


OO第一单元总结
OO第一单元总结
代码分析
第一次作业
UML类图分析
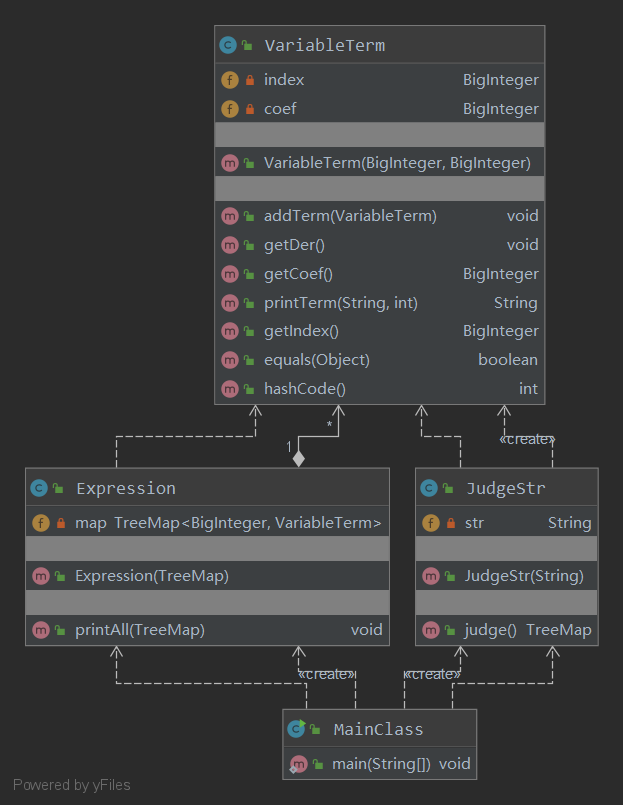
在本次作业中设计四个类,MainClass类中读入,然后送入JudgeStr类中处理,因为没有WF判断,所以直接替换所有的空格符号,用正则表达式匹配每一项,group()方法得到系数、指数后建立新的项,即VariableTerm的一个新的对象,调用VariableTerm类的getDer()方法得到求导后的项,所有的项存储在Treemap,由Expression类进行管理,输出时在MainClass中调用Expression类的printAll()方法,在VariableTerm类中实现printTerm()方法,并且在printTerm()方法中进行性能优化。
代码复杂度分析
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| workone.Expression.Expression(TreeMap) | 1 | 1 | 1 |
| workone.Expression.printAll(TreeMap) | 3 | 5 | 5 |
| workone.JudgeStr.JudgeStr(String) | 1 | 1 | 1 |
| workone.JudgeStr.judge() | 1 | 9 | 11 |
| workone.MainClass.main(String[]) | 1 | 1 | 1 |
| workone.VariableTerm.VariableTerm(BigInteger,BigInteger) | 1 | 1 | 1 |
| workone.VariableTerm.addTerm(VariableTerm) | 1 | 1 | 1 |
| workone.VariableTerm.equals(Object) | 3 | 2 | 4 |
| workone.VariableTerm.getCoef() | 1 | 1 | 1 |
| workone.VariableTerm.getDer() | 1 | 2 | 2 |
| workone.VariableTerm.getIndex() | 1 | 1 | 1 |
| workone.VariableTerm.hashCode() | 1 | 1 | 1 |
| workone.VariableTerm.printTerm(String,int) | 4 | 4 | 12 |
本次作业整体复杂度较低,由于字符串判断以及创建VariableTerm对象全都在judege()方法中,导致该方法复杂度较高,同时输出优化的printTerm()方法的复杂度也较高、耦合度较高,在这些方面还存在着面向过程的思维方式。
代码行数分析
| Project Name | Package Name | Type Name | Method Name | LOC | CC | PC |
|---|---|---|---|---|---|---|
| work1 | workone | Expression | Expression | 3 | 1 | 1 |
| work1 | workone | Expression | printAll | 26 | 5 | 1 |
| work1 | workone | JudgeStr | JudgeStr | 3 | 1 | 1 |
| work1 | workone | JudgeStr | judge | 54 | 11 | 0 |
| work1 | workone | MainClass | main | 9 | 1 | 1 |
