
C#网络爬虫--多线程处理强化版
上次做了一个帮公司妹子做了爬虫,不是很精致,这次公司项目里要用到,于是有做了一番修改,功能添加了网址图片采集,下载,线程处理界面网址图片下载等。
说说思路:首相获取初始网址的所有内容 在初始网址采集图片 去初始网址采集链接 把采集到的链接放入队列 继续采集图片,然后继续采集链接,无限循环
还是上图片大家看一下,在上代码!
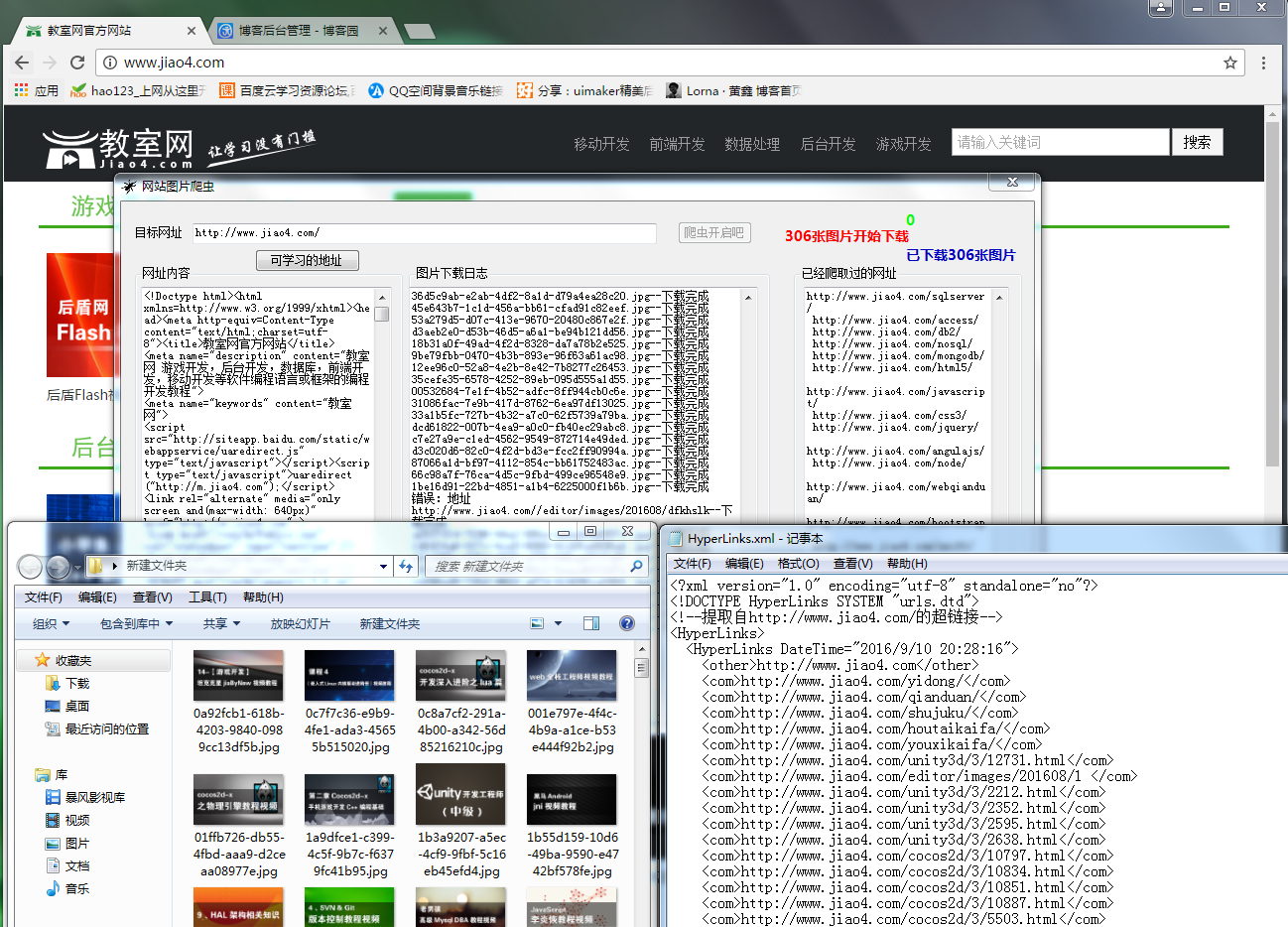
处理网页内容抓取跟网页网址爬取都做了改进,下面还是大家来看看代码,有不足之处,还请之处!
