上海交大开源超逼真声音克隆 TTS;微软探索音生图 AI 模型丨 RTE 开发者日报

这里是 「RTE 开发者日报 」,每天和大家一起看新闻、聊八卦。
我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@鲍勃
01有话题的新闻
1、Adobe 推出全新 AI 视频生成器 Firefly Video Model,完全使用授权内容进行训练
Adobe 公司今日发布了全新的人工智能驱动的文本转视频工具 Firefly Video Model。该工具能够根据文本提示生成全新的视频,与竞争对手不同,Adobe 声称 Firefly Video Model 完全使用授权内容进行训练,有望规避其他生成式 AI 工具所面临的伦理和版权问题。
由于其使用授权内容进行训练,Adobe 称 Firefly Video Model 是「第一个公开可用的商业安全视频模型」。然而,Adobe 尚未宣布其正式发布日期,并且在测试阶段仅向等待名单上的用户提供访问权限。
自至少 2023 年 4 月以来,Adobe 一直在开发这款新模型,其基础技术源自该公司为 Firefly 图像合成模型所开发的技术。与该公司后来集成到 Photoshop 中的文本转图像生成器一样,Adobe 希望将 Firefly Video Model 瞄准媒体专业人士,如视频创作者和编辑。该公司声称其模型可以生成与传统制作的视频内容无缝融合的素材。
虽然 Adobe 尚未透露任何使用其视频工具的客户,但据路透社报道,一些主要品牌已经使用其图像生成技术。百事可乐旗下的佳得乐计划使用 Adobe 的图像模型为定制瓶子设计网站提供服务。美泰公司一直在使用 Adobe 工具协助设计芭比产品包装。(@IT 之家)
2、微软生成式 AI 研究副总裁 Sebastien Bubeck,加入 OpenAI
路透社消息,微软生成式 AI 研究副总裁 Sebastien Bubeck 将离开微软,加入 OpenAI。
Bubeck 是描述微软 Phi 模型的主要作者之一,这是一系列超小型语言和视觉模型,旨在推动 AI 应用到边缘设备。随着像 OpenAI 的 GPT-4o 这样的庞大集中模型在某些市场逐渐被快速、私密且离线工作的设备模型所取代,这种专业知识变得越来越重要。
微软发言人表示,Sebastian 已决定离开微软,进一步开发 AGI。我们期待通过 Bubeck 与 OpenAI 的合作来继续维持双方的关系。
Sebastien Bubeck 是微软一位重要研究人员,其研究涵盖深度学习、机器学习、优化和算法理论等多个方面。(@AIGC 开发者社区)
3、微软探索音生图 AI 模型,实时视觉化会议演讲者语音讲述的场景
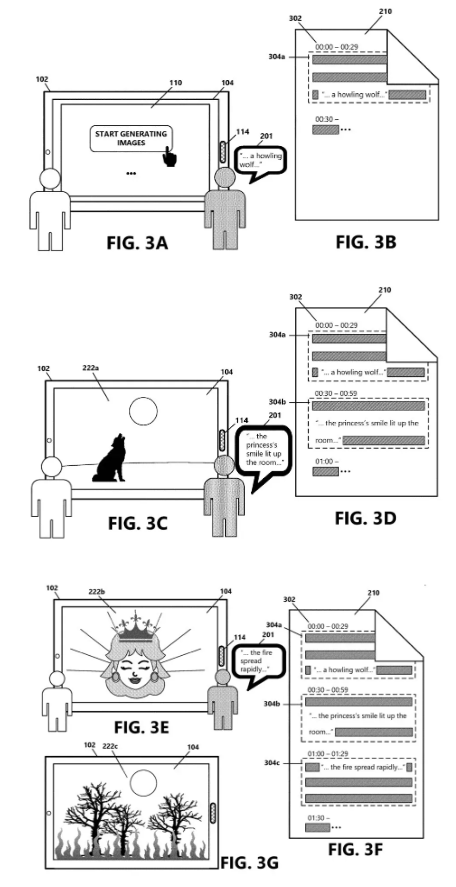
科技媒体 MSPoweruser 称微软公司获得了一项新的专利,描述了基于用户实时输入的语音来生成图片。
根据美国商标和专利局最新公示的清单,该专利共计 20 页,微软于 2023 年 4 月 5 日提交申请,于 10 月 10 日获批。
根据专利描述,该系统可以在会议或讲座中实时捕捉音频,随后通过语言模型进行总结,并生成相应的 AI 图像。
IT 之家援引该媒体报道,该工作会分为 3 个步骤:
-
捕捉音频 :用户通过麦克风发言,系统实时记录并转化为文本。
-
处理文本 :分段记录文本,每段内容通过语言模型进行总结。
-
生成图像 :根据总结生成的提示,系统创建AI 生成的图像,并在屏幕上实时显示。
预计该功能将主要应用于 Microsoft Teams。随着演讲者话题的变化,实时生成的图像也会随之更新,从而增强视觉沟通的效果。微软表示,这种图像的使用有助于澄清概念,特别适合通过视觉辅助学习的用户。(@IT 之家)
4、F5-TTS:上海交大开源超逼真声音克隆 TTS,告别 ElevenLabs
F5-TTS 是一款基于流匹配的全非自回归文本到语音转换系统。不需要复杂的设计如持续时间模型、文本编码器和音素对齐,能够快速训练并实现实时因素(RTF)0.15 的推理速度,显著优于当前基于扩散的 TTS 模型。F5-TTS 在公共的 100K 小时多语言数据集上进行训练,展现出高自然性和表现力的零样本能力、无缝代码切换能力和速度控制效率。项目提出了一种推理时的摇摆采样策略,显著提高了模型的性能和效率。
模型特点有:
-
零样本 (Zero-shot) 声音克隆
-
速度控制(基于总时长)
-
可以控制合成语音的情感表现
-
长文本合成
-
支持中文和英文多语言合成
-
在10 万小时数据上训练
-
最重要的是支持商用(@开源 AI 项目落地)
5、One-Click Creative Template:创意模型 用一张卡通图片总结 4 张真实人物照片