| work1 | workone | VariableTerm | VariableTerm | 4 | 1 | 2 |
| work1 | workone | VariableTerm | addTerm | 3 | 1 | 1 |
| work1 | workone | VariableTerm | getDer | 9 | 2 | 0 |
| work1 | workone | VariableTerm | getCoef | 3 | 1 | 0 |
| work1 | workone | VariableTerm | printTerm | 53 | 12 | 2 |
| work1 | workone | VariableTerm | getIndex | 3 | 1 | 0 |
| work1 | workone | VariableTerm | equals | 10 | 3 | 1 |
| work1 | workone | VariableTerm | hashCode | 3 | 1 | 0 |
从代码行数中也可看出judge()和printTerm()行数较多,其复杂度也较高。
第二次作业
UML类图分析
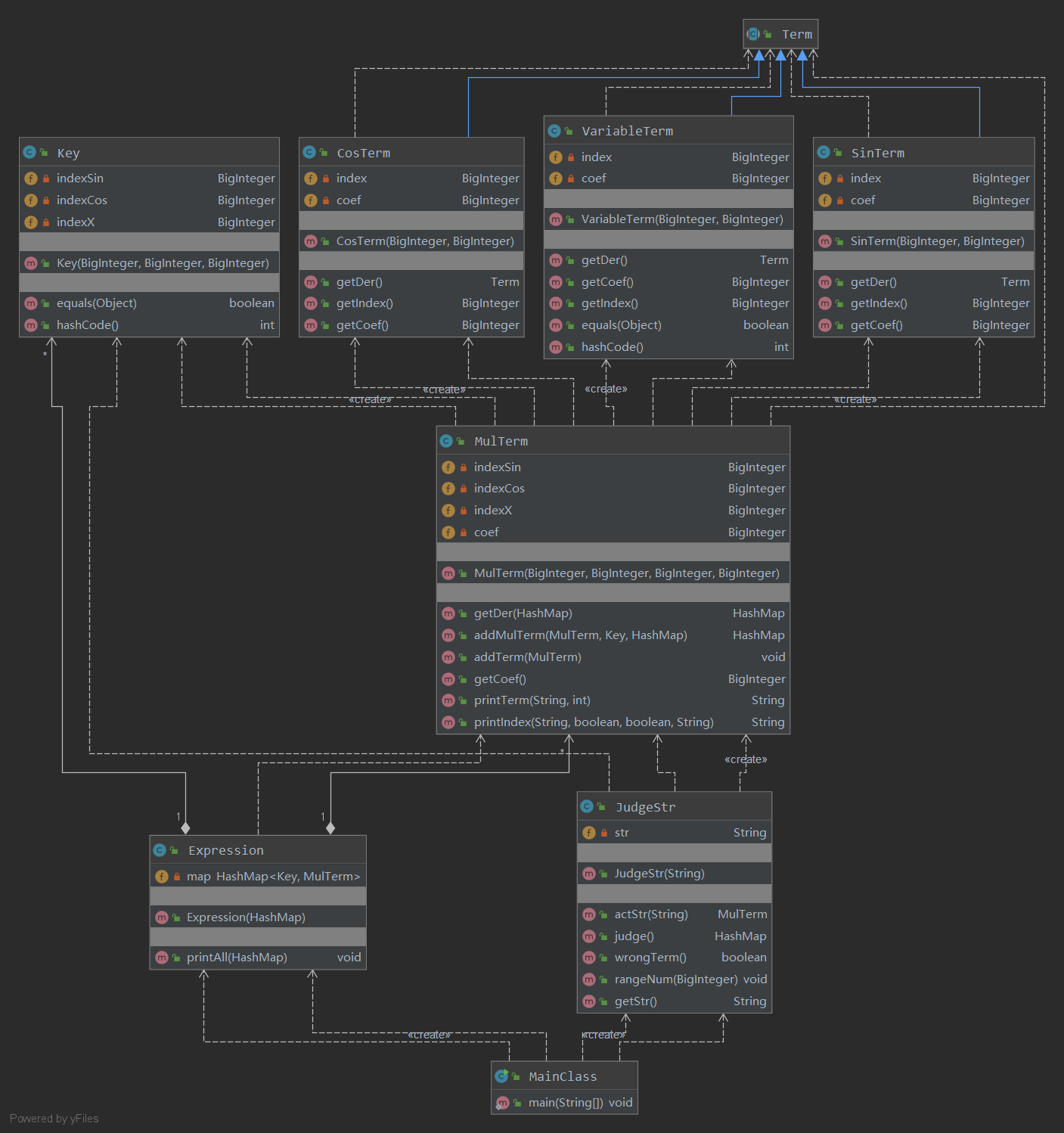
在本次作业中,部分类及方法沿用了第一次作业的设计,例如:Expression类依然管理每一项(即MulTerm的每个对象),通过HashMap存储,重写hashCode()方法和equals()方法便于合并同类项,在JudgeStr类中进行字符串的判断、WF判断以及创建每一项。但在本次作业中添加了三角函数,所以在作业中增加了SinTerm类和CosTerm类,并且与VariableTerm类都继承自抽象类Term类,在每个类中实现了求导方法,并且将第一次作业中的大正则表达式修改为层次化的表达式,便于在第三次作业中的扩展。
代码复杂度分析
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| worktwo.CosTerm.CosTerm(BigInteger,BigInteger) | 1 | 1 | 1 |
| worktwo.CosTerm.getCoef() | 1 | 1 | 1 |
| worktwo.CosTerm.getDer() | 1 | 1 | 1 |
| worktwo.CosTerm.getIndex() | 1 | 1 | 1 |
| worktwo.Expression.Expression(HashMap) | 1 | 1 | 1 |
| worktwo.Expression.printAll(HashMap) | 3 | 5 | 5 |
| worktwo.JudgeStr.JudgeStr(String) | 1 | 1 | 1 |
| worktwo.JudgeStr.actStr(String) | 1 | 10 | 11 |
| worktwo.JudgeStr.getStr() | 1 | 1 | 1 |
| worktwo.JudgeStr.judge() | 2 | 3 | 4 |
| worktwo.JudgeStr.rangeNum(BigInteger) | 1 | 2 | 3 |
| worktwo.JudgeStr.wrongTerm() | 2 | 1 | 2 |
| worktwo.Key.Key(BigInteger,BigInteger,BigInteger) | 1 | 1 | 1 |
| worktwo.Key.equals(Object) | 3 | 4 | 6 |
| worktwo.Key.hashCode() | 1 | 1 | 1 |
| worktwo.MainClass.main(String[]) | 1 | 2 | 2 |
