把Layer Norm放在了attention前面,效果更好了。
Decoder
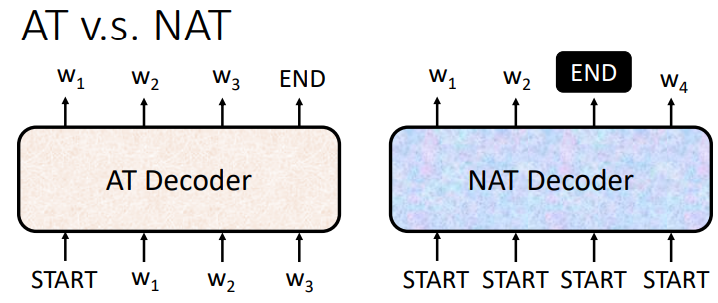
讲完编码器,我们来看解码器。解码器有两种,AT和NAT。
- Autoregressive (AT)
解码器通过某种方法把Encoder的输出读进来(后面会细说),输入一个特殊的START向量来作为序列的开始。
假设要处理翻译任务,这个输出向量的维数就和字典的长度一样,每个字都会对应一个数值,分数最高的那一个字就是最后的输出。
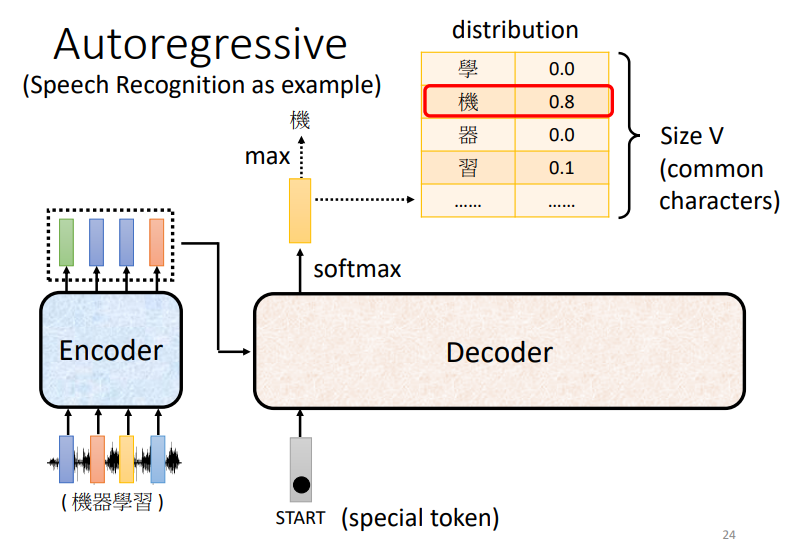
拿到第一个输出之后,把它作为下一个输入进入Decoder,重复前面的步骤,依次得到新的输出和新的输入...这样的过程就叫做自回归 (Autoregressive) 。

但是,难道就这么无休止的输出下去吗?
当然不了!有始 (START) 有终 (END) ,在字典里我们也要加入一个特殊的END,标志着输出序列的结束。
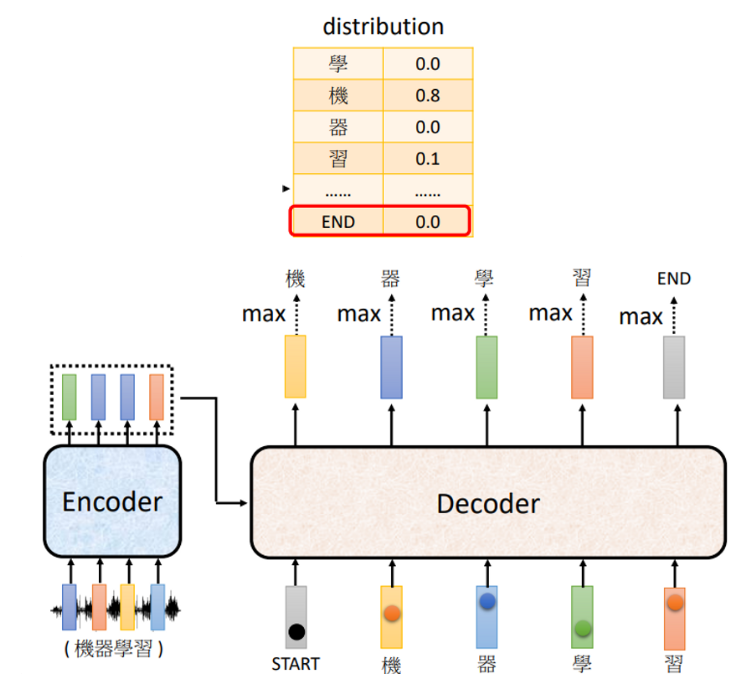
现在,我们来看看Decoder具体在做些什么。
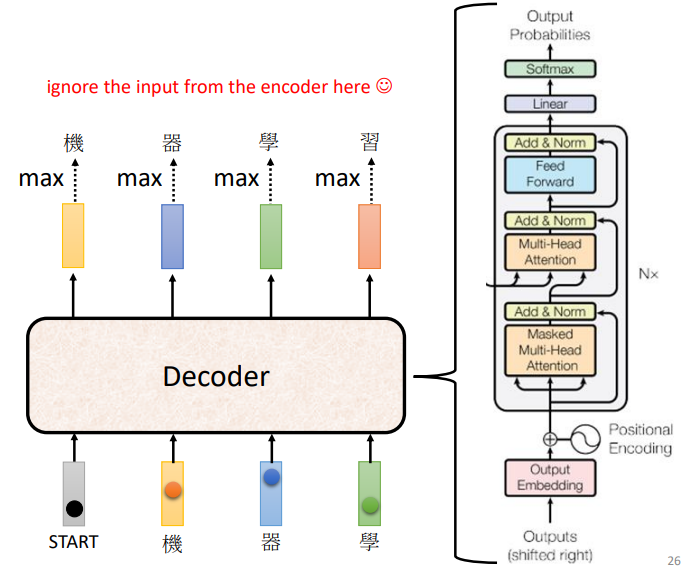
诶,怎么这么眼熟?没错,它和Encoder长得很像!把中间那一块挡住,Decoder和Encoder的block简直一模一样嘛!