FLUX.1-dev-LoRA-One-Click-Creative-Template 是由 Shakker Labs 提供的一个用于 文本生成图像(Text-to-Image) 的模板模型,专为创造性照片生成而设计。
模型会根据你的输入提示词生成 4 张背景照片,背景部分由 4 张真实照片组成,并在其中央插入一张卡通风格的图像,作为对整个场景的总结。(@小互 AI)
02 有态度的观点
1、Benchmark 合伙人:训练大模型目前成本远大于收入;但理论上成功回报极大,所以你仍需不断加注
David Cahn 在文章《AI's $600B Question》中论述道,鉴于 NVIDIA 预计 2024 年第四季度的收入为 1500 亿美元,要收回为训练和运行大语言模型所投入的巨额资金,现在 AI 收入需要达到 6000 亿美元,而在这方面我们至少还差 5000 亿美元。这个数字确实令人震惊……而且只会越来越大。
随着 LLM 的进步,它将超越代码补全(「Copilot」)的功能,进入代码创作(「Autopilot」)的领域,价值创造几乎没有上限,因为这将极大地扩展市场——如果有人成为主导者,这将是一个潜在的数万亿美元的机会。AI 的潜在价值创造和获取,已经超出了我们现有的思维模型。
挑战在于,每训练一个更复杂的 LLM 所需的资金量都会呈数量级增加,而且一旦某个模型被另一个超越,旧模型的定价权会迅速降为零。如今,开发者可选择的 GPT3.5 等价模型已经多到不值得一一尝试。当 GPT3.5 在 2022 年 11 月发布时,它遥遥领先于任何竞争模型,1000 个 tokens 的成本是 0.0200 美元。而现在,这个价格已经降到 0.0005 美元——仅仅 1 年半内价格下降至原来的 2.5%。这种动态使得此时此刻几乎不可能为任何投资的 LLM 找到合理的投资回报率,因为每一笔投资几乎都会在下一个版本推出时立刻贬值。然而,我们也无法跳过任何步骤。要实现最终的理想目标,理想化的「AGI」,需要经历无数看似毫无价值的版本。
最终结果是,在短期内,除非在继续投资现有 Transformer 架构的基础设施的边际价值上达到了一个有效前沿,或者电力资源耗尽,亦或是某个团队凭借智能的算法工作取得无法超越的领先地位,否则 Meta、Microsoft、Google 这些巨头在这一领域的投资必将继续大幅增加,而成本必然会先于收入。理论上,回报是如此之大,如果有一个明确的赢家出现,他们的市场机会几乎是无上限的,因此必须不断加大赌注。(@Z Potentials)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻

 浙公网安备 33010602011771号
浙公网安备 33010602011771号