背景
MySQL中SQL加锁的情况十分复杂,不同隔离级别、不同索引类型、索引是否命中的SQL加锁各不相同。
然而在分析死锁过程当中,熟知各种情况的SQL加锁是分析死锁的关键,因此需要将MySQL的各种SQL情况加锁进行分析总结。
基础知识
MVCC
- 快照读
- 读取历史版本,从undo log中读取行记录的快照;这样读行就不需要等待锁资源,提高了并发;
- 当前读
- 读取最新版本,并且当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
- 加锁读、插入、更新、删除等操作均属于当前读
将插入,更新,删除归为当前读是因为这些操作均包含读取当前记录的操作。拿update table set ? where ?来讲,
当Update SQL被发给MySQL后,MySQL Server会根据where条件,读取第一条满足条件的记录,然后InnoDB引擎会将第一条记录返回,并加锁 (current read)。
待MySQL Server收到这条加锁的记录之后,会再发起一个Update请求,更新这条记录。一条记录操作完成,再读取下一条记录,直至没有满足条件的记录为止。
因此,Update操作内部,就包含了一个当前读。同理,Delete操作也一样。Insert操作会稍微有些不同,简单来说,就是Insert操作可能会触发Unique Key的冲突检查,也会进行一个当前读。
注意:
Innodb当前读加锁是一条一条进行,先对一条满足条件的记录加锁,返回给MySQL Server做一些DML操作,然后在读取下一条加锁,直至读取完毕。
Two-phase locking
Two-Phase Locking,说的是锁操作分为两个阶段:加锁阶段与解锁阶段,并且保证加锁阶段与解锁阶段不相交。 加锁阶段:只加锁,不放锁。解锁阶段:只放锁,不加锁。
隔离级别
数据库的隔离现象与隔离级别如下图所示
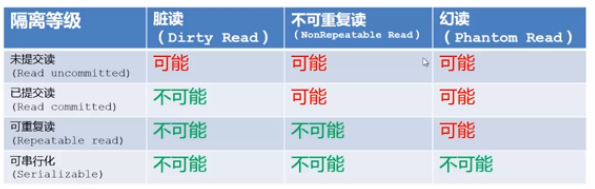
脏读现象:即A连接,未提交的事务,B连接的事务可以看到;
NONREPEATABLE READ(不可重复读)现象:
A连接,提交的事务,B连接的事务中可以看到,这样在B连接中的事务,就可以看到A连接事务提交前,和提交后两种状态;
注意:不可重复读针对update,delete
PHANTOM READ(幻读)现象:
A连接,提交的事务,B连接的事务可以看到,这样在B连接中的事务,就可以看到A连接事务提交前,和提交后两种状态;
注意:幻读针对insert;
innodb事务引擎,通过间隙锁 粗暴 将RR隔离级别的幻读现象消除,这也是RR与RC的主要区别。
基础SQL组合分析
使用下面这张 students 表作为实例,其中 id 为主键,no(学号)为二级唯一索引, score(学分)为二级非唯一索引,age(年龄)无索引。
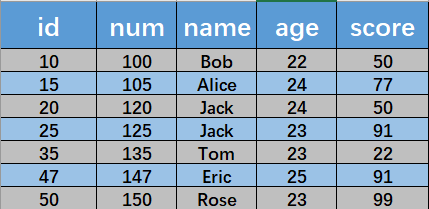
我们只分析基础SQL,它只包含一个 WHERE 条件,等值查询或范围查询,根据条件类型以及隔离级别不同(主要分析最常用的RR,RC)我们主要分析一下情况:
聚簇索引,索引命中
SQL select * from students where id = 20 for update, 在 RC 和 RR 隔离级别下加锁情况一样,都是对 id 这个聚簇索引加 X 锁,如下:

唯一索引,索引命中
SQL:select * from students where num = 135 for update;
若检索唯一索引,那么SQL需要加两个X锁,一个对应唯一索引上的num = 135的记录,另一把锁对应于聚簇索引上的[id=35]的记录。

二级索引,索引命中
SQL:select * from students where score= 91 for update;
如此例子当中如法插入score 值有[77,99),注意边界值。前边界77是无法插入的,后边界99则可以插入。
此外 select * from students where score= 77 for update,是不用等待锁的。