| worktwo.MulTerm.MulTerm(BigInteger,BigInteger,BigInteger,BigInteger) | 1 | 1 | 1 |
| worktwo.MulTerm.addMulTerm(MulTerm,Key,HashMap) | 1 | 2 | 2 |
| worktwo.MulTerm.addTerm(MulTerm) | 1 | 1 | 1 |
| worktwo.MulTerm.getCoef() | 1 | 1 | 1 |
| worktwo.MulTerm.getDer(HashMap) | 2 | 4 | 5 |
| worktwo.MulTerm.printIndex(String,boolean,boolean,String) | 1 | 4 | 8 |
| worktwo.MulTerm.printTerm(String,int) | 3 | 9 | 14 |
| worktwo.SinTerm.SinTerm(BigInteger,BigInteger) | 1 | 1 | 1 |
| worktwo.SinTerm.getCoef() | 1 | 1 | 1 |
| worktwo.SinTerm.getDer() | 1 | 1 | 1 |
| worktwo.SinTerm.getIndex() | 1 | 1 | 1 |
| worktwo.VariableTerm.VariableTerm(BigInteger,BigInteger) | 1 | 1 | 1 |
| worktwo.VariableTerm.equals(Object) | 3 | 2 | 4 |
| worktwo.VariableTerm.getCoef() | 1 | 1 | 1 |
| worktwo.VariableTerm.getDer() | 1 | 2 | 2 |
| worktwo.VariableTerm.getIndex() | 1 | 1 | 1 |
| worktwo.VariableTerm.hashCode() | 1 | 1 | 1 |
在本次作业中,因为将字符串的判断处理设计在actStr()方法中,导致该方法复杂度较高,不利于第三次作业扩展,并且将输出处理及优化集中在Term类中,而没有在每个因子类中实现,导致了该部分在第三次作业中需要重构。
代码行数分析
| Package Name | Type Name | Method Name | LOC | CC | PC |
|---|---|---|---|---|---|
| worktwo | CosTerm | CosTerm | 4 | 1 | 2 |
| worktwo | CosTerm | getDer | 6 | 1 | 0 |
| worktwo | CosTerm | getIndex | 3 | 1 | 0 |
| worktwo | CosTerm | getCoef | 3 | 1 | 0 |
| worktwo | Expression | Expression | 3 | 1 | 1 |
| worktwo | Expression | printAll | 26 | 5 | 1 |
| worktwo | JudgeStr | JudgeStr | 3 | 1 | 1 |
| worktwo | JudgeStr | actStr | 61 | 11 | 1 |
| worktwo | JudgeStr | judge | 36 | 4 | 0 |
| worktwo | JudgeStr | wrongTerm | 8 | 2 | 0 |
| worktwo | JudgeStr | rangeNum | 6 | 2 | 1 |
