(二)Spark高可用HA搭建
一.集群规划
| Master | Slave1 | Slave2 | Slave3 | |
| IP | 192.168.2.131 | 192.168.2.132 | 192.168.2.133 | 192.168.2.134 |
| Zookeeper | Y | Y | Y | N |
| Master | Y | Y | N | N |
| Worker | Y | Y | Y | Y |
二.搭建Spark(HA)
2.1.说明
Spark(HA)启动前需要启动、zookeeper、hadoop、可参照zookeeper、hadoop(HA)进行搭建。 Spark参照Spark(spark on yarn 模式)安装,然后改动一些配置重启Spark即可。
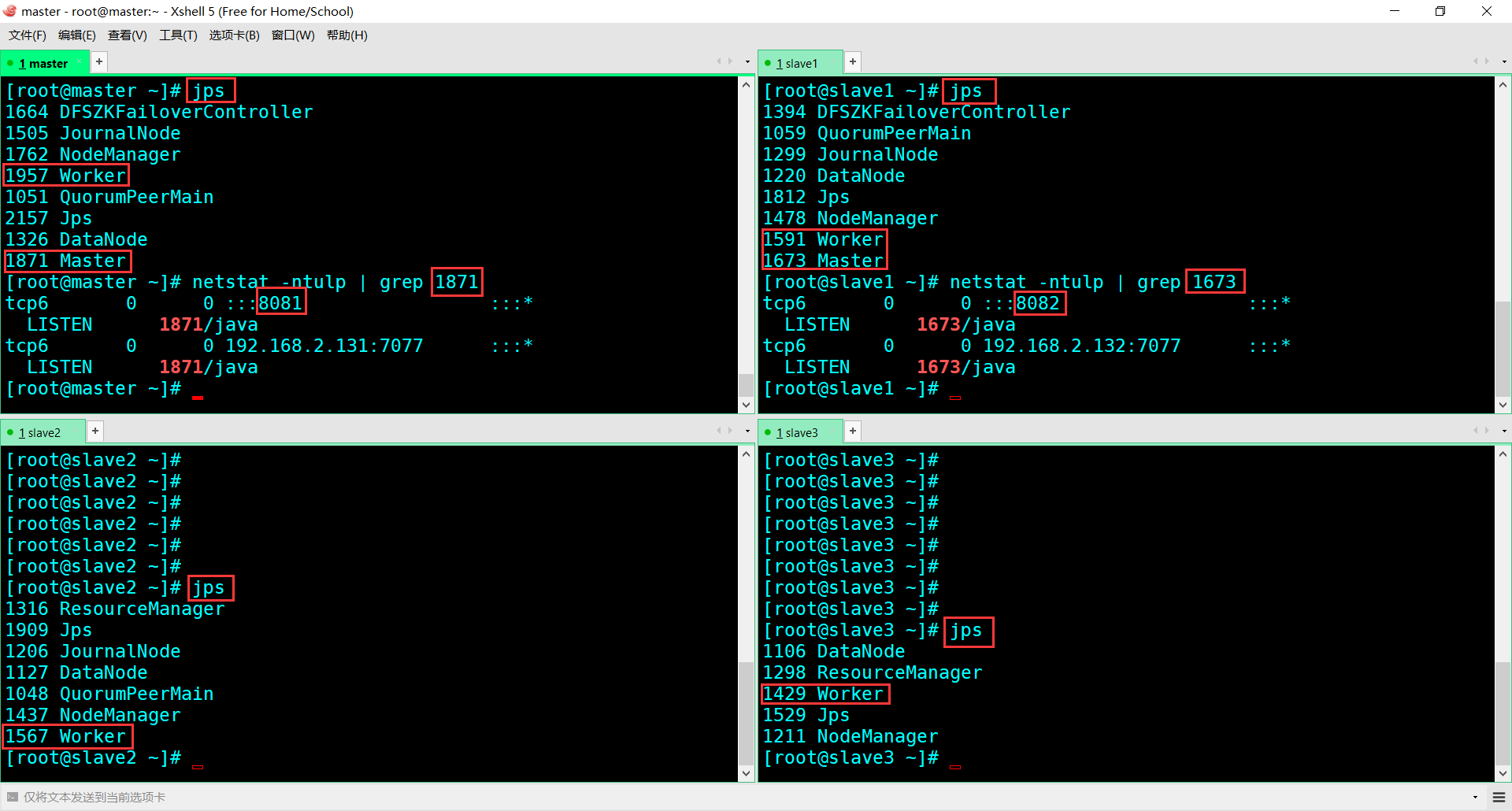
1.配置spark-env.sh文件中添加【其他不变】 # 设置zookeeper维护主备切换 