无索引
SQL: select * from students where age = 22 for update;
无索引时如何是RR还是RC均会将行锁升级为表锁,具体表现就是全表update,delete。
此外因为RR隔离级别有next-key,RR除了不能update,delete外连insert都不可以,而RC则可以进行insert 操作。

索引未命中
聚簇索引,索引未命中
SQL select * from students where id = 30 for update;
RR隔离级别下,当查找聚簇索引但索引未命中时,此时聚簇索引加锁状态与二级索引状态相同,原本行锁变为gap锁,锁范围如下:
- (25,35)
当然此时收主键唯一性约束,任何插入id=25或35的操作均会失败,这一点与二级索引不同。
RC隔离级别下,由于id索引未命中即聚簇索引中没有相关记录,则不加任何锁。

唯一索引,索引未命中
SQL select * from students where num = 130 for update;
唯一索引,索引未命中的情况与上面聚簇索引,索引未命中的情况 相似。区别在于聚簇索引gap锁加载聚簇表中,唯一索引则在唯一索引自身的索引表中。
同样是没有行锁,仅有gap锁,其表现出来的现象就是在gap范围内如法插入数据,不影响其余DML操作。

二级索引,索引未命中
SQL select * from students where score = 70 for update;

范围查询
- 聚簇索引范围查询
- select * from students where id <=25 for update;
RR隔离级别时,聚簇索引范围查询时加锁情况如下图。
如果where 条件为id<25 则在25-35间不会加GAP锁,但也会在25上加X锁,然后再在相应范围加GAP锁。
如果where 条件为id>25,并不会在25处加X锁,仅会在(25,+)加GAP锁以及对应索引项加X锁。
注意:在RR隔离级别时,条件y<id<x, 则MySQL选择比y,x大的索引项来加X锁,称为向右扩展。

- 唯一索引范围查询
- select * from students where num >125 for update;
唯一索引范围查询整体与聚簇索引范围查询相似,RC仅在范围内的索引列上加X锁。RR则除在索引列上在X锁外,还会在范围内索引列之间加GAP锁。
此外RR的边界值是否加X锁,有向右扩展原则即向索引值大的方向扩展加X锁。当num<125时,向右扩展的第一个索引值为125 则会在125上加X锁。
当num<=125时,向右扩展的第一个索引值为135,则会在135上加X锁。当num>125时,向右扩展的第一个索引值为135,包含在范围之内因此无特殊表现。

- 二级索引范围查询
select * from students where score <= 50 for update;
由下图可见二级索引范围查询其实与唯一索引以及聚簇索引的范围查询的加锁原理相同。RC仅在范围内的索引项上加X锁。
RR则除范围内索引项加X锁外,并在索引项间加GAP锁,且边界值是否加X锁遵循向右扩展原则。