| worktwo | JudgeStr | getStr | 3 | 1 | 0 |
| worktwo | Key | Key | 5 | 1 | 3 |
| worktwo | Key | equals | 10 | 3 | 1 |
| worktwo | Key | hashCode | 3 | 1 | 0 |
| worktwo | MainClass | main | 14 | 2 | 1 |
| worktwo | MulTerm | MulTerm | 6 | 1 | 4 |
| worktwo | MulTerm | getDer | 37 | 5 | 1 |
| worktwo | MulTerm | addMulTerm | 10 | 2 | 3 |
| worktwo | MulTerm | addTerm | 3 | 1 | 1 |
| worktwo | MulTerm | getCoef | 3 | 1 | 0 |
| worktwo | MulTerm | printTerm | 66 | 14 | 2 |
| worktwo | MulTerm | printIndex | 32 | 7 | 4 |
| worktwo | SinTerm | SinTerm | 4 | 1 | 2 |
| worktwo | SinTerm | getDer | 6 | 1 | 0 |
| worktwo | SinTerm | getIndex | 3 | 1 | 0 |
| worktwo | SinTerm | getCoef | 3 | 1 | 0 |
| worktwo | VariableTerm | VariableTerm | 4 | 1 | 2 |
| worktwo | VariableTerm | getDer | 11 | 2 | 0 |
| worktwo | VariableTerm | getCoef | 3 | 1 | 0 |
| worktwo | VariableTerm | getIndex | 3 | 1 | 0 |
| worktwo | VariableTerm | equals | 10 | 3 | 1 |
| worktwo | VariableTerm | hashCode | 3 | 1 | 0 |
从代码行数中,也可看出actStr()方法和printTerm()方法行数较多、较为复杂、耦合度较高,这部分设计不够合理。同时在这次设计中,没有设计常数因子,而是作为MulTerm类的系数,虽然使第一次作业中代码的重构部分减少,但不利于第三次作业中的扩展。
第三次作业
UML图分析
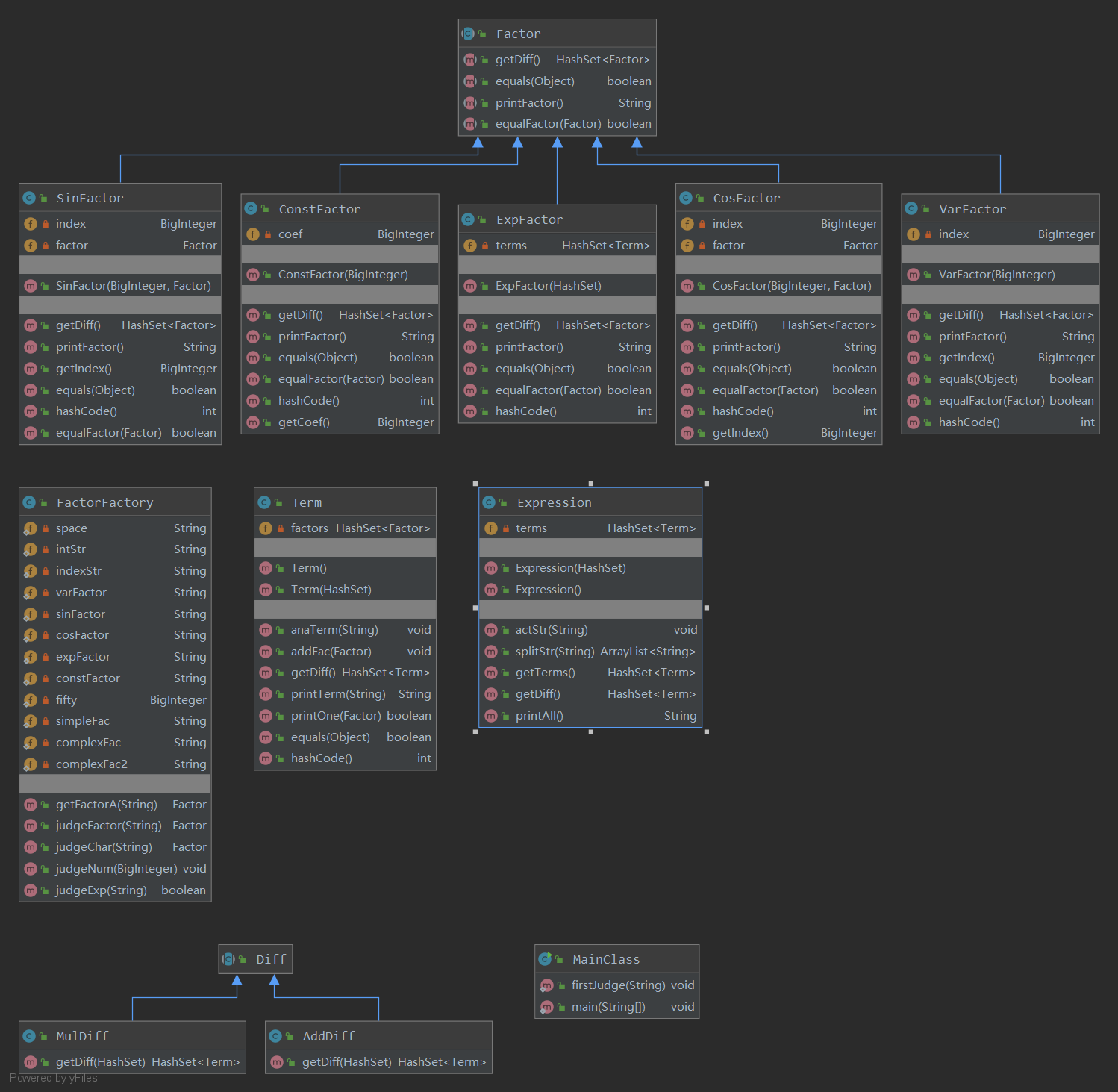
在本次作业中,增加了表达式因子和sin/cos因子嵌套,结构较为复杂,所以大部分代码都进行了重构。
五种因子VarFactor,ConstFactor,ExpFactor,CosFactor,SinFactor都继承了抽象类Factor,并重写了父类的求导方法getDiff()、输出方法printFactor()以及equals()方法。整体层次上有Expression类(即表达式),Term类(即项),Factor类(即因子),层层调用。先对字符串进行预处理,替换有符号整数的正负号和指数的**,然后在Expression类中将字符串根据+-进行分割,对分割后的每一项的字符串在Term类中根据*进行分割。在本次作业中也有一些工厂模式的影子,分割后的因子字符串送入FactorFactory进行正则匹配检查,并且返回生成的Factor子类的对象。
