Meta 最新 SPIRIT-LM:语音文本无缝转换还能懂情绪;字节回应实习生破坏大模型训练:网传损失不实丨 RTE 开发者日报

开发者朋友们大家好:
这里是「RTE 开发者日报」,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@鲍勃
01 有话题的新闻
1、Meta 最新黑科技 SPIRIT-LM:能说会写还能懂你的情绪
Meta AI 最新推出的 SPIRIT-LM 是一款具有革命性意义的多模态基础语言模型,它能够自由混合文本和语音,并能像人类一样理解和表达情感。
SPIRIT-LM 基于预训练的文本语言模型构建,通过在文本和语音单元上进行持续训练,扩展到语音模态。该模型将语音和文本序列连接成一个单一的标记集,并使用一个小型自动管理的语音-文本平行语料库,采用词级交织方法进行训练。
SPIRIT-LM 有基础版和情感版两个版本,两个版本均使用子词 BPE 标记对文本进行编码。
SPIRIT-LM 结合了文本模型的语义能力和语音模型的表达能力,因此它能够完成跨模态的任务,如语音识别、文本转语音和语音分类,并且只需少量样本即可学习新任务。
为了评估生成模型的表达能力,研究人员引入了语音-文本情感保存基准 (STSP),该基准衡量生成模型在模态内部和跨模态情况下,对口头和书面表达的情感保存程度。
情感版 SPIRIT-LM 是第一个能够在模态内部和跨模态情况下保存文本和语音提示情感的语言模型。它利用音调和风格标记来捕捉语音的情感和风格,并通过专门设计的语音-文本情感保存基准进行评估。(@AIbase 基地)
2、微软开源 bitnet.cpp 1-bit LLM 推理框架:不靠 GPU 可本地运行千亿参数 AI 模型,能耗最多降低 82.2%
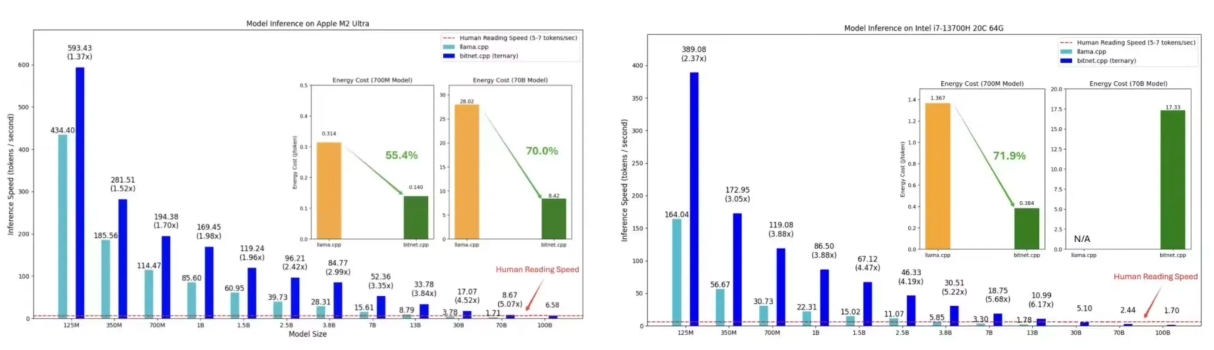
科技媒体 marktechpost 于 10 月 18 日发布博文,报道称微软公司开源了 bitnet.cpp,这是一个能够直接在 CPU 上运行、超高效的 1-bit 大语言模型(LLM)推理框架。
用户通过 bitnet.cpp 框架,不需要借助 GPU,也能在本地设备上运行具有 1000 亿参数的大语言模型,实现 6.17 倍的速度提升,且能耗可以降低 82.2%。
传统大语言模型通常需要庞大的 GPU 基础设施和大量电力,导致部署和维护成本高昂,而小型企业和个人用户因缺乏先进硬件而难以接触这些技术,而 bitnet.cpp 框架通过降低硬件要求,吸引更多用户以更低的成本使用 AI 技术。
bitnet.cpp 支持 1-bit LLMs 的高效计算,包含优化内核以最大化 CPU 推理性能,且当前支持 ARM 和 x86 CPU,未来计划扩展至 NPU、GPU 和移动设备。
根据初步测试结果,在 ARM CPU 上加速比为 1.37x 至 5.07x,x86 CPU 上为 2.37x 至 6.17x,能耗减少 55.4% 至 82.2%。
bitnet.cpp 的推出,可能重塑 LLMs 的计算范式,减少对硬件依赖,为本地 LLMs(LLLMs)铺平道路。
用户能够在本地运行模型,降低数据发送至外部服务器的需求,增强隐私保护。微软的「1-bit AI Infra」计划也在进一步推动这些模型的工业应用,bitnet.cpp 在这一进程中扮演着重要角色。(@IT 之家)
3、Meta 发布新 AI 模型:利用 AI 来评估 AI 的能力,无需人类参与
据路透社报道,Meta 当地时间周五宣布,其研究团队推出了一系列新的 AI 模型,其中包括一个名为「自我训练评估器」的工具。该工具有望推动 AI 开发过程中减少对人类干预的依赖。这个工具早前在 8 月的论文中首次亮相,其使用与 OpenAI 新发布的 o1 模型类似的「思维链」技术,让 AI 对模型的输出做出可靠判断。
这种技术将复杂问题分解为多个逻辑步骤,从而提高了在科学、编程和数学等高难度领域中的答案准确性。Meta 的研究人员使用完全由 AI 生成的数据来训练这个评估器,从而在这一过程中完全摒弃了人类的参与。
使用 AI 来评估 AI 的能力展示了实现自主 AI 智能体的可能性,这类代理能够从自身错误中学习。两位负责该项目的 Meta 研究人员表示,许多 AI 专家设想未来可以开发出「智能化程度极高」的数字助手,可以自主处理大量任务,而无需人类介入。