网页内容抓取HtmlCodeRequest,
网页网址爬取GetHttpLinks,用正则去筛选html中的Links
图片抓取GetHtmlImageUrlList,用正则去筛选html中的Img
都写进了一个封装类里面 HttpHelper
/// <summary> /// 取得HTML中所有图片的 URL。 /// </summary> /// <param name="sHtmlText">HTML代码</param> /// <returns>图片的URL列表</returns> public static string HtmlCodeRequest(string Url) { if (string.IsNullOrEmpty(Url)) { return ""; } try { //创建一个请求 HttpWebRequest httprequst = (HttpWebRequest)WebRequest.Create(Url); //不建立持久性链接 httprequst.KeepAlive = true; //设置请求的方法 httprequst.Method = "GET"; //设置标头值 httprequst.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705"; httprequst.Accept = "*/*"; httprequst.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5"); httprequst.ServicePoint.Expect100Continue = false; httprequst.Timeout = 5000; httprequst.AllowAutoRedirect = true;//是否允许302 ServicePointManager.DefaultConnectionLimit = 30; //获取响应 HttpWebResponse webRes = (HttpWebResponse)httprequst.GetResponse(); //获取响应的文本流 string content = string.Empty; using (System.IO.Stream stream = webRes.GetResponseStream()) { using (System.IO.StreamReader reader = new StreamReader(stream, System.Text.Encoding.GetEncoding("utf-8"))) { content = reader.ReadToEnd(); } } //取消请求 httprequst.Abort(); //返回数据内容 return content; } catch (Exception) { return ""; } } /// <summary> /// 提取页面链接 /// </summary> /// <param name="html"></param> /// <returns></returns> public static List<string> GetHtmlImageUrlList(string url) { string html = HttpHelper.HtmlCodeRequest(url); if (string.IsNullOrEmpty(html)) { return new List<string>(); } // 定义正则表达式用来匹配 img 标签 Regex regImg = new Regex(@"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""'<>]*)[^<>]*?/?[\s\t\r\n]*>", RegexOptions.IgnoreCase); // 搜索匹配的字符串 MatchCollection matches = regImg.Matches(html); List<string> sUrlList = new List<string>(); // 取得匹配项列表 foreach (Match match in matches) sUrlList.Add(match.Groups["imgUrl"].Value); return sUrlList; } /// <summary> /// 提取页面链接 /// </summary> /// <param name="html"></param> /// <returns></returns> public static List<string> GetHttpLinks(string url) { //获取网址内容 string html = HttpHelper.HtmlCodeRequest(url); if (string.IsNullOrEmpty(html)) { return new List<string>(); } //匹配http链接 const string pattern2 = @"http(s)?://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?"; Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase); //获得匹配结果 MatchCollection m2 = r2.Matches(html); List<string> links = new List<string>(); foreach (Match url2 in m2) { if (StringHelper.CheckUrlIsLegal(url2.ToString()) || !StringHelper.IsPureUrl(url2.ToString()) || links.Contains(url2.ToString())) continue; links.Add(url2.ToString()); } //匹配href里面的链接 const string pattern = @"(?i)<a\s[^>]*?href=(['""]?)(?!javascript|__doPostBack)(?<url>[^'""\s*#<>]+)[^>]*>"; ; Regex r = new Regex(pattern, RegexOptions.IgnoreCase); //获得匹配结果 MatchCollection m = r.Matches(html); foreach (Match url1 in m) { string href1 = url1.Groups["url"].Value; if (!href1.Contains("http")) { href1 = Global.WebUrl + href1; } if (!StringHelper.IsPureUrl(href1) || links.Contains(href1)) continue; links.Add(href1); } return links; }
这边下载图片有个任务条数限制,限制是200条。如果超过的话线程等待5秒,这里下载图片是异步调用的委托
public string DownLoadimg(string url) { if (!string.IsNullOrEmpty(url)) { try { if (!url.Contains("http")) { url = Global.WebUrl + url; } HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Timeout = 2000; request.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705"; //是否允许302 request.AllowAutoRedirect = true; WebResponse response = request.GetResponse(); Stream reader = response.GetResponseStream(); //文件名 string aFirstName = Guid.NewGuid().ToString(); //扩展名 string aLastName = url.Substring(url.LastIndexOf(".") + 1, (url.Length - url.LastIndexOf(".") - 1)); FileStream writer = new FileStream(Global.FloderUrl + aFirstName + "." + aLastName, FileMode.OpenOrCreate, FileAccess.Write); byte[] buff = new byte[512]; //实际读取的字节数 int c = 0; while ((c = reader.Read(buff, 0, buff.Length)) > 0) { writer.Write(buff, 0, c); } writer.Close(); writer.Dispose(); reader.Close(); reader.Dispose(); response.Close(); return (aFirstName + "." + aLastName); } catch (Exception) { return "错误:地址" + url; } } return "错误:地址为空"; }
话不多说,更多的需要大家自己去改进咯!欢迎读者来与楼主进行交流。如果本文对您有参考价值,欢迎帮博主点下文章下方的推荐,谢谢
有兴趣可加入企鹅群一起进步:495104593
下面源码送上:嘿嘿要分的哦!
http://download.csdn.net/detail/nightmareyan/9627215
作者:码魇
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!


您的资助是我最大的动力!
金额随意,欢迎来赏!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号