在求导的时候,增加了AddDiff和MulDiff两个类,在两个类中有各自的求导规则,继承了抽象类Diff,Expression会调用AddDiff类的AddDiff()方法,AddDiff()方法逐项调用Term类的getDiff()方法,getDiff()方法调用MulDiff类的MulDiff()方法,而在该方法中会调用每个因子的getDiff()方法,传入传出参数均为HashSet。
每个Expression的对象有一个HashSet成员变量存储Term对象,每个Term的对象有一个HashSet成员变量存储Factor对象,并且为了层次清晰,选择了将Expression和ExpFactor设计为两个类,而在ExpFactor中会调用Expression类的部分方法。在Factor类及子类重写equals()方法即hashcode()方法之后,每次增加新的因子都会调用这两个方法,直接合并同类因子,无需再写一个方法进行遍历或者其他操作,虽然这种设计让合并因子十分简单,但存在一定隐患。
代码复杂度分析
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| workthree.AddDiff.getDiff(HashSet) | 1 | 2 | 2 |
| workthree.ConstFactor.ConstFactor(BigInteger) | 1 | 1 | 1 |
| workthree.ConstFactor.equalFactor(Factor) | 3 | 3 | 4 |
| workthree.ConstFactor.equals(Object) | 3 | 3 | 4 |
| workthree.ConstFactor.getCoef() | 1 | 1 | 1 |
| workthree.ConstFactor.getDiff() | 1 | 1 | 1 |
| workthree.ConstFactor.hashCode() | 1 | 1 | 1 |
| workthree.ConstFactor.printFactor() | 1 | 1 | 1 |
| workthree.CosFactor.CosFactor(BigInteger,Factor) | 1 | 1 | 1 |
| workthree.CosFactor.equalFactor(Factor) | 3 | 4 | 5 |
| workthree.CosFactor.equals(Object) | 4 | 4 | 5 |
| workthree.CosFactor.getDiff() | 1 | 1 | 1 |
| workthree.CosFactor.getIndex() | 1 | 1 | 1 |
| workthree.CosFactor.hashCode() | 1 | 1 | 1 |
| workthree.CosFactor.printFactor() | 1 | 3 | 3 |
| workthree.ExpFactor.ExpFactor(HashSet) | 1 | 1 | 1 |
| workthree.ExpFactor.equalFactor(Factor) | 2 | 3 | 3 |
| workthree.ExpFactor.equals(Object) | 3 | 2 | 4 |
| workthree.ExpFactor.getDiff() | 1 | 1 | 1 |
| workthree.ExpFactor.hashCode() | 1 | 1 | 1 |
| workthree.ExpFactor.printFactor() | 1 | 1 | 2 |
| workthree.Expression.Expression() | 1 | 1 | 1 |