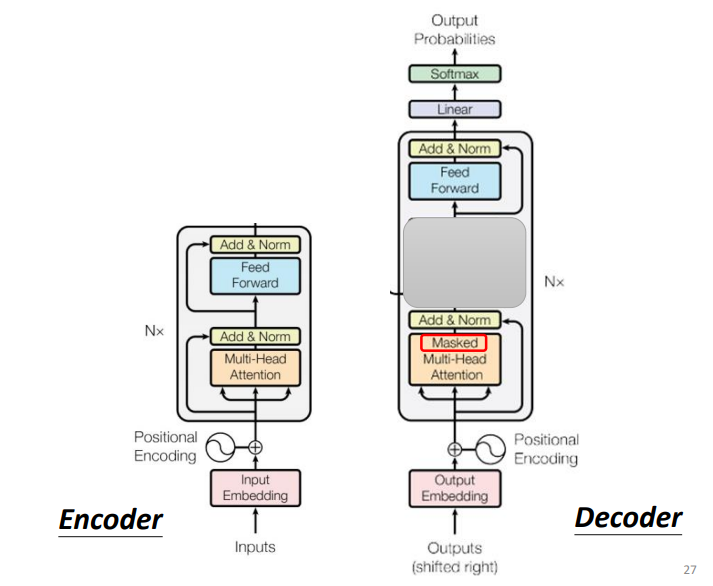
但是,这边为什么是Masked Attention呢?
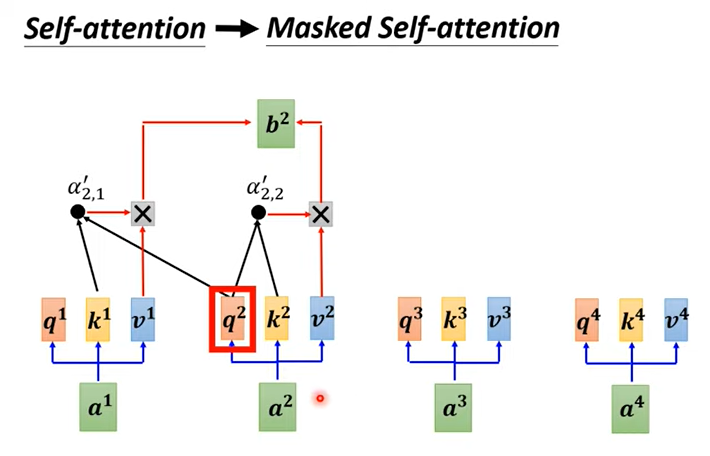
和前面的Encoder不一样,Decoder是一个一个输出的,在产生当前输出的时候,只考虑它左边的那些输入,而不是一下子看到整个输入序列。
- Non-autoregressive (NAT)
和自回归解码器不同,NAT解码器一次性产生所有输出——因此,也是一次性输入BEGIN!
可是,我们并不知道输出序列有多长啊?NAT是怎么办到的呢?
有两个方法:
- 再加一个predictor,把编码器的输出作为输入,预测序列的长度
- 输入一个很长的STRAT序列,输出只取END之前的部分
Encoder - Decoder
前面挖的坑还没填,Decoder和Encoder是怎么联动的呢?
