Schema设计
Schema:表的模式;
设计数据的表,索引,以及表和表的关系
- 在数据建模的基础上将关系模型转为数据库表
- 满足业务模型需要基础上根据数据库和应用特点优化表结构
关系模型图:
Schema关系到应用程序功能与性能
- 满足业务功能需求
- 同性能密切相关
- 数据库扩展性
- 满足周边需求(统计,迁移等)
关系型数据库修改Schema经常是高危操作
Schema设计要体现一定的前瞻性
完全由开发者主导的Schema设计
- 着眼于实现当前功能
- 完全基于功能的设计可能存在一些隐患
-
- 不合理的表结构或索引设计造成性能问题
- 没有合理评估到数据量的增长造成空间紧张而且难以维护
- 需求频繁修改造成表结构经常变更
- 业务重大调整导致数据经常需要重构订正
基于性能的表设计
- 根据查询需要设计好索引
- 根据核心查询需求, 适当调整表结构
- 基于一些特殊业务需求,调整实现方式
索引
- 正确使用索引
- 更新尽可能使用主键或唯一索引
- 主键尽可能使用自增ID字段
- 核心查询使用覆盖索引
-
- 用户登录需要根据用户名返回密码用于验证
- create index idx_uname_passwd on tb_user (username,passwd);
- 建立联合索引避免回表取数据
设计举例
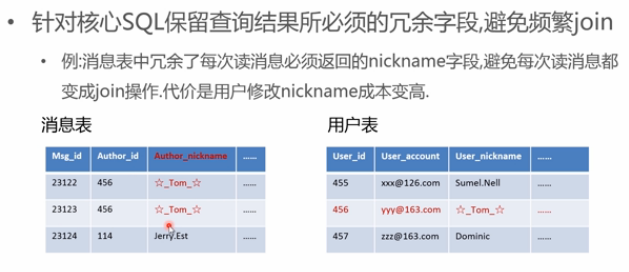
1 反范式,冗余必要字段
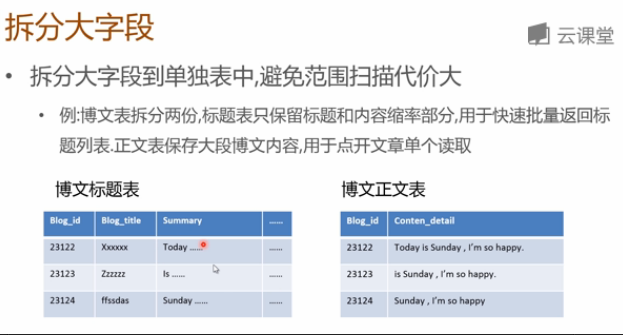
2 拆分大字段
3 避免过多字段或过长行![]()

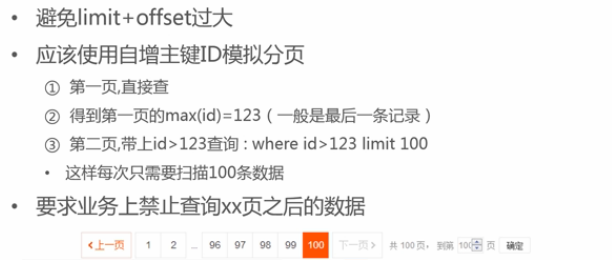
4 分页查询:
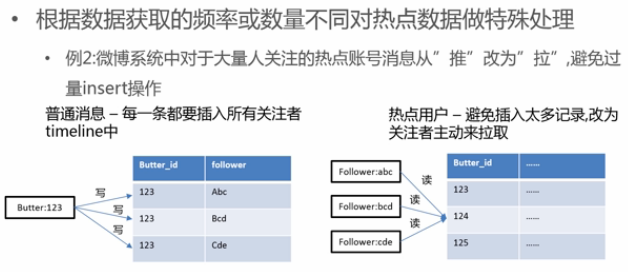
5 热点读数据特殊处理