| workthree.Expression.Expression(HashSet) | 1 | 1 | 1 |
| workthree.Expression.actStr(String) | 1 | 2 | 2 |
| workthree.Expression.getDiff() | 1 | 1 | 1 |
| workthree.Expression.getTerms() | 1 | 1 | 1 |
| workthree.Expression.printAll() | 1 | 2 | 3 |
| workthree.Expression.splitStr(String) | 1 | 4 | 7 |
| workthree.FactorFactory.getFactorA(String) | 3 | 5 | 5 |
| workthree.FactorFactory.judgeChar(String) | 2 | 5 | 10 |
| workthree.FactorFactory.judgeExp(String) | 2 | 1 | 2 |
| workthree.FactorFactory.judgeFactor(String) | 4 | 11 | 11 |
| workthree.FactorFactory.judgeNum(BigInteger) | 3 | 2 | 3 |
| workthree.MainClass.firstJudge(String) | 2 | 3 | 4 |
| workthree.MainClass.main(String[]) | 1 | 2 | 2 |
| workthree.MulDiff.getDiff(HashSet) | 4 | 4 | 4 |
| workthree.SinFactor.SinFactor(BigInteger,Factor) | 1 | 1 | 1 |
| workthree.SinFactor.equalFactor(Factor) | 3 | 4 | 5 |
| workthree.SinFactor.equals(Object) | 4 | 4 | 5 |
| workthree.SinFactor.getDiff() | 1 | 1 | 1 |
| workthree.SinFactor.getIndex() | 1 | 1 | 1 |
| workthree.SinFactor.hashCode() | 1 | 1 | 1 |
| workthree.SinFactor.printFactor() | 1 | 3 | 3 |
| workthree.Term.Term() | 1 | 1 | 1 |
| workthree.Term.Term(HashSet) | 1 | 1 | 1 |
| workthree.Term.addFac(Factor) | 7 | 7 | 7 |
| workthree.Term.anaTerm(String) | 4 | 7 | 17 |
| workthree.Term.equals(Object) | 3 | 2 | 4 |
| workthree.Term.getDiff() | 1 | 1 | 1 |
| workthree.Term.hashCode() | 1 | 1 | 1 |
| workthree.Term.printOne(Factor) | 9 | 5 | 9 |
| workthree.Term.printTerm(String) | 6 | 9 | 16 |
| workthree.VarFactor.VarFactor(BigInteger) | 1 | 1 | 1 |
| workthree.VarFactor.equalFactor(Factor) | 3 | 3 | 4 |
