
gpt-4o-audio-preview 发布,支持 STT/TTS 不含实时音频;Ministral 3B/8B 端侧模型发布
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。
我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@鲍勃
01`有话题的新闻
1、英伟达开源模型 Nemotron-70B 超越 GPT-4o 和 Claude 3.5,仅次于 OpenAI o1
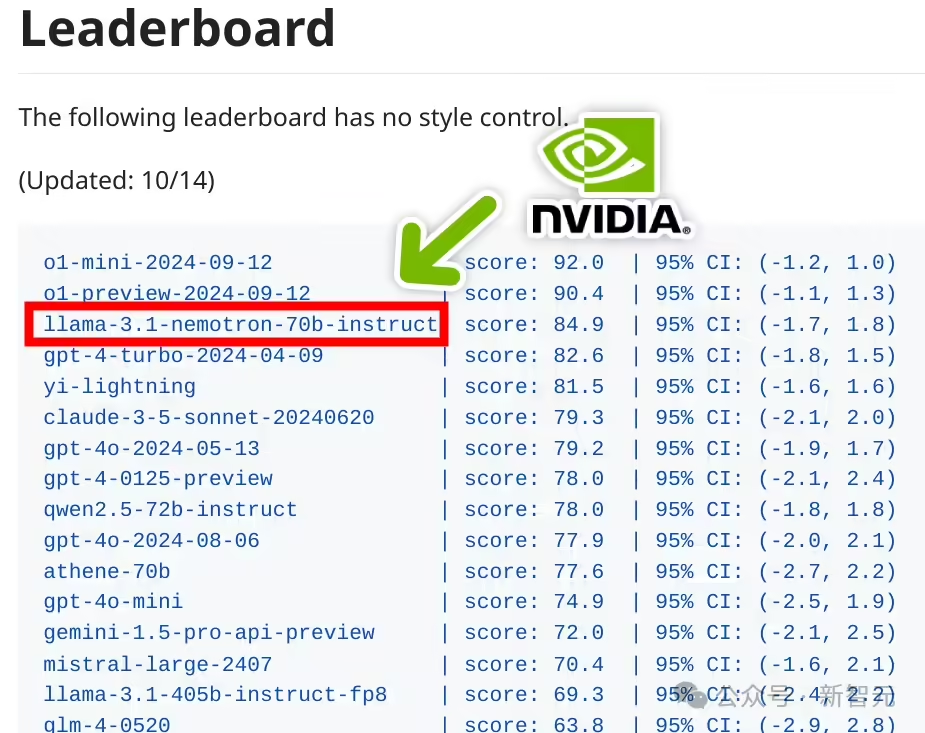
英伟达开源了超强模型 Nemotron-70B,该模型一经发布,就立刻在 AI 社区引发巨大轰动。
在多个基准测试中,它一举超越多个最先进的 AI 模型,包括 OpenAI 的 GPT-4、GPT-4 Turbo 以及 Anthropic 的 Claude 3.5 Sonnet 等 140 多个开闭源模型。并且仅次于 OpenAI 最新模型 o1。
Nemotron 基础模型,是基于 Llama-3.1-70B 开发而成。Nemotron-70B 通过人类反馈强化学习完成的训练,尤其是「强化算法」。
这次训练过程中,使用了一种新的混合训练方法,训练奖励模型时用了 Bradley-Terry 和 Regression。使用混合训练方法的关键,就是 Nemotron 的训练数据集,而英伟达也一并开源了。
它基于 Llama-3.1-Nemotron-70B-Reward 提供奖励信号,并利用 HelpSteer2-Preference 提示来引导模型生成符合人类偏好的答案。
业内人士评价:英伟达在 Llama 3.1 的基础上训练出不太大的模型,超越了 GPT-4o 和 Claude 3.5 Sonnet,简直是神来之笔。
目前,模型权重已可在 Hugging Face 上获取。(@IT 之家)
2、OpenAI 开放 ChatGPT Windows 版本,可像 Office 那样使用了