小结
- 索引等值查询,且索引命中
- 主键、唯一索引无论RR或RC均在索引项及其聚簇索引对应记录上加X锁。
- 二级索引RC隔离级别与主键、唯一索引相同
- 二级索引RR隔离级别,除对应索引项及其记录上加X锁外,在各索引项间加GAP锁
- 索引等值查询,且索引未命中
- RR主键,与唯一索引会在包含条件值得两个索引项间 加GAP锁
- 二级索引与主键、唯一索引相似,也会在包含条件值的两个索引间加GAP锁并在左侧索引项上加X锁
- RC不加任何锁
- 索引范围查询
- 主键索引,唯一索引,二级索引加锁原理相同。
- RC仅在范围内的索引项上加X锁。
- RR则除范围内索引项加X锁外,并在索引项间加GAP锁,且边界值是否加X锁遵循向右扩展原则
- 主键索引,唯一索引,二级索引加锁原理相同。
另一个角度总结
- RC
- RC隔离级别没有GAP锁(唯一索引insert情况除外,仅指select情况),仅在符合条件的索引项上加X锁
- RR
- RR隔离基本多了GAP锁,但在主键或唯一索引存在时仅在索引项及其记录上加X锁,不加GAP锁。
- 二级锁索引则除索引项及其记录上加X锁外,并在包含X锁记录的两侧索引项之间加GAP锁。
- 若索引值未命中
- 主键,唯一索引,二级索引均会在包含未命中索引值得两侧索引项之间加GAP锁。
- 若是二级索引还会在左侧索引项上加X锁。
- RR隔离基本多了GAP锁,但在主键或唯一索引存在时仅在索引项及其记录上加X锁,不加GAP锁。
where 条件提取
给定一条SQL,索引项是如何影响查询过程的,非索引项的条件是如何过滤数据,只有清楚掌握每个细节才能写出性能较高的SQL语句。
SQL的where条件大约分为3类
- index key
- index filter
- table filter
Index Key
确定索引扫描的范围,其包括起始位置与终止位置, 因此Index Key也被拆分为Index First Key和Index Last Key,
分别用于定位索引查找的起始,以及索引查询的终止条件。
Frist Key
用于确定索引查询的起始范围。
提取规则:从索引的第一个键值开始,检查其在where条件中是否存在,若存在并且条件是=、>=,则将对应的条件加入Index First Key之中,继续读取索引的下一个键值,使用同样的提取规则;若存在并且条件是>,则将对应的条件加入Index First Key中,同时终止Index First Key 提取;若不存在,同样终止Index First Key 提取。
例如
idx_c1_c2_c3(c1,c2,c3)
where c1>=1 and c2>2 and c3=1
--> first key (c1,c2)
--> c1为 '>=' ,加入下边界界定,继续匹配下一个
--> c2 为 '>', 加入下边界界定,停止匹配
Last Key
用于确定索引查询的终止范围.
提取规则:从索引的第一个键值开始,检查其在where条件中是否存在,若存在并且条件是=、<=,则将对应条件加入到Index Last Key中,继续提取索引的下一个键值,使用同样的提取规则;若存在并且条件是 < ,则将条件加入到Index Last Key中,同时终止提取;若不存在,同样终止Index Last Key的提取。
例如
idx_c1_c2_c3(c1,c2,c3)
where c1<=1 and c2=2 and c3<3
--> last key (c1,c2,c3)
--> c1为 '<=',加入上边界界定,继续匹配下一个
--> c2为 '='加入上边界界定,继续匹配下一个
--> c3 为 '<',加入上边界界定,停止匹配
注意:提取过程中 如果比较符号中包含'='号,'>='也是包含'=',那么该索引键是可以被利用的,可以继续匹配后面的索引键值;如果不存在'=',也就是'>','<',这两个,后面的索引键值就无法匹配了。
Index Filter
字面理解就是可以用索引去过滤。也就是字段在索引键值中,但是无法用去确定Index Key的部分。
exp:
idex_c1_c2_c3
where c1>=1 and c2<=2 and c3 =1
index key --> c1
index filter--> c2 c3
这里为什么index key 只是c1呢?因为c2 是用来确定上边界的,但是上边界的c1没有出现(<=,=),而下边界中,c1是>=,c2没有出现,因此index key 只有c1字段。c2,c3 都出现在索引中,被当做index filter.
MySQL 是 5.6 之前的版本,Index Filter 和 Table Filter 没有区别,统统将 Index First Key 与 Index Last Key 范围内的索引记录,回表读取完整记录,然后返回给 MySQL Server 层进行过滤。而在 MySQL 5.6 之后,Index Filter 与 Table Filter 分离,Index Filter 下降到 InnoDB 的索引层面进行过滤,减少了回表与返回 MySQL Server 层的记录交互开销,提高了SQL的执行效率,这就是 ICP(Index Condition Pushdown)。
Table Filter
无法利用索引完成过滤,就只能用table filter。此时引擎层会将行数据返回到server层,然后server层进行table filter。
举例来说

Index Key : pubtime
Index Filter: userid
Table Filter: comment
若使用5.6之前的版本则红色箭头线所指的记录会加X锁,因为5.6之前Index Filter与Table Filter作用一样,都需要根据Index Key 的扫描范围回表,到server层再过滤。
若使用5.6及其之后的版本则红色箭头线缩指的记录不会加X锁,因为ICP(Index Condition Pushdown)特性,在Index Key 扫描完范围后,根据Index Filter过滤掉不符合要求的然后在回表到server层去过滤Table Filter 即找到comment not null的记录在该条记录上加X锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号