
【基础组件18】Apache Druid 0.14入门(一)简介、集群部署、使用kafka 构建实时数据摄取
参考链接:
https://www.cnblogs.com/momoyan/p/9614635.html
https://blog.csdn.net/weixin_38441544/article/details/82853651
http://www.zhyea.com/2018/07/12/druid-historical-broker-boot-failed.html
参考课程:
https://www.imooc.com/video/20024 慕课网
Druid支持对海量数据聚合存储,聚合查询

一、OLTP(数据操作)和OLAP(数据分析)系统的区别
Druid主要用于OLAP 数据分析,提供决策,仅支持查询
MySQL主要用于OLTP 数据操作,支持数据的增删查改,实时修改,支持事务

二、druid的应用场景

三、druid基本特点

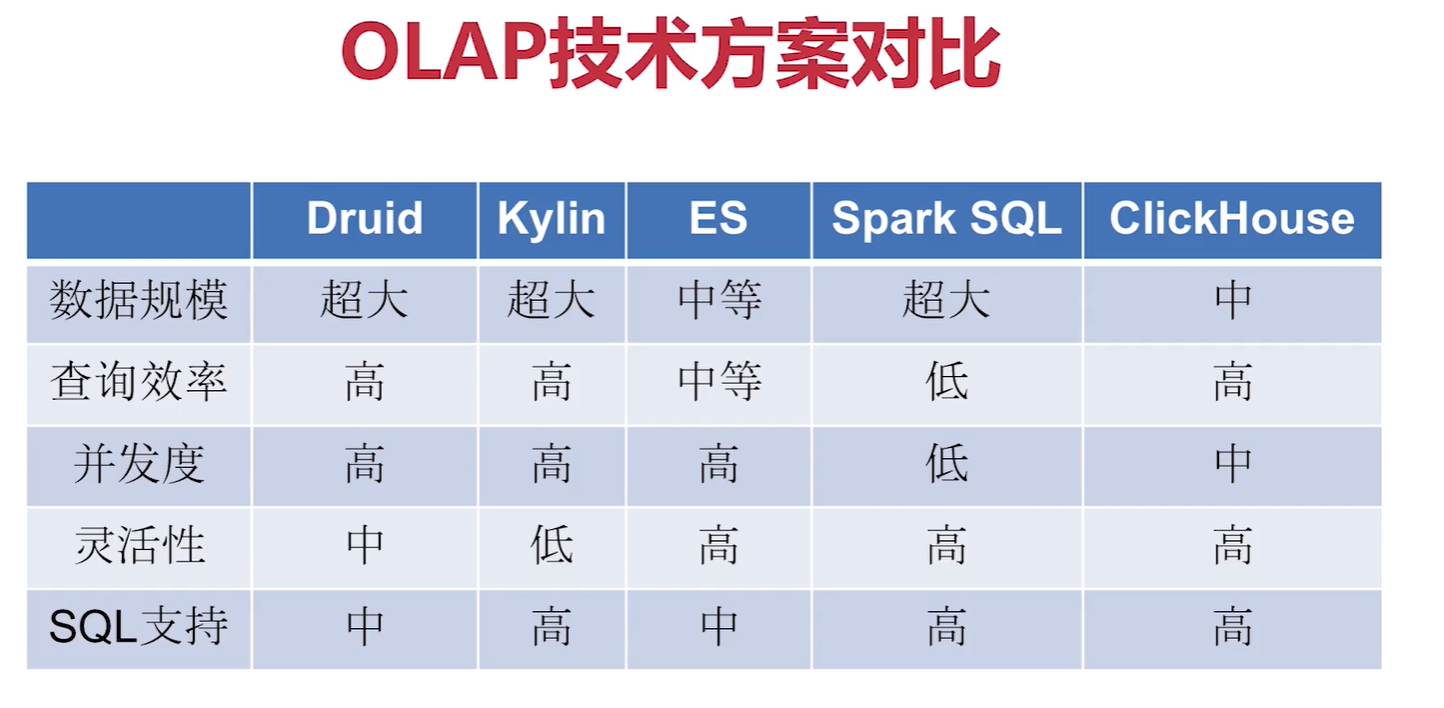
四、OLAP系统方案对比
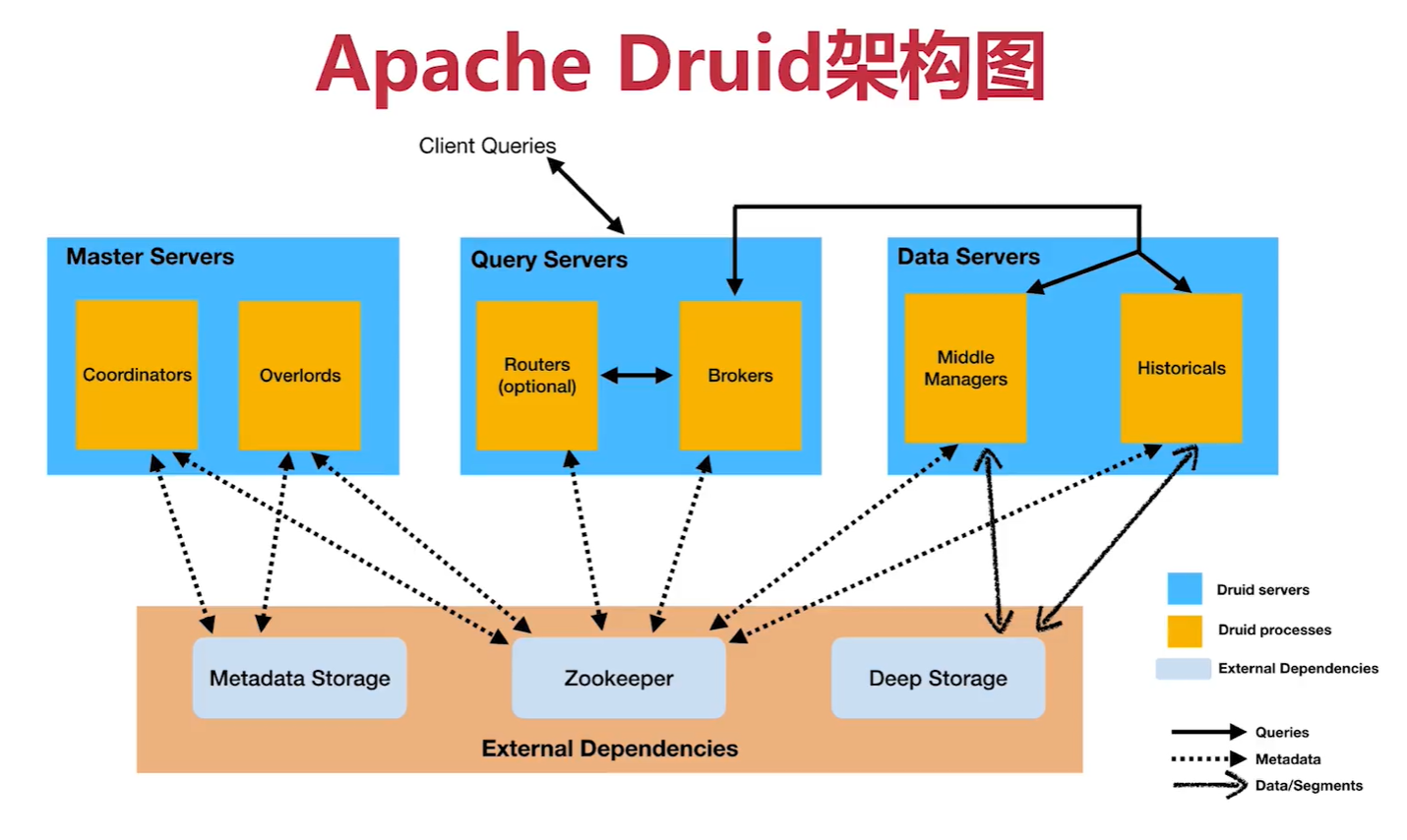
五、druid的架构
参考课程:https://www.imooc.com/video/19660
metadata 元数据,存在mysql中
deep storage , 存在hdfs中
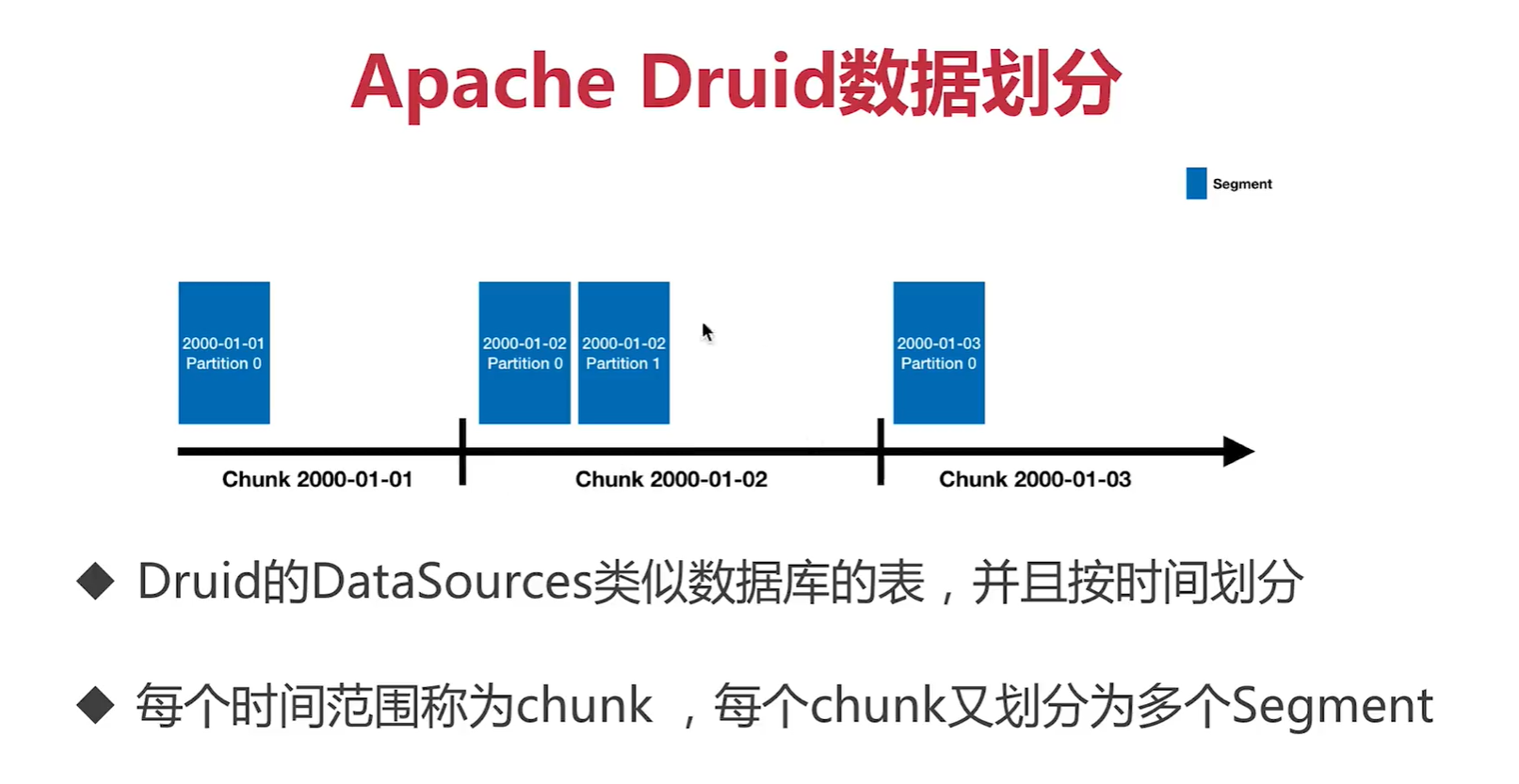
六、datasource, chunk, segment druid的数据结构
七、druid集群部署
1.官网下载安装包
https://druid.apache.org/downloads.html