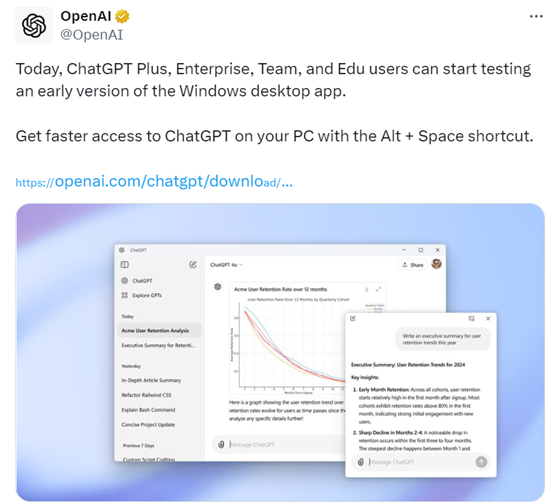
今天凌晨 OpenAI 宣布向所有 ChatGPT Plus、Enterprise、Team 和 Edu 用户,提供 Windows 桌面应用早期版本。
用户可在微软的应用商店中下载,安装完成后通过 Alt + Space 快捷键就能迅速启用,提供文件分析、搜索对话、文本生成等功能,使用体验相当丝滑和 Office 一样。
目前,OpenAI 已经开放了 Mac、Windows 两大操作系统的桌面版本,唯独没有对 Linux 做出明确的发布时间安排,所以,不少用户询问何时能开放该平台版本。OpenAI 还没有给出详细的日期。(@AIGC 开放者社区)
3、端侧 AI 崛起:Mistral 发布 Ministral 3B / 8B,「全球最好的边缘模型」
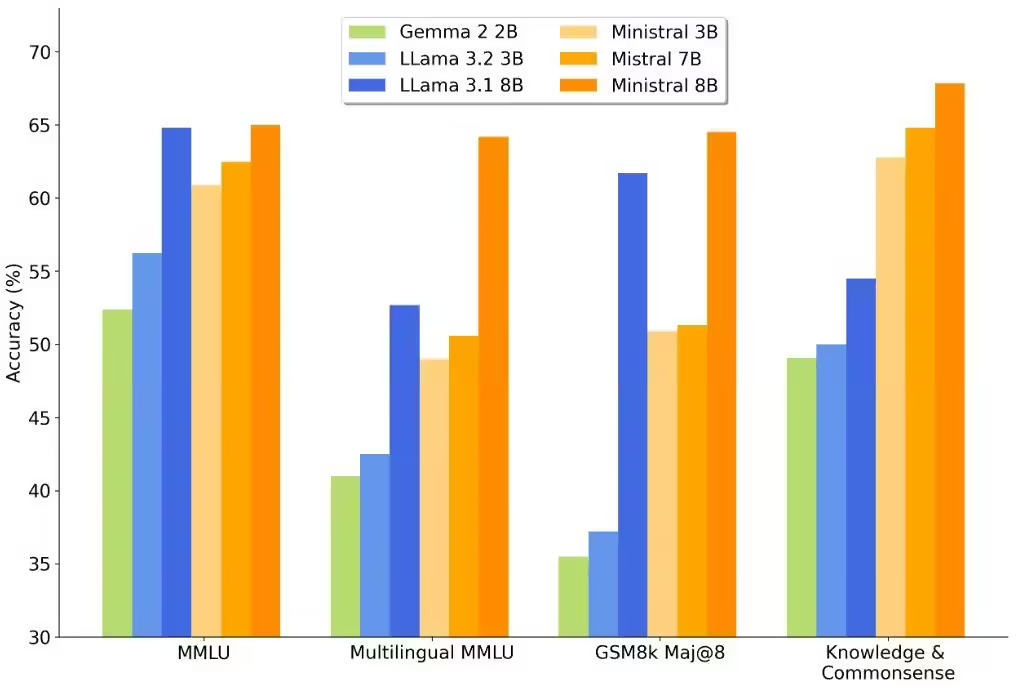
Mistral 公司最新推出了 Ministral 3B 和 Ministral 8B 两款 AI 模型,并不需要连接云服务器,重点提高笔记本电脑和智能手机等设备的本地化 AI 体验,官方声称是「世界上最好的边缘模型」。
Mistral 公司表示越来越多的企业希望能够在个人设备上运行 AI 模型,一方面确保安全的数据处理,另一方面也提高响应速度。
上述两个模型可在没有互联网接入的情况下,执行翻译服务、本地分析和机器人等多项服务。
这两个 AI 模型的上下文窗口均为 128K,相当于一次可以处理 50 页文档。
Ministral 8B 的价格为每百万个 tokens 售价 0.1 美元,而 3B 版本则为 0.04 美元,适合小规模操作或初创开发者。Ministral 8B 采用了特殊的交错滑动窗口注意力机制,这种设计可以在推理时更快且节省内存。(@IT 之家)
4、微软将终止中国个人 Azure OpenAI 服务,仅企业客户可用
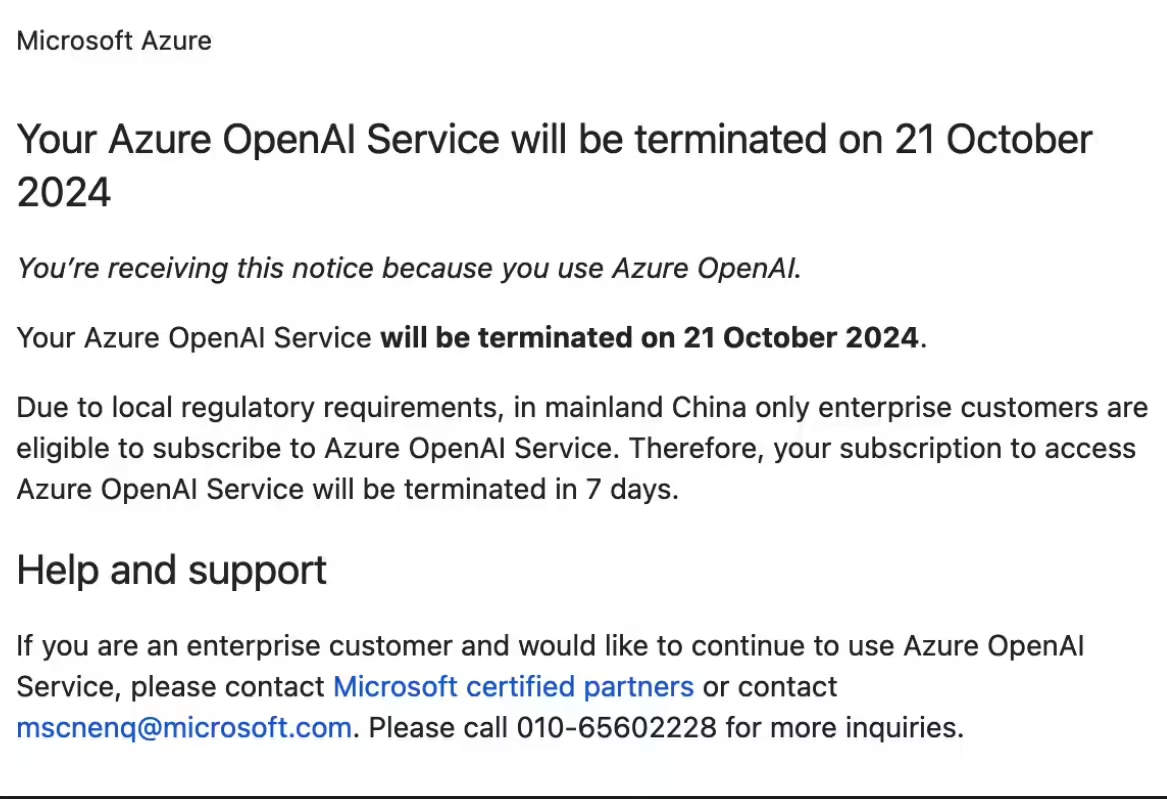