自我改进的模型有望减少目前使用的「基于人类反馈的强化学习」(RLHF)过程的需求。这一过程往往昂贵且低效,因为它依赖于拥有专业知识的人类来标注数据和验证复杂问题的答案是否正确。
「我们希望,随着 AI 的发展,它能超越人类,逐渐具备自行检查工作的能力,并在准确性上超过普通人类水平,」项目研究员之一 Jason Weston 说。「自我训练和评估的能力是实现超人级 AI 的关键因素之一。」他补充道。
报道称,包括谷歌和 Anthropic 在内的其他科技公司也在研究 RLAIF(基于 AI 反馈的强化学习)这一概念,但与 Meta 不同,这些公司通常不会公开发布其研究模型。(@IT 之家)
4、字节回应实习生破坏大模型训练:网传损失严重夸大
近日有媒体报道称,字节跳动大模型训练被实习生攻击,注入了破坏代码,导致其训练成果不可靠,可能需要重新训练。该实习生为某高校的博士生,因对团队资源分配不满采取了这种行动。
消息称此次事件导致字节跳动损失「8000 多卡」、「上千万美元」。
字节官方对此回应称,确有商业化技术团队实习生发生严重违纪行为,该实习生已被辞退,公司已将其行为同步给行业联盟和所在学校,交由校方处理。
字节表示,该名实习生恶意干扰商业化技术团队研究项目的模型训练任务,但并不影响商业化的正式项目及线上业务,也不涉及字节跳动大模型等其他业务。至于网传的「8000 多卡、上千万美元」损失,字节回应称属于「严重夸大」。(@ APPSO)
5、消息称部分苹果员工认为公司 AI 技术落后行业领先水平两年
科技记者 Mark Gurman 获悉,苹果公司内部有一些人认为,公司的生成式人工智能技术落后行业领先者两年。
根据 Gurman 获悉的一些苹果内部研究显示,OpenAI 的 ChatGPT 聊天机器人比苹果 Siri 准确率要高 25%,能够回答的问题多出 30%。
苹果今年推出了「Apple 智能」的 AI 功能集合,不过目前还未推出正式版,所有功能也要在明年春季左右才会完全实装。Gurman 认为目前的 Apple 智能「缺乏令人惊叹的因素」。
不过 Gurman 也指出了苹果在 AI 领域有一个「秘密优势」:能够向大量的设备推出 AI 功能,例如全新推出的 iPad mini 就能支持 Apple 智能功能。
Gurman 称,现在有五款 iPhone、大部份的 iPad 和 Mac 都支持 Apple 智能,到了 2026 年,几乎所有带屏幕的苹果设备都有望运行相关功能。Gurman 也在报道中提到,苹果可能会在今年年底更新入门级 iPad 型号,将支持 Apple 智能。(@ APPSO)
02 有态度的观点
1、OpenAI 新董事兼 CMU 机器学习系主任:虽然数据有限,但 AI 性能不会停滞不前;LLM 行业很可能会整合
OpenAI 新董事 Zico 在一次采访中提到,虽然数据有限,但 AI 性能不会停滞不前,我们当前的算法还没有从我们拥有的数据中最大限度地提取信息,还有更多的推论、推断和其他过程我们可以应用到我们当前的数据上,以提供更多的价值。随着模型变得越来越大、越来越好,它们可以通过合成数据或通过我们训练这些模型的不同机制自己做到这一点。
Zico 认为,AI 造成了人们对客观现实的信任缺失,错误信息、深度伪造和使用这些工具来传播各种错误信息的问题,这当然是一个巨大的担忧。但这一结果的最终影响并不是让人们开始相信他们看到的所有错误信息,真正的负面结果是人们将不再相信他们看到的任何东西。
人们基本上不再相信他们读到或看到的任何不符合他们当前信念的东西。我们甚至不需要 AI 就能达到这种程度,但 AI 绝对加速了这一过程。但这不是 AI 的错,当 AI 涉及到虚假信息时,它并没有发明虚假信息。「在 AI 出现之前,虚假信息和宣传就已经存在了。你可以说 AI 加速了这一切,就像它对很多事情都有加速作用一样。但它并没有发明这些东西。」(@ Z potentials)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻

 浙公网安备 33010602011771号
浙公网安备 33010602011771号