2.参考教程:https://www.imooc.com/video/19661
八、druid 数据摄取配置
overlord节点:发布任务
middlemanager节点:生产数据
historical节点:加载数据
broker节点:接收客户端的查询请求


九、Apache Druid 使用HDFS 构建离线数据摄取
需要从 mapreduce中摄取数据
此外 hdfs也可以作为druid的深度存储
十、Apache Druid 使用Kafka 构建实时数据摄取
1.kafka简介
consumer 消费者
consumer group 消费者组:不同的消费者组,互不影响,A组消费了topic 111的消息后,B组也可以去消费topic 111的消息
同一个消费者组里的消费者,有影响,若消费者数小于或者等于partition数,则一个消费者消费一个或者多个partition
若消费者数大于partition数,则有消费者消费不了消息,没有消息消费
就是同一个消费者组的消费者,会消费不同partition的消息,消费了就没了,不能重复消费
topic 不同类型的消息
partiton 分区,为了提高并行度
某些topic的消息多,就可以多设置几个partition, 提高并行度,
消息少,则可少设置几个partition
cosumer_offset 偏移量 消费了就会把偏移量返回给broker
2. kafka配置参考:https://www.imooc.com/video/19665
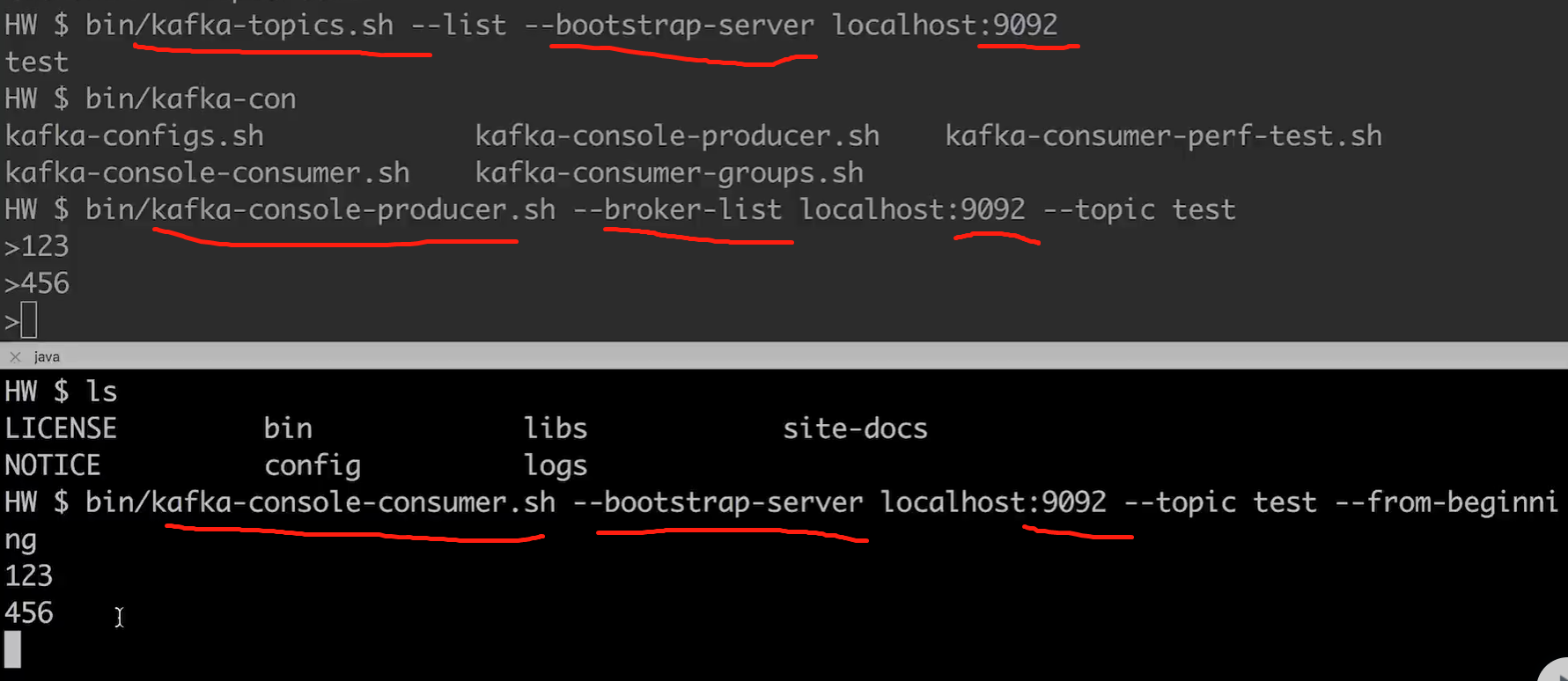
3.使用kafka 构建实时数据摄取
参考:https://www.imooc.com/video/19666

 浙公网安备 33010602011771号
浙公网安备 33010602011771号