据第一财经 10 月 17 日报道,多位开发者收到微软邮件称,由于当地监管要求,微软 Azure OpenAI 服务将于 10 月 21 日关停,未来在中国大陆只有企业客户才能订阅 Azure 的 OpenAI 服务。
多数开发者是 17 日早上收到了邮件。有开发者表示,「这是个人身份在国内能合规使用 OpenAI 的唯一窗口,现在也关闭了。」同时,有开发者不满微软「就给四天处理时间」。针对此事,微软方面暂未表态。
值得注意的是,微软官方微信公众号「微软科技」悄悄删除了一篇题为《何须平替?迁移到 AzureOpenAI,简单快捷的文章,这篇文章发出于 6 月 26 日。
而据此前报道,就在 6 月 25 日,OpenAI 向国内部分开发者发送邮件,称「从 7 月 9 日起采取额外措施,阻止来自非支持国家和地区列表中的地区的 API 流量」。(@IT 之家)
5、Hallo 2:根据单张图像和音频输入能够生成长达一小时的 4K 分辨率人像视频
根据单张图像和音频输入生成唱歌和说话视频,并能控制人物表情和姿态的模型 Hallo 发布了更新版本 Hallo 2。
Hallo2 解决了长时、高分辨率的视频生成问题。它在现有的短时视频生成模型(如 Hallo)基础上进行了多项重要改进,能够生成长达一小时的 4K 分辨率人像视频,适用于各种人像表情和风格控制。
-
生成视频时长:最多支持生成 1 小时 的连续人像视频,且保持视觉一致性。
-
分辨率支持:最高支持 4K 分辨率 视频输出,生成的人像动画在细节和清晰度方面表现出色。
-
表情和风格控制:通过语音和文本标签的结合,生成的内容表现出高水平的可控性,能够根据不同输入生成情感丰富的多样化内容。
-
视觉一致性与时间连贯性:实验表明,Hallo2 通过补丁丢弃和噪声增强技术,在生成长时视频时极大程度上减少了表情抖动和外观漂移等问题。
Hallo2 是目前首个实现长达一小时、4K 分辨率的音频驱动人像动画生成模型。通过创新的补丁丢弃、噪声增强和时间对齐等技术,它解决了长时视频生成中的外观漂移和视觉不一致问题,支持灵活的语音与文本控制,生成质量达到业内领先水平。(小互 AI)