| workthree.VarFactor.equals(Object) | 3 | 3 | 4 |
| workthree.VarFactor.getDiff() | 1 | 1 | 1 |
| workthree.VarFactor.getIndex() | 1 | 1 | 1 |
| workthree.VarFactor.hashCode() | 1 | 1 | 1 |
| workthree.VarFactor.printFactor() | 1 | 2 | 3 |
| workthree.WfException.WfException() | 1 | 1 | 1 |
因为根据*将每一项的字符串分割为因子的过程,需判断正负号和是否处于嵌套中,较为复杂,导致Term类中anaTerm()方法的复杂度较高,并且对于输出的优化,有关正负号和±1的判断较为繁杂,导致printTerm()方法和其他有关输出优化方法的复杂度也比较高。将匹配正则表达式和创建Factor子类设计在工厂类FactorFactory后,其复杂度和耦合度都比较高,可以考虑将创建对象与匹配正则表达式分离或者在每个Factor子类中完成降低复杂度。
在重写的equals()方法中,判断同类因子后直接修改了后者的成员变量,虽然能方便地合并同类因子,但这个设计让代码复用性变得很差,给深度判断是否合并时带来了极大的不便,较为复杂嵌套因子以及项无法判断合并,虽然最后增加了equalFactor()方法,在深度判断的时候调用equalFactor()方法,但也只是亡羊补牢,这部分代码复杂度较高。
代码行数分析
| Package Name | Type Name | NOF | NOPF | NOM | NOPM | LOC | WMC | NC | DIT | LCOM | FANIN | FANOUT |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| workthree | AddDiff | 0 | 0 | 1 | 1 | 11 | 2 | 0 | 1 | -1 | 1 | 1 |
| workthree | ConstFactor | 1 | 0 | 7 | 7 | 48 | 11 | 0 | 1 | 0.428571 | 6 | 2 |
| workthree | CosFactor | 2 | 0 | 7 | 7 | 67 | 14 | 0 | 1 | 0 | 4 | 4 |
| workthree | Diff | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | -1 | 0 | 0 |
| workthree | ExpFactor | 1 | 0 | 6 | 6 | 49 | 10 | 0 | 1 | 0 | 2 | 4 |
| workthree | Expression | 1 | 0 | 7 | 7 | 63 | 15 | 0 | 0 | 0 | 3 | 2 |
| workthree | Factor | 0 | 0 | 4 | 4 | 6 | 4 | 5 | 0 | -1 | 9 | 1 |
| workthree | FactorFactory | 12 | 0 | 5 | 5 | 140 | 26 | 0 | 0 | 0.4 | 2 | 8 |
| workthree | MainClass | 0 | 0 | 2 | 2 | 30 | 3 | 0 | 0 | -1 | 1 | 3 |
| workthree | MulDiff | 0 | 0 | 1 | 1 | 24 | 4 | 0 | 1 | -1 | 1 | 2 |
| workthree | SinFactor | 2 | 0 | 7 | 7 | 67 | 14 | 0 | 1 | 0 | 4 | 4 |