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark" 2.手动启动 # cd /usr/local/spark/sbin/ 进 # ./start-master.sh 启动备机 # jps 查看
# netstat -ntulp | grep Master进程号 通过进程号来查看端口
2.2.验证
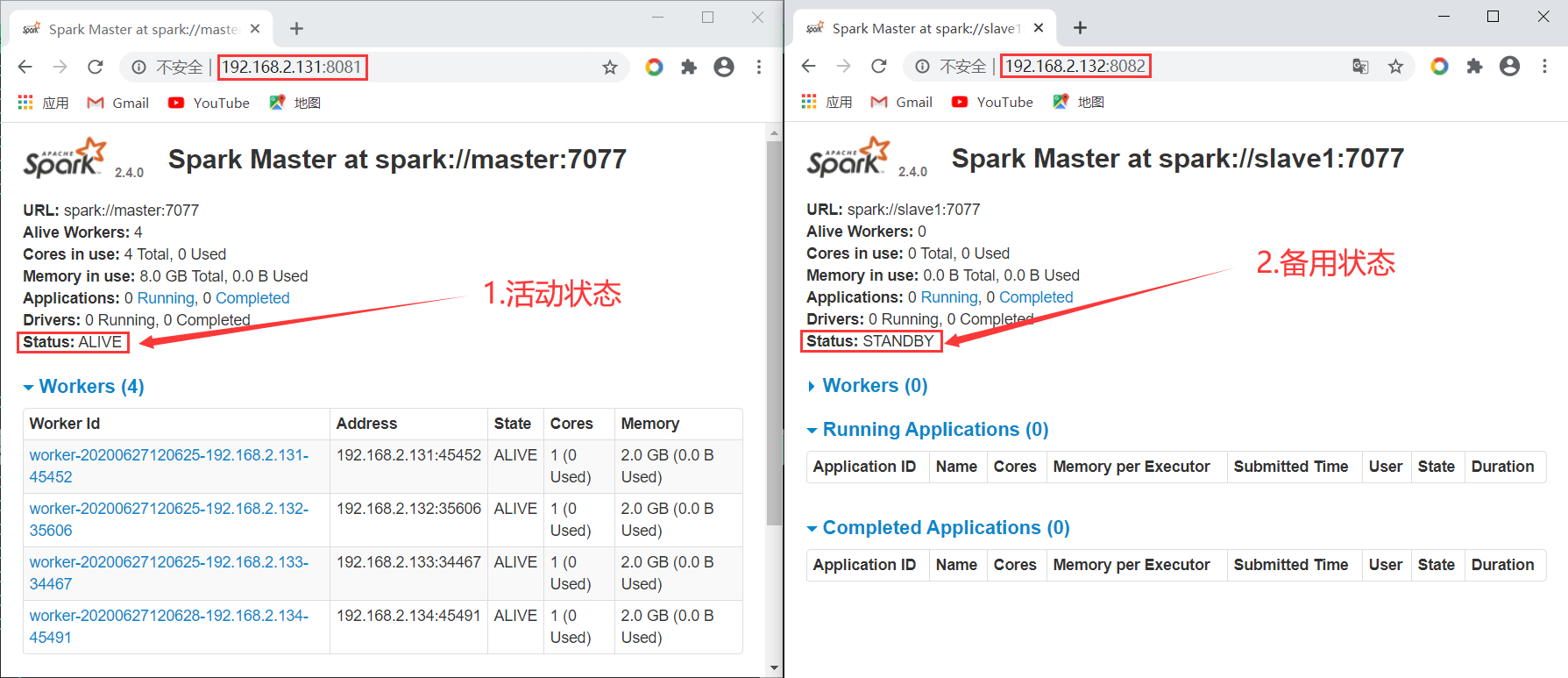
