(一)Hadoop全分布式搭建
一.集群规划
| Name | Master | Slave1 | Slave2 |
| IP | 192.168.2.98 | 192.168.2.99 | 192.168.2.100 |
| Jdk版本 | 1.8.0.171 | 1.8.0.171 | 1.8.0.171 |
| Zookeeper版本 | 3.4.10 | 3.4.10 | 3.4.10 |
| Hadoop版本 | 2.7.3 | 2.7.3 | 2.7.3 |
| NameNode | Y | N | N |
| SecondaryNameNode | Y | N | N |
| NodeManager | N | Y | Y |
| DataNode | N | Y | Y |
二.搭建Hadoop(分布式)
在已完成此配置的基础上执行以下。tar包链接: https://pan.baidu.com/s/1hwLPI0eUwkpGmP5ROqM6Lw 提取码: k7m3
# mkdir /usr/Hadoop 建立hadoop目录 # tar -zxvf /opt/soft/hadoop-2.7.3.tar.gz -C /usr/hadoop/ 解压至hadoop目录 # vim /etc/profile 添加hadoop环境变量 export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3 export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib export PATH=$PATH:$HADOOP_HOME/bin # cd /usr/hadoop/hadoop-2.7.3/etc/hadoop/ 进入 # vim hadoop-env.sh 配置1添加 export JAVA_HOME=/usr/java/jdk1.8.0_171 Jdk路径 # vim core-site.xml 配置2在<configuration> </configuration>之间添加 <property>
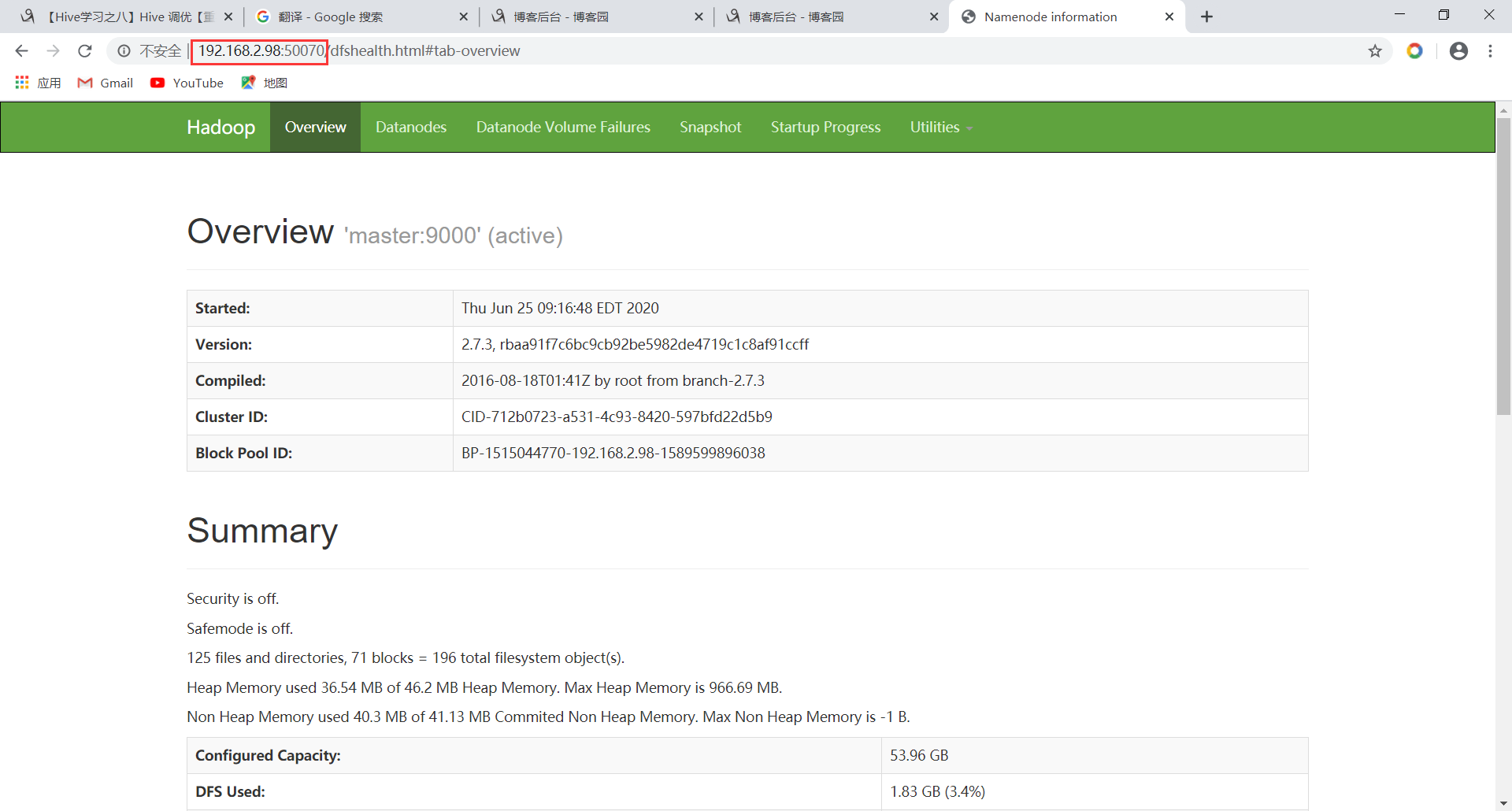
<!-- NameNode地址,这里判断fs.default.name参数还是使用fs.defaultFS。看部署是否开启了NN的HA --> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value> <description>A base for temporary directories.</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>fs.checkpoint.period</name> <value>60</value> </property> <property> <name>fs.checkpoint.size</name> <value>67108864</value> </property> # vim yarn-site.xml 