| workthree | Term | 1 | 0 | 9 | 9 | 185 | 46 | 0 | 0 | 0.222222 | 4 | 8 |
| workthree | VarFactor | 1 | 0 | 7 | 7 | 59 | 13 | 0 | 1 | 0.285714 | 3 | 3 |
| workthree | WfException | 0 | 0 | 1 | 1 | 5 | 1 | 0 | 0 | -1 | 2 | 0 |
由代码行数和FANOUT也可以看出Term类和FactorFactory类承载的功能过多,需要进一步分解。
在ImplementationSmells的指标中,可发现Magic Number较多,也存在一些Complex Conditional,是一种不好的变成习惯。(共计29次,表格不再展示)
分析bug
自己程序的bug
- 第一次作业中,强测和互测均未出现bug。测试时主要根据指导书,构造各种测试样例,逐步增加测试样例的复杂度,并且着重测试了一些特殊的数据,如结果为0或1,或系数为1或-1,或指数为1或-1或0.
- 第二次作业中,强测和互测均未出现bug。测试时在第一次的基础上增加了一些有关三角函数因子的测试和WF测试。
- 第三次作业中,强侧未出现bug。因为没有进行更多的优化改变
ExpFactor因子,只是在输出的时候判断是否需要加括号,使得有一种情况下,程序会错误地判断为不需要加括号,在互测中被hack3次。
互测中的bug
- 第一次互测,根据上述提到的特殊数据,hack成功。
- 第三次互测,在阅读代码后,手动构建了一些测试样例,hack成功。
对象创建模式
- 五种因子
VarFactor,ConstFactor,ExpFactor,CosFactor,SinFactor都继承了抽象类Factor,并重写了父类的求导方法getDiff()、输出方法printFactor()以及equals()方法。 - 增加了
AddDiff和MulDiff两个类,在两个类中有各自的求导规则,继承了抽象类Diff。 - 整体层次上有
Expression类(即表达式),Term类(即项),Factor类(即因子),处理字符串、求导和输出过程中都层层调用。 - 应用了工厂模式,在
FactorFactory进行正则匹配检查,并且返回创建的Factor子类的对象。 - 第二次作业仅在第一次作业基础上增加了一些类,而第三次作业则进行了上述方面的重构。
对比和心得体会
本单元作业复杂度的逐渐上升,让我对面向对象的思想有了更深刻的认识。从刚开始在一个类中集中地处理求导、输出功能,到学会将这些功能分解到每个类中,为后面的迭代开发留下空间。构建层次化的设计,使代码的脉络清晰,并且在这个过程中用到了工厂模式的思想。但在这个过程中还存在一些问题:
- 在第三次作业中,有一些类还是承担了较多的功能,使方法复杂度、耦合度较高,应该进一步分解,将功能分配给子类或新创建的类。
- 在最初设计的时候,着重完成基础功能,几乎没有考虑性能的优化,一些方法虽然使基础功能的实现变得简单,但是对优化造成了困难,使最后一些优化在已经较为完整的设计中,有点像缝缝补补,最后也是因此出现了bug,在互测中被hack。
- 没有实现自动化测试,手动构造测试样例颇为艰辛,并且覆盖性很差。
- 在重写
equals()方法时忽略了代码的复用性,给后续造成了很多问题。 - 存在一些不好的编程习惯,如:Magic Number、Complex Conditional等。
在本单元的学习中,我获益匪浅。在讨论区和优秀代码中学习到了一些不同的思路和处理问题的方法,给了我很大启发。希望能在今后的学习和练习中,能改善问题,有更好的设计。

