
Llama3学习记录
Llama3学习记录
Llama3是一个稠密的transformer网络模型,应用于预测文本序列的下一个token。相较于先前版本的Llama模型,其性能提升主要来自于数据质量的提升以及多样性,并且也受益于模型参数的增加
1. 网络架构
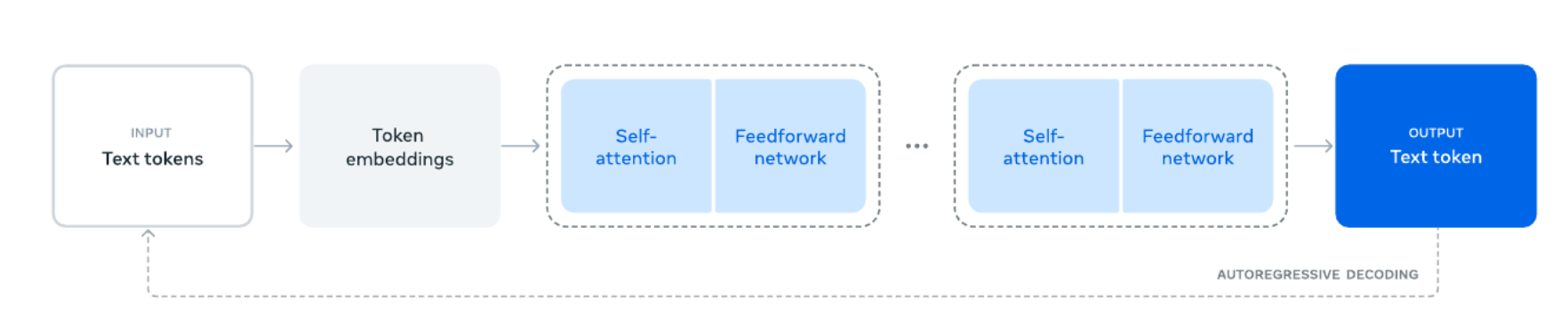
- 由上图可知,Llama3是一个decoder only的网络模型
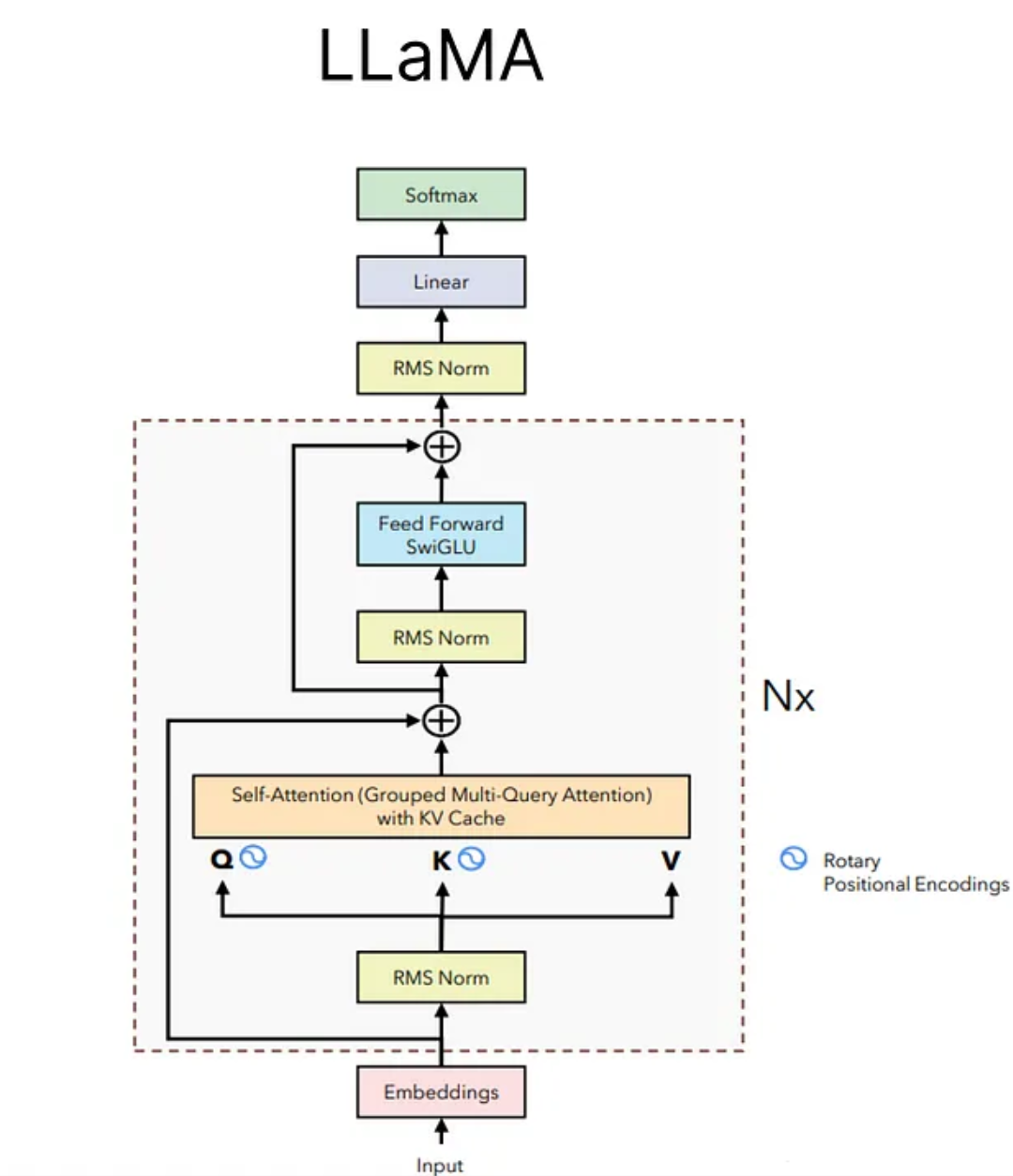
- Llama3模型具体架构层如上图,可以看到,Llama模型使用了前置的RMSNorm层,并且在注意力机制中采用了GQA架构,并且在Q、K上使用了RoPE旋转位置编码
- 由于模型是预测下一个token,因此Llama在训练时,会mask掉卫位于当前token之后的token
2. 核心概念
2.1 RMSNorm:
RMSNorm是LayerNorm的变体,通过激活值的均方根来实现归一化
优点:
- 不计算均值,相比于LayerNorm,减少了计算开销
- 避免了过度归一化,使得训练更加稳定:没有对均值进行归一化,只归一化方差,因此可以保留均值的信息,减少对信息的破坏
2.1.1 计算步骤:
- 计算均方根值RMS(x):对输入的特征x计算其均方根值,x是输入特征向量,n是特征维度

- 进行归一化,利用计算的均方根进行归一化:

- 可以通过可学习的参数进行缩放和平移,g是缩放参数,b是平移参数
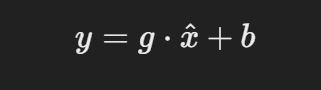
2.1.2 代码实现:
# 计算归一化结果并进行缩放(self.weight为缩放参数) # torch.rsqrt:计算每个元素平方根的倒数 class RMSNorm(torch.nn.Module): def __init__(self, dim: int, eps: float): super().__init__() self.eps = eps self.weight = nn.Parameter(torch.ones(dim)) def _norm(self, x): return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) def forward(self, x): output = self._norm(x.float()).type_as(x) return output * self.weight
2.2 Rope:旋转位置编码
- 对于输入的向量进行分解,看作多个二维向量的组合。Rope对每个二位向量进行旋转变换,对于位置p,旋转角度公式为:
 ,其中
,其中 是一个伴随维度变化的常数,用来控制旋转速度,每个二维向量的旋转公式为:
是一个伴随维度变化的常数,用来控制旋转速度,每个二维向量的旋转公式为:
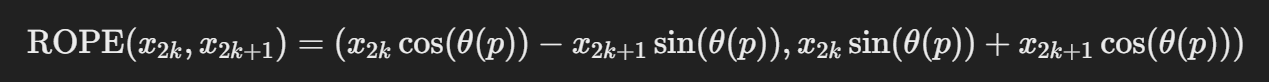
- 其计算的矩阵形式为:
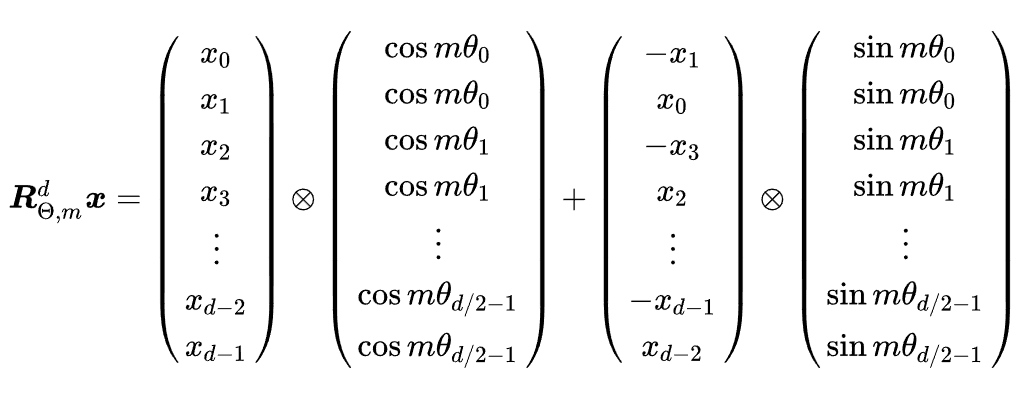
- Rope会随着相对位置的增加,逐渐减小
- 代码实现:
# 计算频率矩阵,返回余弦和正弦的频率矩阵 def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0): freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)) t = torch.arange(end, device=freqs.device) freqs = torch.outer(t, freqs).float() freqs_cos = torch.cos(freqs) freqs_sin = torch.sin(freqs) return freqs_cos, freqs_sin def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor): ndim = x.ndim assert 0 <= 1 < ndim assert freqs_cis.shape == (x.shape[1], x.shape[-1]) shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)] return freqs_cis.view(shape) def apply_rotary_emb( xq: torch.Tensor, xk: torch.Tensor, freqs_cos: torch.Tensor, freqs_sin: torch.Tensor ) -> Tuple[torch.Tensor, torch.Tensor]: # 重塑 xq 和 xk,使其与复数表示相匹配 xq_r, xq_i = xq.float().reshape(xq.shape[:-1] + (-1, 2)).unbind(-1) xk_r, xk_i = xk.float().reshape(xk.shape[:-1] + (-1, 2)).unbind(-1) # 重塑形为了广播 freqs_cos = reshape_for_broadcast(freqs_cos, xq_r) freqs_sin = reshape_for_broadcast(freqs_sin, xq_r) # 应用旋转嵌入 xq_out_r = xq_r * freqs_cos - xq_i * freqs_sin xq_out_i = xq_r * freqs_sin + xq_i * freqs_cos xk_out_r = xk_r * freqs_cos - xk_i * freqs_sin xk_out_i = xk_r * freqs_sin + xk_i * freqs_cos # 将最后两维度拉平。 xq_out = torch.stack([xq_out_r, xq_out_i], dim=-1).flatten(3) xk_out = torch.stack([xk_out_r, xk_out_i], dim=-1).flatten(3) return xq_out.type_as(xq), xk_out.type_as(xk)
2.3 Attn实现
class Attention(nn.Module): def __init__(self, args: ModelArgs): super().__init__() self.group = args.n_group self.heads = args.n_heads self.kv_heads = args.n_heads // args.n_group assert args.n_heads % self.kv_heads == 0 self.head_dim = args.dim // args.n_heads self.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False) self.wk = nn.Linear(args.dim, self.kv_heads * self.head_dim, bias=False) self.wv = nn.Linear(args.dim, self.kv_heads * self.head_dim, bias=False) self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False) self.attn_dropout = nn.Dropout(args.dropout) self.resid_dropout = nn.Dropout(args.dropout) self.dropout = args.dropout mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf")) mask = torch.triu(mask, diagonal=1) self.register_buffer("mask", mask) def forward( self, x: torch.Tensor, freqs_cos: torch.Tensor, freqs_sin: torch.Tensor, ): bsz, seqlen, _ = x.shape # QKV xq, xk, xv = self.wq(x), self.wk(x), self.wv(x) xq = xq.view(bsz, seqlen, self.heads, self.head_dim) xk = xk.view(bsz, seqlen, self.kv_heads, self.head_dim) xv = xv.view(bsz, seqlen, self.kv_heads, self.head_dim) # RoPE relative positional embeddings xq, xk = apply_rotary_emb(xq, xk, freqs_cos, freqs_sin) # grouped multiquery attention: expand out keys and values xk = repeat_kv(xk, self.group) # (bs, seqlen, n_local_heads, head_dim) xv = repeat_kv(xv, self.group) # (bs, seqlen, n_local_heads, head_dim) # make heads into a batch dimension xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim) xk = xk.transpose(1, 2) xv = xv.transpose(1, 2) # 先不使用flash attn,从零走一遍流程! scores = torch.matmul(xq, xk.transpose(2, 3)) / math.sqrt(self.head_dim) assert hasattr(self, 'mask') scores = scores + self.mask[:, :, :seqlen, :seqlen] # (bs, n_local_heads, seqlen, cache_len + seqlen) scores = F.softmax(scores.float(), dim=-1).type_as(xq) scores = self.attn_dropout(scores) output = torch.matmul(scores, xv) # (bs, n_local_heads, seqlen, head_dim) # restore time as batch dimension and concat heads output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1) # 最终送入output层并正则,得到最终结果。 output = self.wo(output) output = self.resid_dropout(output) return output
3. Llama3本地部署
按照HF库中文档的简单部署与使用
import transformers import torch model_id = "meta-llama/Meta-Llama-3-8B" pipeline = transformers.pipeline( "text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto" ) pipeline("Hey how are you doing today?")
- 本地部署以及webui使用:
其他
● tokenizer:文本的token id是由特定的tokenizer获得的,tokenizer需要进行训练,可以使用spm.SentencePieceTrainer.train()来训练自己的tokenizer
● 文本输入到tokenizer后,会首先进行分词,然后获得对应的token_ID
● token_ID会输入到后续的embedding层,或的分词后的向量表示
● 训练使用的数据集为:TinyStory


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律