配置3在<configuration> </configuration>之间添加 <property> <name>yarn.resourcemanager.address</name> <value>master:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:18088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:18141</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> # vim hdfs-site.xml 配置4在<configuration> </configuration>之间添加 <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value> <final>true</final> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> # cp mapred-site.xml.template mapred-site.xml 复制配置4 # vim mapred-site.xml 配置4在<configuration> </configuration>之间添加 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> # vim slaves 配置5删除localhost添加 slave1 slave2 # vim master 配置6 自行创建内添加 master # scp -r /usr/hadoop root@slave1:/usr/ 配好的hadoop发往结点1 # scp -r /usr/hadoop root@slave2:/usr/ 发结点2 # scp -r /etc/profile root@slave1:/etc/ 将环境变量发往结点1 # scp -r /etc/profile root@slave2:/etc/ 结点2 # source /etc/profile 各结点执行生效环境变量 # hadoop namenode -format 主结点执行格式化,出现”0”则成功! # cd /usr/hadoop/hadoop-2.7.3/ 进此目录下开启hadoop集群 # sbin/start-all.sh 开启集群 stop为关闭集群 打开浏览器网址栏输: 192.168.2.98:50070访问HDFS的web管理页面 Hadoop搭建完成后关于windows设置 C:\Windows\System32\drivers\etc 以记事本的方式打开hosts做机器名映射加入 192.168.2.98 master 192.168.2.99 slave1 192.168.2.100 slave2
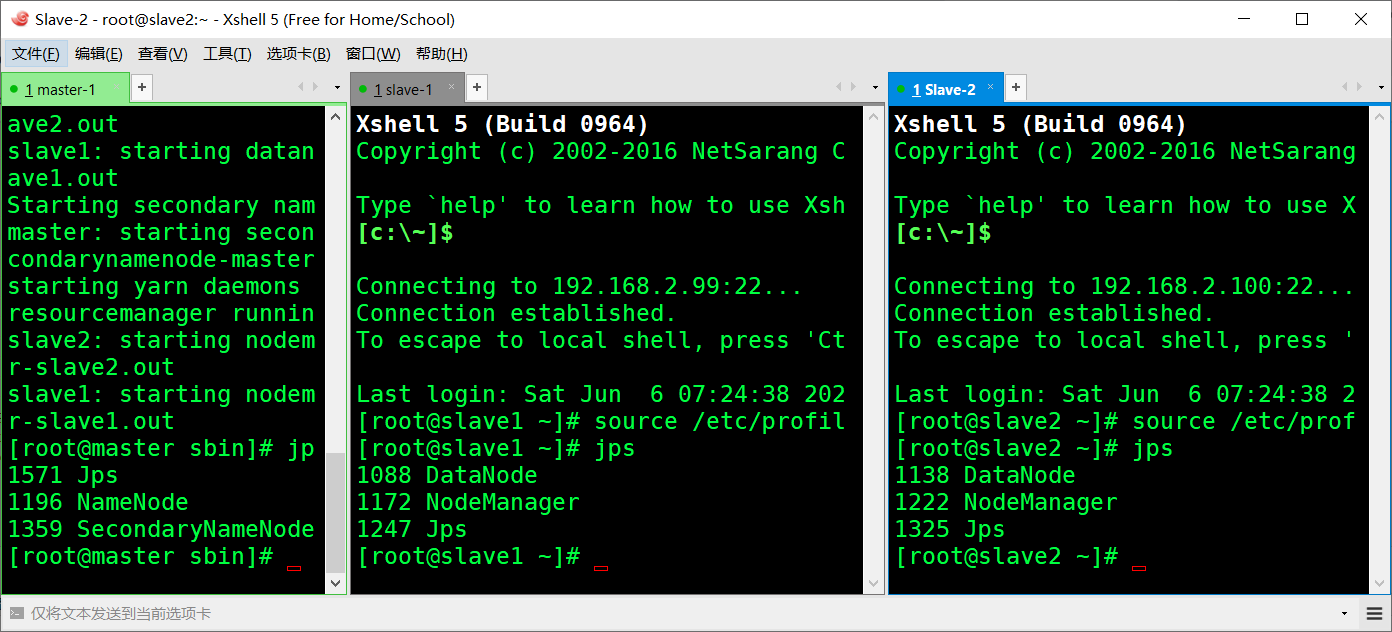
访问WEB端

 浙公网安备 33010602011771号
浙公网安备 33010602011771号