6、OpenAI 发布新的支持音频的 Chat 模型 "gpt-4o-audio-preview"
OpenAI 发布了新的支持音频的 Chat 模型 "gpt-4o-audio-preview"
现在调用这个模型可以输入文本或音频,API 可以返回文本、音频或混合数据。这个 API 更适合异步场景,如果想要实时音频,还是需要用前不久发布的很贵的实时音频 API。
但这个 API 返回速度是不错的,只是不能像实时 API 可以随时打断。
并且这个模型同样可以检测语调、语气变化及其他细微差别。
可以利用这些音频功能来:
-
生成文本内容的语音摘要(输入文本,输出音频)
-
对录音进行情感分析(输入音频,输出文本)
-
与模型进行异步的语音对话(输入音频,输出音频)
来源:宝玉@X https://x.com/dotey/status/1847100400664494186
02有态度的观点
1、LeCun:AGI「至少还需要几年甚至十年的时间」
Meta 首席 AI 科学家 Yann LeCun(杨立昆)近日在「Human-Level AI」演讲中表示,尽管当前 AI 模型在模拟人类记忆、思考、规划和推理方面取得了进展,但它们并未真正达到「人类水平的 AI」。
当前的 AI 系统,如 ChatGPT 和 Meta AI,基于预测下一个标记或像素,虽然在各自维度上预测能力很强,但并不能真正理解三维世界。
他提出了「世界模型」(world model)这一概念,世界模型是关于世界如何运作的心理模型,可以预测一系列行动对世界的影响。与大型语言模型相比,世界模型能够处理更多数据,但计算密集度高,这也是云服务提供商争相与 AI 公司合作的原因。想要达到人类水平的人工智能,或许我们还需要数十年的时间。( @APPSO)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻

 浙公网安备 33010602011771号
浙公网安备 33010602011771号