这里就要引入一个叫”cross-attention“的东西啦。不要被名字吓到,就那么回事儿——只不过key和value来自Encoder的最后一层输出,query来自Decoder经过Masked Attention的输出。当然,输出都要先做投影再做attention。
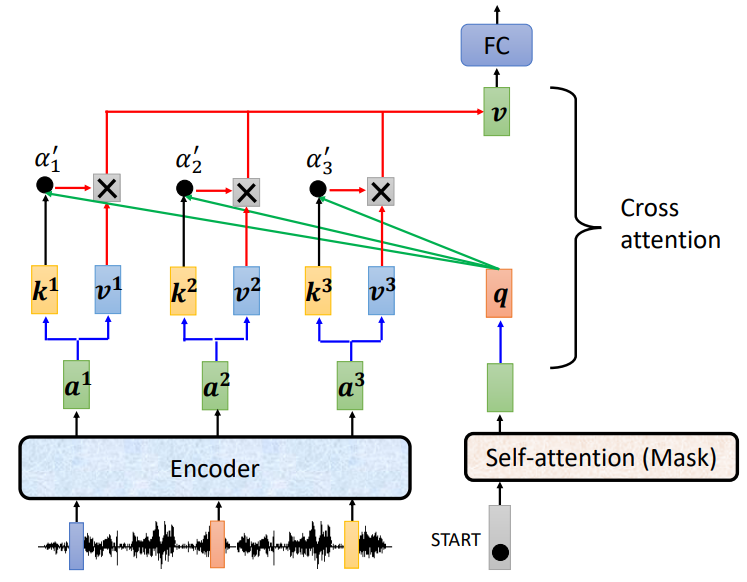
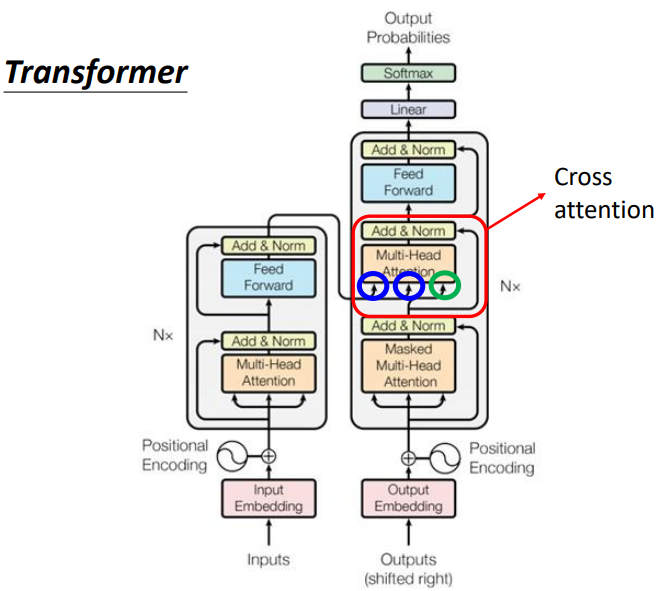
现在看看Transformer整体架构,是不是就懂啦~
Training
我们观察一下Decoder的输入,其实这不就是Decoder的输出嘛!
所以在训练的时候,我们可以把Ground Truth(真实值)拿来做输入,再拿输出和GT算交叉熵,希望所有交叉熵的总和越小越好。
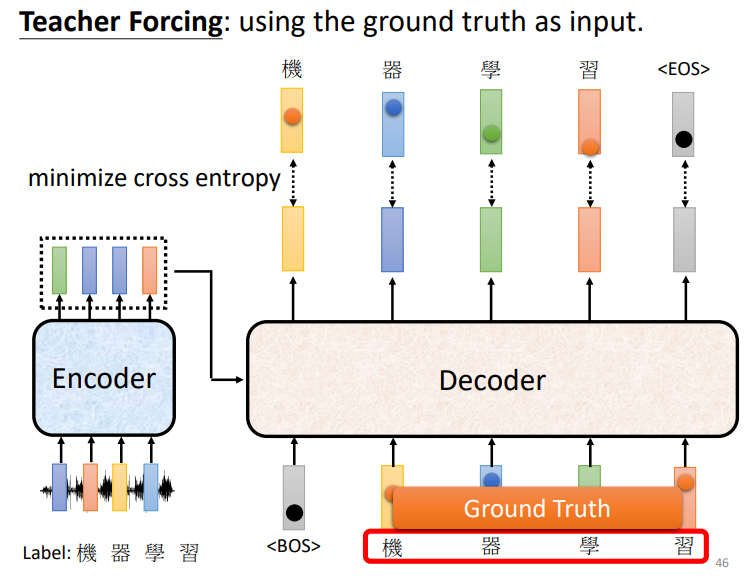
可是在做inference的时候,Decoder看不到正确答案啊!显然和训练的情况存在一个mismatch。
如果Decoder在训练的时候只看过正确的东西,那么inference时可能会出现“一步错,步步错”的情况。所以,在训练的时候,我们不能只给Decoder看正确的答案,也要输入一些错误的东西给它看。这一招叫Schedule Sampling。
比如,GT是“机器学习”,可我们会故意输入“机气学习”,这样如果Decoder犯错输出了“机气”,后面也不至于跟着全部错下去。是不是很有意思?人生也是这样,需要引入一些“随机性”,不断地踩坑、走弯路,看过更多不一样的风景,好坏都参透,后面的路才能走得更稳。
到这里,Transformer就全部讲完啦!
欢迎大家评论区留言讨论!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