6 热点写数据特殊处理
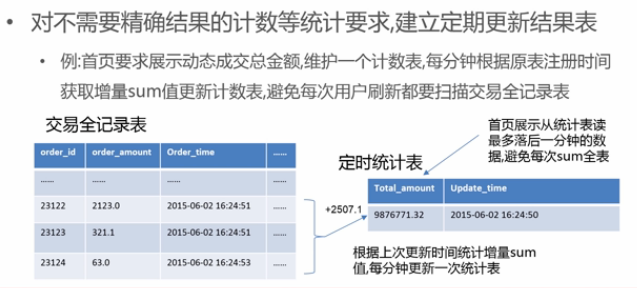
7 准实时统计
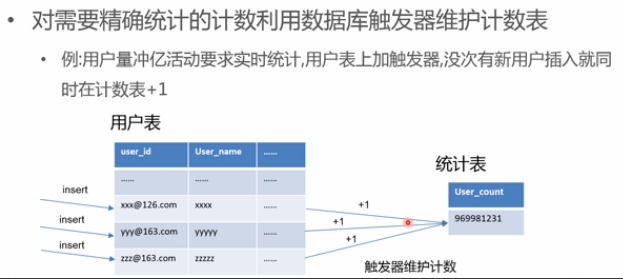
实时统计改进1--触发器实时统计
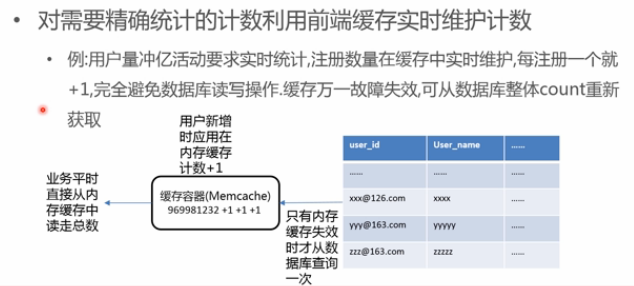
实时统计改进2-缓存实时统计
实时统计改进3-最大自增ID获取总数

8 可扩展性设计

9 分区表与数据淘汰
range分区

list分区

hash分区

10 满足周边需求

统计和后台需求

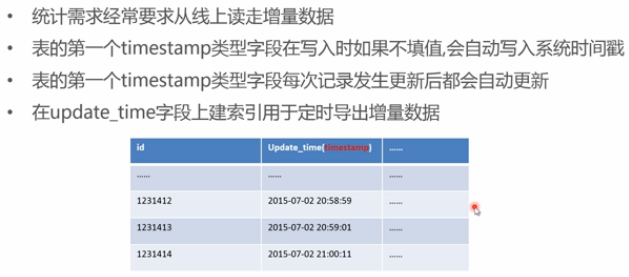
11 自动更新时间戳
Schema设计与前瞻性
- 基于历史经验教训,预防和解决同类问题
- 把折腾DBA够呛的索引Schema改造的原因记录并分析总结
例子:
业务为了用户信息加密做了大改造
- 数据库结果大量改动,增加了加密字段,验证策略表,所有表重新订正数据等等
- 是否所有用到用户信息管理的应用都要去上线就用密文?

总结
- schema设计关系性能
- 反范式,冗余必要字段
- 拆分大字段
- 避免过多字段或过长字段
- 分页查询
- 热点读数据特殊处理:置顶表与普通表分开
- 热点写数据特殊处理:
-
- 微博普通用户发消息,则写入关注他的人的消息列表中;微博大V发消息,则关注他的人都去读他的消息列表;
- 准实时统计:
-
- 定时统计表,更据上次更新时间统计全表中增量sum值,每分钟更新统计表;
- 实时统计:
-
- 触发器实时统计,在用户插入时,更新统计表;
- 缓存实时统计,应用将用户新增写在内存缓存中,业务平时从缓存中读,缓存失效,从数据库做一次查询,接着写在缓存;
- 分区表与数据淘汰
- 满足周边需求:
-
- 如后台统计任务而增加特殊索引,
- 为数据迁移或统计增加时间戳
- 自动更新时间戳
- schema设计与前瞻性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号