登录Spark的Web页面:192.168.2.131:8081(Master)、192.168.2.132:8082(Slave1)。格式:IP+查看的端口号
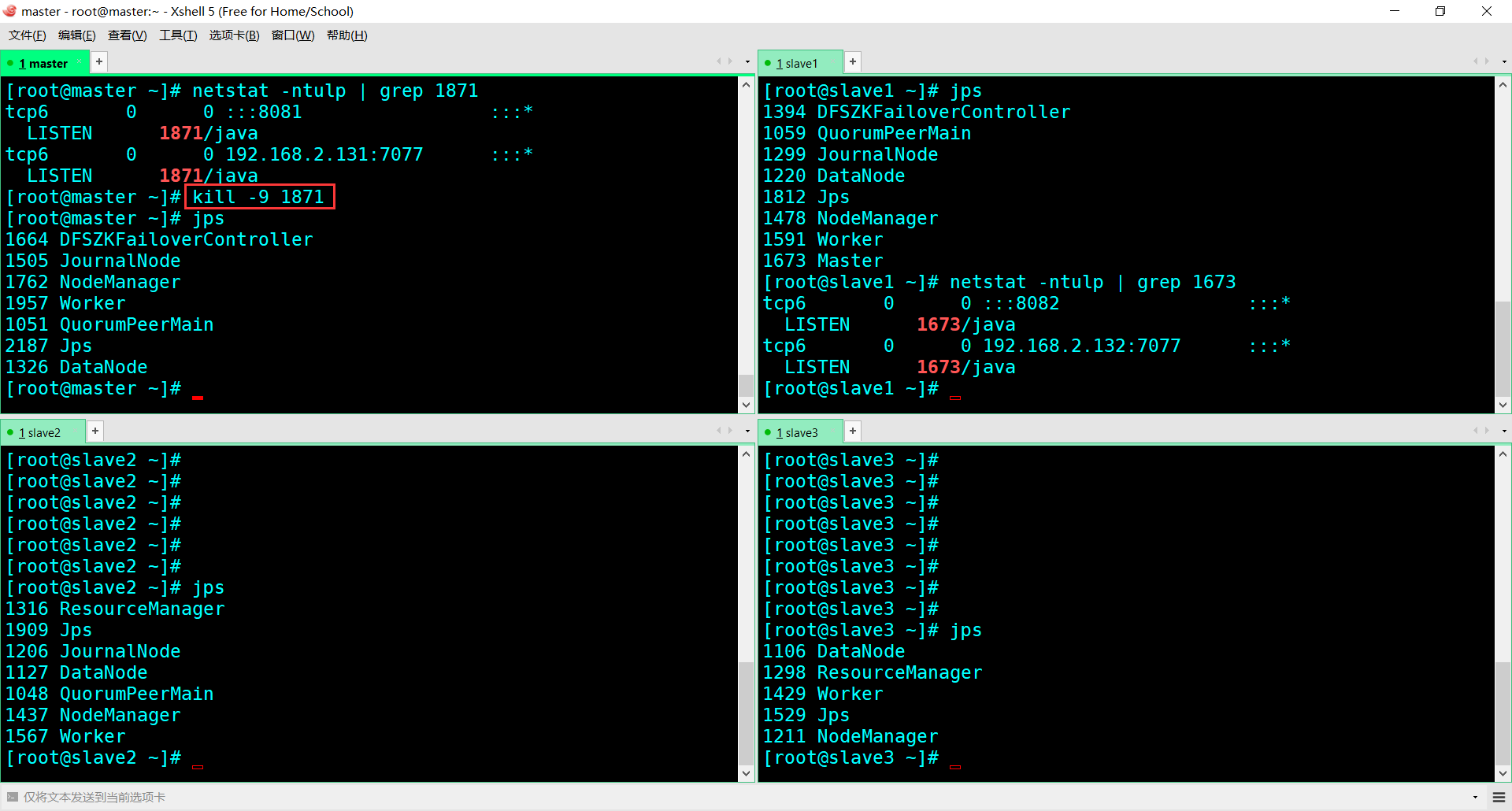
干掉Master(alive)看看
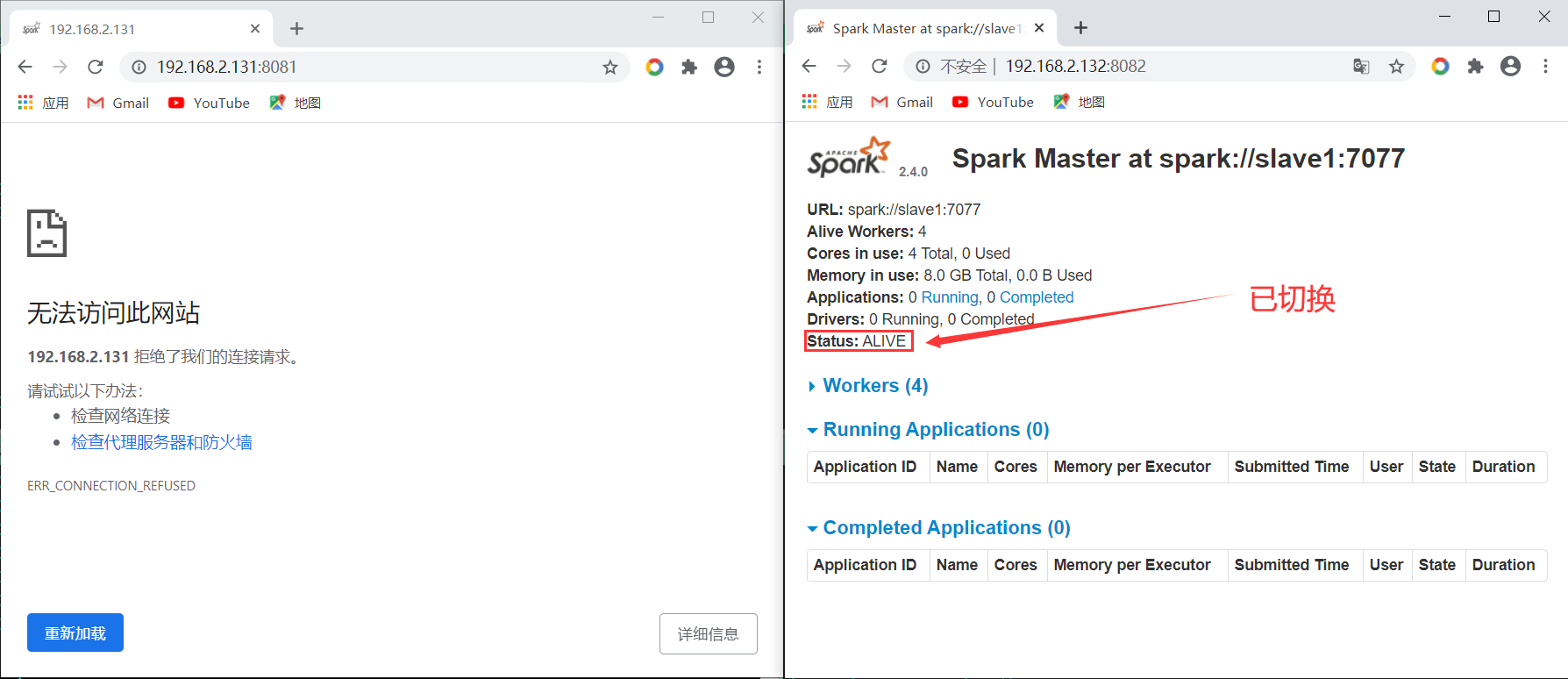
登录Web

 浙公网安备 33010602011771号
浙公网安备 33010602011771号